Downloaded 298 times











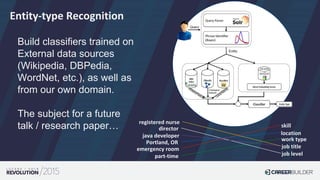
![Building a Taxonomy of Entities
Many ways to generate this:
• Topic Modelling
• Clustering of documents
• Statistical Analysis of interesting phrases
• Buy a dictionary (often doesn’t work for
domain-specific search problems)
• …
Our strategy:
Generate a model of domain-specific phrases by
mining query logs for commonly searched phrases within the domain [1]
[1] K. Aljadda, M. Korayem, T. Grainger, C. Russell. "Crowdsourced Query Augmentation through Semantic Discovery of Domain-specific Jargon," in IEEE Big Data 2014.](https://image.slidesharecdn.com/leveraging-lucene-solr-as-a-knowledge-graph-and-intent-engine-151017133938-lva1-app6892/85/Leveraging-Lucene-Solr-as-a-Knowledge-Graph-and-Intent-Engine-15-320.jpg)




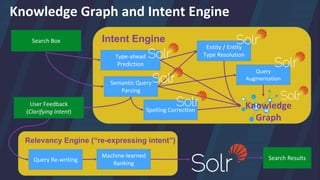
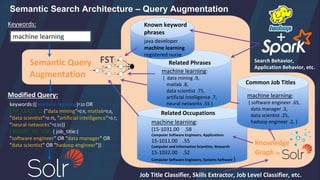
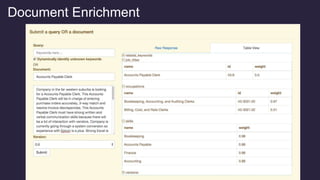
![Semantic Search Architecture – Query Parsing
1) Generate the previously discussed taxonomy of
Domain-specific phrases
• You can mine query logs or actual text of documents for
significant phrases within your domain [1]
2) Feed these phrases to SolrTextTagger (uses Lucene FST
for high-throughput term lookups)
3) Use SolrTextTagger to perform entity extraction
on incoming queries (tagging documents is also possible)
4) Also invoke probabilistic parser to dynamically identify
unknown phrases from a corpus of data (language model)
5) Shown on next slides:
Pass extracted entities to a Query Augmentation phase to
rewrite the query with enhanced semantic understanding
[1] K. Aljadda, M. Korayem, T. Grainger, C. Russell. "Crowdsourced Query Augmentation through Semantic Discovery of
Domain-specific Jargon," in IEEE Big Data 2014.
[2] https://github.com/OpenSextant/SolrTextTagger](https://image.slidesharecdn.com/leveraging-lucene-solr-as-a-knowledge-graph-and-intent-engine-151017133938-lva1-app6892/85/Leveraging-Lucene-Solr-as-a-Knowledge-Graph-and-Intent-Engine-22-320.jpg)

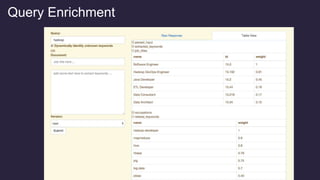
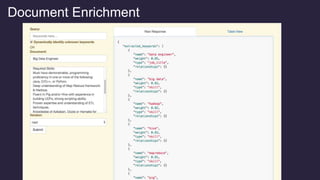


![So how does it work?
Foreground vs. Background Analysis
Every term scored against it’s context. The more
commonly the term appears within it’s foreground
context versus its background context, the more
relevant it is to the specified foreground context.
countFG(x) - totalDocsFG * probBG(x)
z = --------------------------------------------------------
sqrt(totalDocsFG * probBG(x) * (1 - probBG(x)))
{ "type":"keywords”, "values":[
{ "value":"hive", "relatedness":0.9773, "popularity":369 },
{ "value":"java", "relatedness":0.9236, "popularity":15653 },
{ "value":".net", "relatedness":0.5294, "popularity":17683 },
{ "value":"bee", "relatedness":0.0, "popularity":0 },
{ "value":"teacher", "relatedness":-0.2380, "popularity":9923 },
{ "value":"registered nurse", "relatedness": -0.3802 "popularity":27089 } ] }
We are essentially boosting terms which are more related to some known feature
(and ignoring terms which are equally likely to appear in the background corpus)
+
-
Foreground Query:
"Hadoop"
Knowledge
Graph](https://image.slidesharecdn.com/leveraging-lucene-solr-as-a-knowledge-graph-and-intent-engine-151017133938-lva1-app6892/85/Leveraging-Lucene-Solr-as-a-Knowledge-Graph-and-Intent-Engine-30-320.jpg)




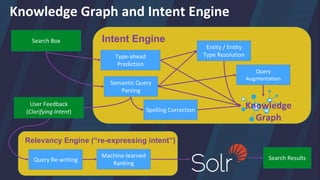


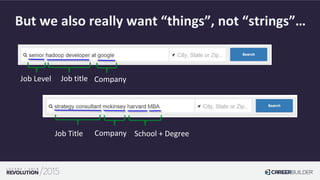
The document outlines Trey Grainger's approach to utilizing Lucene/Solr as an intent engine and knowledge graph for semantic search at CareerBuilder, detailing various components like semantic query parsing, type-ahead predictions, and entity resolution. It discusses the enhancements to traditional query parsing by creating more meaningful queries based on context, thereby improving user search experiences. Additionally, it highlights the significance of a knowledge graph for understanding relationships between different entities like job titles, skills, and locations.



































































































