Downloaded 15 times





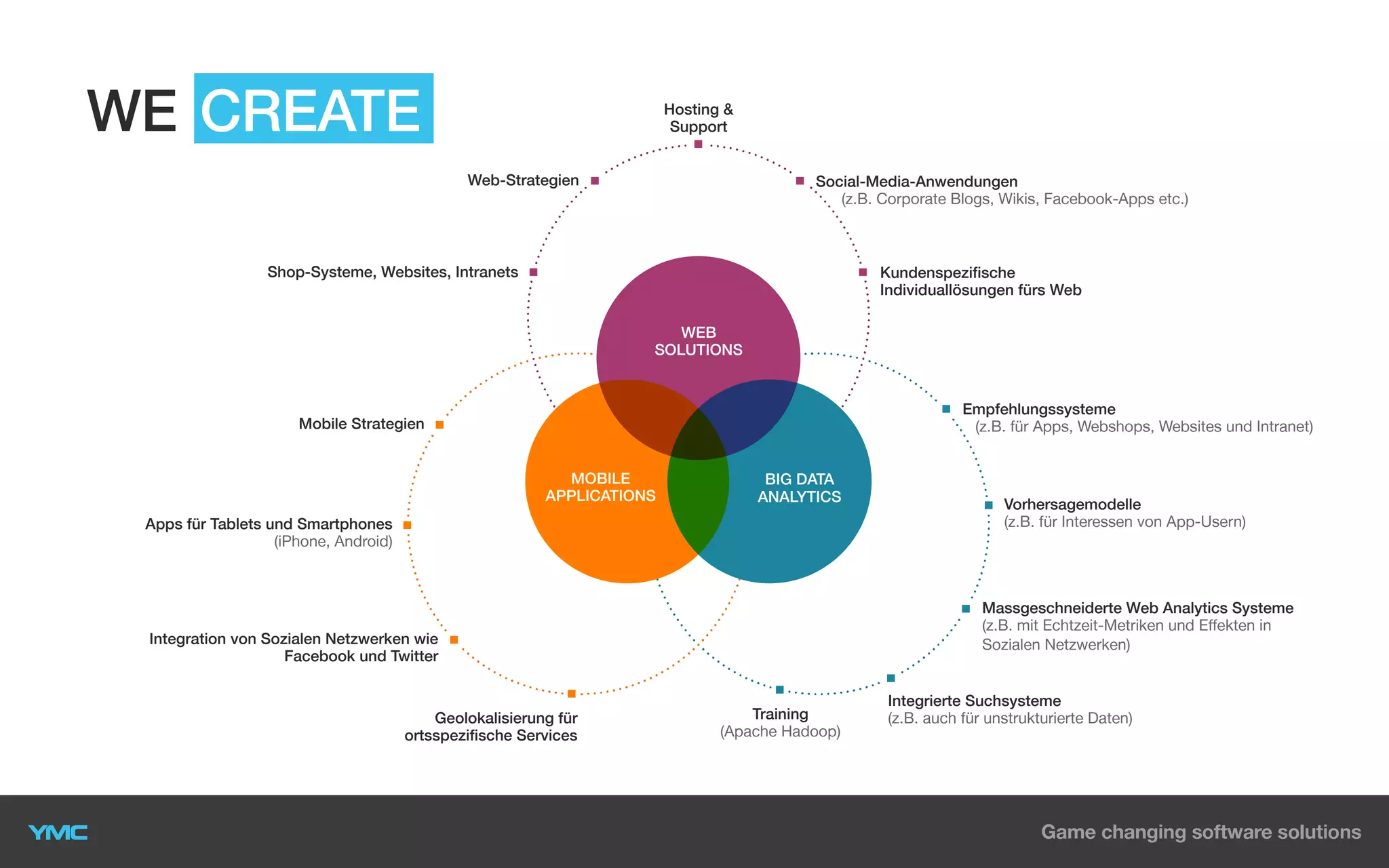








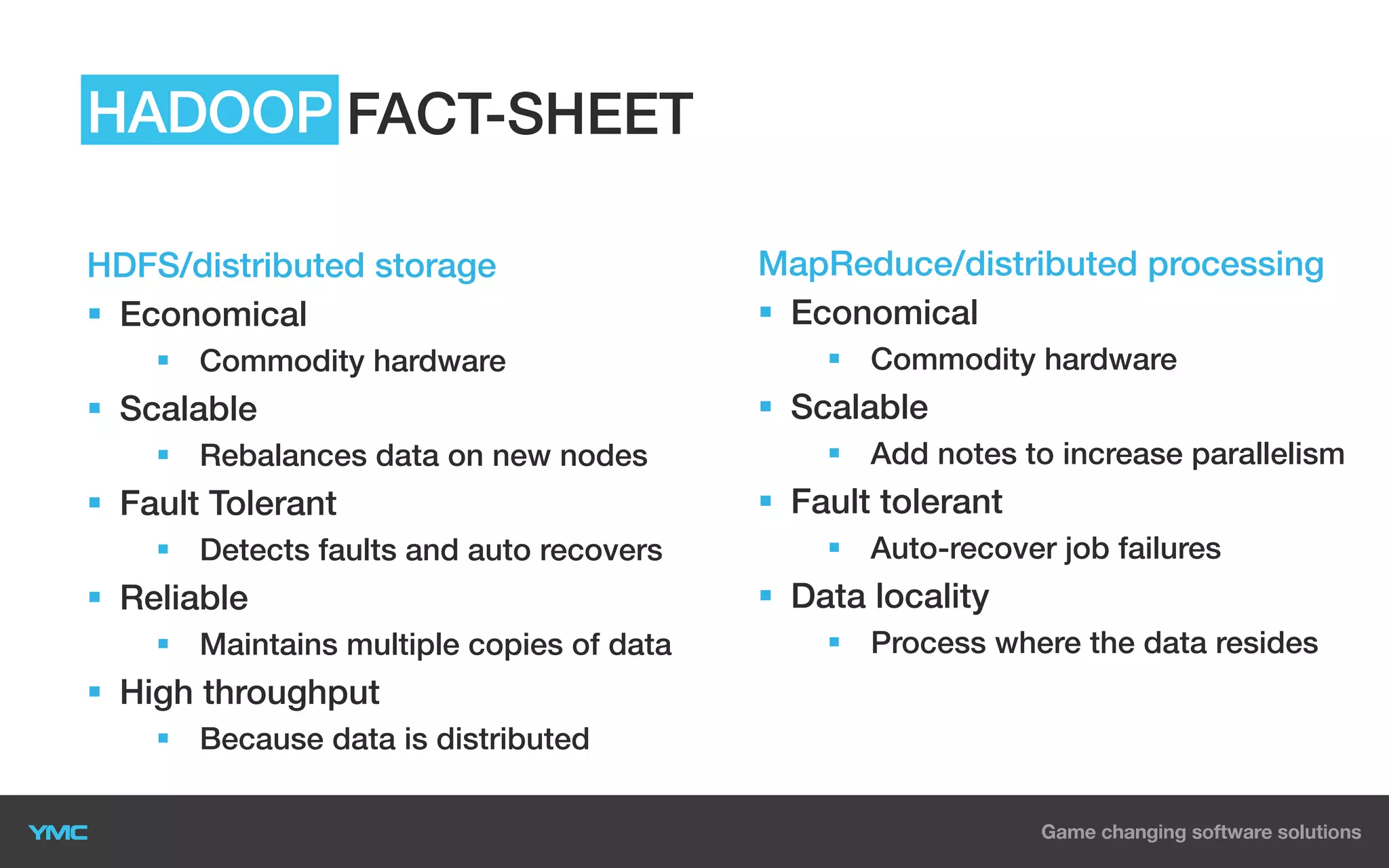

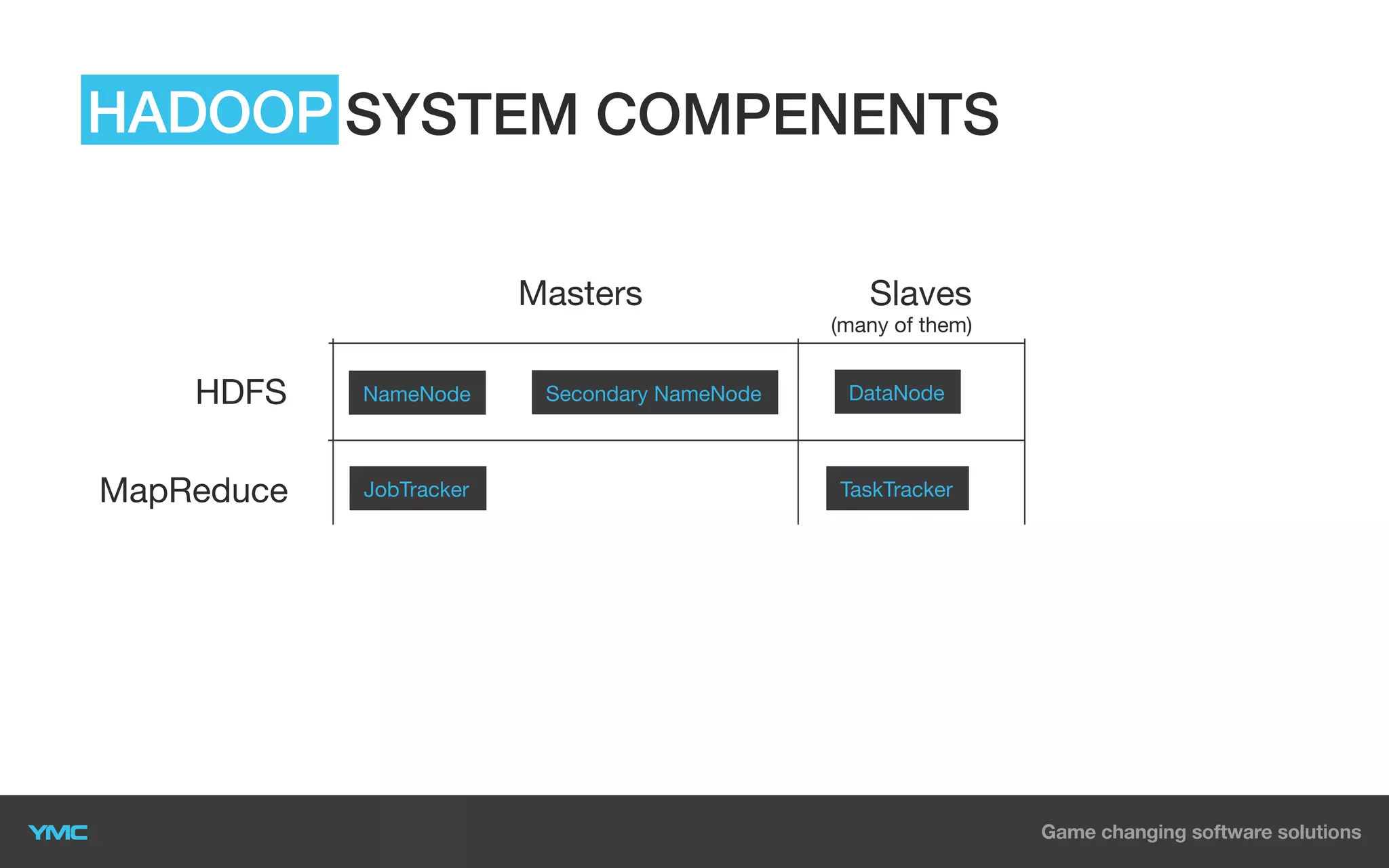
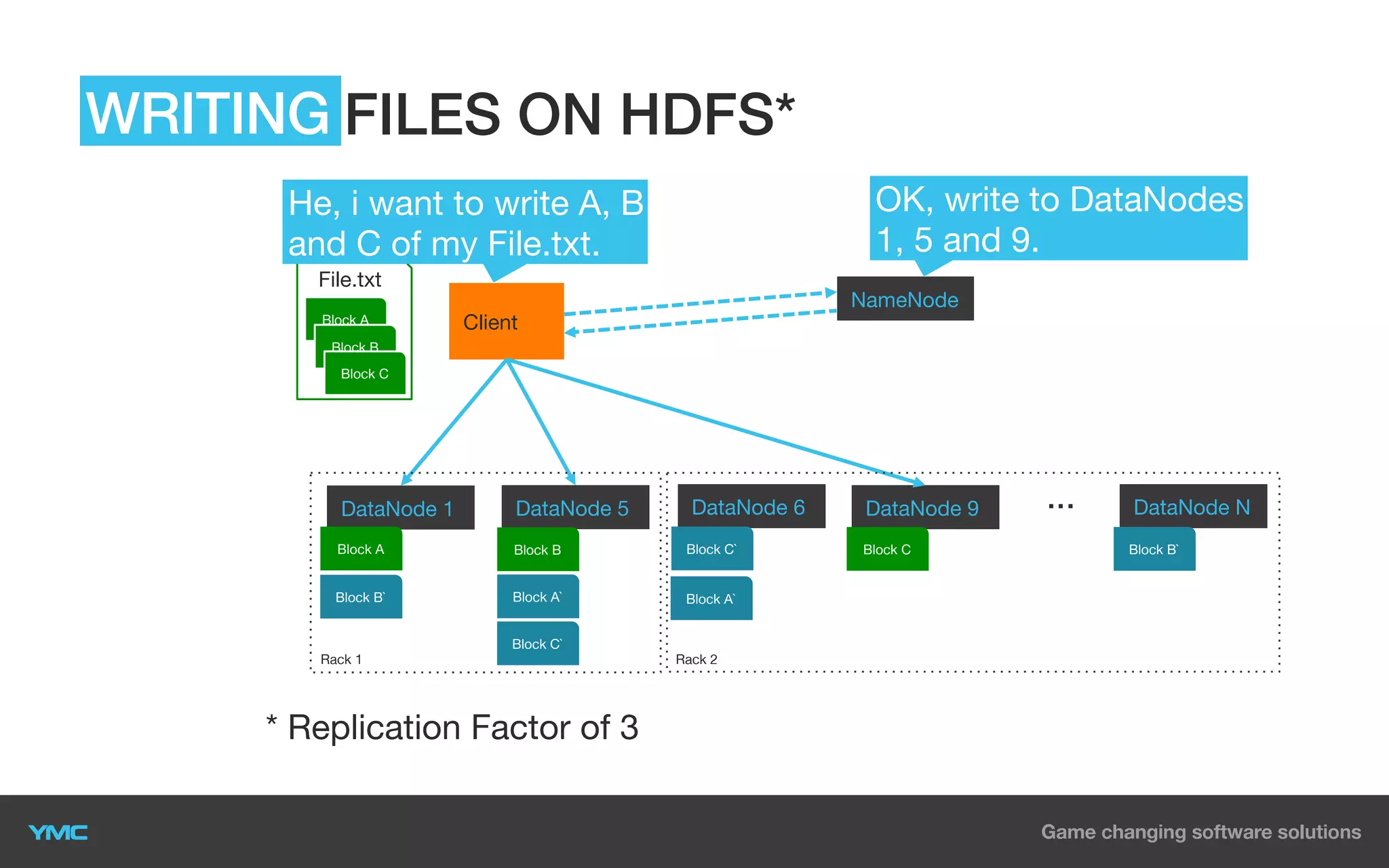
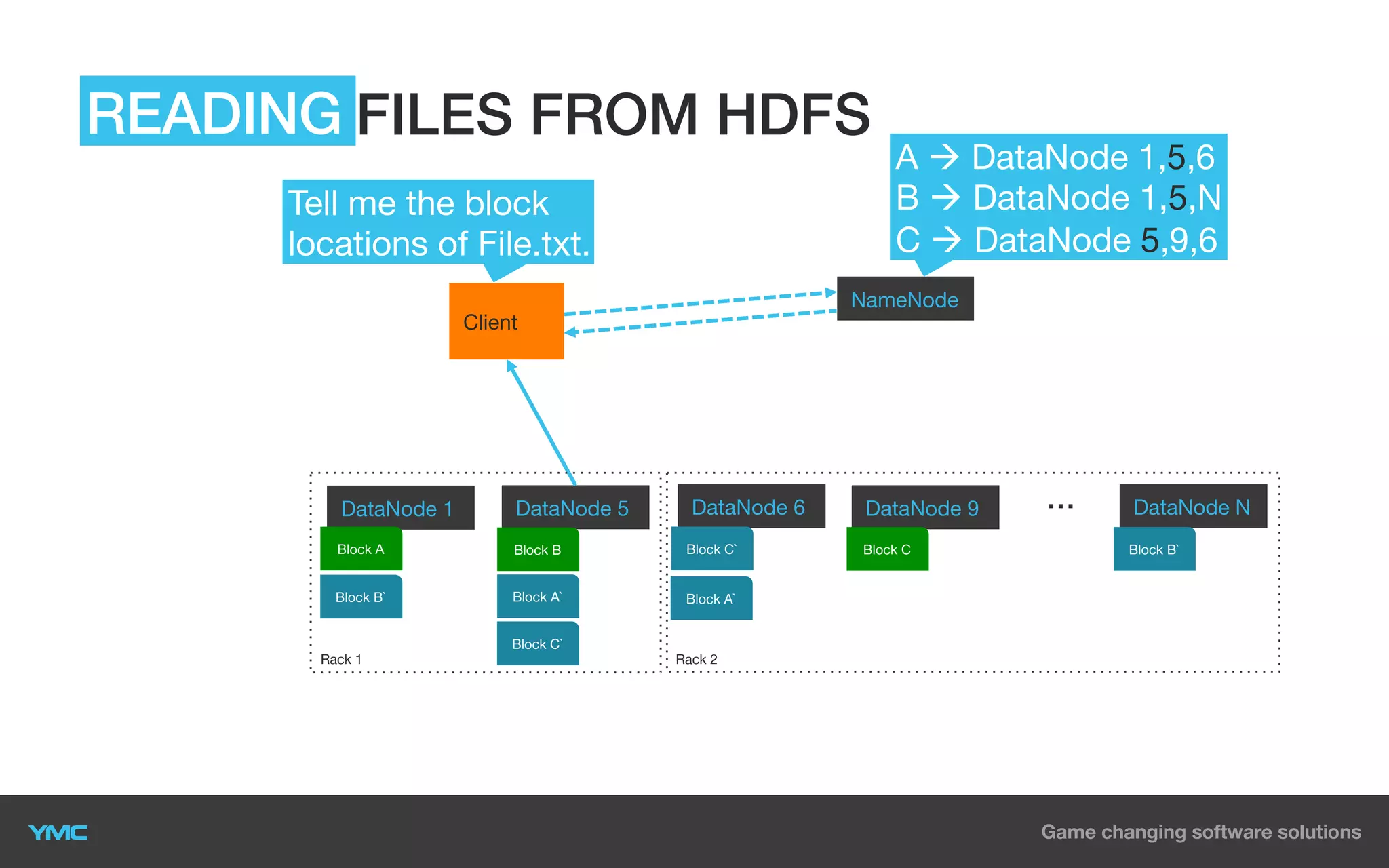
