




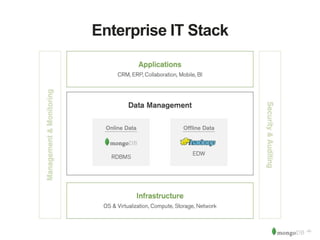
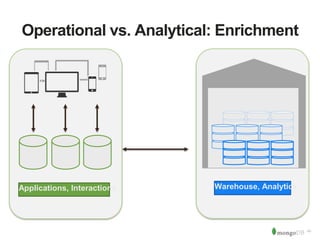
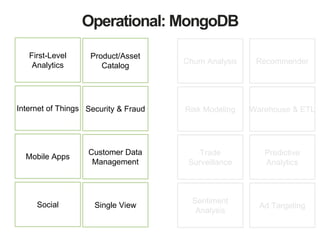
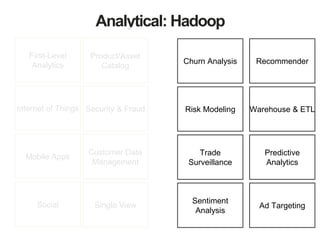
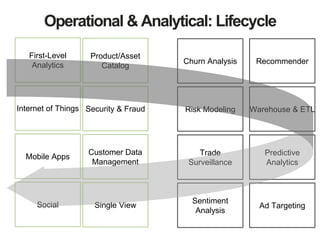

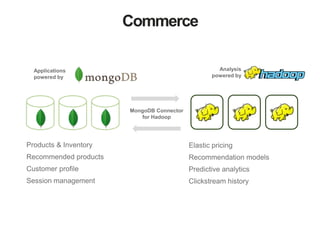
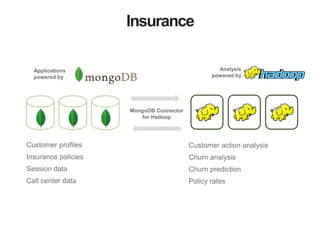
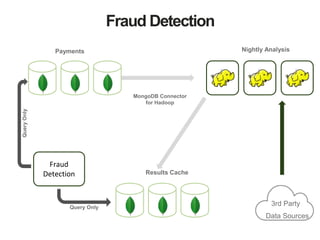

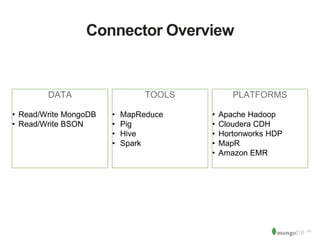




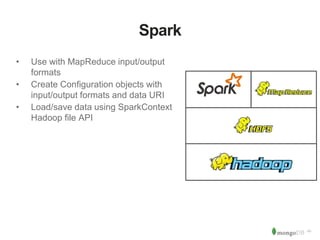
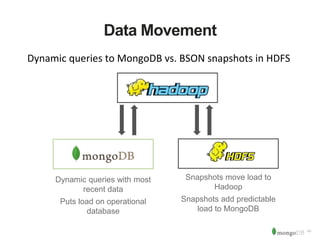



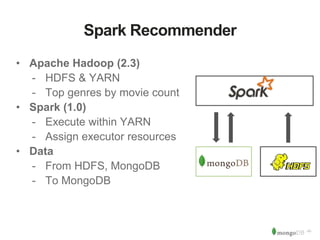
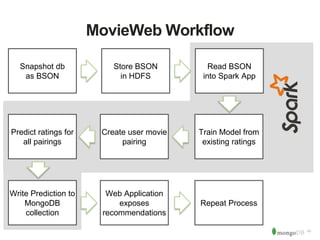
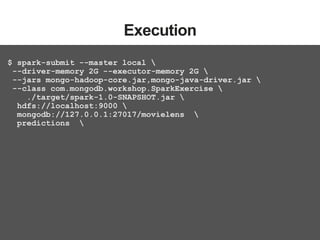

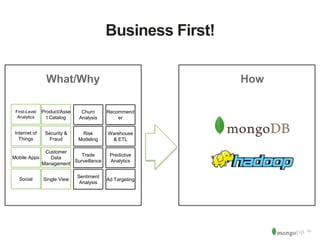

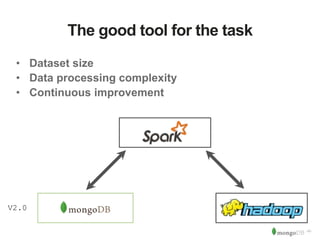


The document discusses MongoDB and Hadoop. It provides an overview of how MongoDB and Hadoop can be used together, including use cases in commerce, insurance and fraud detection. It describes the MongoDB Connector for Hadoop, which allows reading and writing to MongoDB from Hadoop tools like MapReduce, Pig and Hive. A demo is shown of a movie recommendation application that uses both MongoDB and Spark on Hadoop to power a web application.























































































