Downloaded 250 times

















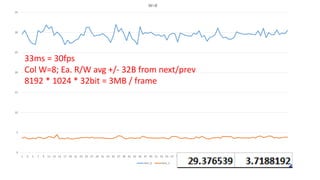
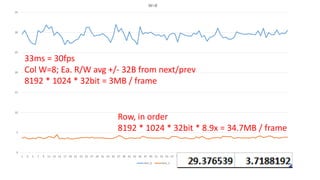
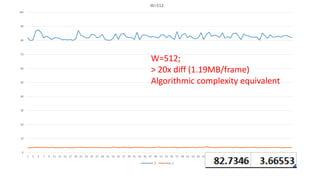
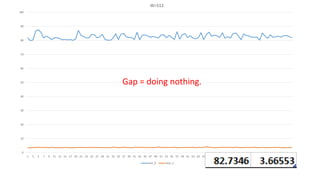




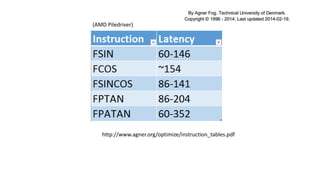



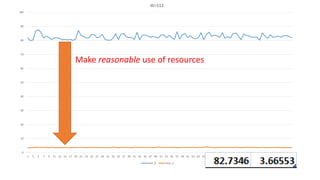
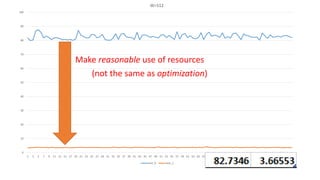





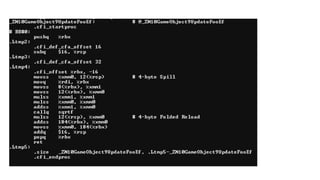
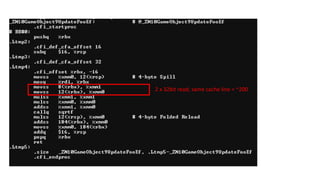
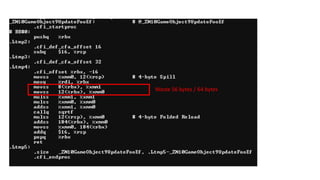
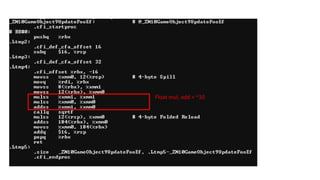
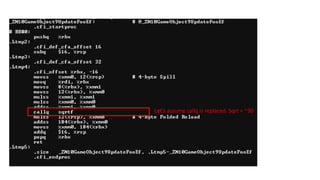
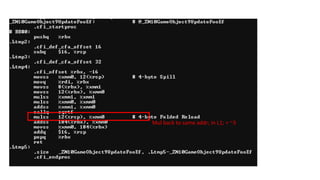
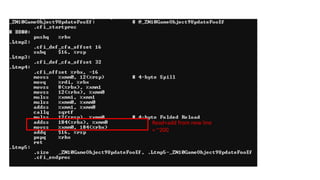
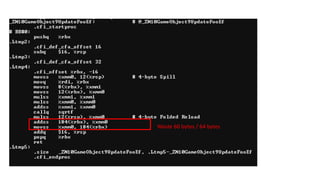
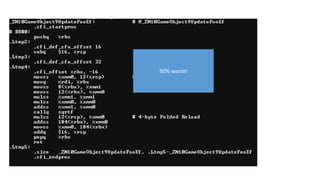
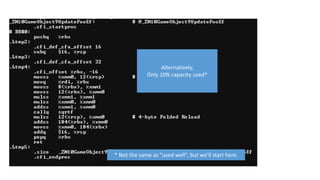
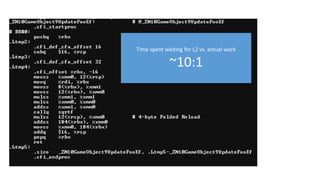
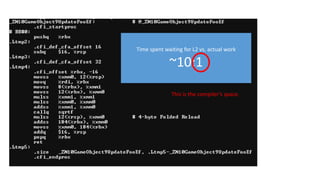
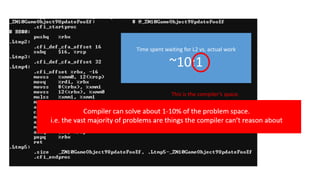


