Download as PDF, PPTX







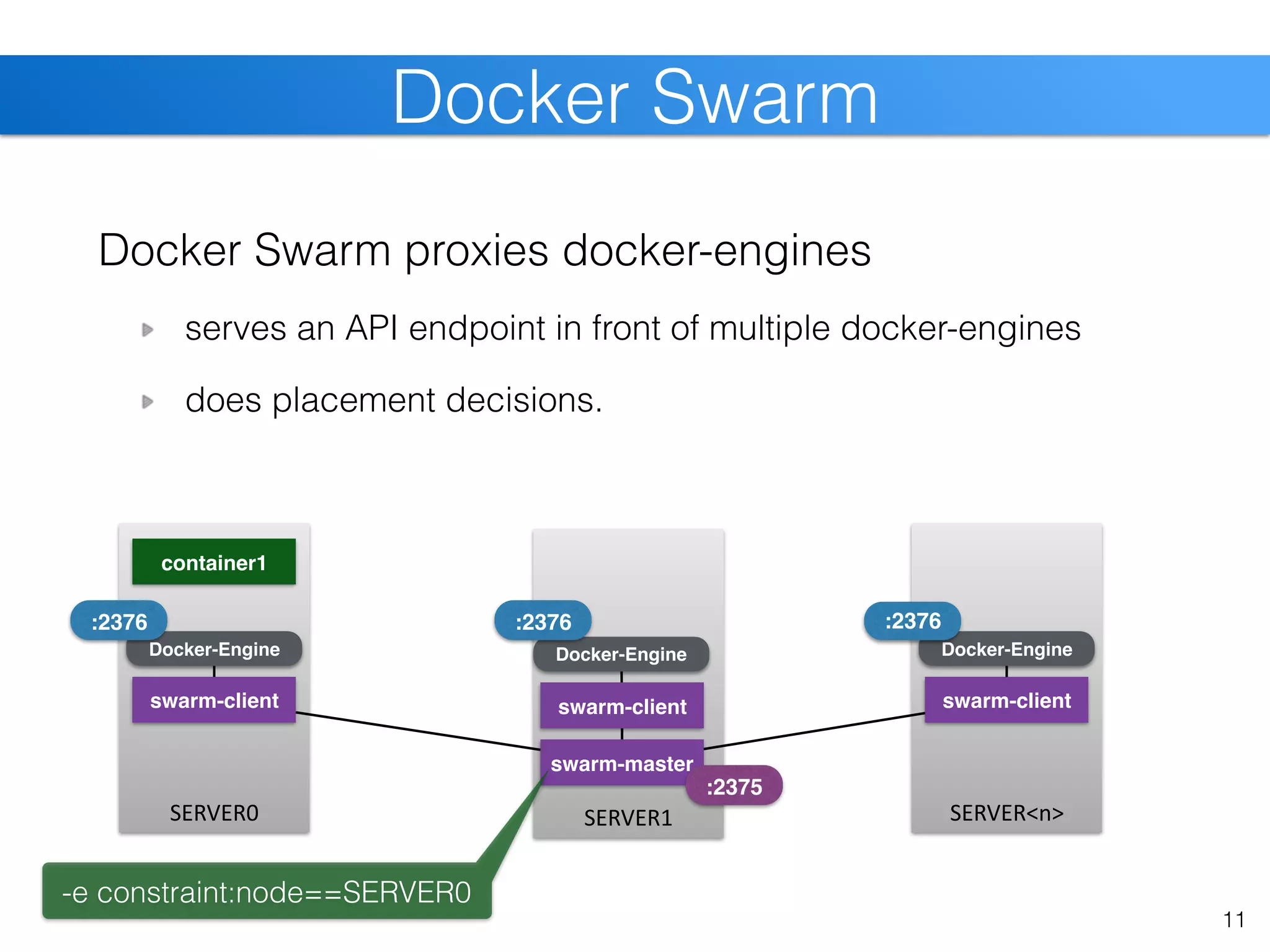
![Docker Swarm [cont]
12
query docker-enginequery docker-swarm](https://image.slidesharecdn.com/christiankniep-160324140935/75/The-State-of-Linux-Containers-12-2048.jpg)






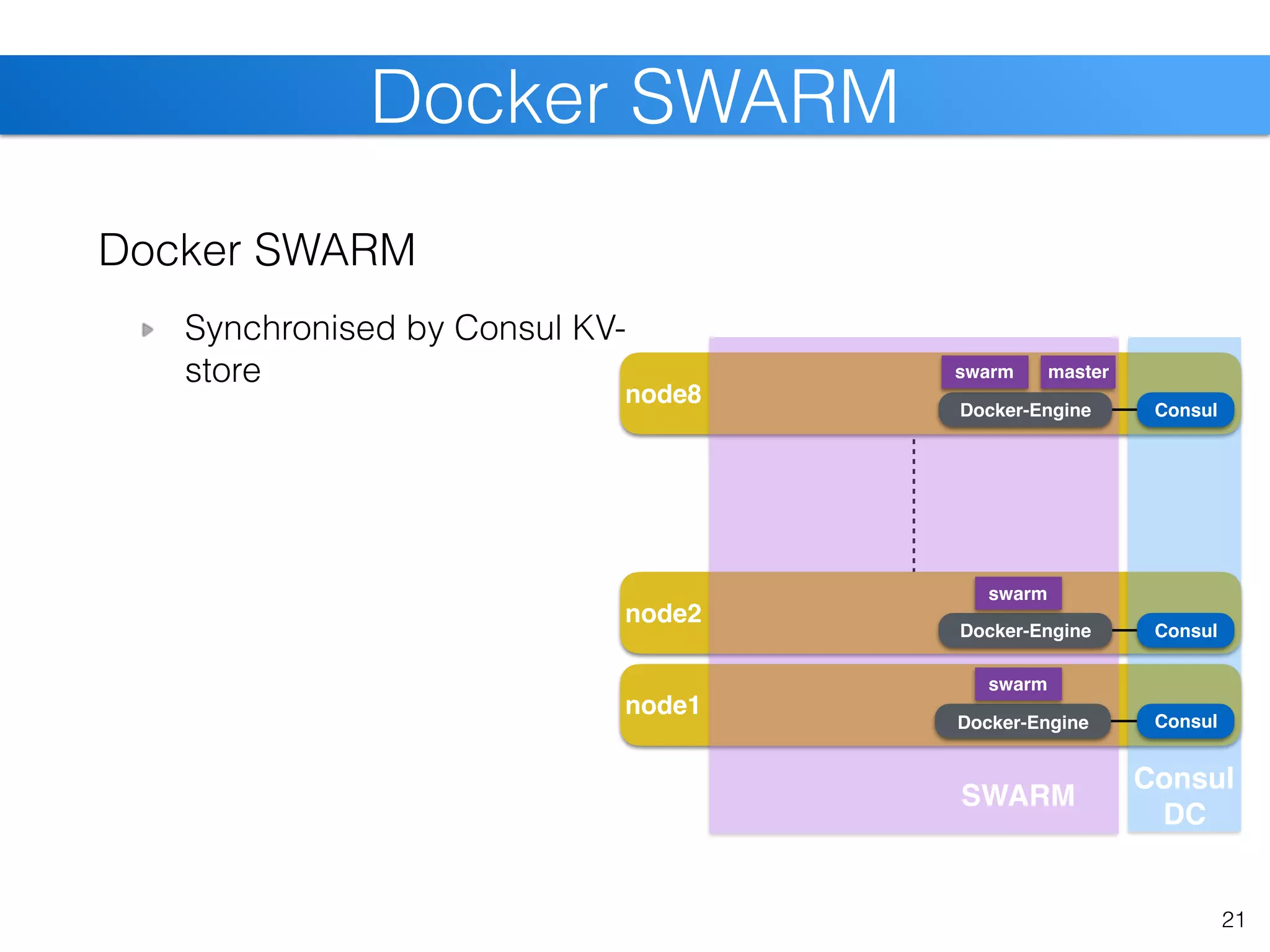
![23
