Downloaded 36 times


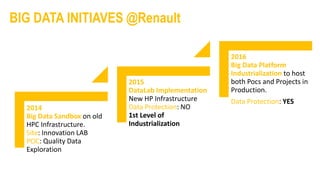


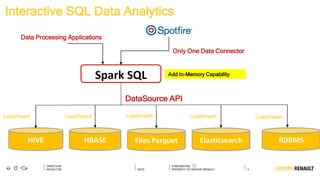
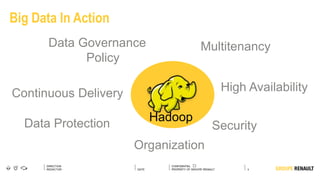
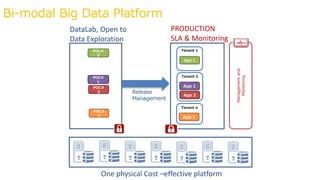
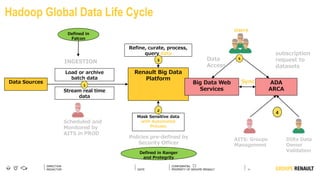
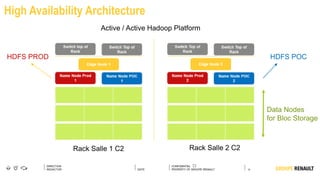
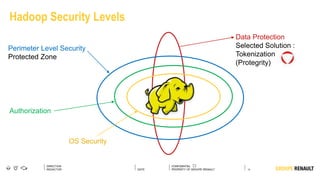
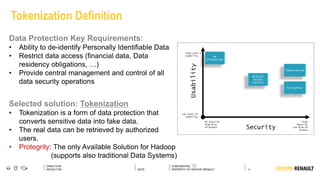

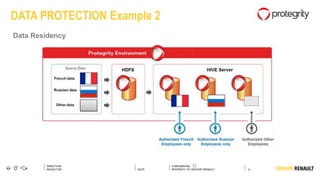
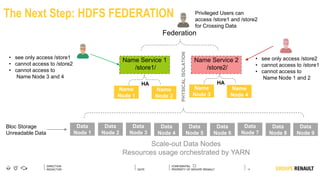
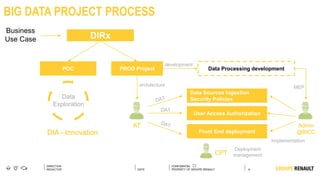

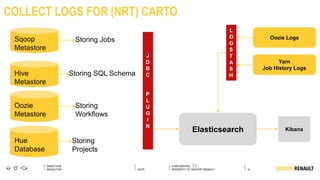
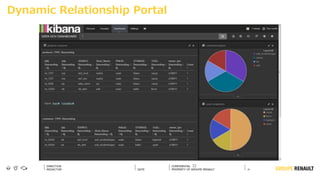


The document outlines Renault's big data initiatives from 2014-2016, including: 1. Starting with a big data sandbox in 2014 using an old HPC infrastructure for data exploration. 2. Implementing a DataLab in 2015 with a new HP infrastructure and establishing a first level of industrialization while improving data protection. 3. Creating a big data platform in 2016 to industrialize hosting both proofs of concept and production projects while ensuring data protection.













































![[D2 COMMUNITY] Spark User Group - 스파크를 통한 딥러닝 이론과 실제](https://cdn.slidesharecdn.com/ss_thumbnails/520160211-160307085845-thumbnail.jpg?width=640&height=640&fit=bounds)




























































