Downloaded 838 times



























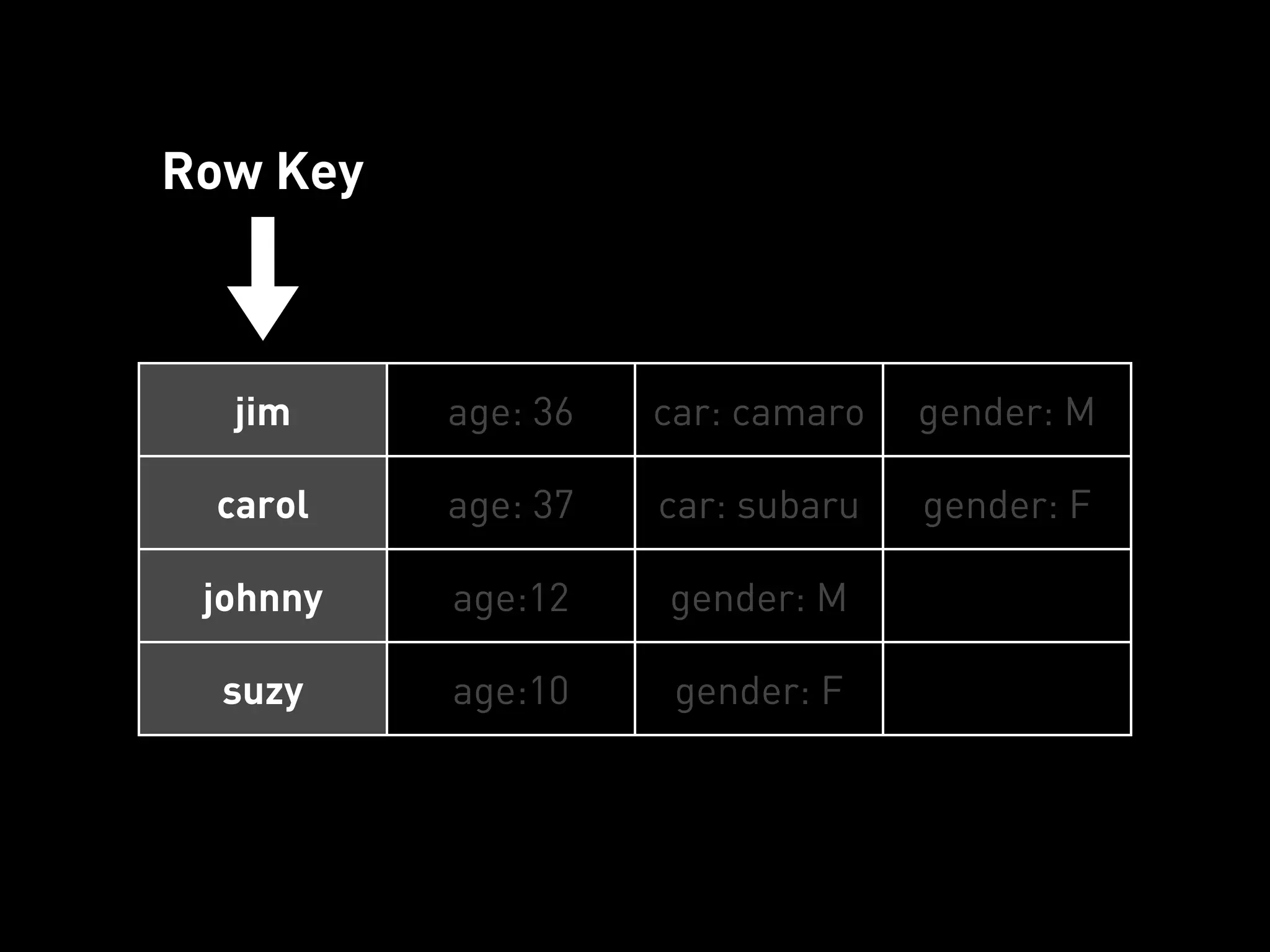





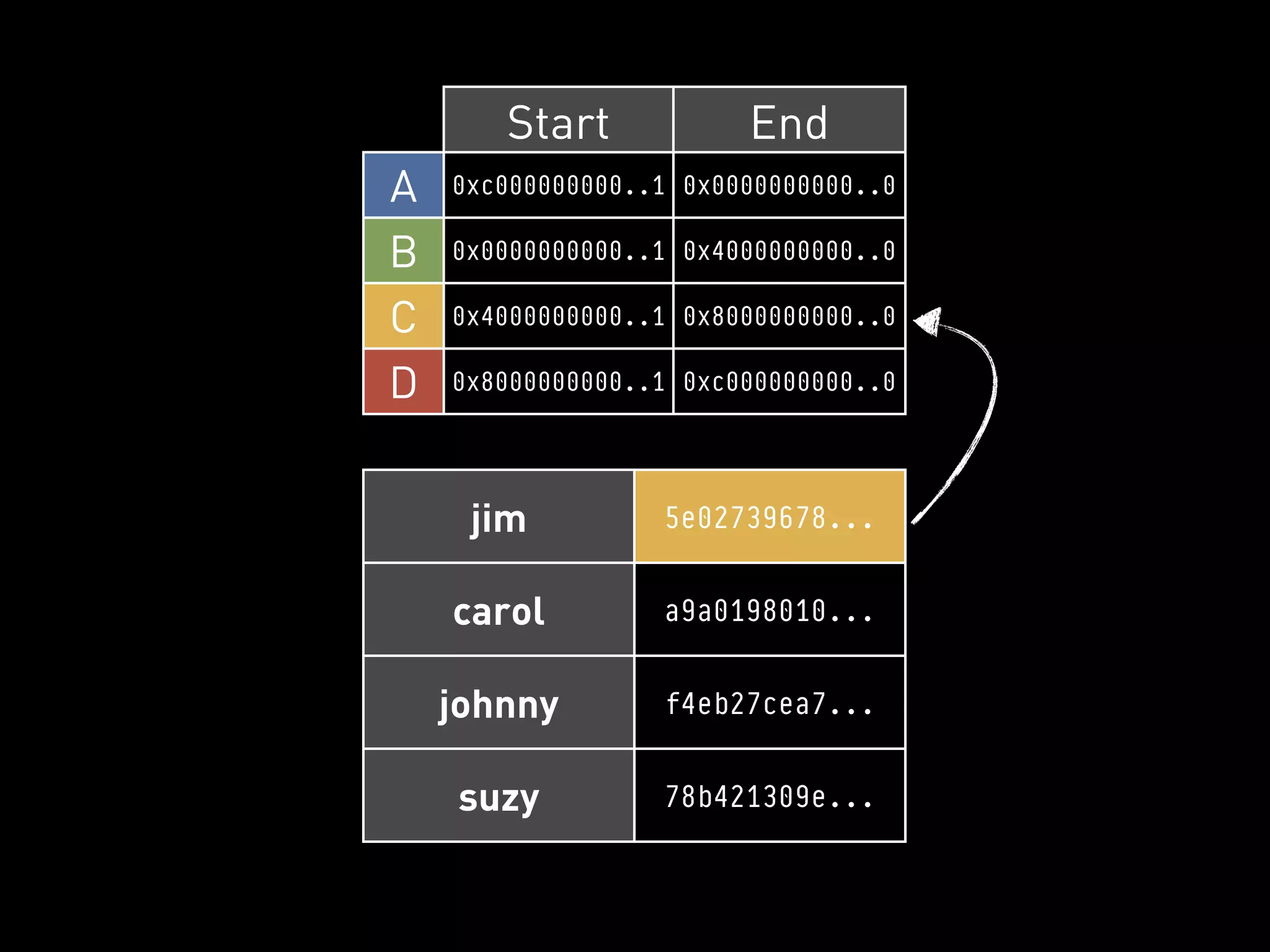


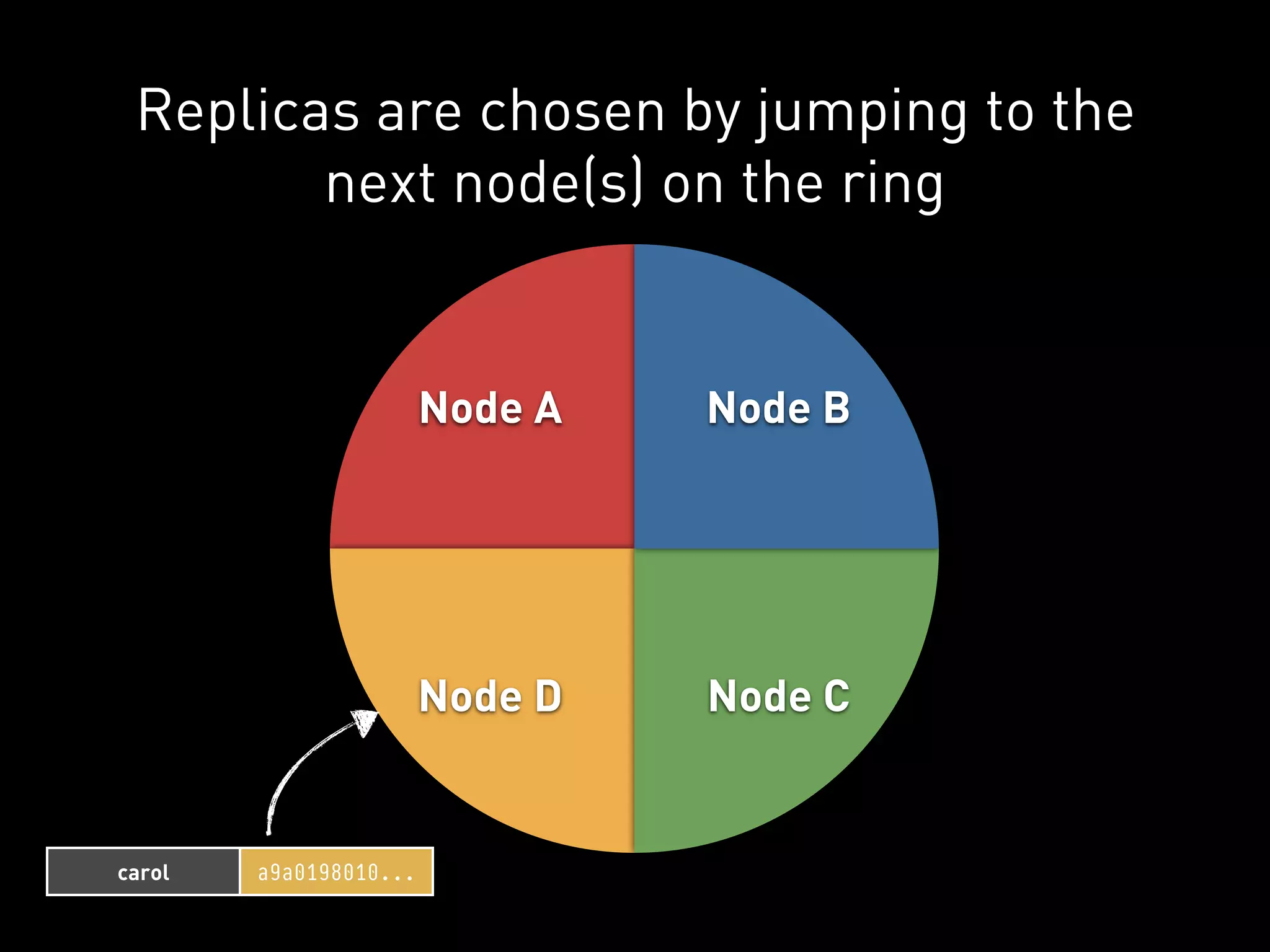
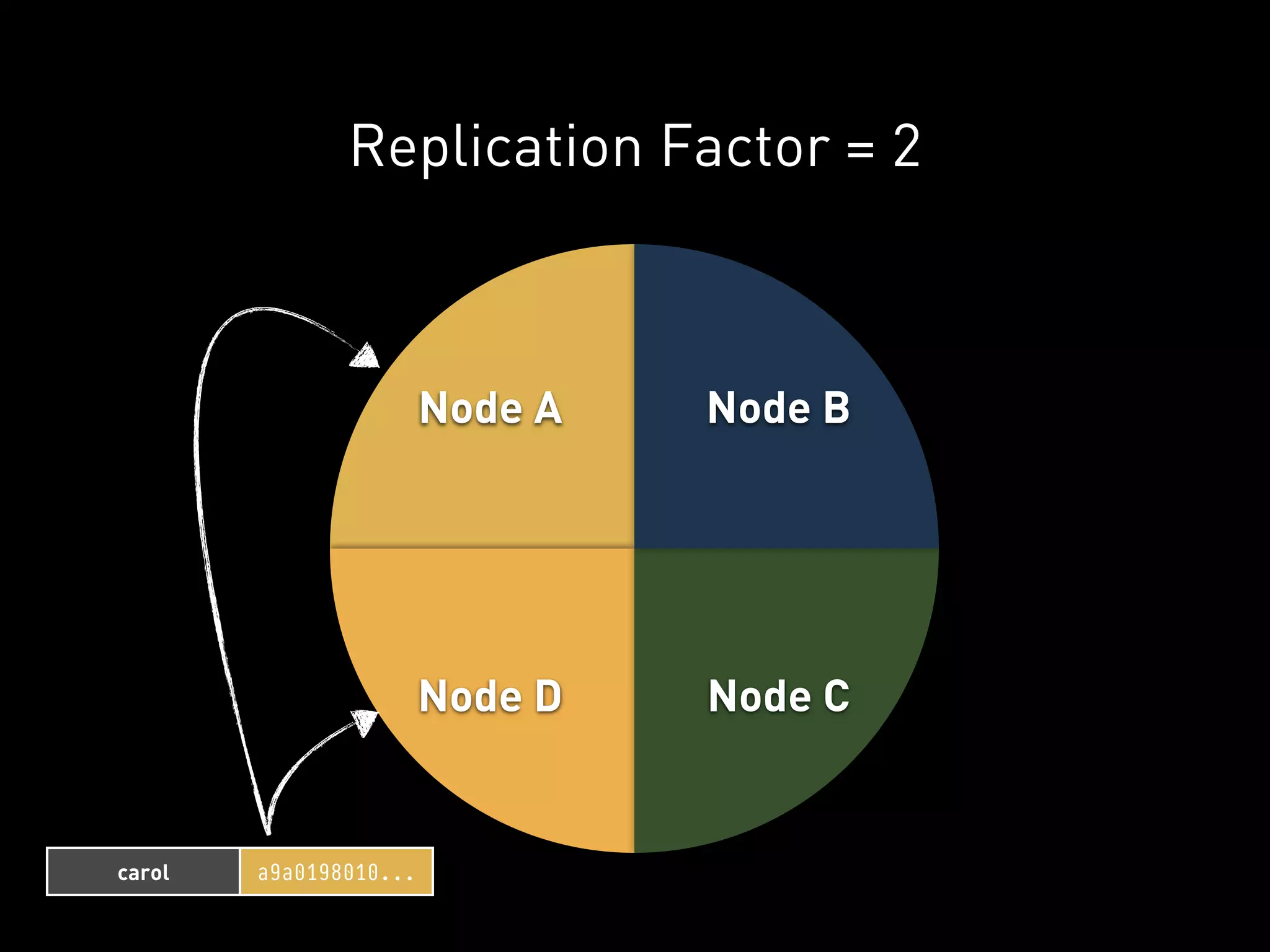
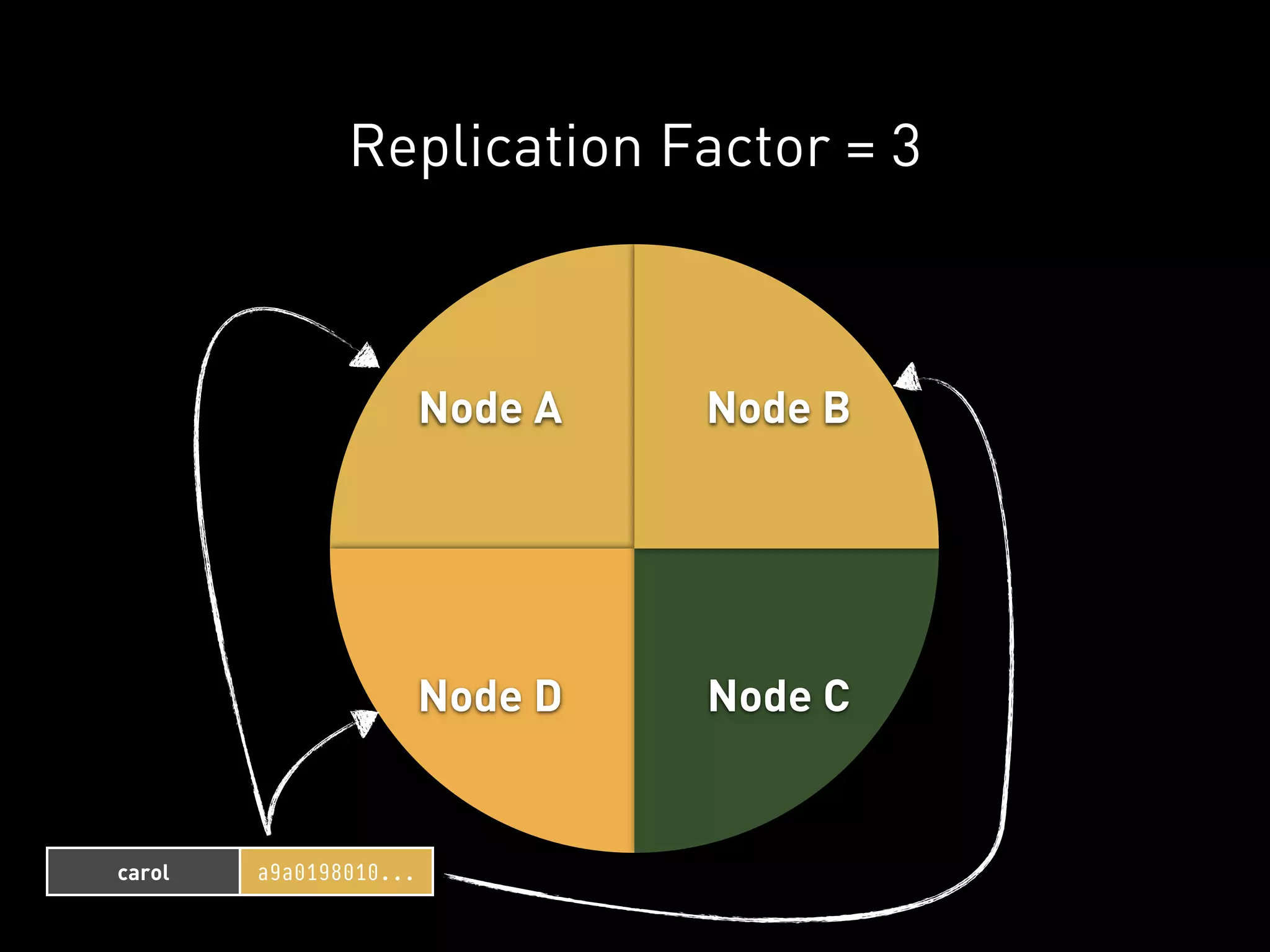















![PYCASSA
CREATE A CONNECTION
>>> pool = pycassa.ConnectionPool(“Keyspace”,
server_list=[“192.168.1.1”])
Moar servers here will distribute