SLURM Cluster [cont]](https://image.slidesharecdn.com/christiankniep-160324140935/75/The-State-of-Linux-Containers-23-2048.jpg)
![node8
node2
node1
24
SLURM Cluster [cont]
Consul
Consul
DC
Consul
Consul
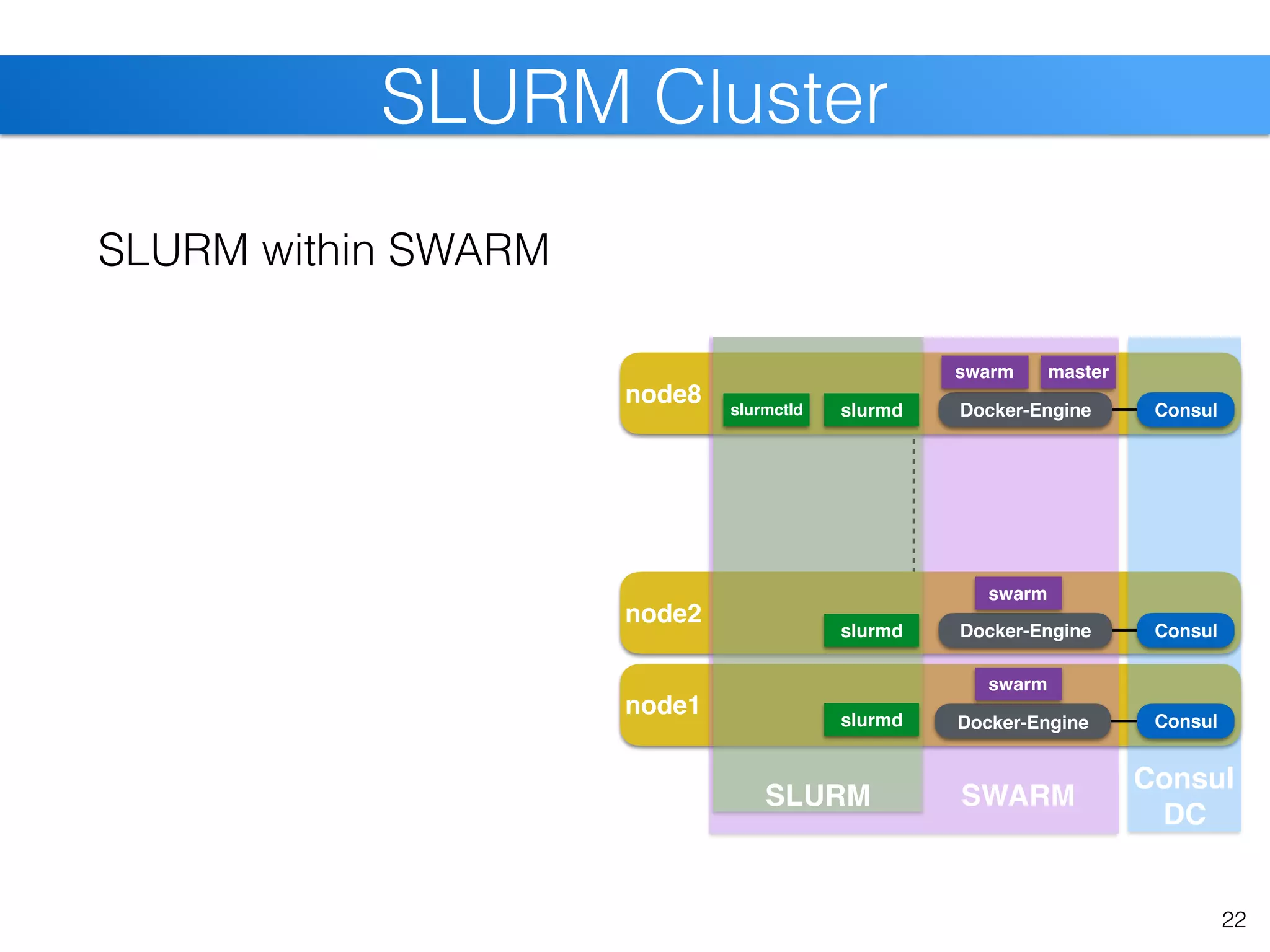
SLURM within SWARM
slurmd within app-container
