Download as PDF, PPTX





![Hadoop design
Hadoop designed to solve complex data
Structured and non structured
With [close to] linear scalability
Simplifying the programming model
From MPI, OpenMP, CUDA, …
Operates as a blackbox for data analysts
Image source: Hadoop, the definitive guide](https://image.slidesharecdn.com/benchmarkinghadoop-nicolaspoggi-150604175558-lva1-app6892/75/Benchmarking-Hadoop-and-Big-Data-6-2048.jpg)
![Hadoop attributes
Fault tolerant
from commodityhardware
Built in redundancy
via replication
Automatic scales out / down
With [almost] linear scalability
Move computation to data
minimize communication
Share nothing architecture](https://image.slidesharecdn.com/benchmarkinghadoop-nicolaspoggi-150604175558-lva1-app6892/75/Benchmarking-Hadoop-and-Big-Data-7-2048.jpg)










![Comparisonof popularHadoop benchmarks
Spec[1
]
App
domains
Workload
types
Workload
s
Scalable
data
sets[2]
Diverse
implem[3]
Multi-
tenancy[4]
Subset[5] Simulator
[6]
BigDataBench Y Five Four[7] Thirty-
three [8] Eight[9] Y Y Y Y
BigBench Y One Three Ten Three N N N N
CloudSuite N N/A Two Eight Three N N N Y
HiBench N N/A Two Ten Three N N N N
CALDA Y N/A One Five N/A Y N N N
YCSB Y N/A One Six N/A Y N N N
LinkBench Y N/A One Ten N/A Y N N N
AMP Benchma
rks
Y N/A One Four N/A Y N N N
The Differences of BigDataBench from Other Benchmarks Suites.
Source: BigDataBench homepage](https://image.slidesharecdn.com/benchmarkinghadoop-nicolaspoggi-150604175558-lva1-app6892/75/Benchmarking-Hadoop-and-Big-Data-25-2048.jpg)