this client’s load over multiple
nodes in the cluster.](https://image.slidesharecdn.com/2011-11-21-mempy-cassandra-rbranson-111122005016-phpapp01/75/How-Do-I-Cassandra-70-2048.jpg)


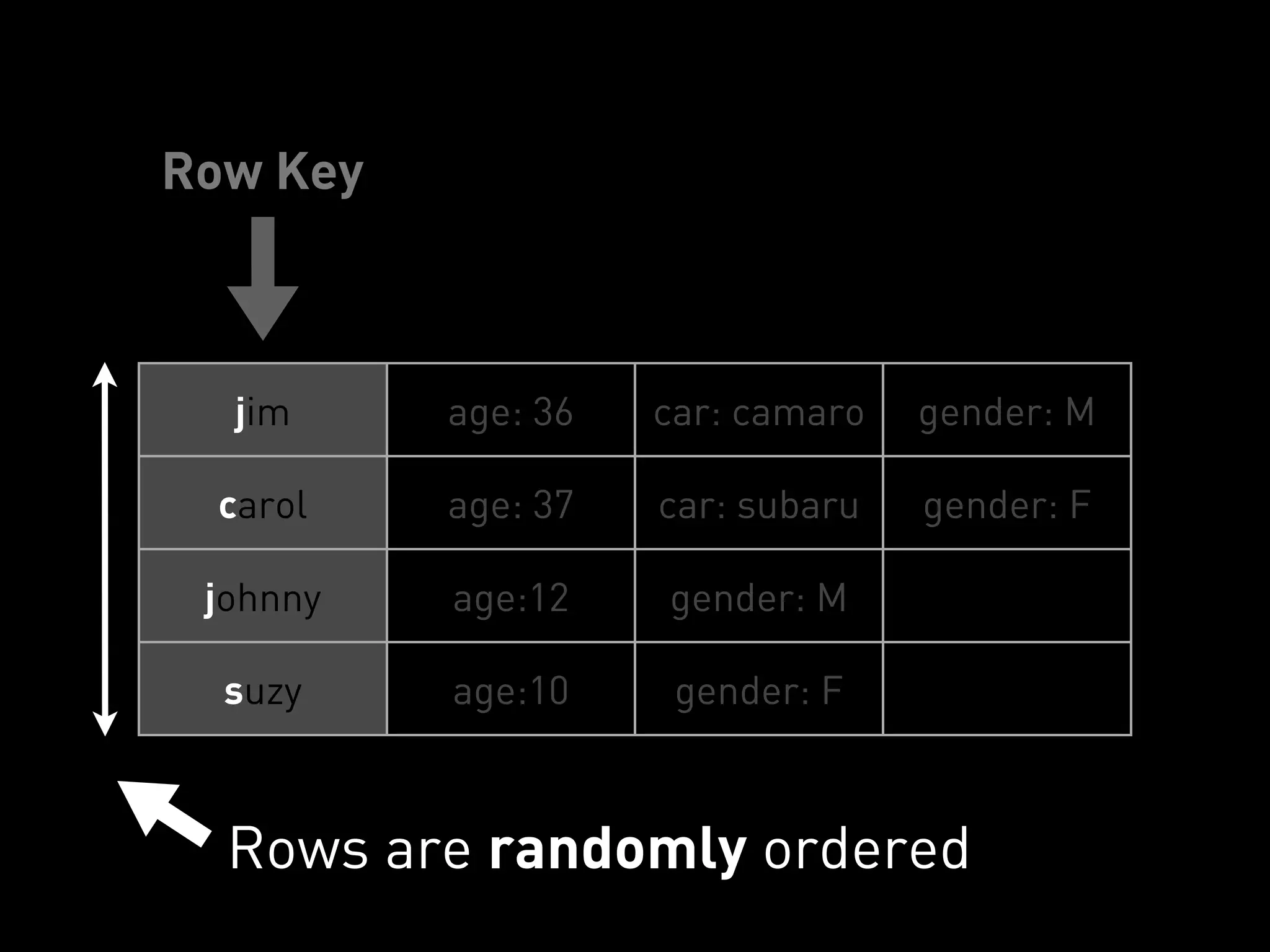
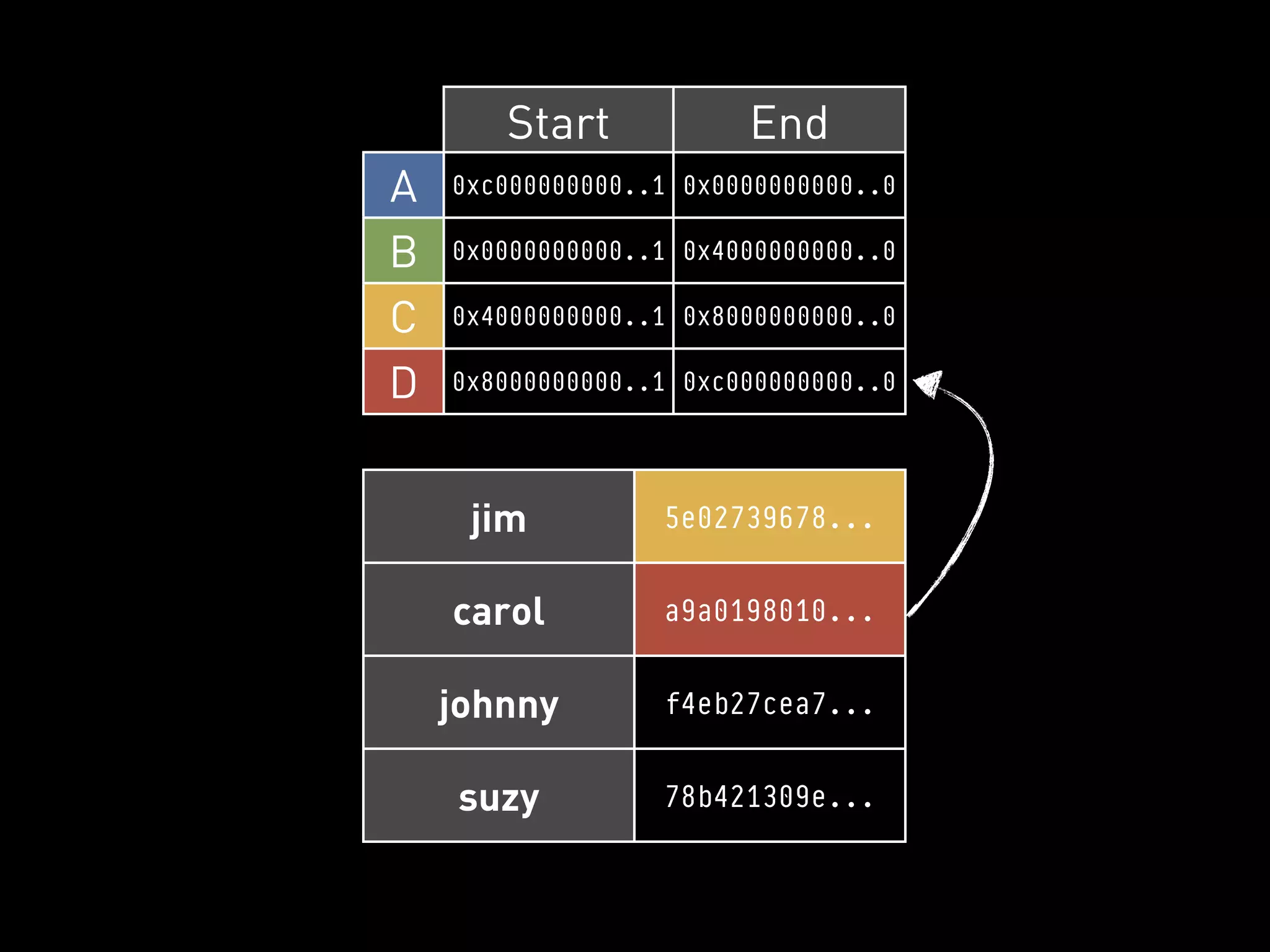
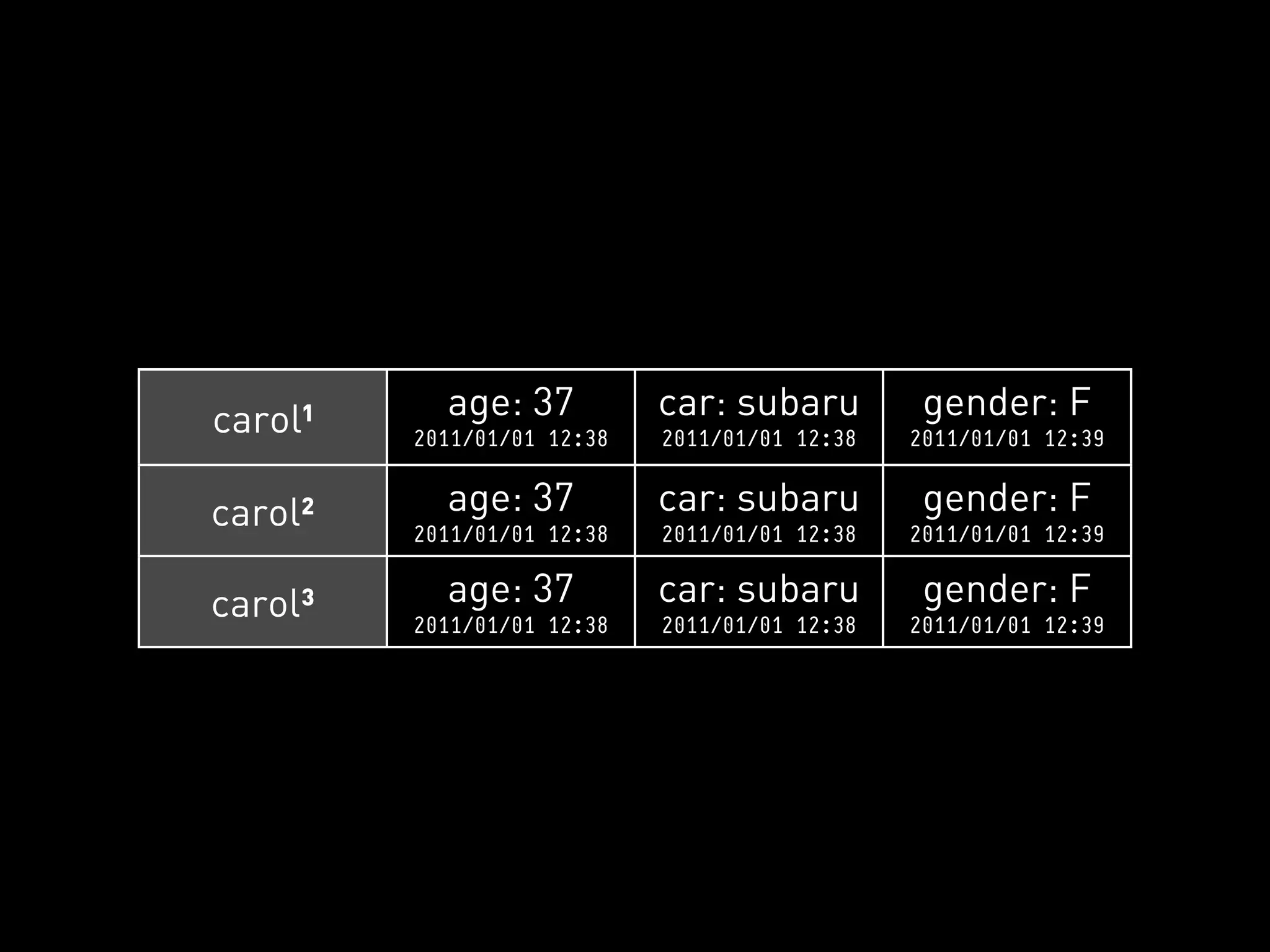
![PYCASSA
GET SPECIFIC COLUMNS
Row Key Column Names
>>> cf.get(“carol”, columns=[“age”, “gender”])