pre-stage containers slurmctld slurmd
slurmd
slurmd
Docker-Engine
Docker-Engine
Docker-Engine
swarm
swarm
hpcg
hpcg
SWARM
hpcg
swarm master
SLURM](https://image.slidesharecdn.com/christiankniep-160324140935/75/The-State-of-Linux-Containers-24-2048.jpg)
![node8
node2
node1
26
SLURM Cluster [cont]
Consul
Consul
DC
Consul
Consul
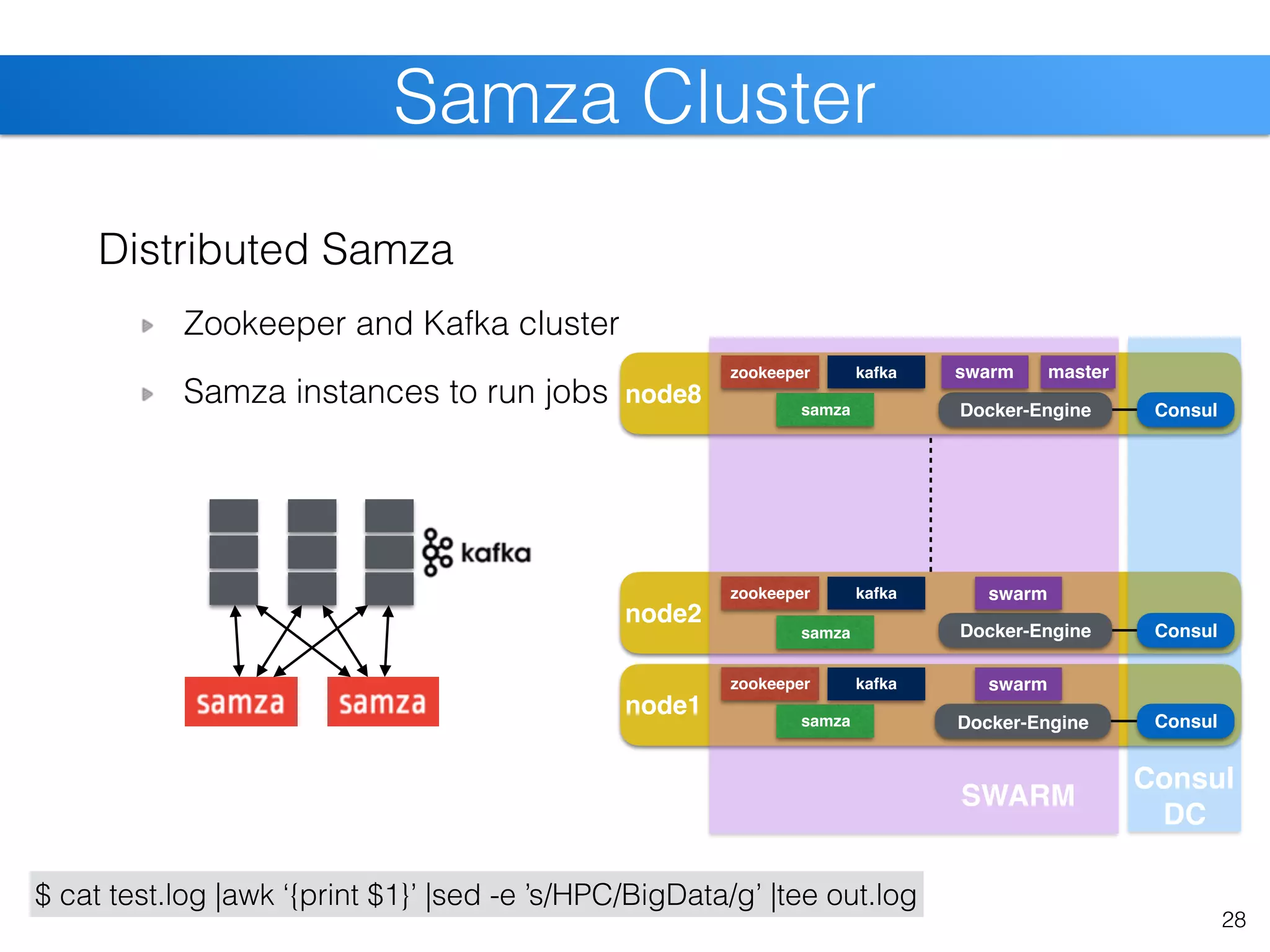
SLURM within SWARM
slurmd within app-container
pre-stage containers slurmctld slurmd
slurmd
slurmd
Docker-Engine
Docker-Engine
Docker-Engine
swarm
swarm
hpcg
hpcg
SWARM
hpcg
OpenFOAM
OpenFOAM
OpenFOAM
swarm master