![34
Benchmarks Execution comparisons
You can compare, side by side, all execution parameters:
CPU, Memory, Network, Disk, Hadoop parameters….
Sample:
http://hadoop.bsc.es/perfcharts?execs[]=91144](https://image.slidesharecdn.com/benchmarkinghadoop-nicolaspoggi-150604175558-lva1-app6892/75/Benchmarking-Hadoop-and-Big-Data-31-2048.jpg)






The document discusses the BDoop group, which focuses on benchmarking Hadoop and aims to create a community for sharing knowledge on big data performance, scalability, and solutions. It outlines the attributes and challenges of Hadoop, emphasizing the importance of benchmarking for validating performance, simulating loads, and understanding different workloads. Additionally, it presents tools and resources for data benchmarking, including the Aloja online repository and various benchmark suites.
Introduction of Nicolas Poggi and BDOOP as a community focusing on Big Data and benchmarking.
Discussion on Hadoop's design principles, scalability, and attributes like fault tolerance and performance requirements.Explanation of Hadoop's ecosystem, the need for tuning parameters, and the challenge of diverse workloads.
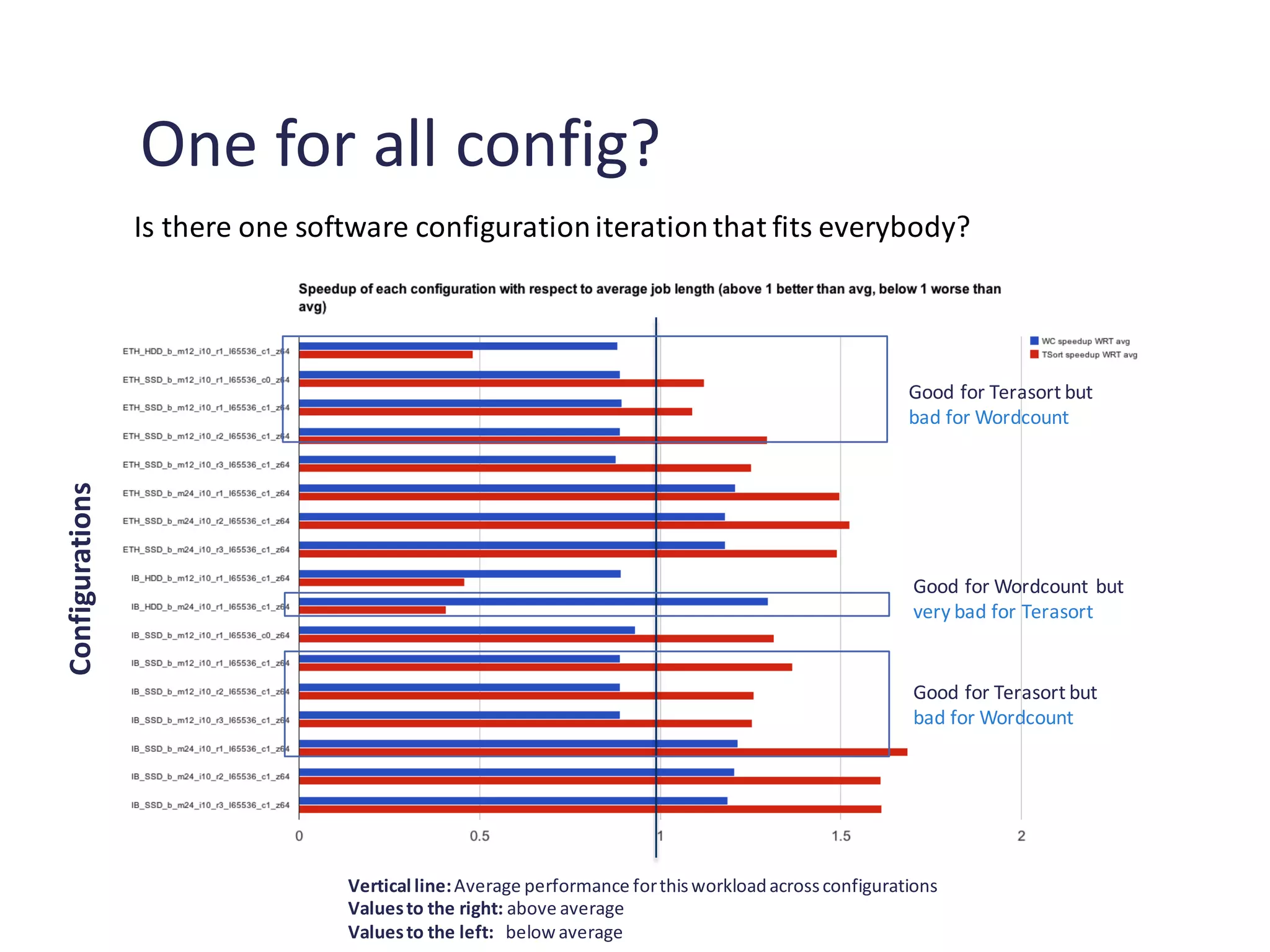
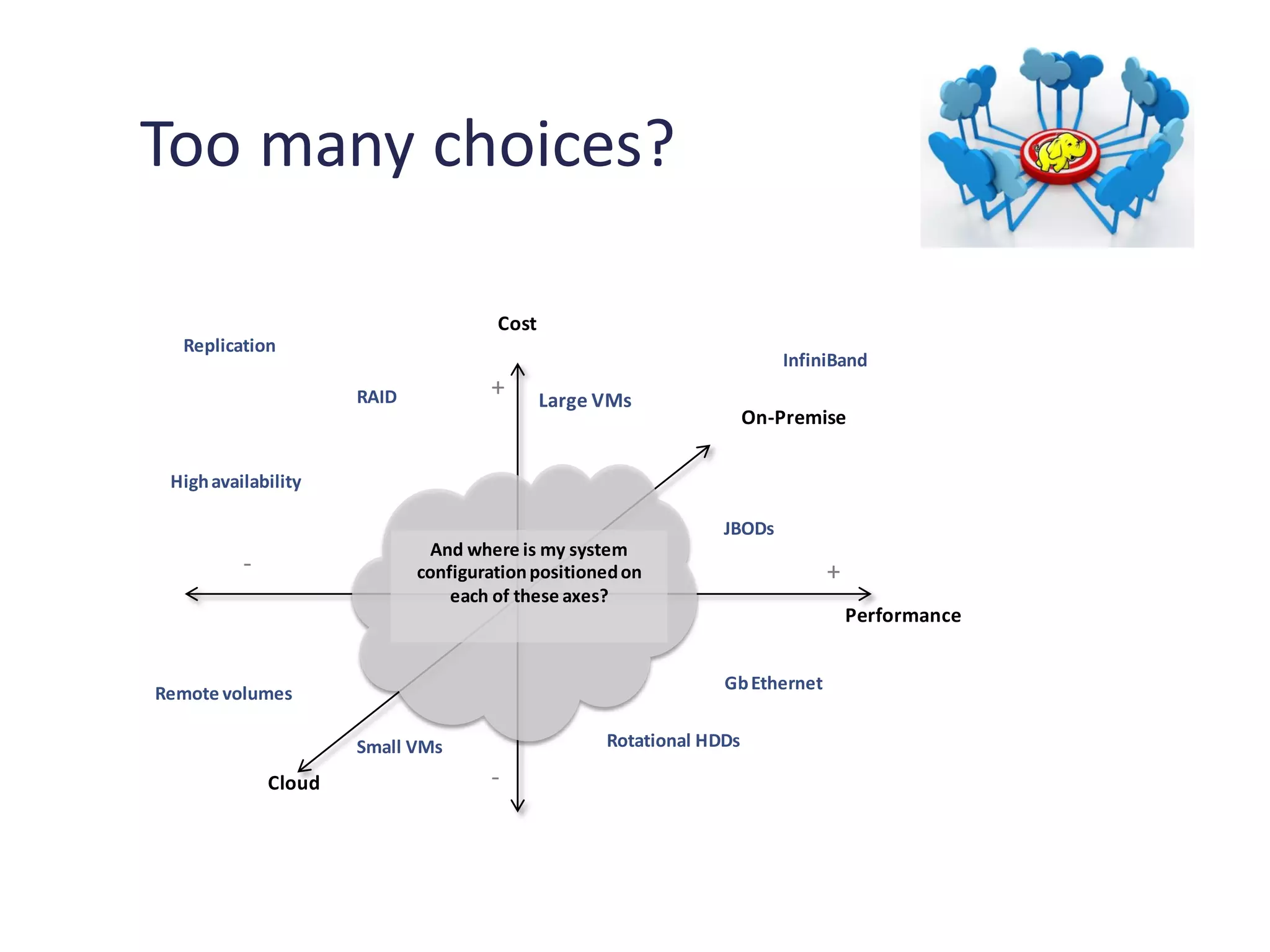
Exploration of the impact of configurations on performance and the variety of hardware choices available.
Understanding why benchmarking is essential for performance measurement and comparison in Big Data.