{ “age”: “37”, “gender”: “F” }](https://image.slidesharecdn.com/2011-11-21-mempy-cassandra-rbranson-111122005016-phpapp01/75/How-Do-I-Cassandra-73-2048.jpg)



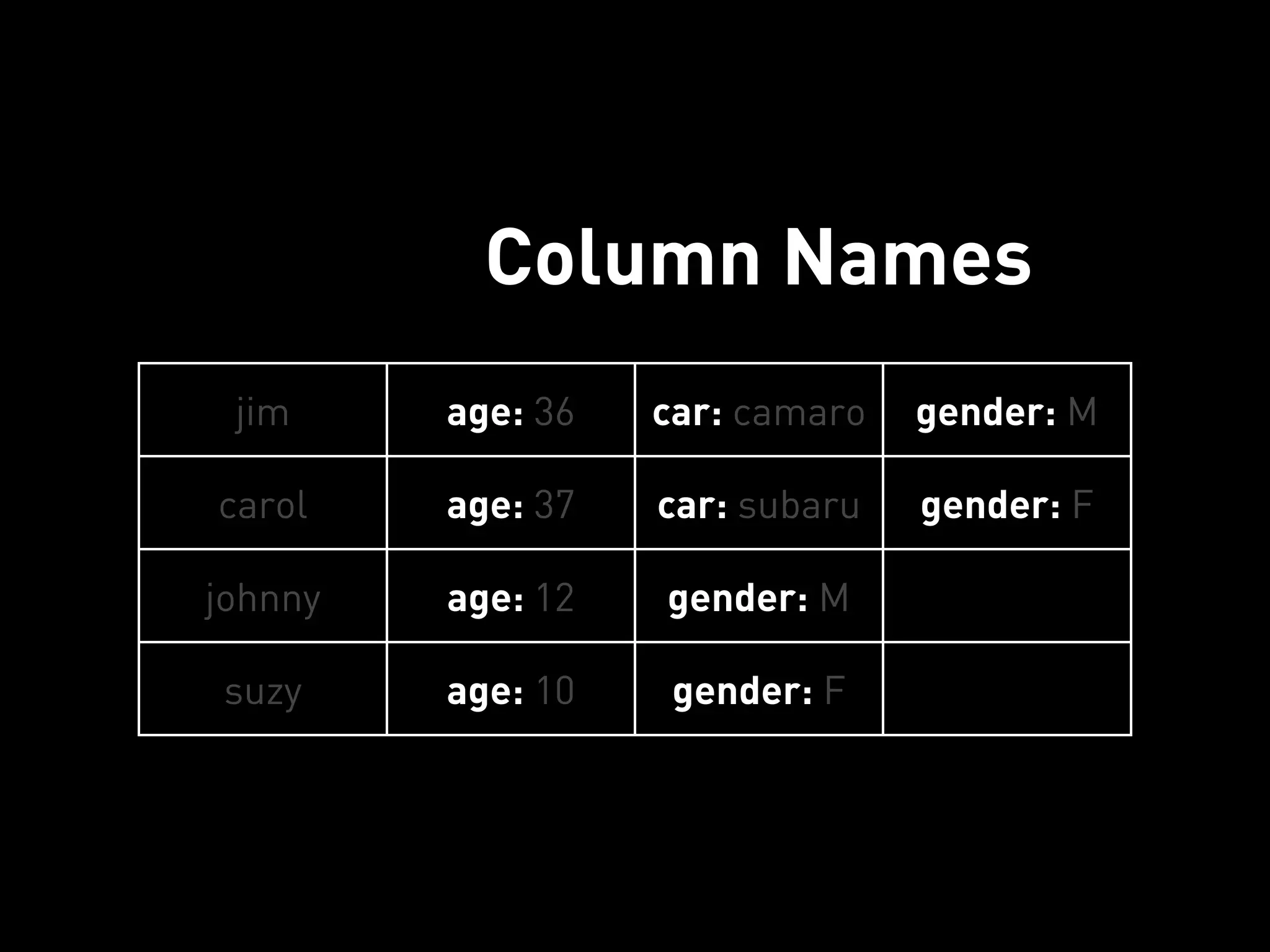
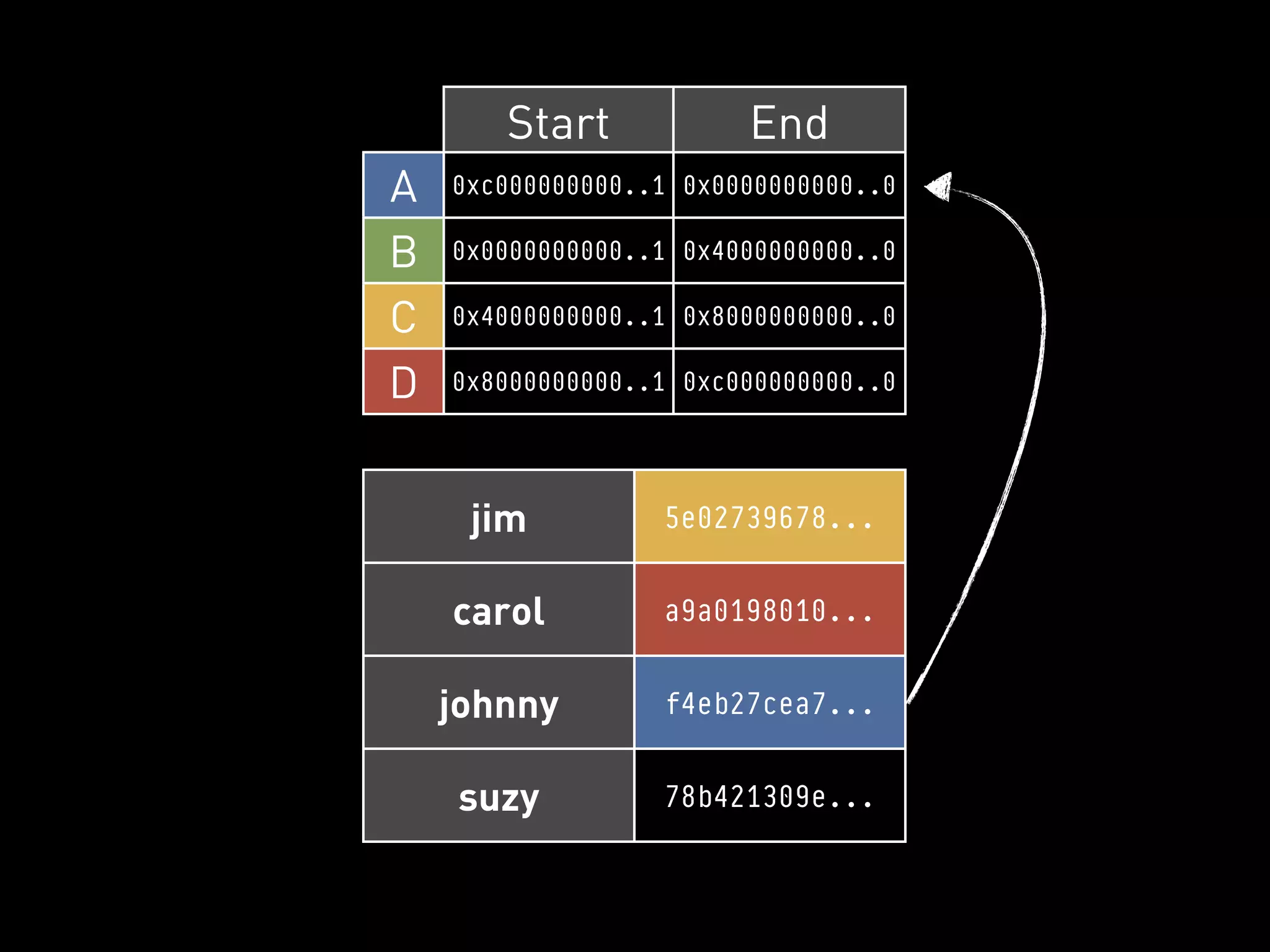
![PYCASSA
DELETE A COLUMN
Column Names
>>> cf.remove(“carol”, columns=[“car”])
Row Key](https://image.slidesharecdn.com/2011-11-21-mempy-cassandra-rbranson-111122005016-phpapp01/75/How-Do-I-Cassandra-77-2048.jpg)