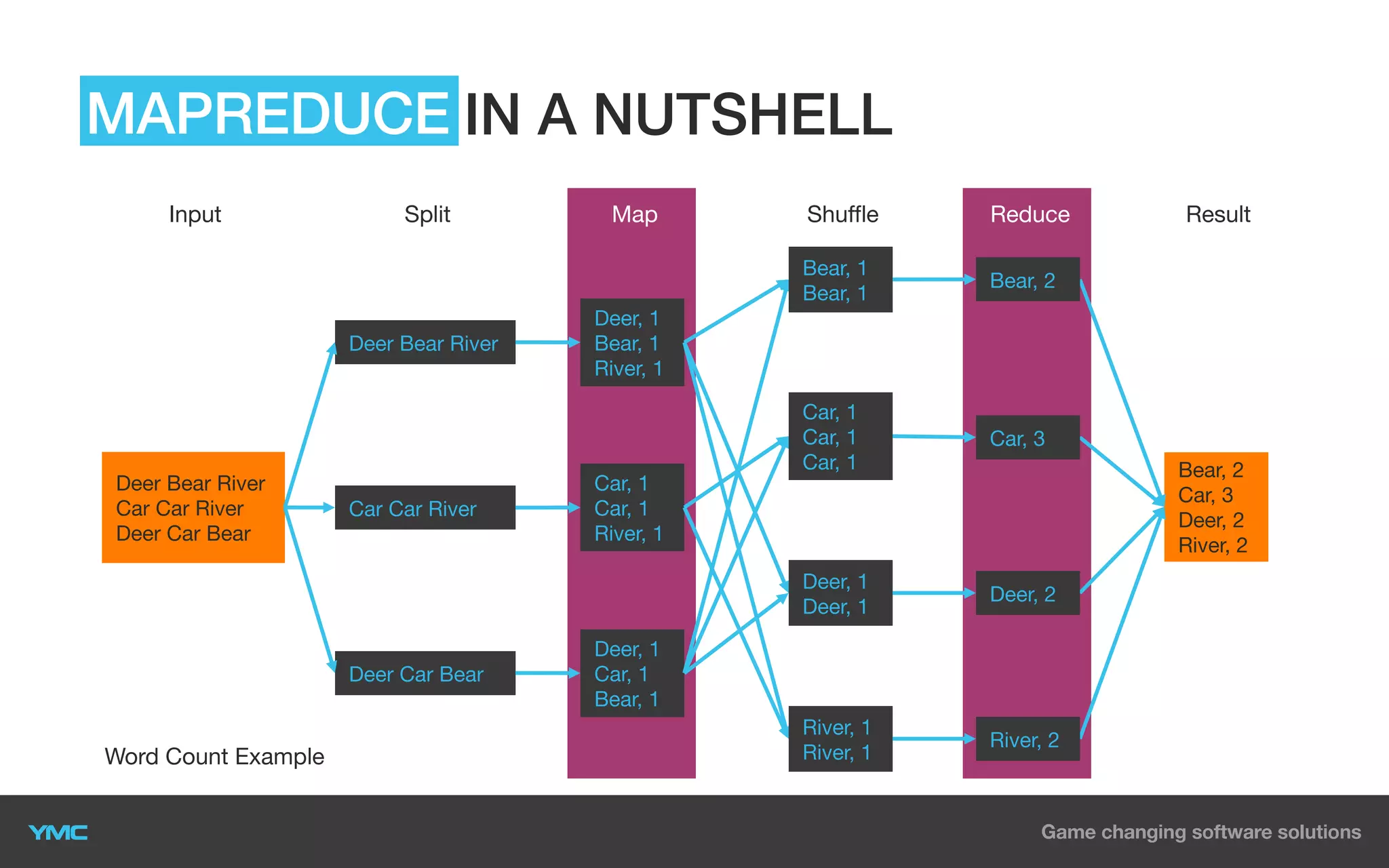


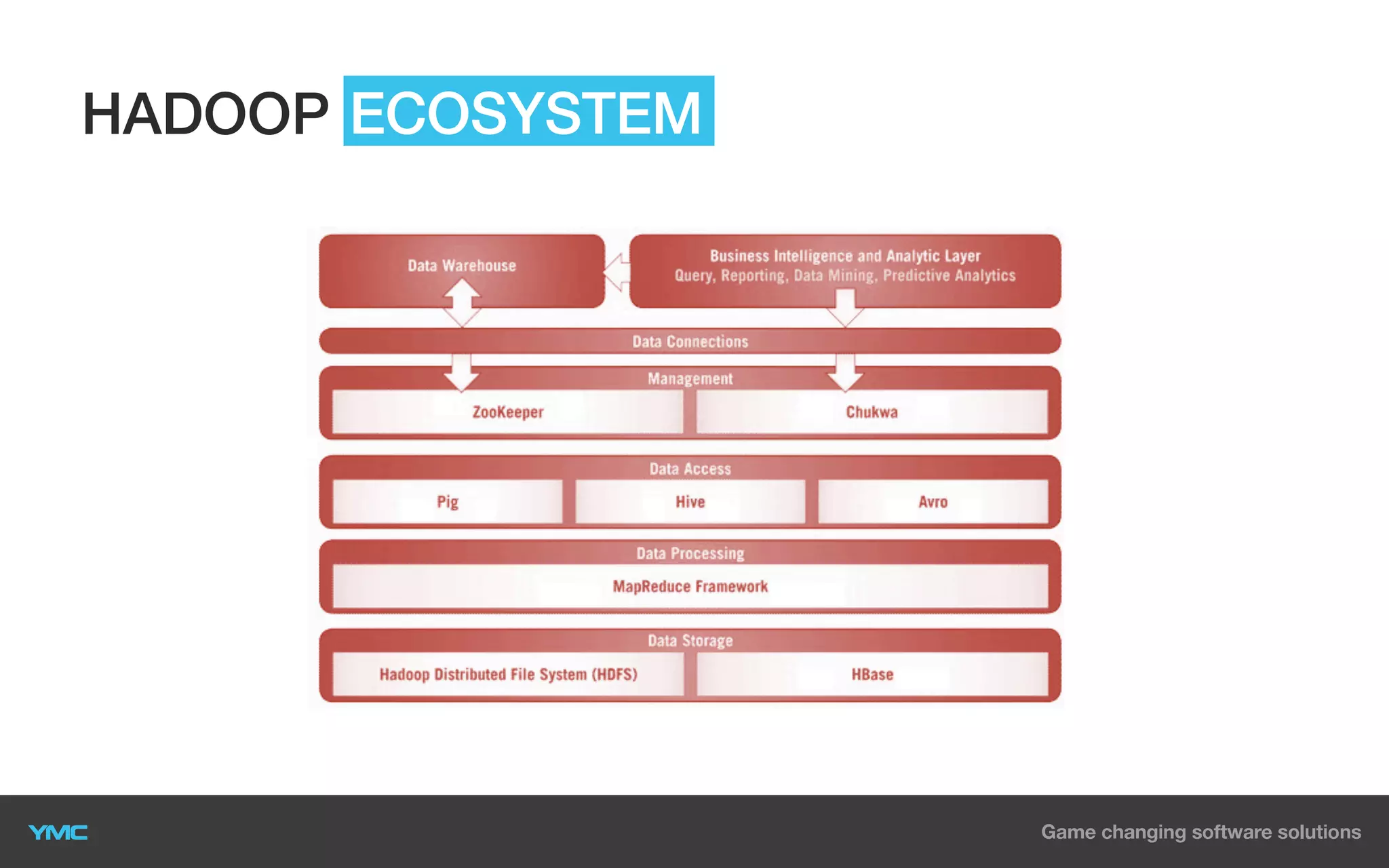


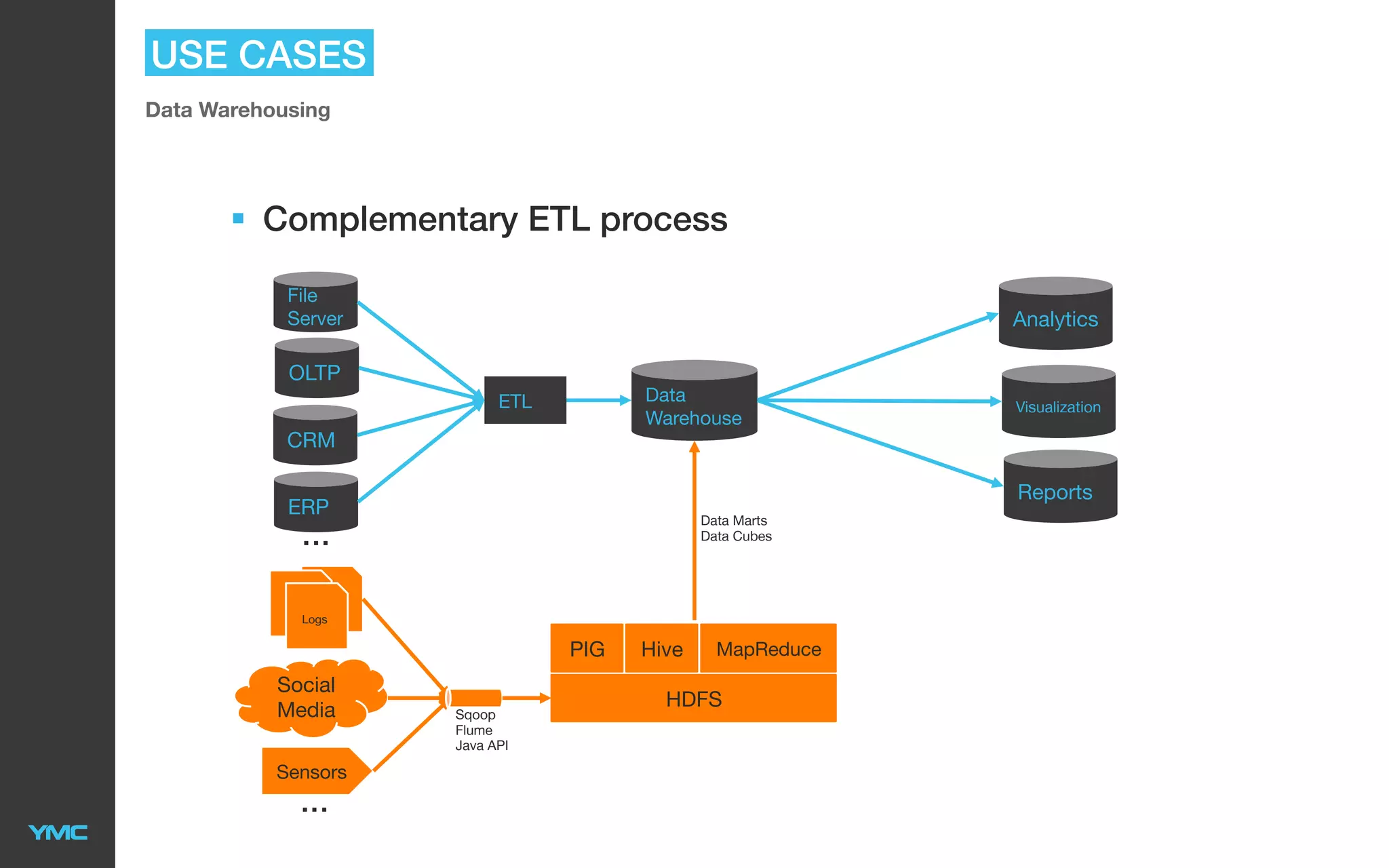
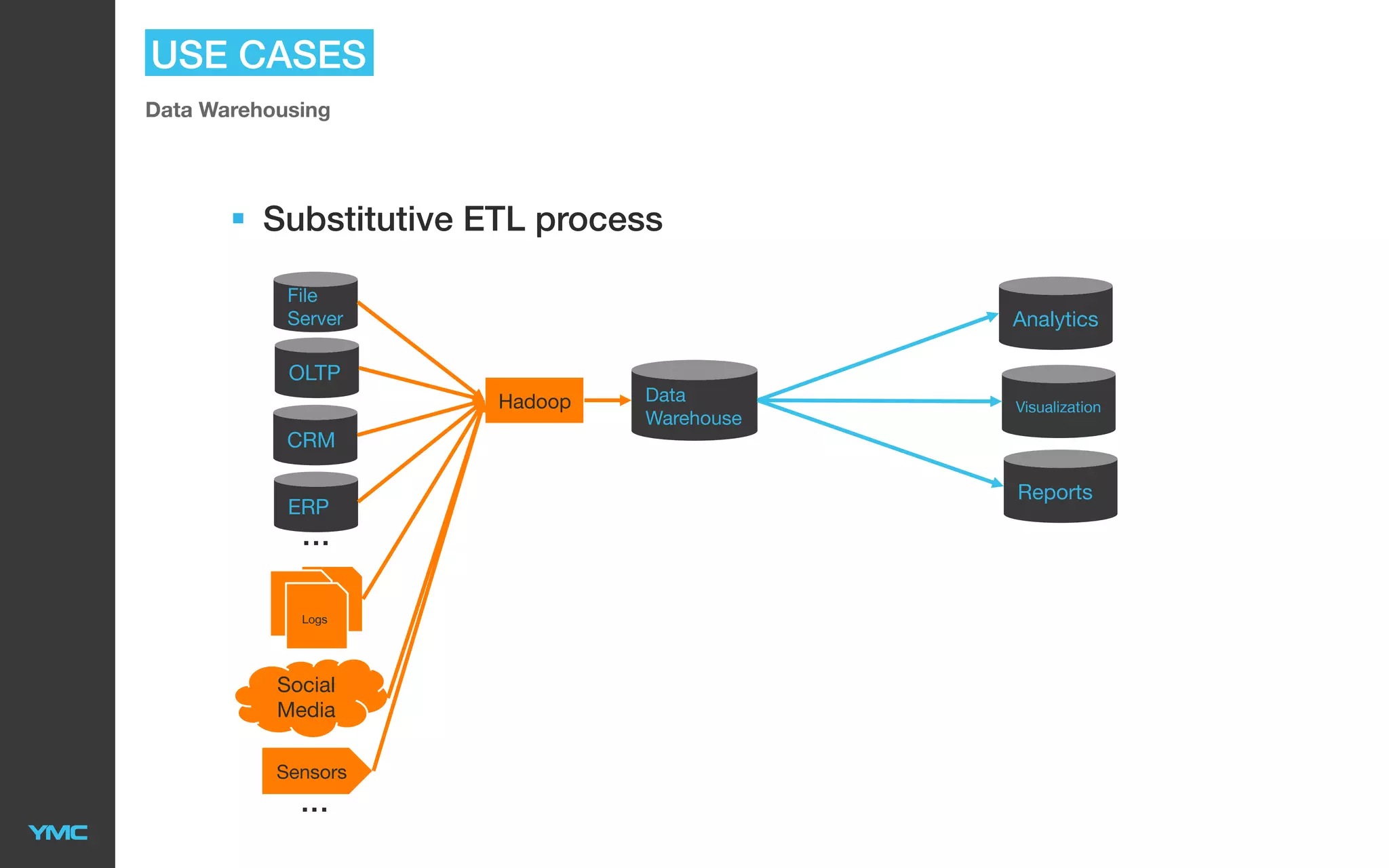
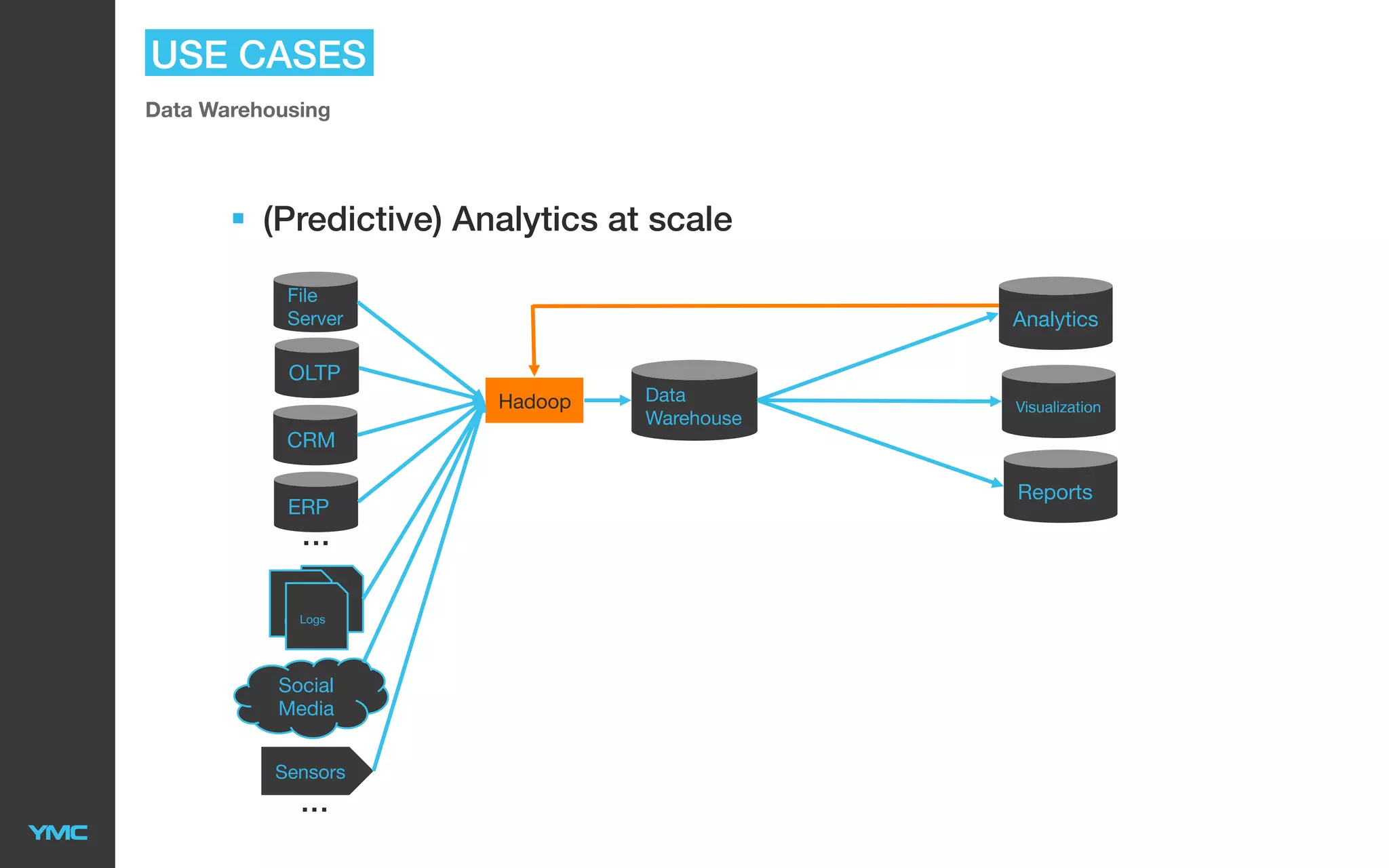
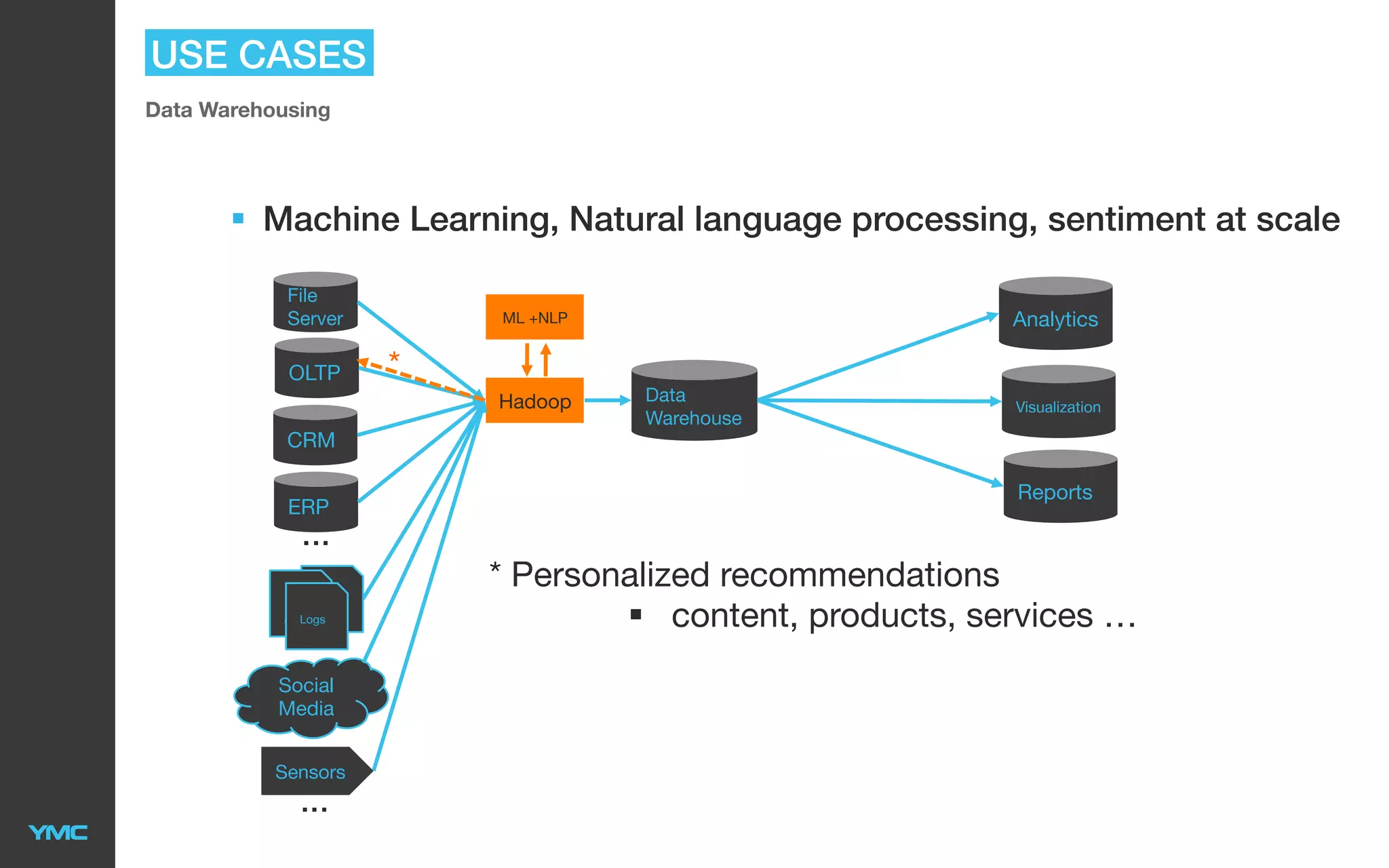