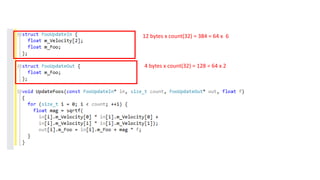
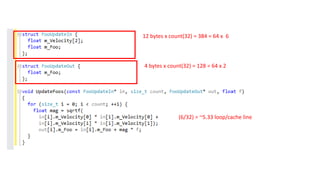
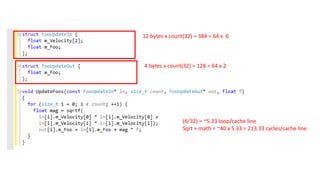
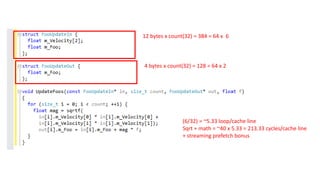

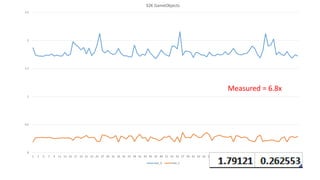






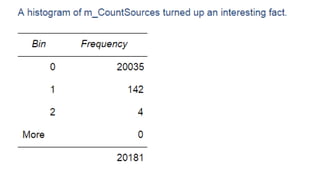
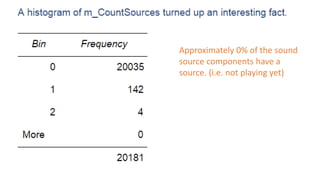


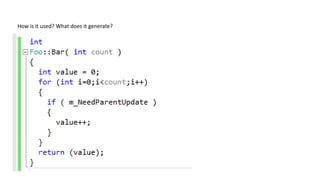

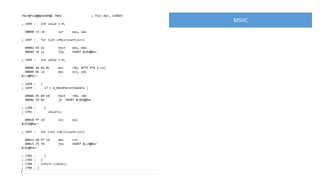
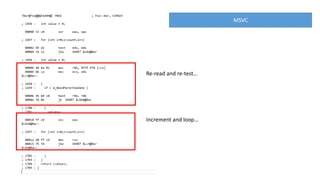
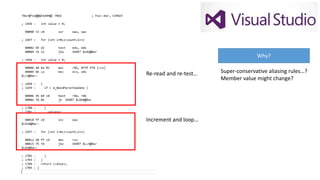








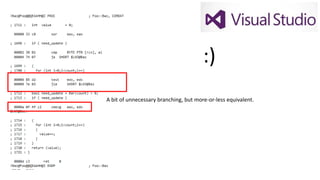


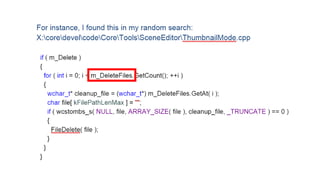
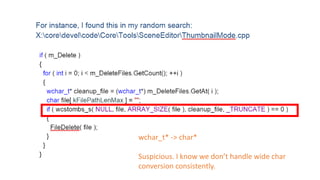
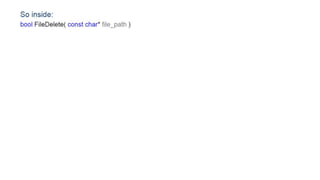


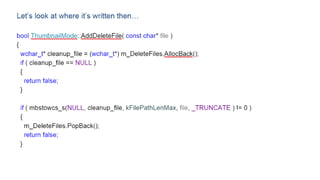
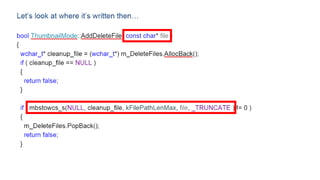














The document discusses approaches to optimizing resource usage in programming, particularly through effective tool utilization and identifying bottlenecks. It emphasizes the importance of both preparation and detailed problem-solving, noting that compilers can only perform mediocre optimizations without careful consideration of the code structure. Additionally, it provides practical tips for analyzing data access patterns and avoiding redundant computations to enhance performance.













































