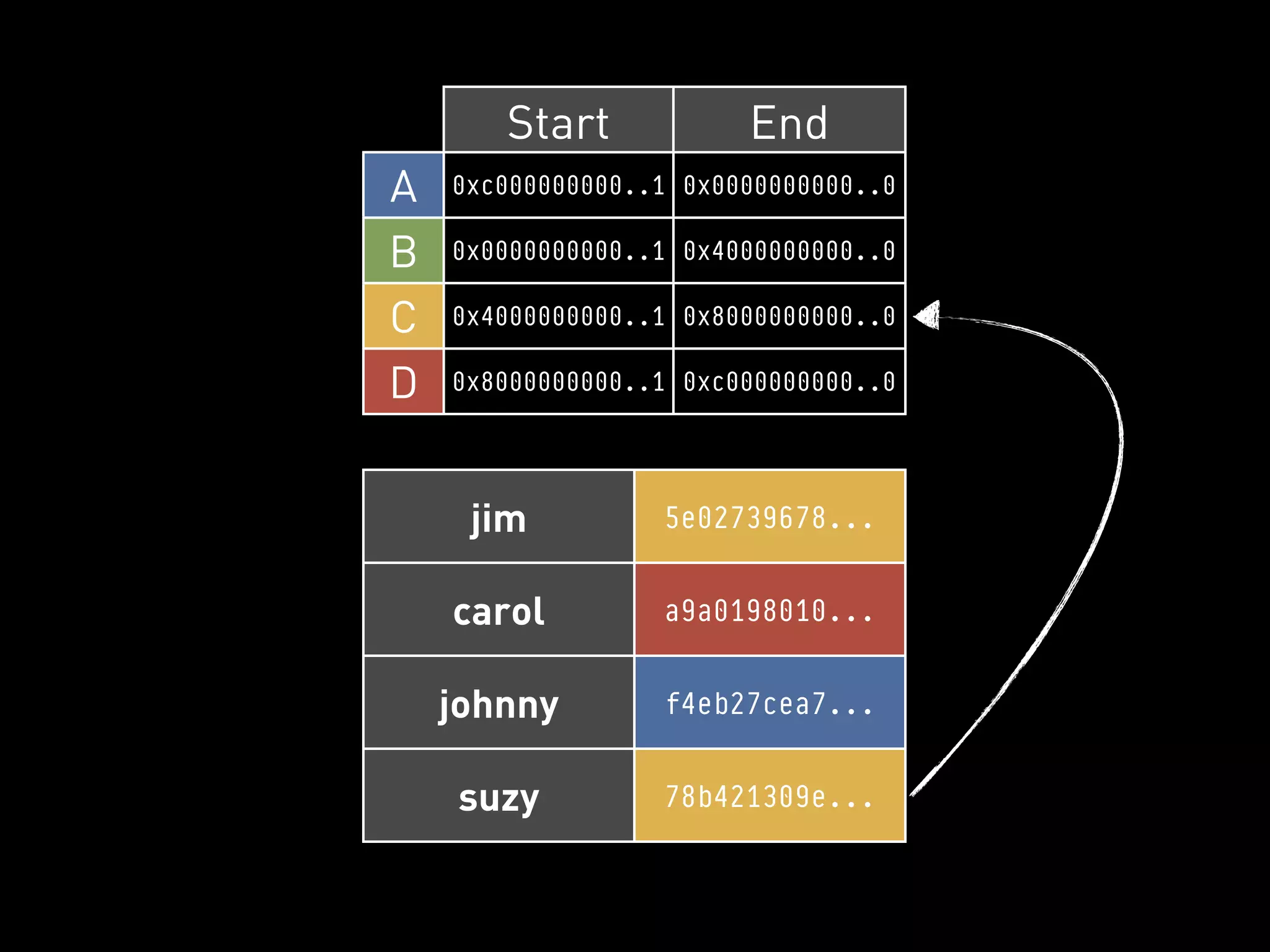
![PYCASSA
CUSTOM TIMESTAMPS
• Default is GMT timestamp
• Overridden for inserts & removes
• Per-CF generator function can be
specified. Insert beats delete!
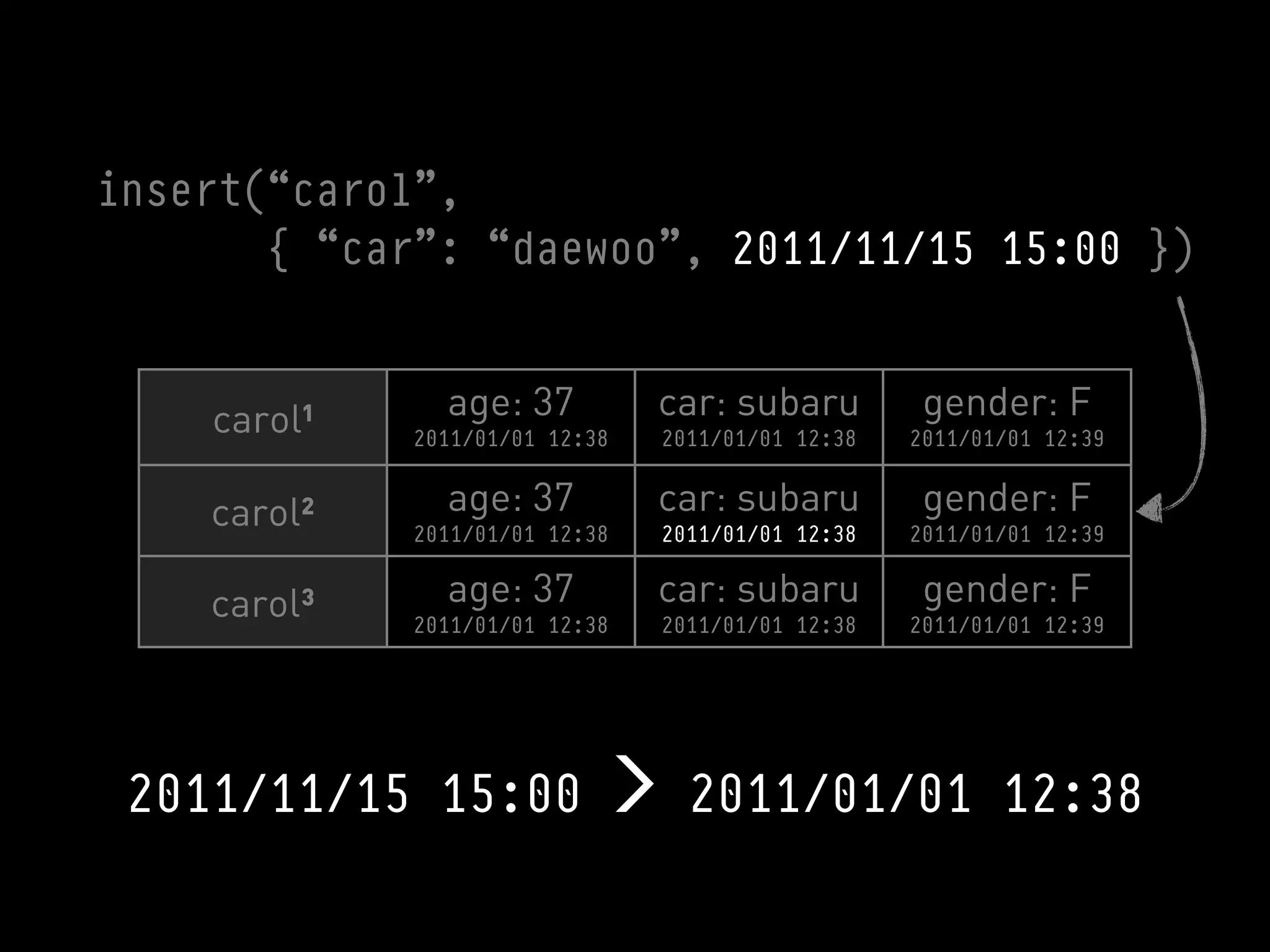
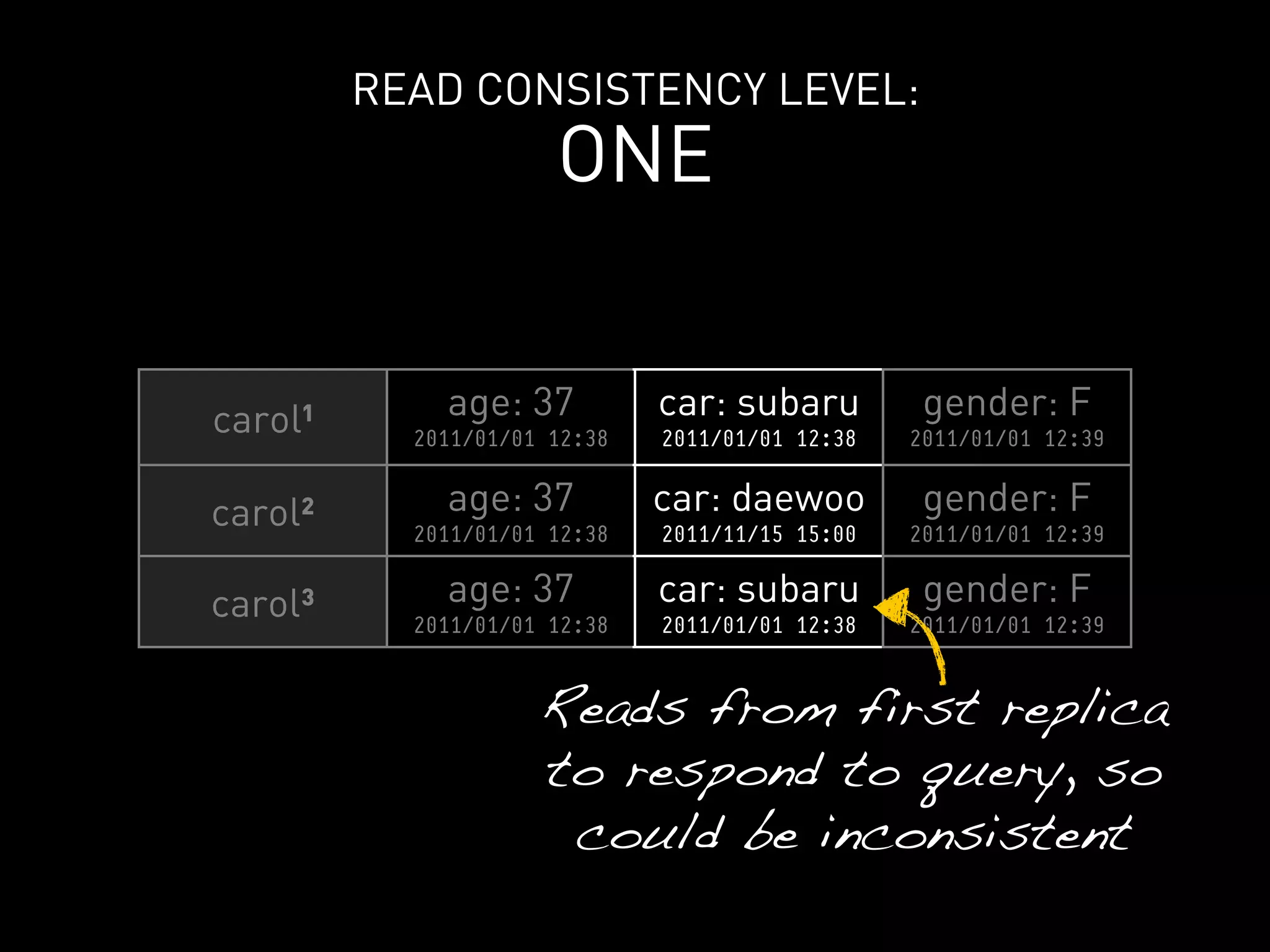
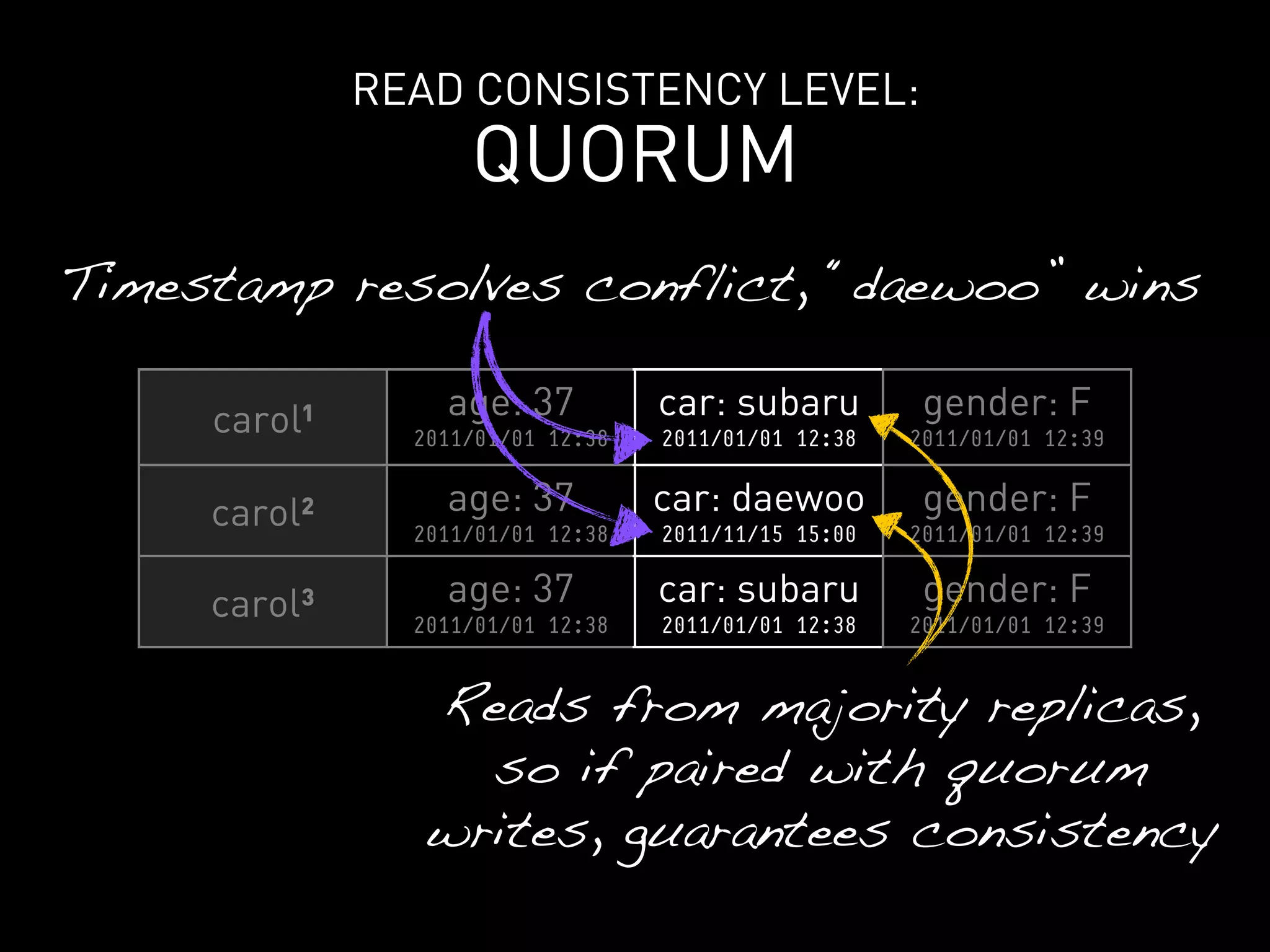
>>> cf.insert(“carol”, { “car”: “subaru” },
timestamp=10000001)