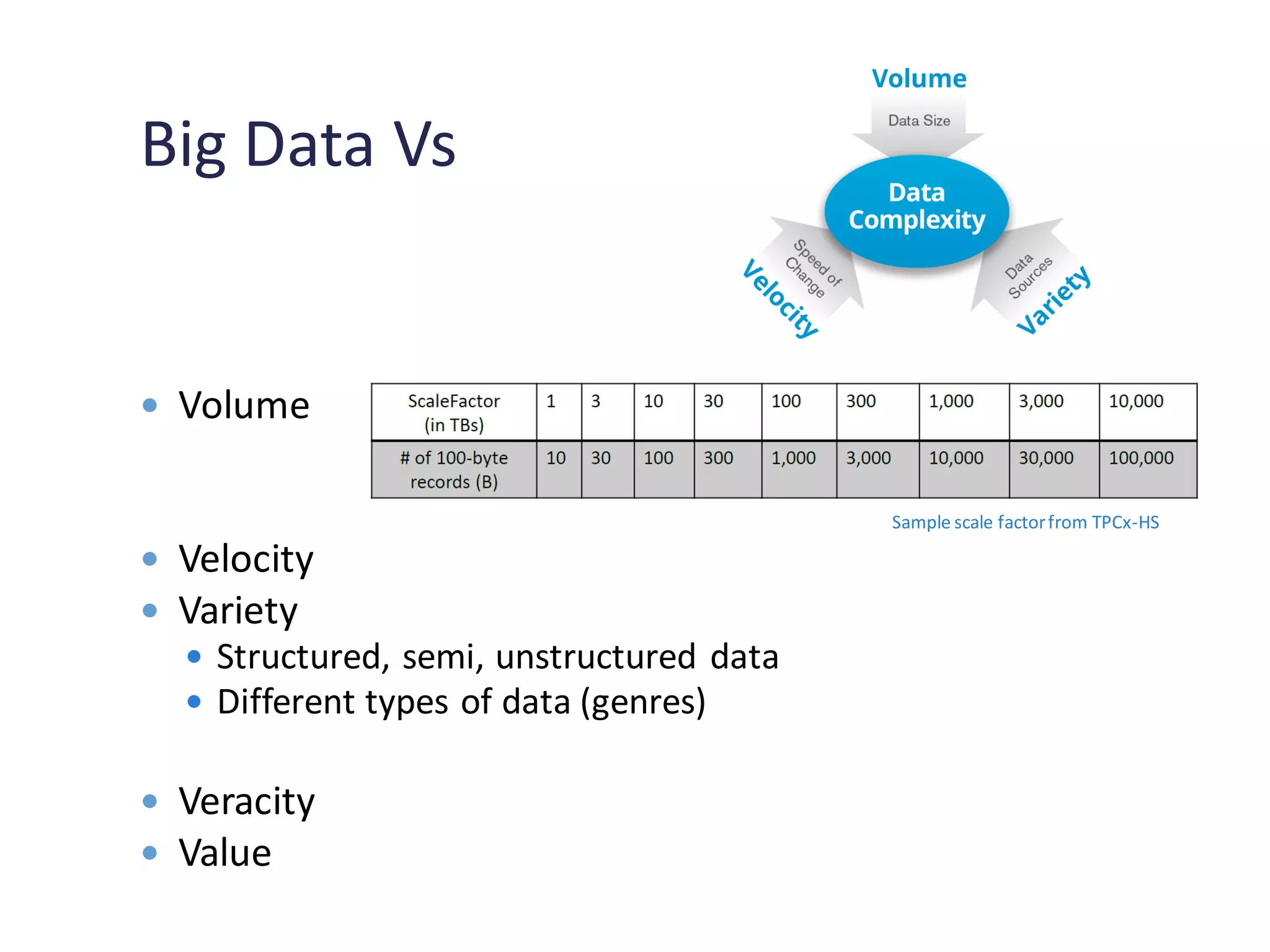
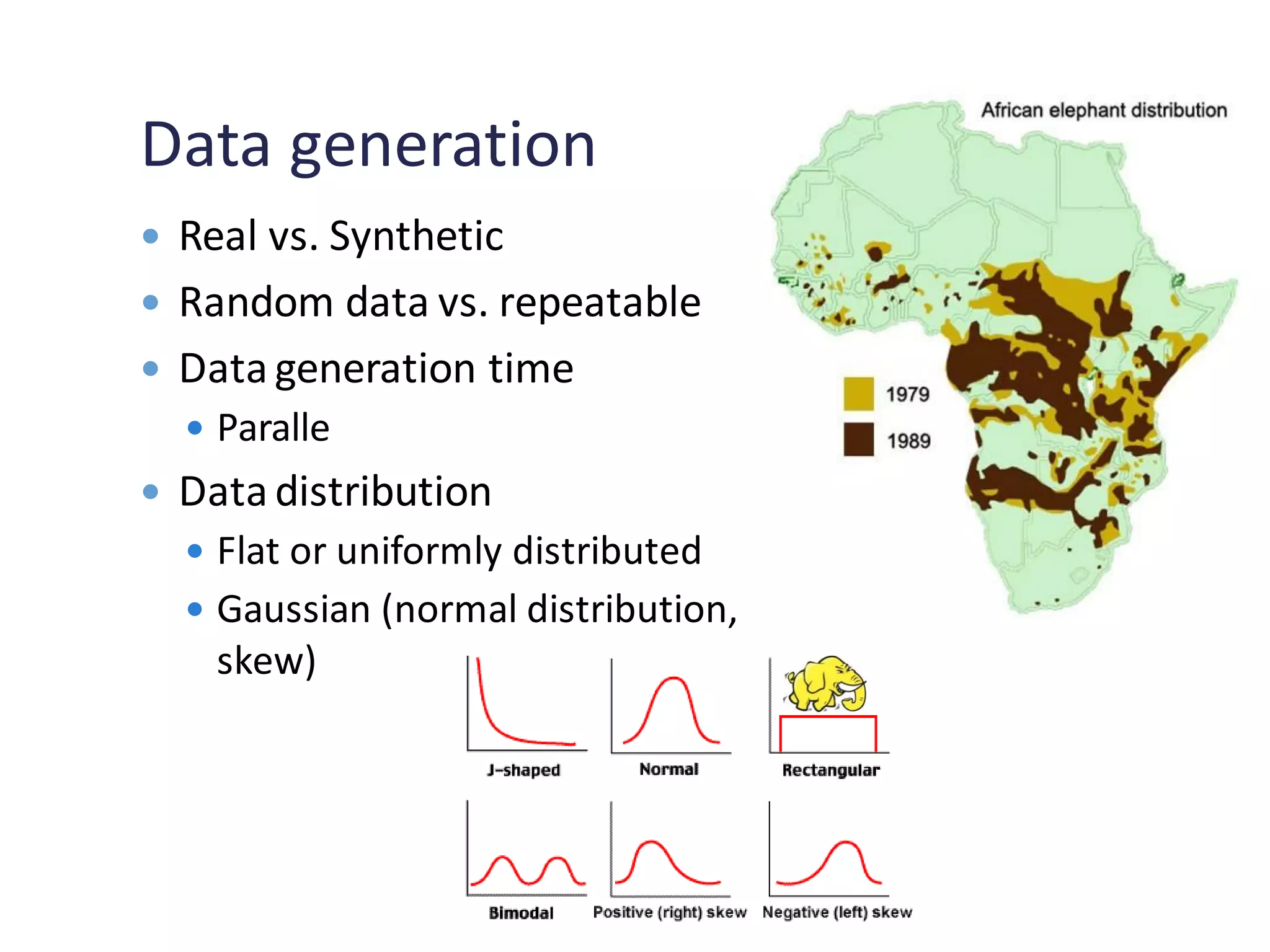
Challenges in generating data for benchmarks and the types of benchmarks used in Big Data scenarios.
