Downloaded 214 times


















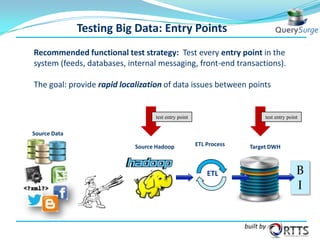




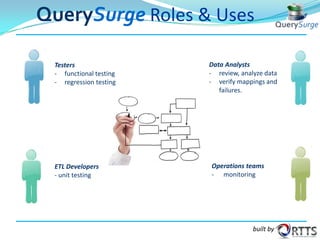








The document outlines a webinar on automated ETL testing of Hadoop, covering big data, Hadoop architecture, data warehouses, and the ETL process. It emphasizes the importance of testing in data management and introduces QuerySurge as a tool for automating data warehouse testing and improving data quality. Key points include the growth of the big data market and the need for efficient testing across multiple platforms.



































