This document provides an overview of Big Data and Hadoop. It defines Big Data as large and complex datasets that are difficult to process using traditional databases and systems. The three V's of Big Data are described as high volume, velocity, and variety. Hadoop is introduced as an open-source software framework for distributed storage and processing of large datasets across clusters of commodity servers. Key components of Hadoop including HDFS for storage and MapReduce for distributed processing are summarized. Example use cases for Hadoop in data warehousing and analytics are also outlined.






















































![[BDD 2025 - Artificial Intelligence] Building AI Systems That Users (and Comp...](https://cdn.slidesharecdn.com/ss_thumbnails/ai-buildingaisystemsthatusersandcompanieslove-251124030845-038f7732-thumbnail.jpg?width=640&height=640&fit=bounds)
![[BDD 2025 - Mobile Development] Exploring Apple’s On-Device FoundationModels](https://cdn.slidesharecdn.com/ss_thumbnails/md-exploringappleson-devicefoundationmodels-251124030840-d690542c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[BDD 2025 - Full-Stack Development] Digital Accessibility: Why Developers nee...](https://cdn.slidesharecdn.com/ss_thumbnails/fs-digitalaccessibilitywhydevelopersneedtoknowandcarein2025-251127011019-0674441d-thumbnail.jpg?width=640&height=640&fit=bounds)