>>> cf.remove(“carol”, columns=[“car”],
timestamp=10000000)](https://image.slidesharecdn.com/2011-11-21-mempy-cassandra-rbranson-111122005016-phpapp01/75/How-Do-I-Cassandra-78-2048.jpg)








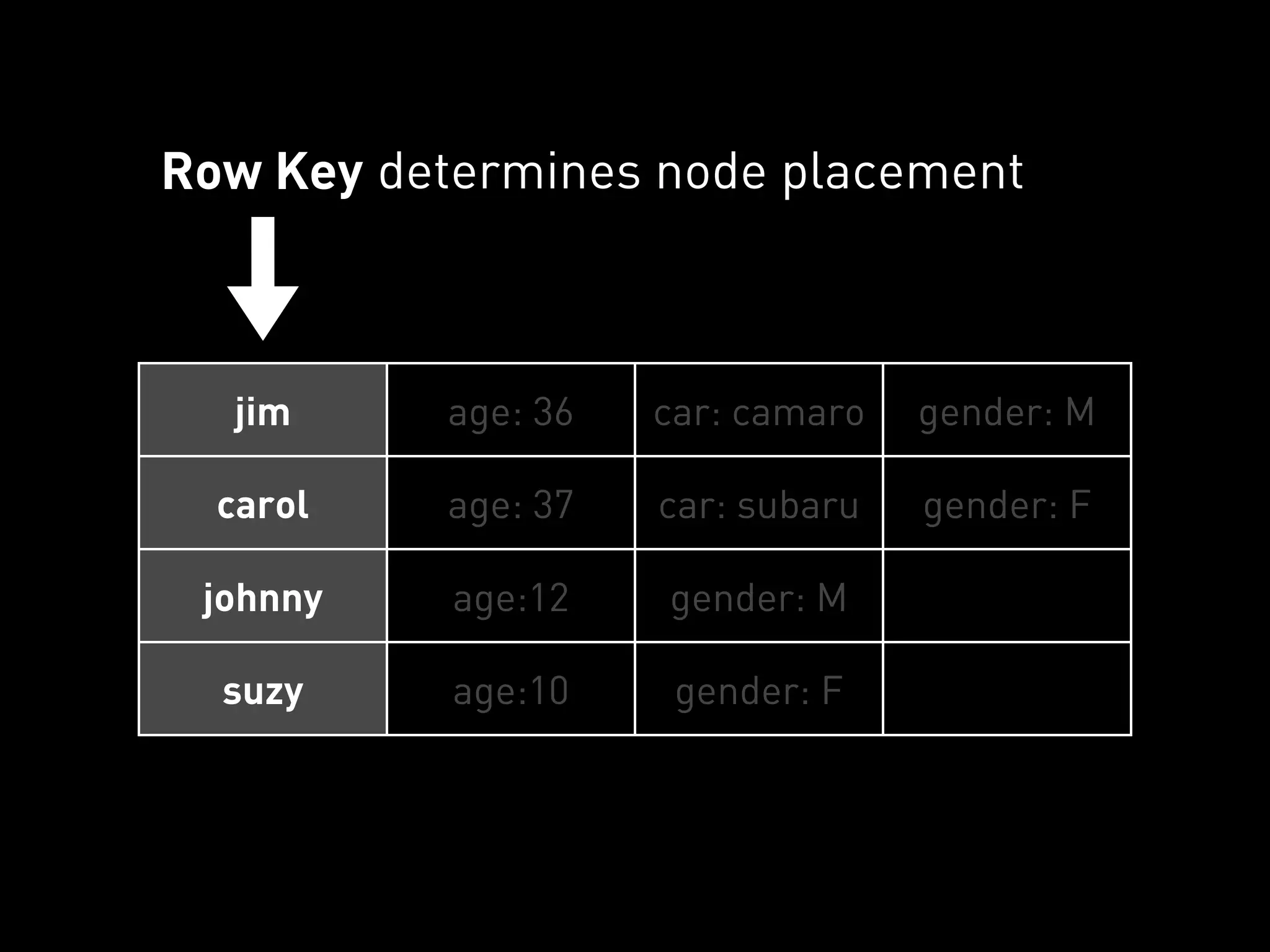
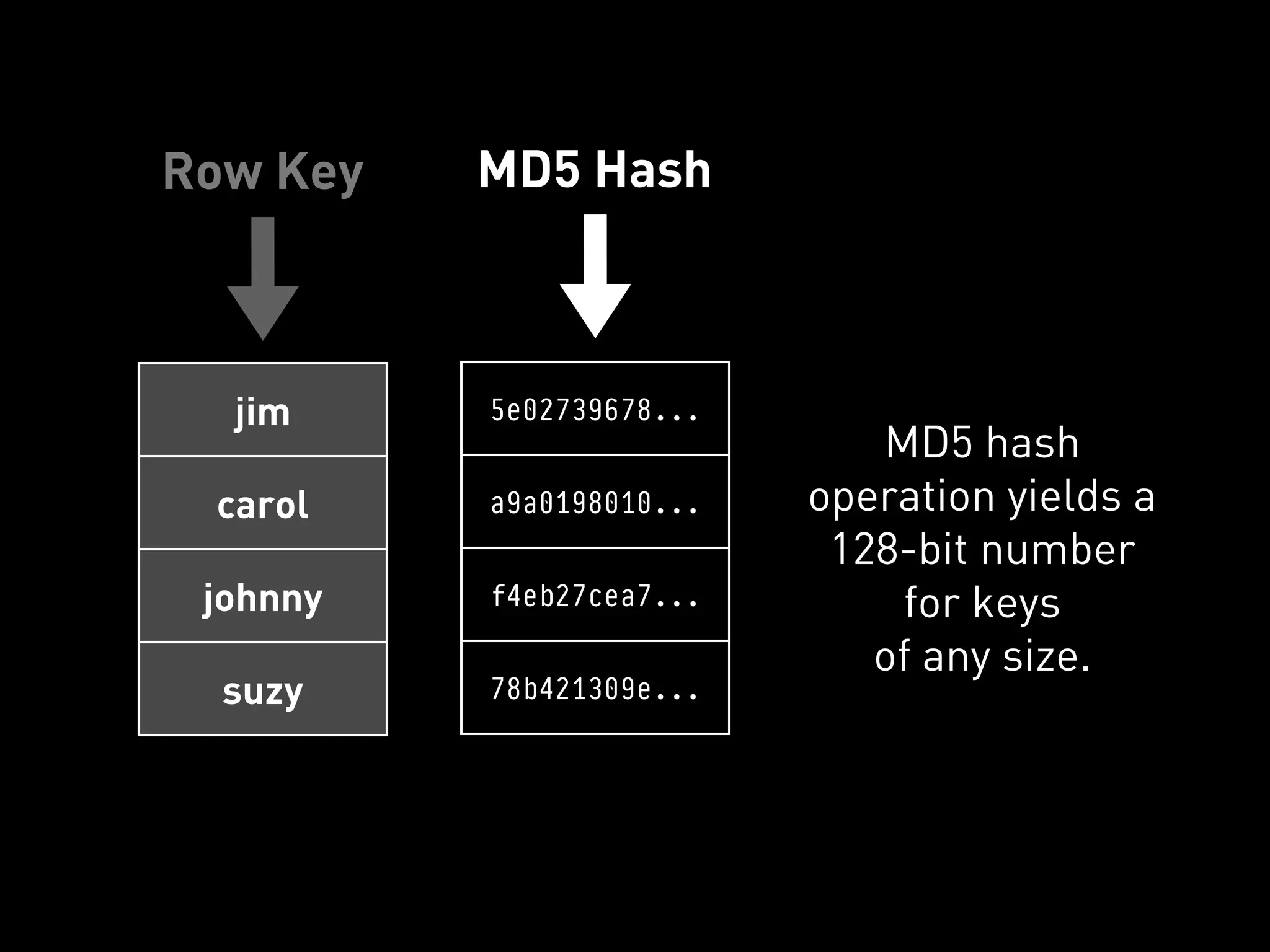
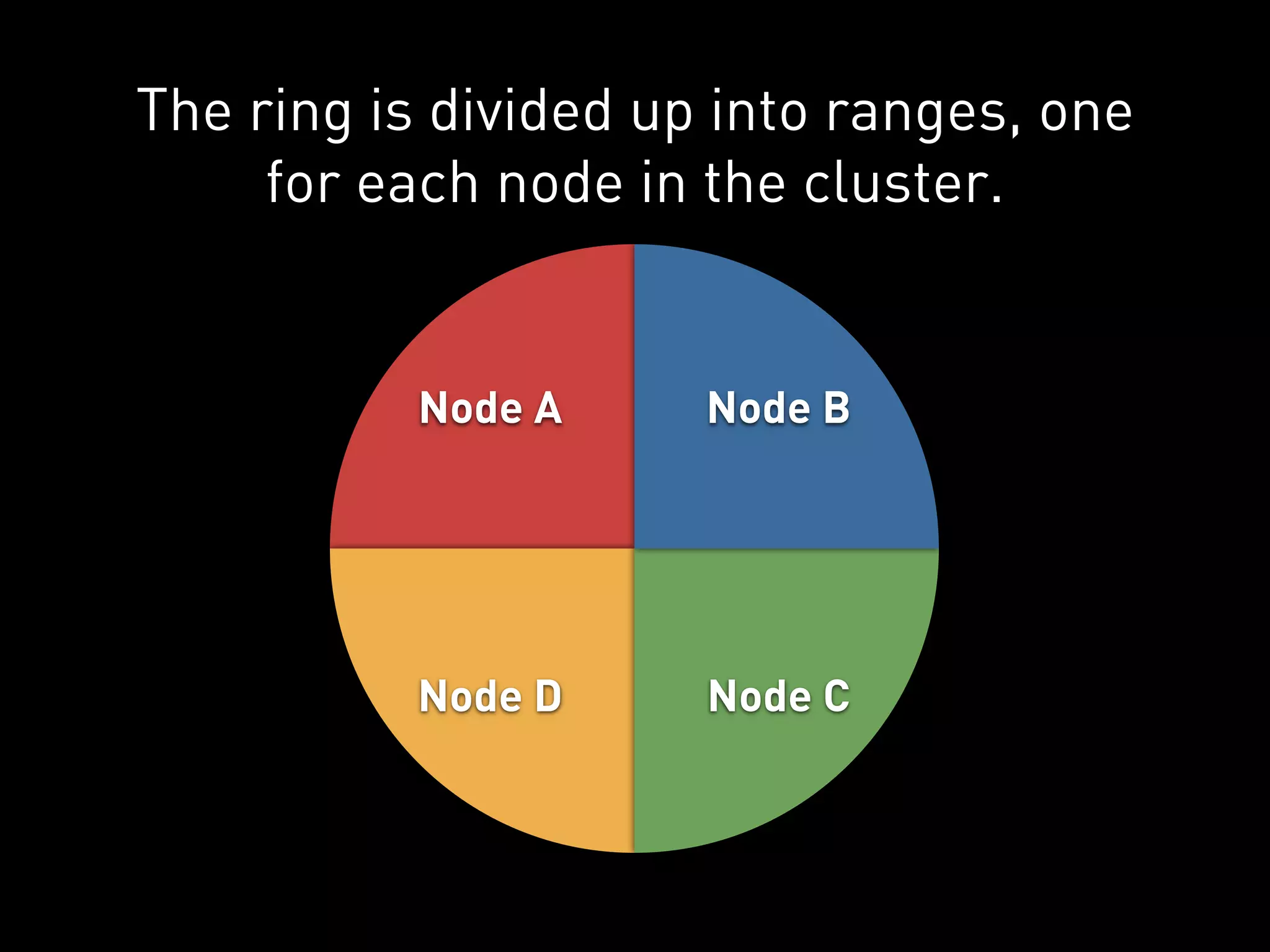
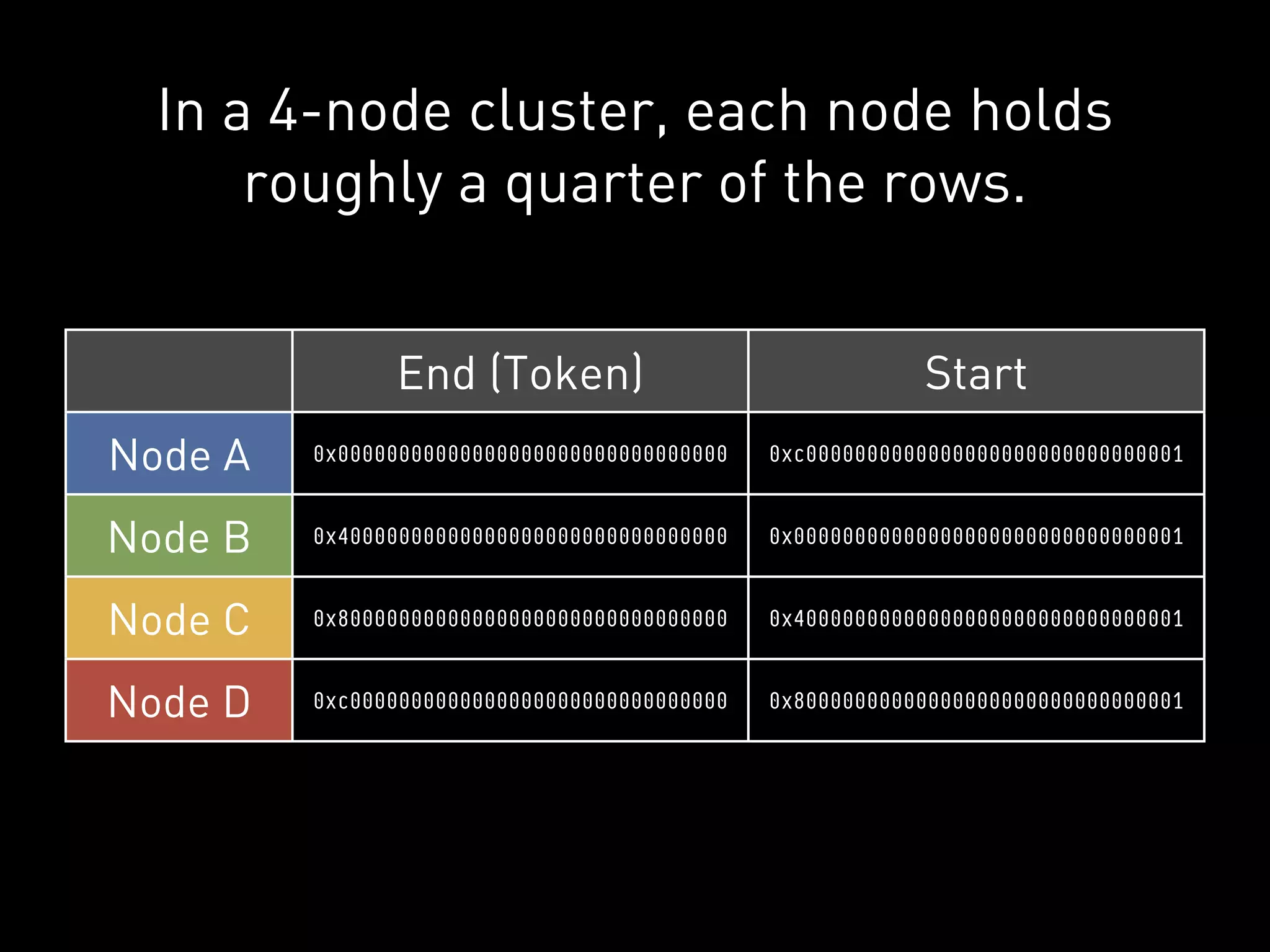
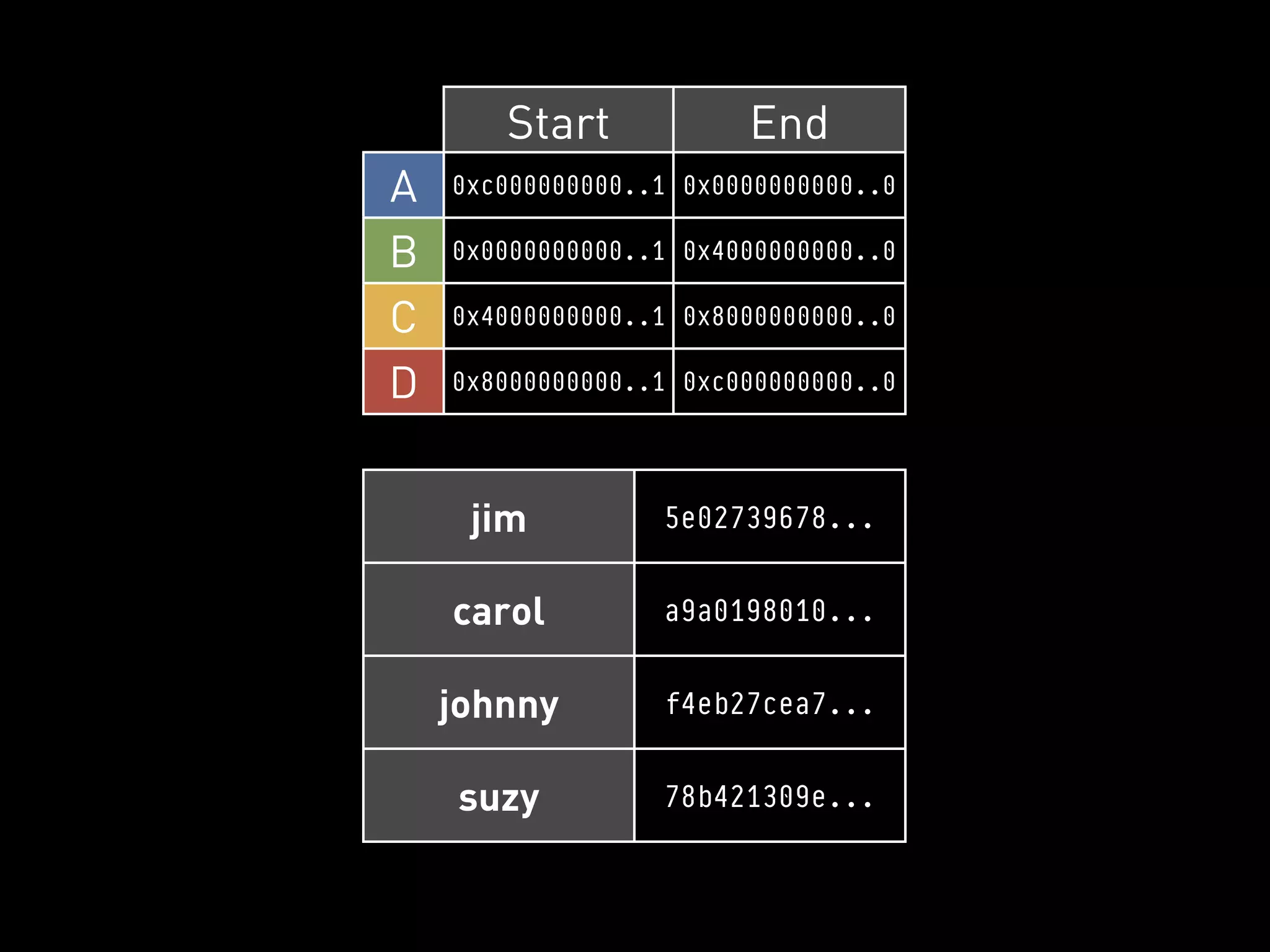
The document provides an overview of Cassandra and how to use it. It discusses that Cassandra is a distributed database that scales out across commodity servers and remains available even during failures. It also covers that Cassandra uses a column-oriented data model and partitions data by row key across nodes, with configurable replication for high availability. The document recommends Cassandra for workloads where availability is critical and provides examples of how companies like Reddit and UrbanAirship use it.



























































![[DevFest Strasbourg 2025] - NodeJs Can do that !!](https://cdn.slidesharecdn.com/ss_thumbnails/devfeststrasbourg2025-nodejscandothat-251127142731-da65b6fd-thumbnail.jpg?width=640&height=640&fit=bounds)






![[BDD 2025 - Mobile Development] Crafting Immersive UI with E2E and AGSL Shade...](https://cdn.slidesharecdn.com/ss_thumbnails/md-craftingimmersiveuiwithe2eandagslshaderveronicaputrianggraini-251124030840-0c677f44-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] PHP in AI Age: The Laravel Way. (Rizqy Hi...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-phpinaiagethelaravelway-251125012602-ef9d330e-thumbnail.jpg?width=640&height=640&fit=bounds)










