Downloaded 10 times







![Solution - Reduce
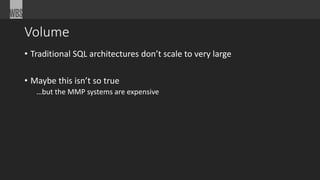
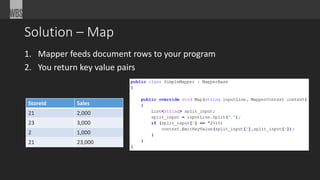
• Data is merged
• Merged into Key/Values:
{21, [2,000, 23,000]}
{23, [3,000]}
{2, [1,000]}
• You process each row](https://image.slidesharecdn.com/bigdatapart1-141031082523-conversion-gate01/85/Big-Data-Overview-Part-1-20-320.jpg)

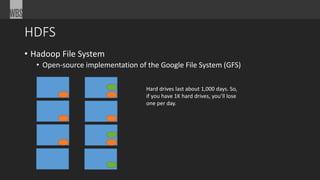

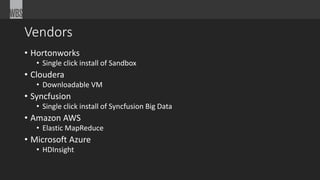

The document is an overview of big data, discussing its definition, characteristics (volume, velocity, and variety), and challenges associated with traditional data processing methods. It introduces MapReduce as a solution for processing large data sets and highlights various tools and technologies in the big data ecosystem, including Hadoop and its components. Additionally, it mentions sponsors and events related to the topic, such as Boston Code Camp 22.




















































