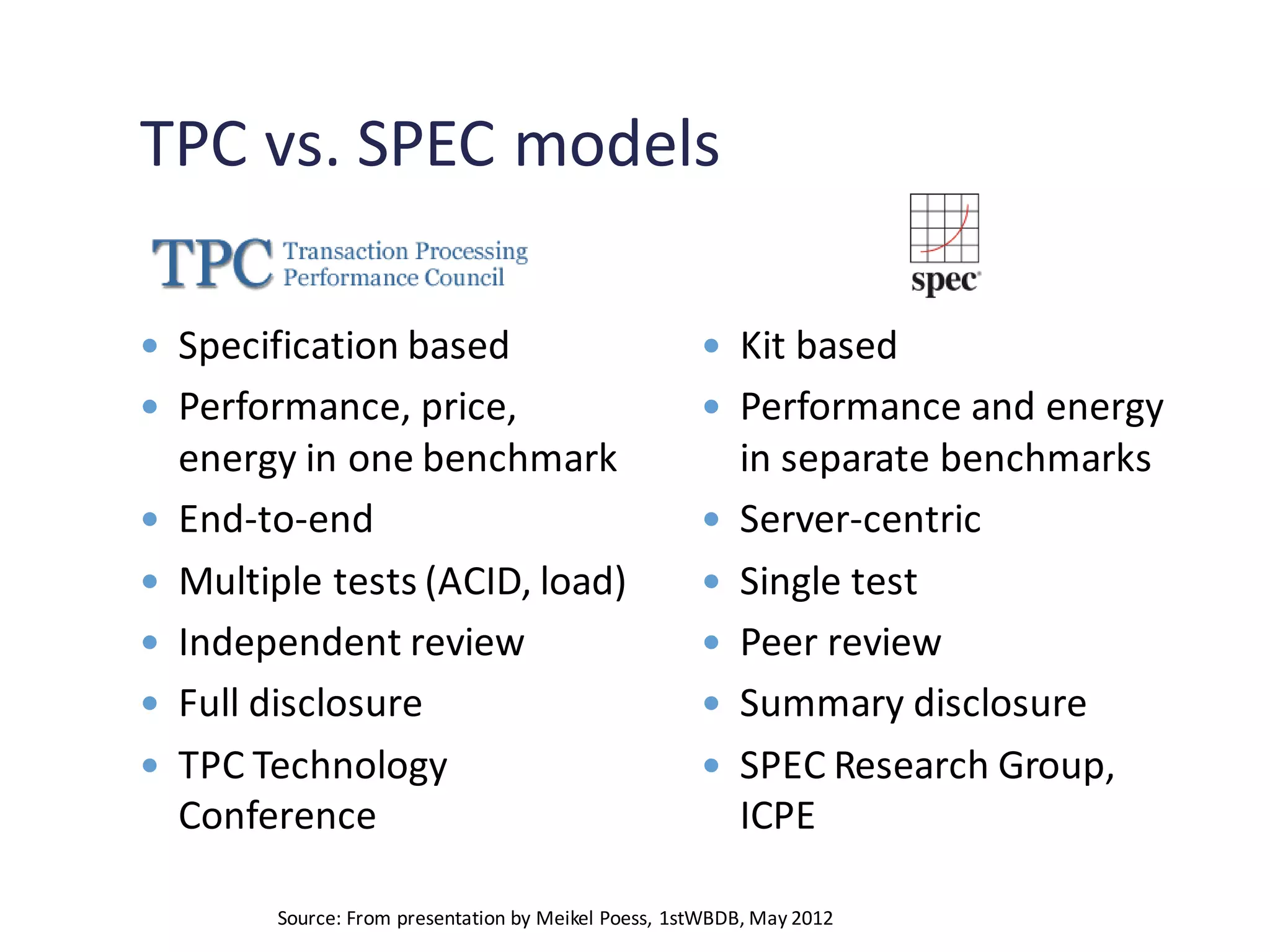
Comparison of benchmarking models TPC and SPEC, and the evolution of different benchmark types.
