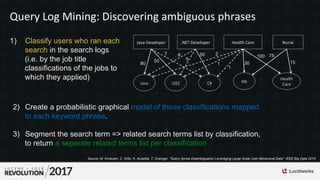
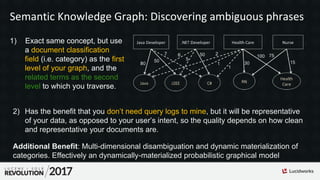
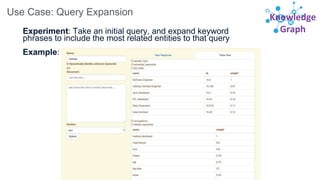
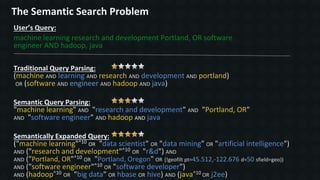
Downloaded 386 times










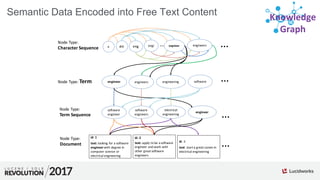
![Term Documents
a doc1 [2x]
brown doc3 [1x] , doc5 [1x]
cat doc4 [1x]
cow doc2 [1x] , doc5 [1x]
… ...
once doc1 [1x], doc5 [1x]
over doc2 [1x], doc3 [1x]
the doc2 [2x], doc3 [2x],
doc4[2x], doc5 [1x]
… …
Document Content Field
doc1 once upon a time, in a land far,
far away
doc2 the cow jumped over the moon.
doc3 the quick brown fox jumped over
the lazy dog.
doc4 the cat in the hat
doc5 The brown cow said “moo”
once.
… …
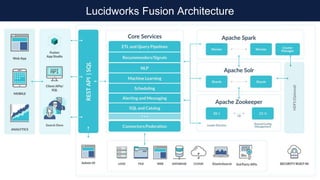
What you SEND to Lucene/Solr:
How the content is INDEXED into
Lucene/Solr (conceptually):
The inverted index](https://image.slidesharecdn.com/skg-181105051457/85/The-Apache-Solr-Semantic-Knowledge-Graph-11-320.jpg)






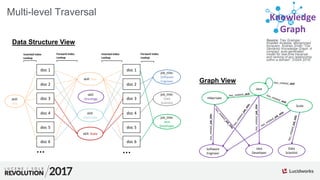
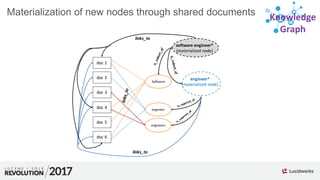


![Scoring of Node Relationships (Edge Weights)
Foreground vs. Background Analysis
Every term scored against it’s context. The more
commonly the term appears within it’s foreground
context versus its background context, the more
relevant it is to the specified foreground context.
countFG(x) - totalDocsFG * probBG(x)
z = --------------------------------------------------------
sqrt(totalDocsFG * probBG(x) * (1 - probBG(x)))
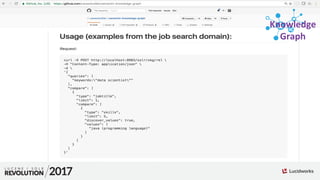
{ "type":"keywords”, "values":[
{ "value":"hive", "relatedness":0.9773, "popularity":369 },
{ "value":"java", "relatedness":0.9236, "popularity":15653 },
{ "value":".net", "relatedness":0.5294, "popularity":17683 },
{ "value":"bee", "relatedness":0.0, "popularity":0 },
{ "value":"teacher", "relatedness":-0.2380, "popularity":9923 },
{ "value":"registered nurse", "relatedness": -0.3802 "popularity":27089 } ] }
We are essentially boosting terms which are more related to some known feature
(and ignoring terms which are equally likely to appear in the background corpus)
+
-
Foreground Query:
"Hadoop"
Knowledge
Graph](https://image.slidesharecdn.com/skg-181105051457/85/The-Apache-Solr-Semantic-Knowledge-Graph-25-320.jpg)
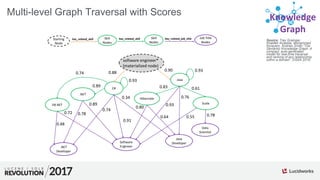



