








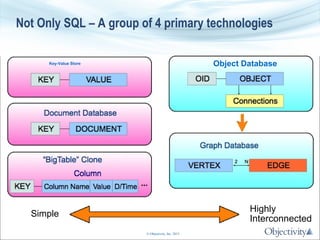













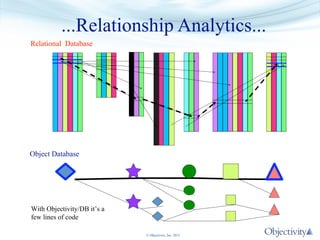




























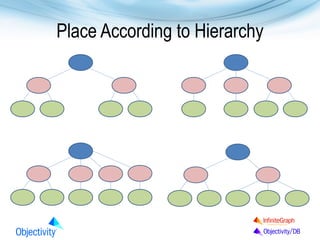
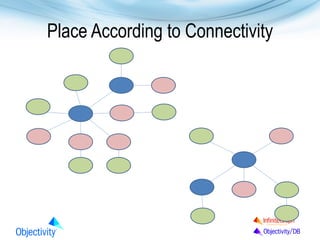





The document presents Objectivity, Inc.'s NoSQL database, Objectivity/DB, highlighting its applications in defense, scientific, and engineering sectors. It discusses the evolution of object databases, the scalability and performance of high ingest systems, and the importance of data placement for optimal database performance. The presentation also covers architectural features, typical configurations, and the flexibility of the database in accommodating various data models and usage cases.
















































