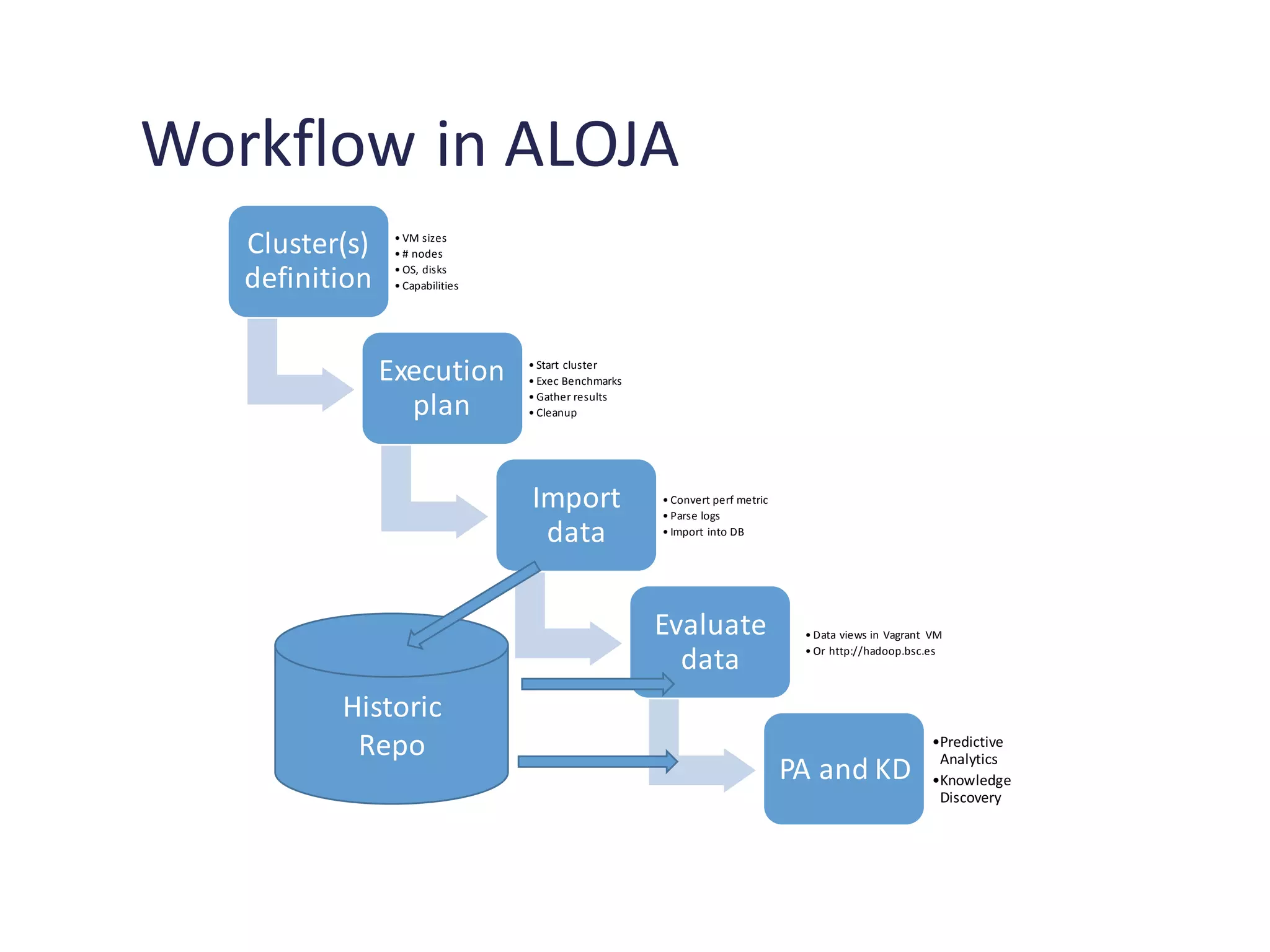
Key performance metrics to be measured during benchmarking tasks and introduction to ALOJA repository.
Overview of ALOJA’s functionalities for benchmarking, including data collection and evaluations.
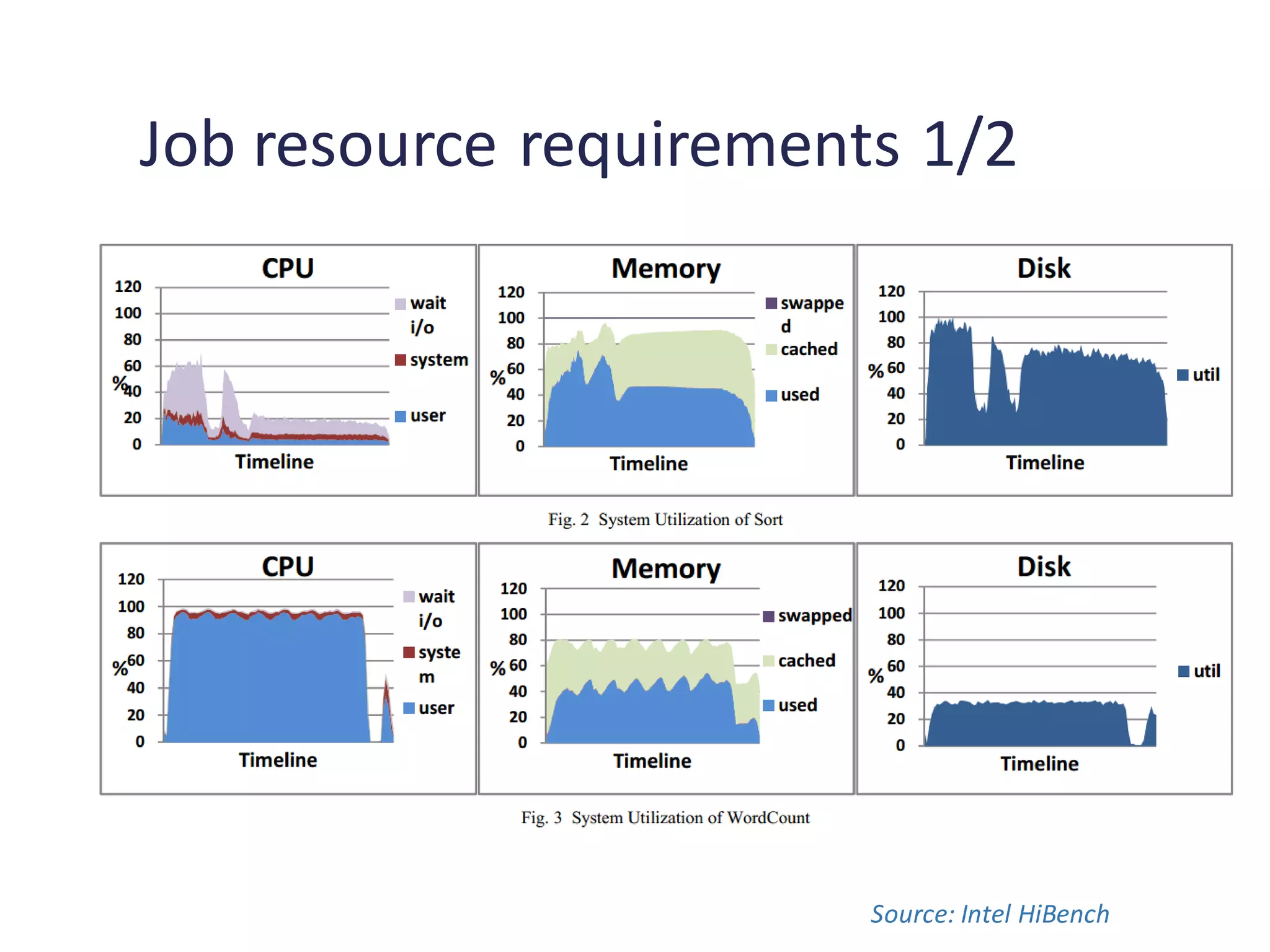
