Download as PDF, PPTX

























![Problems with Cached Tables
Still have to read the data from Cassandra first, which is slow
Amount of RAM: your entire data + extra for conversion to
cached table
Cached tables only live in Spark executors - by default
tied to single context - not HA
once any executor dies, must re-read data from C*
Caching takes time: convert from RDD[Row] to compressed
columnar format
Cannot easily combine new RDD[Row] with cached tables
(and keep speed)](https://image.slidesharecdn.com/2015-08-breakthrougholapperformancewithcassandraandspark-150818072730-lva1-app6891/85/Breakthrough-OLAP-performance-with-Cassandra-and-Spark-25-320.jpg)















![So, why isn't everybody doing this?
No columnar storage format designed to work with NoSQL
stores
Efficient conversion to/from columnar format a hard problem
Most infrastructure is still row oriented
Spark SQL/DataFrames based on RDD[Row]
Spark Catalyst is a row-oriented query parser](https://image.slidesharecdn.com/2015-08-breakthrougholapperformancewithcassandraandspark-150818072730-lva1-app6891/85/Breakthrough-OLAP-performance-with-Cassandra-and-Spark-41-320.jpg)


















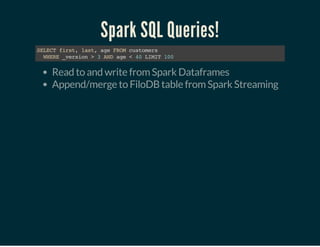











The document discusses leveraging Apache Cassandra and Apache Spark for achieving high-performance OLAP analytics on large datasets, particularly through innovative integration techniques. It outlines the limitations of traditional databases and formats like Parquet, while also highlighting the benefits of using Cassandra's flexible data modeling and Spark's fast query capabilities. The content emphasizes the importance of efficient data caching, columnar storage approaches, and introduces Filodb as a solution for optimizing analytical queries, particularly in IoT and real-time data environments.












































































