Downloaded 49 times



















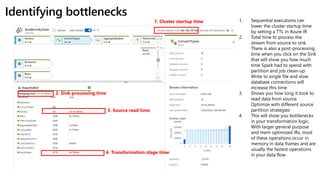












This document discusses optimizing performance for data flows in Azure Data Factory. It provides sample timing results for various scenarios and recommends settings to improve performance. Some best practices include using memory optimized Azure integration runtimes, maintaining current partitioning, scaling virtual cores, and optimizing transformations and sources/sinks. The document also covers monitoring flows to identify bottlenecks and global settings that affect performance.








































![[DBA]_HiramFleitas_SQL_PASS_Summit_2017_Summary](https://cdn.slidesharecdn.com/ss_thumbnails/dbahiramfleitassqlpasssummit2017summary-180202201153-thumbnail.jpg?width=640&height=640&fit=bounds)













