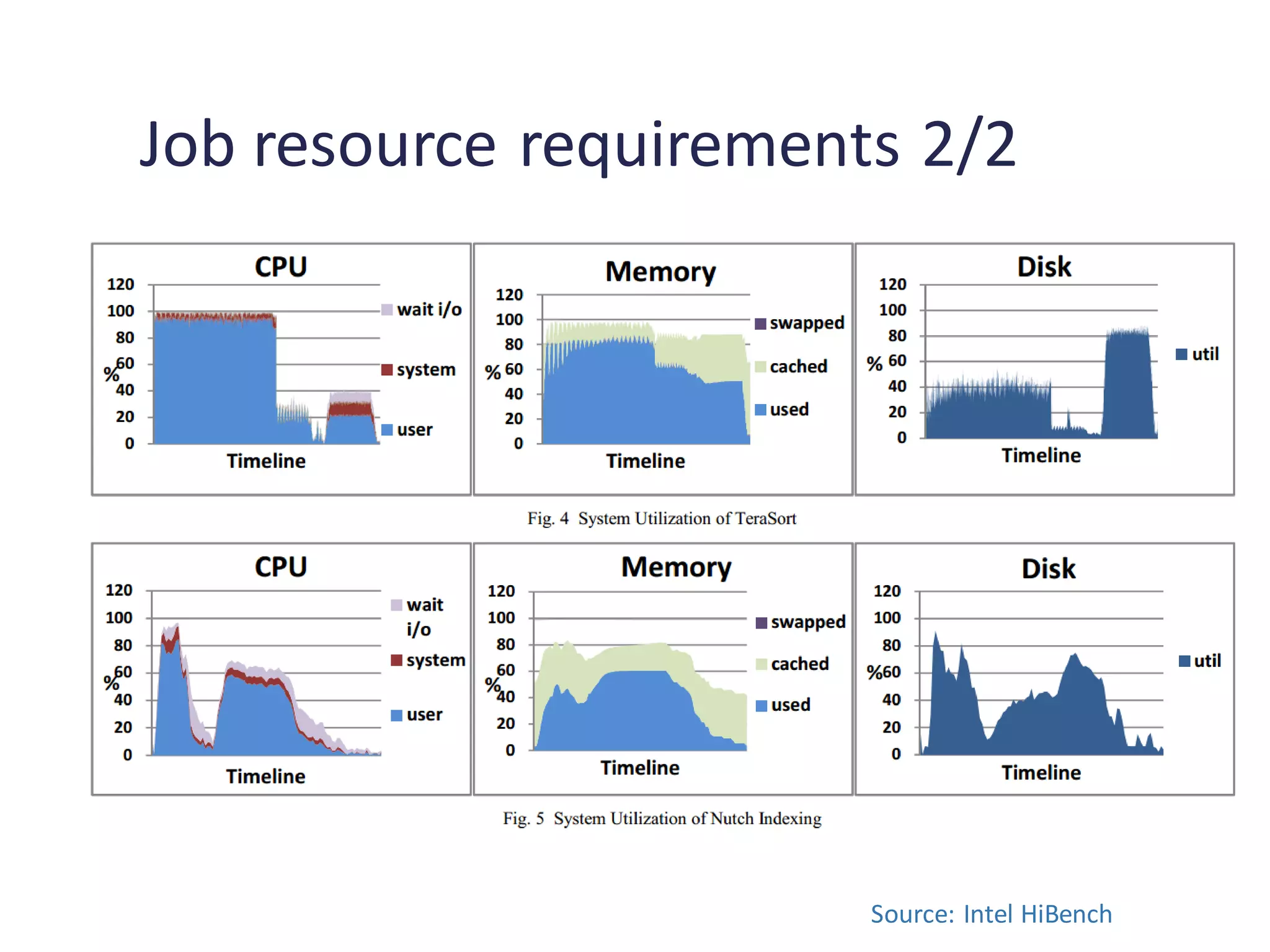
Comparison of benchmark execution parameters and resource requirements for different benchmark suites.
Analysis of speedup impacts due to different software and hardware configurations affecting benchmarks.
