Download as PDF, PPTX


![State of the Art
• Significant body of work
in LLMs and testing
• Software Testing with
Large Language Models:
Survey, Landscape, and
Vision (Wang et al.
2023), ArXiv
4
2
f parameters. Such models hold tremendous
ckling complex practical tasks in domains
eration and artistic creation. With their
city and enhanced capabilities, LLMs have
changers in NLP and AI, and are driving
n other fields like coding, software testing.
LMs have been used for various coding
including code generation and code
n [10], [11]. However, there have been
the correctness and reliability of the code
LLMs, as some studies have shown that
ated by LLMs may not always be correct,
eet the expected software requirements. By
hen LLMs are used for software testing
generating test cases or validating the
oftware behavior, the impact of this problem
eaker. This is because the primary goal of
g is to identify issues or problems in the
m, rather than to generate correct code or
oftware requirements. At worst, the only
that the corresponding defects are not
rthermore, in some cases, the seemingly
uts from LLMs may actually be beneficial
er cases in software, and can help uncover](https://image.slidesharecdn.com/briand-forge-2024-240414103515-f88d9b3e/85/Large-Language-Models-for-Test-Case-Evolution-and-Repair-3-320.jpg)





















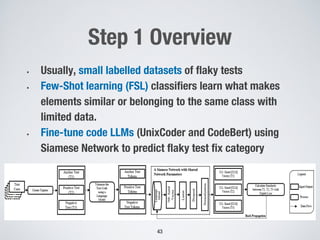


![Step 2 Overview
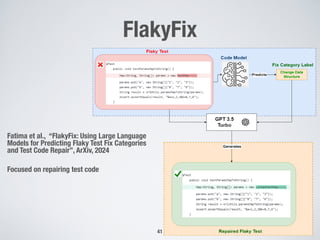
47
Prompt 1 (fix
category label)
Prompt 2 (In-Context
Learning)
10
(41 examples), and
h of these three fix
flaky tests, along with
abels, as prompts for
the model to provide
ven fix category label,
se example tests and
ur prompt explicitly
e fixed test code, ex-
tions. This approach
the model generates
g post-processing. In
GPT model using a
ests. This expansion
odel’s capabilities in
pt
is
de]
ed code
to make
provide
iption.
� Input: Prompt
This test case is
Flaky: [Flaky Code]
This test can be fixed by
changing the following
information in the code:
[Fix Category Label]
Just Provide the full fixed code
of this test case only without
any other text description’
� Output: Generated Output:
[Fixed Flaky Test Code]
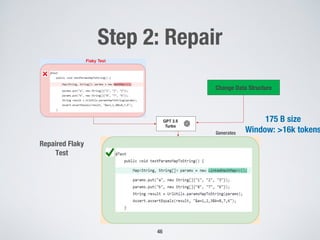
Fig. 6: Flaky test fix using GPT-3.5 Turbo with fix category
label.
� Input: Prompt
This test case is
Flaky: [Flaky Code]
This test can be fixed by
changing the following
information in the code:
[Fix Category Label]
Just Provide the full fixed code
of this test case only without
any other text description’
Here are some Flaky tests
examples, their fixes and fix
category labels: [Examples]
� Output: Generated Output:
[Fixed Flaky Test Code]
Fig. 7: Flaky test fix using GPT-3.5 Turbo with in-context
learning.
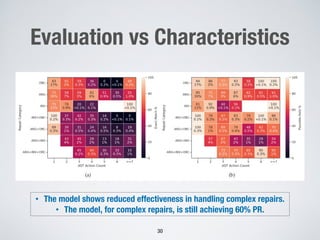
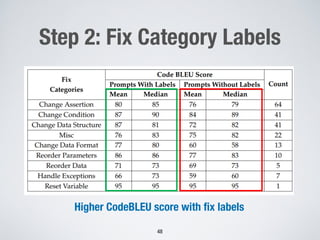
UniXcoder without FSL dem
and similar recall in the Ch
Structure, Handle Exception, C
Parameters categories, with p
87%, and 91%, respectively, ou
approaches. For Reorder Data, a
achieves the highest precision s
incorporating FSL, UniXcoder
call of 88%. Furthermore, Cod
slightly better results for the
83% precision and 67% recall
UniXcoder is not significant. F
UniXcoder with FSL yielded h
cision and 97% recall rates, w
achieved a slightly higher rec
precision of 88%. Finally, for Ch
with FSL outperformed all ot
precision and recall. Howeve
UniXcoder is not significant.
The Change Data Format, Ha
Reorder Data and Change A
easiest for all four approaches
precision score (across all app
88%, and 90%, respectively. T
frequency of common keywor
handling, assert statements, res
ing data (with keywords like ”
case of the Change Data Form
for a long complicated string
function. These strings are eas
because we observed that all
category contain a long compl
updated to remove flakiness. A
strong performance across m
high recall and precision. Ho](https://image.slidesharecdn.com/briand-forge-2024-240414103515-f88d9b3e/85/Large-Language-Models-for-Test-Case-Evolution-and-Repair-41-320.jpg)