![Knowledge
Graph
Use Case: Data Cleansing
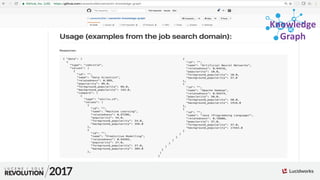
{ "type":"keywords”, "values":[
{ "value":"hive", "relatedness": 0.9765, "popularity":369 },
{ "value":”spark", "relatedness": 0.9634, "popularity":15653 },
{ "value":".net", "relatedness": 0.5417, "popularity":17683 },
{ "value":"bogus_word", "relatedness": 0.0, "popularity":0 },
{ "value":"teaching", "relatedness": -0.1510, "popularity":9923 },
{ "value":"CPR", "relatedness": -0.4012, "popularity":27089 } ] }
Foreground Query: "Hadoop"
Experiment: Data analyst
manually annotated 500
pairs of terms found together
in real query logs as
“relevant” or “not relevant”
Results: SKG removed 78%
of the terms while maintaining
a 95% accuracy at removing
the correct noisy pairs from
the input data.](https://image.slidesharecdn.com/skg-181105051457/85/The-Apache-Solr-Semantic-Knowledge-Graph-30-320.jpg)
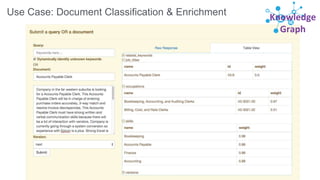















![Graph Query Parser
• Query-time, cyclic aware graph traversal is able to rank documents based on relationships
• Provides controls for depth, filtering of results and inclusion
of root and/or leaves
• Limitations: single node/shard only
Examples:
• http://localhost:8983/solr/graph/query?fl=id,score&
q={!graph from=in_edge to=out_edge}id:A
• http://localhost:8983/solr/my_graph/query?fl=id&
q={!graph from=in_edge to=out_edge
traversalFilter='foo:[* TO 15]'}id:A
• http://localhost:8983/solr/my_graph/query?fl=id&
q={!graph from=in_edge to=out_edge maxDepth=1}foo:[* TO 10]](https://image.slidesharecdn.com/skg-181105051457/85/The-Apache-Solr-Semantic-Knowledge-Graph-57-320.jpg)









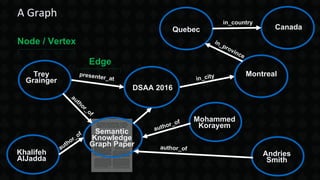
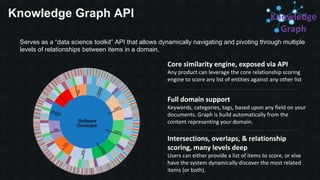
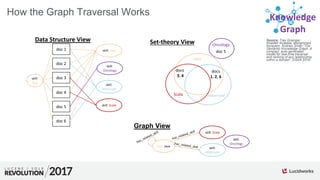
The document discusses the Apache Solr Semantic Knowledge Graph, a tool designed for real-time traversal and ranking of relationships within a domain, enabling advanced functions like semantic search, predictive analytics, and data cleansing. It highlights various use cases, including document summarization and query disambiguation, and emphasizes the challenges of traditional knowledge graphs, which often require explicit modeling of entities and relationships. Additionally, the document outlines the functionalities of the Lucidworks platform, its contributions to open-source Solr, and a variety of applications utilizing machine learning and artificial intelligence.





















































