SLURM](https://image.slidesharecdn.com/christiankniep-160324140935/75/The-State-of-Linux-Containers-26-2048.jpg)









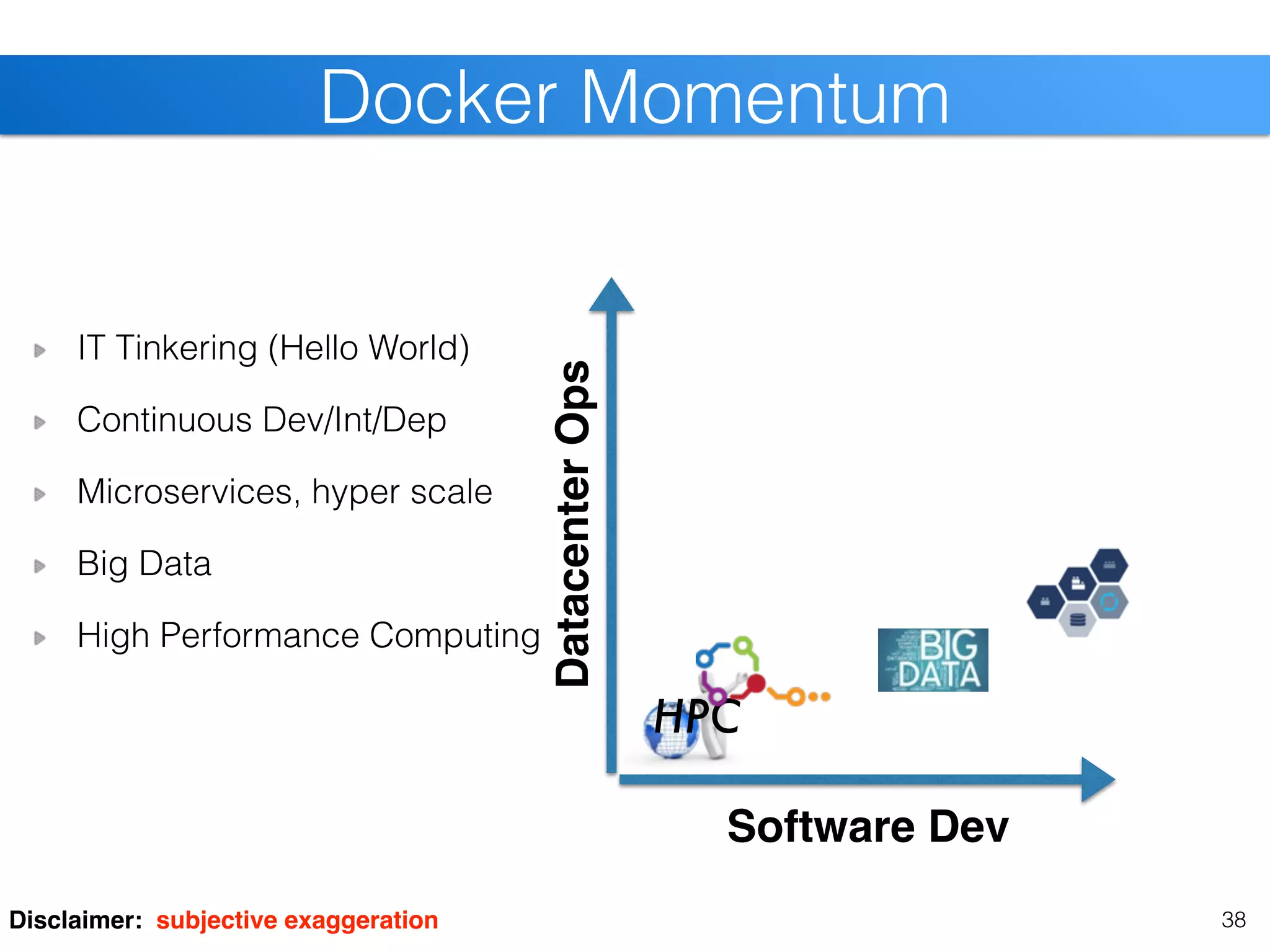



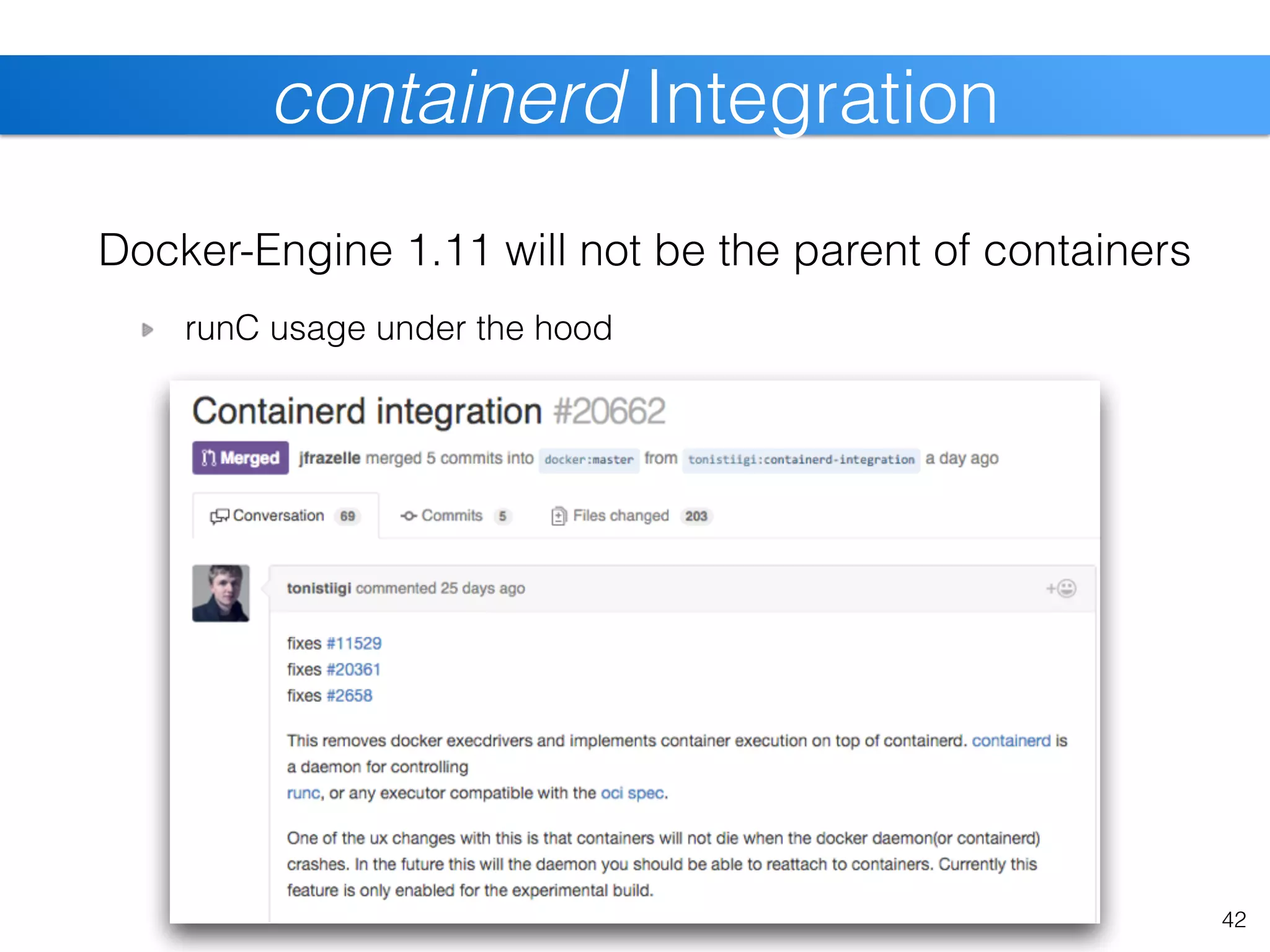


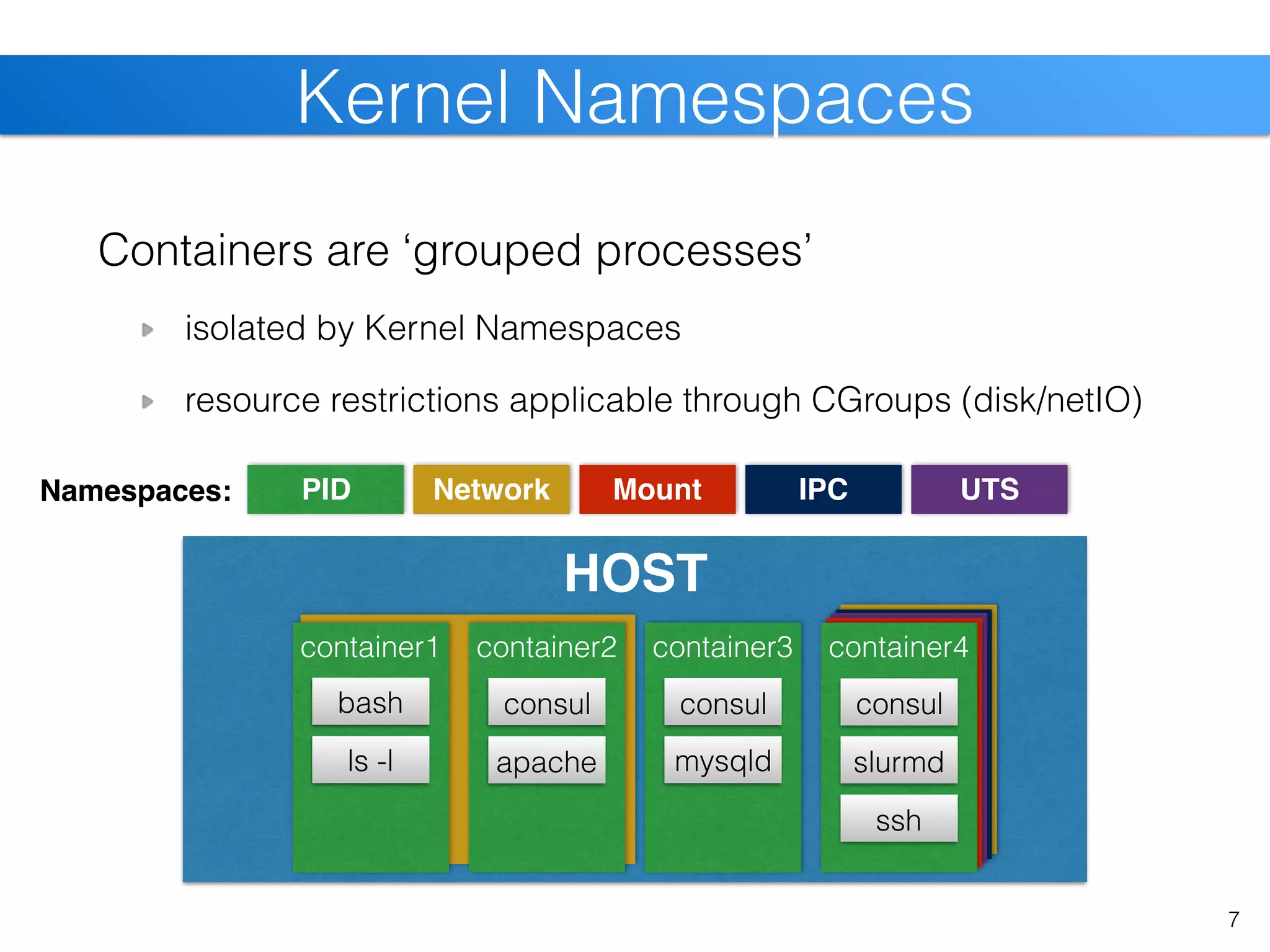
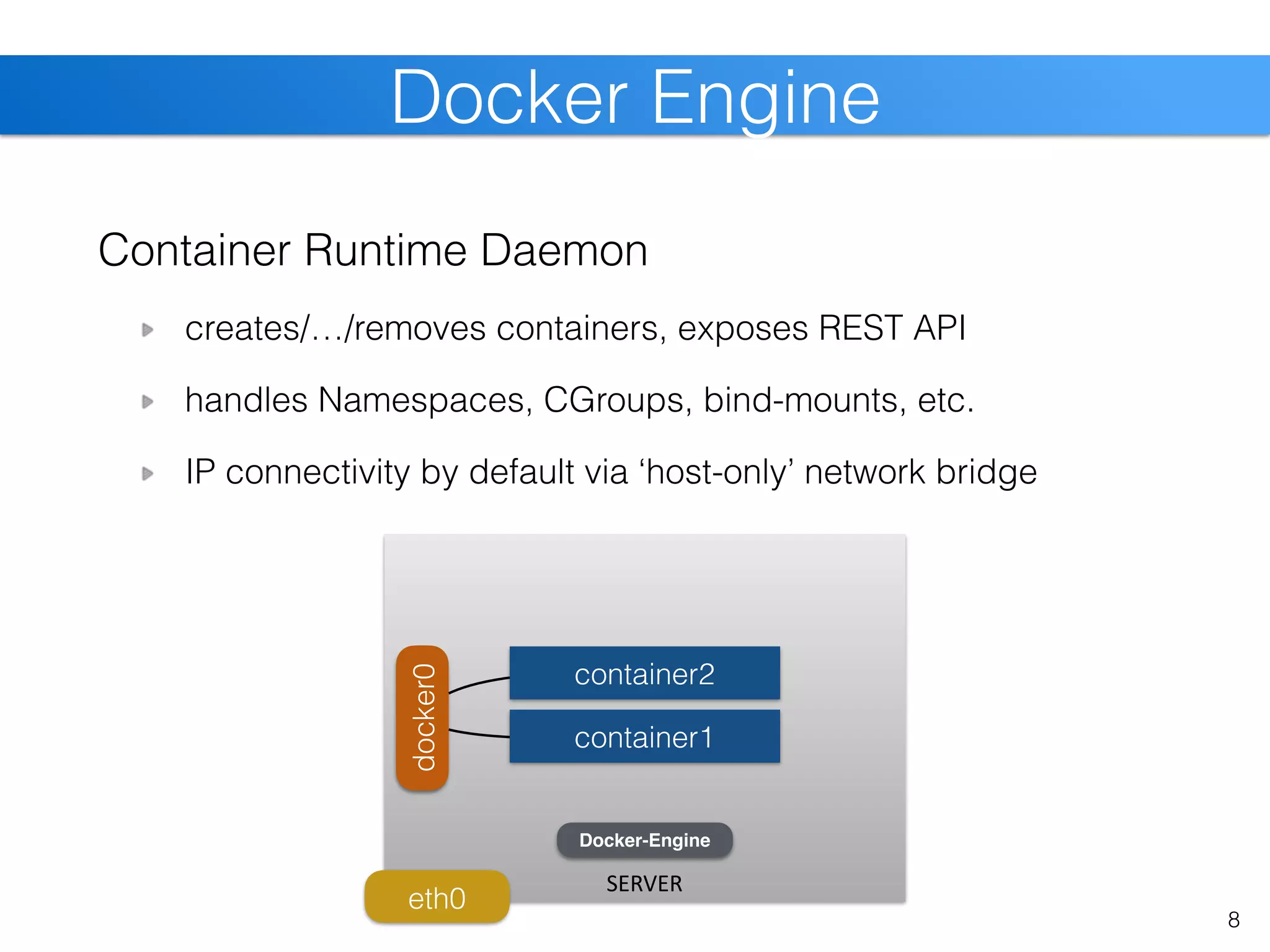
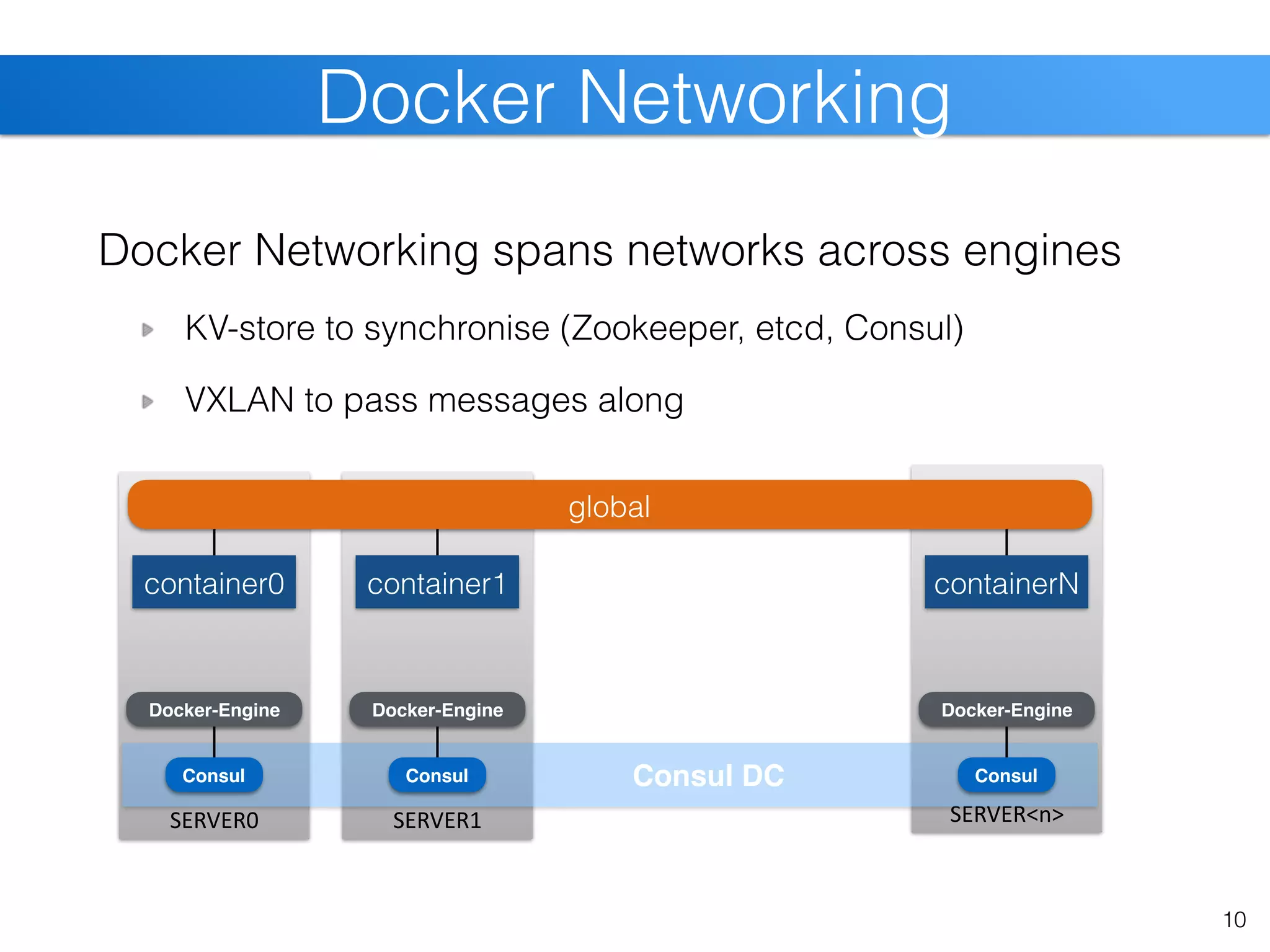
The document discusses the state of Linux containers and the Docker ecosystem, highlighting its architecture, components, and containerization concepts. It emphasizes the integration of various technologies like Docker Swarm, SLURM, and Consul for orchestration and service discovery in high-performance computing. Additionally, it addresses challenges and opportunities arising from adopting new technologies in traditional environments.






![[OpenStack Day in Korea 2015] Keynote 5 - The evolution of OpenStack Networking](https://cdn.slidesharecdn.com/ss_thumbnails/05-150213034012-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2015-05월 세미나] Network Bottlenecks Mutiply with NFV Don't Forget Performance ...](https://cdn.slidesharecdn.com/ss_thumbnails/6wind-openstackkoreameetup27may15-150530064530-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)