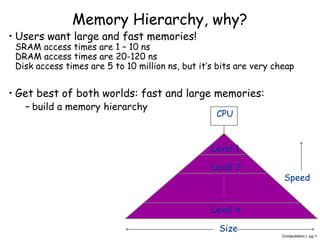
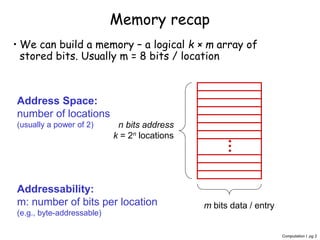
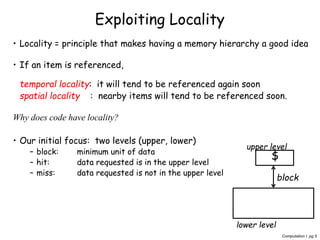
The document discusses memory hierarchy and caching techniques. It begins by explaining the need for a memory hierarchy due to differing access times of memory technologies like SRAM, DRAM, and disk. It then covers concepts like cache hits, misses, block size, direct mapping, set associativity, compulsory misses, capacity misses, and conflict misses. Finally, it discusses using a second-level cache to reduce memory access times by capturing misses from the first-level cache.

















![Computation I pg 23
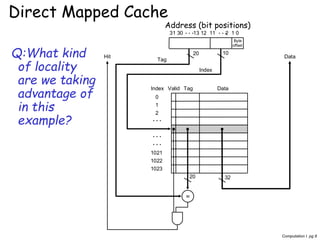
Direct Mapped
Block address Cache Block
0 0 mod 4=0
6 6 mod 4=2
8 8 mod 4=0
Address of
memory block
Hit or
miss
Location
0
Location
1
Location
2
Location
3
0 miss Mem[0]
8 miss Mem[8]
0 miss Mem[0]
6 miss Mem[0] Mem[6]
8 miss Mem[8] Mem[6]
Coloured = new entry = miss](https://image.slidesharecdn.com/ecuvacltscrj3tl4c3q9-signature-f4575690e230540ef9f794b14004cd87315948d538341dae22f563b9573c5543-poli-160505165621/85/Cache-recap-23-320.jpg)
![Computation I pg 24
2-way Set Associative:
2 sets
Block address Cache Block
0 0 mod 2=0
6 6 mod 2=0
8 8 mod 2=0
Address of
memory block
Hit or
miss
SET 0
entry 0
SET 0
entry 1
SET 1
entry 0
SET 1
entry 1
0 Miss Mem[0]
8 Miss Mem[0] Mem[8]
0 Hit Mem[0] Mem[8]
6 Miss Mem[0] Mem[6]
8 Miss Mem[8] Mem[6]
LEAST RECENTLY USED BLOCK
(so all in set/location 0)](https://image.slidesharecdn.com/ecuvacltscrj3tl4c3q9-signature-f4575690e230540ef9f794b14004cd87315948d538341dae22f563b9573c5543-poli-160505165621/85/Cache-recap-24-320.jpg)
![Computation I pg 25
Fully associative
(4 way assoc., 1 set)
Address of
memory block
Hit or
miss
Block 0 Block 1 Block 2 Block 3
0 Miss Mem[0]
8 Miss Mem[0] Mem[8]
0 Hit Mem[0] Mem[8]
6 Miss Mem[0] Mem[8] Mem[6]
8 Hit Mem[0] Mem[8] Mem[6]](https://image.slidesharecdn.com/ecuvacltscrj3tl4c3q9-signature-f4575690e230540ef9f794b14004cd87315948d538341dae22f563b9573c5543-poli-160505165621/85/Cache-recap-25-320.jpg)














































































































