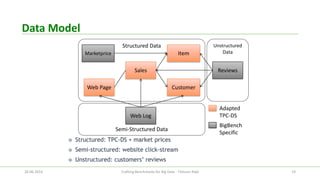
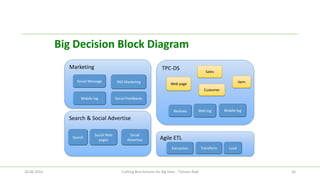
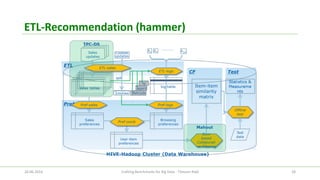
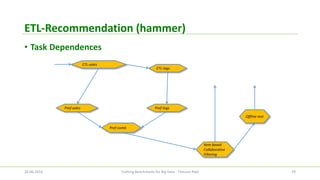
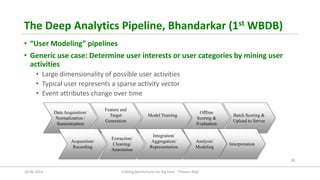
The document discusses the efforts of the big data benchmarking community, highlighting the genesis, objectives, and outcomes of various workshops aimed at establishing benchmarks for big data technologies. It describes the formation of working groups, the creation of a 'Big Data Top 100' list, and details various types of benchmarks, including micro-benchmarks and application-level benchmarks. Additionally, it provides insights into specific benchmarking efforts like BigBench and TPC's big data subcommittee initiatives.