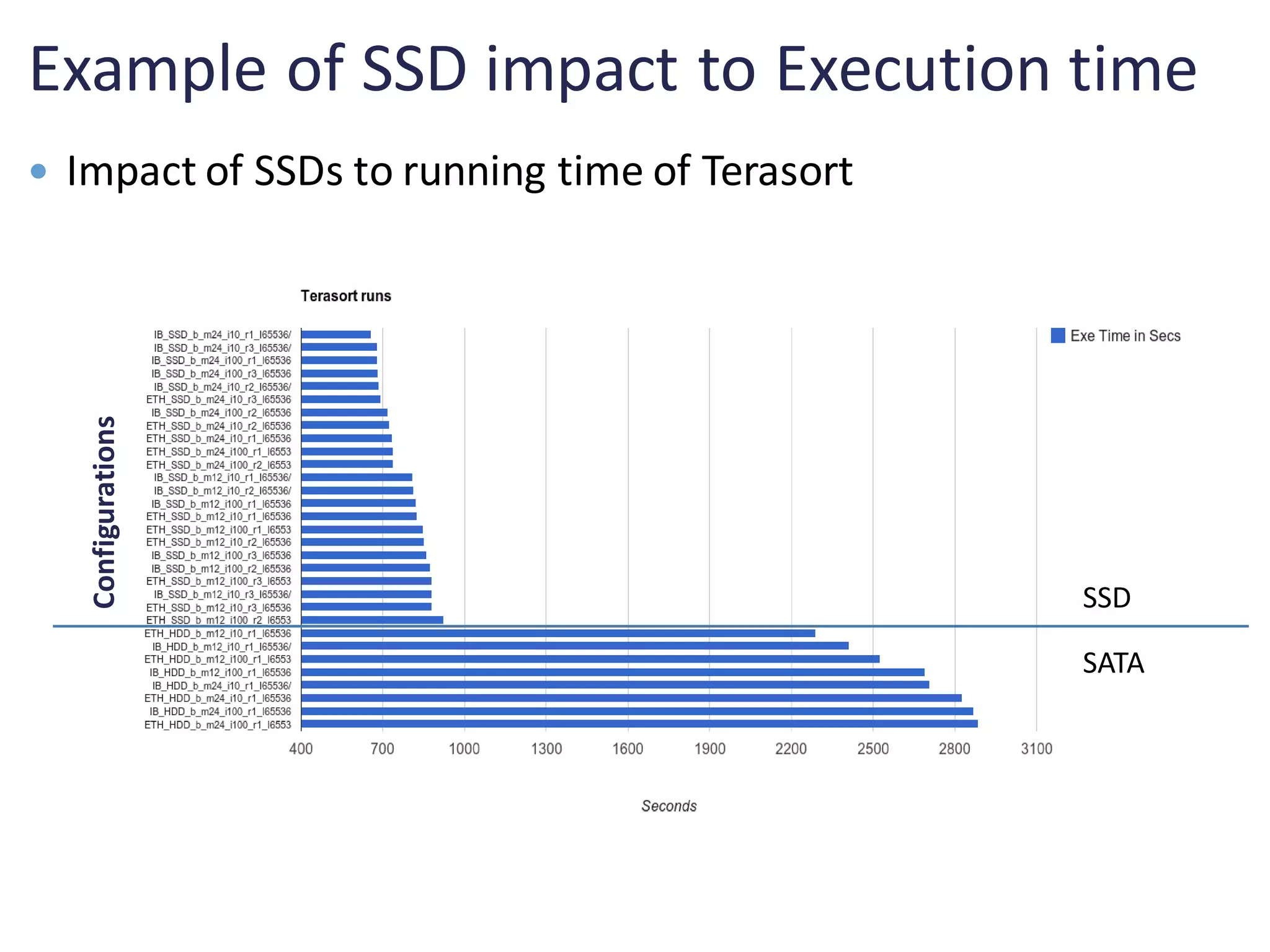
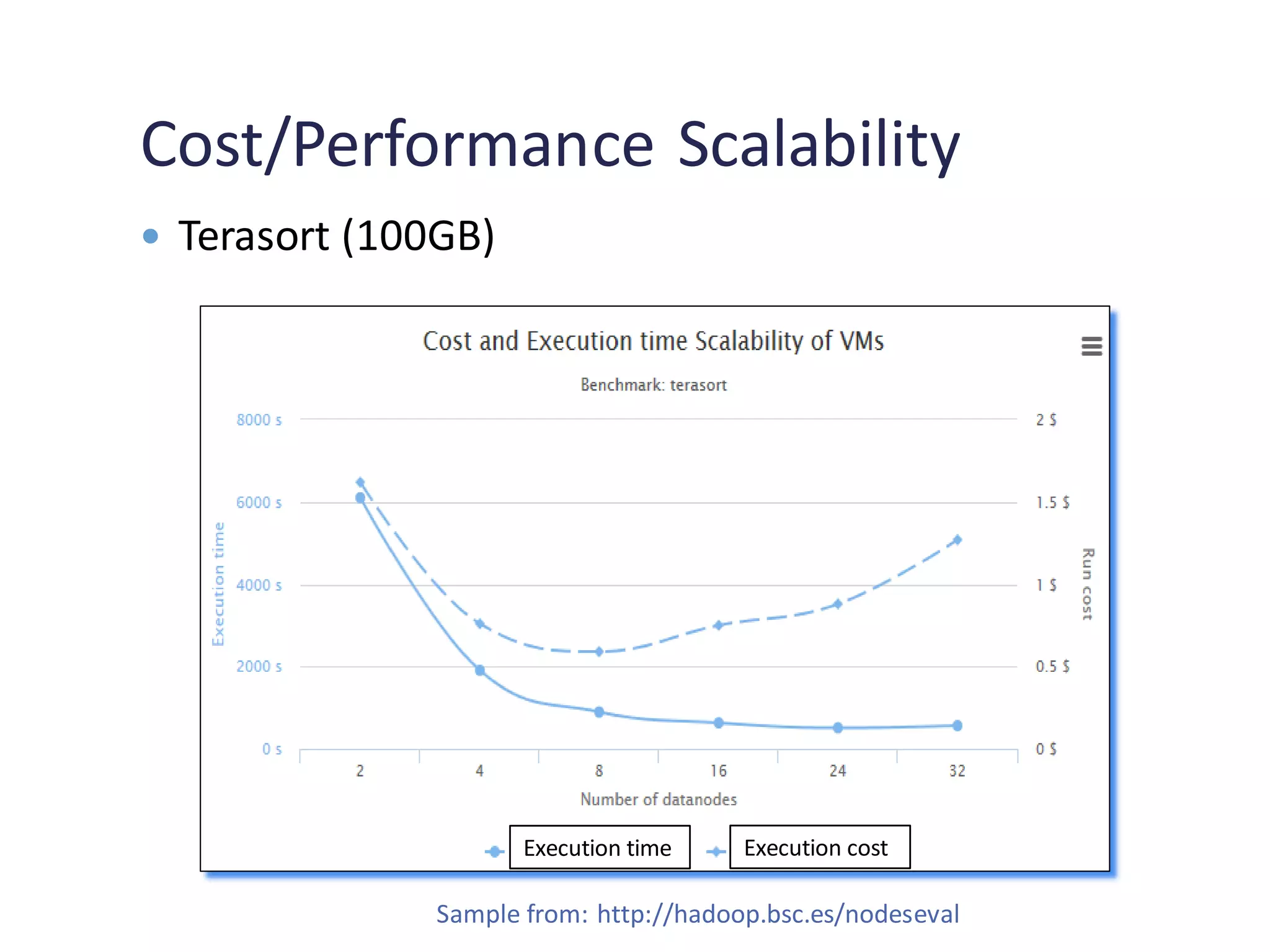
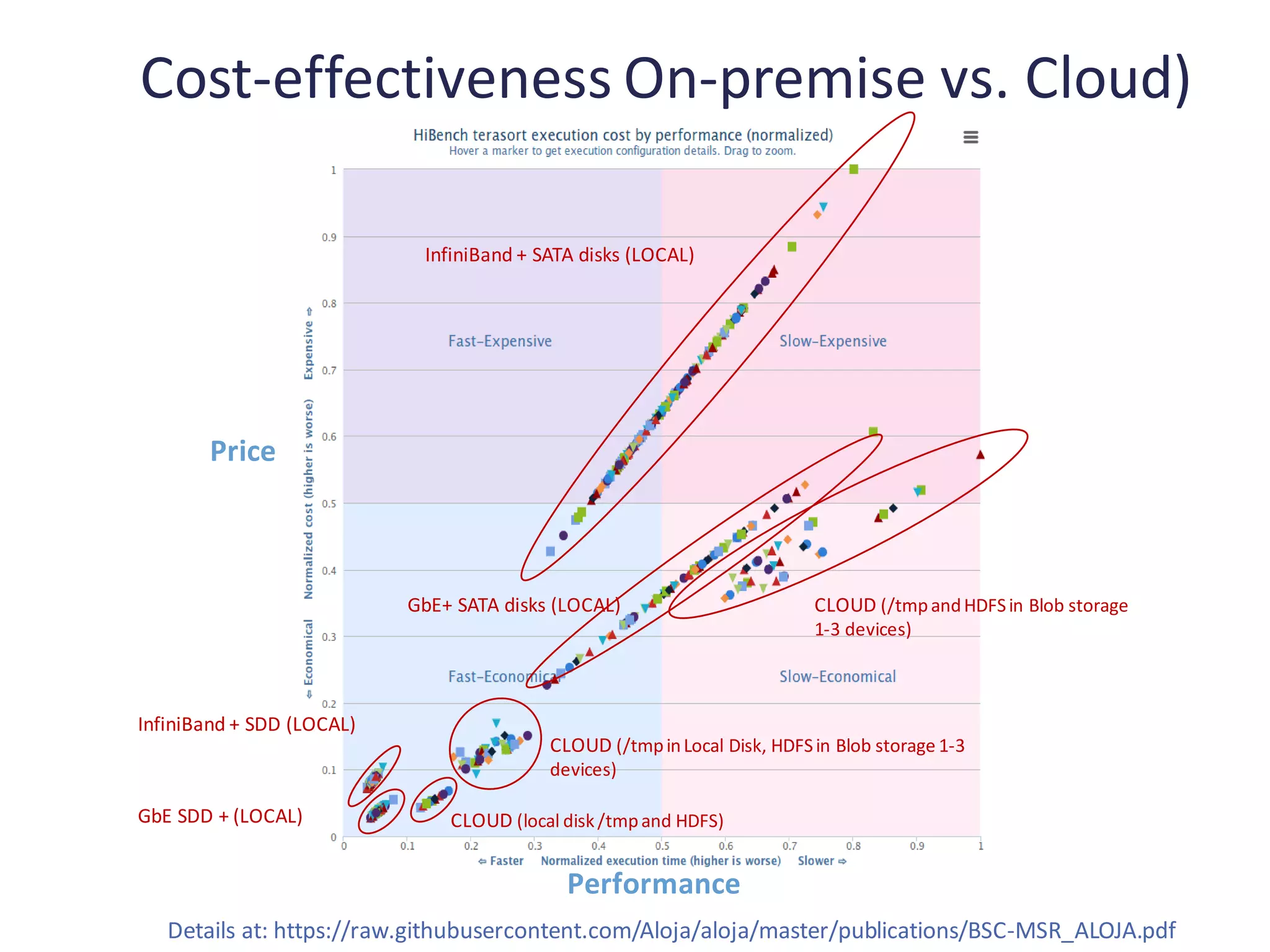
Review of scalability, cost-performance ratios, and comparisons for Terasort across configurations.
Identification of prevalent mistakes when benchmarking Big Data applications and reliability of results.
Closing remarks from the presentation along with resources for further engagement in benchmarking Hadoop.












































































![Vagrant + Docker provider [+Puppet]](https://cdn.slidesharecdn.com/ss_thumbnails/npoggivagrant-docker-140725100147-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Full-Stack Development] Agentic AI Architecture: Redefining Syste...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-agenticaiarchitectureredefiningsystemcommunication-251124030838-e6c70cc2-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Full-Stack Development] The Modern Stack: Building Web & AI Appli...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-themodernstackbuildingwebaiapplicationswithserverless-251124030844-388cf04f-thumbnail.jpg?width=640&height=640&fit=bounds)

![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)






![Support, Monitoring, Continuous Improvement & Scaling Agentic Automation [3/3]](https://cdn.slidesharecdn.com/ss_thumbnails/agenticcommunityseries-day3-cfd-251120170304-ddef8112-thumbnail.jpg?width=640&height=640&fit=bounds)








