Downloaded 11 times





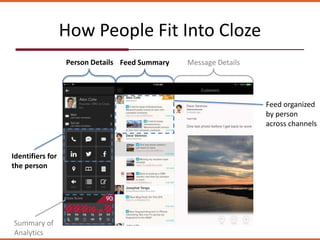
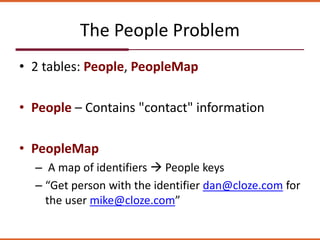










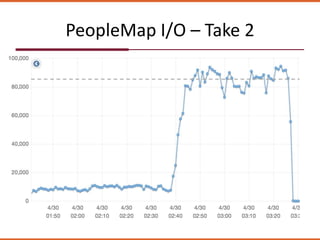
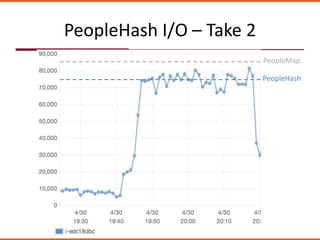

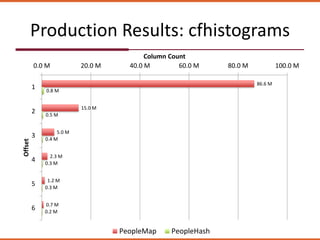
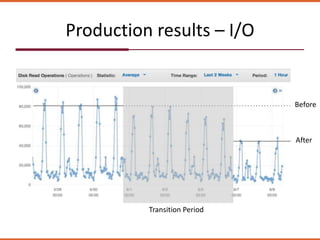


The document discusses how the design of the 'peoplemap' and proposed 'peoplehash' tables in a Cassandra database affects performance, particularly in terms of memory and I/O utilization. It presents comparative tests showing that 'peoplemap' has faster randomized read times than 'peoplehash', despite aiming to reduce memory footprint significantly. The conversion process is ongoing, aiming for a more efficient use of resources while maintaining performance.















