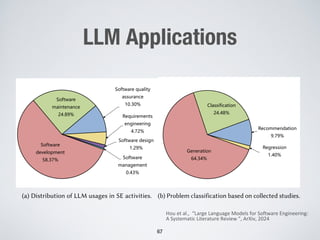

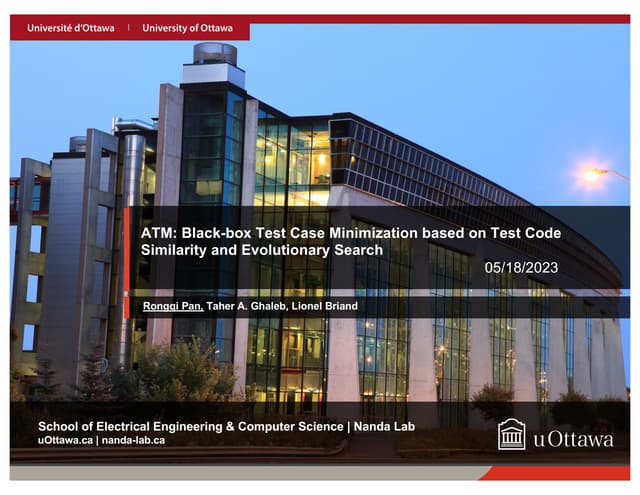
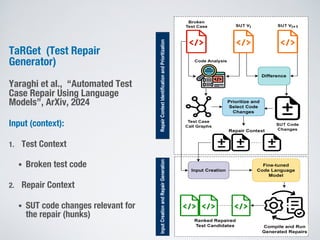
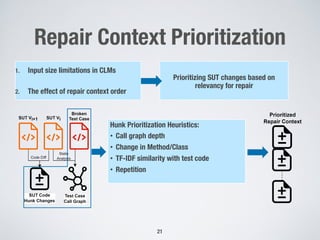
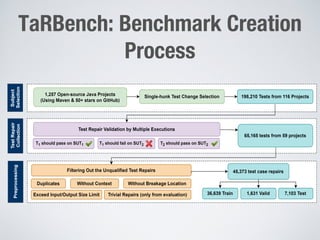
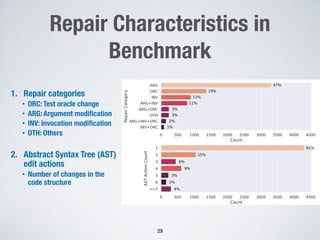
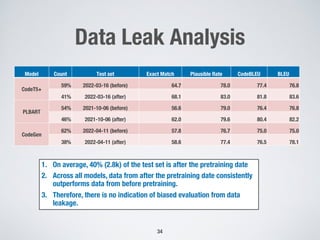
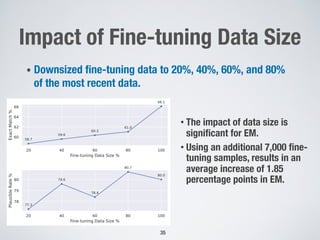
Large language models show promise for test case repair tasks. LLMs can be applied to tasks like test case generation, classification of flaky tests, and test case evolution and repair. The paper presents TaRGet, a framework that uses LLMs for automated test case repair. TaRGet takes as input a broken test case and code changes to the system under test, and outputs a repaired test case. Evaluation shows TaRGet achieves over 80% plausible repair accuracy. The paper analyzes repair characteristics, evaluates different LLM and input/output formats, and examines the impact of fine-tuning data size on performance.