Download as PDF, PPTX

























![YOUR_CUSTOM_CONF.yaml example
37
docker:
memory_limit: "4g"
image: "bigtop/puppet:centos-7"
repo: "http://bigtop-repos.s3.amazonaws.com/releases/1.2.0/
centos/7/x86_64"
distro: centos
components: [hdfs, yarn, mapreduce]
enable_local_repo: false
smoke_test_components: [hdfs, yarn, mapreduce]](https://image.slidesharecdn.com/leveragingdockerforhadoopbuildautomationandbigdatastackprovisioningdataworkssummit2017-170621165935/85/Leveraging-docker-for-hadoop-build-automation-and-big-data-stack-provisioning-37-320.jpg)






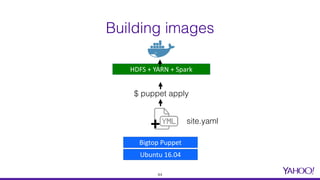
![site.yaml example
45
bigtop::hadoop_head_node: bigtop.example.com
bigtop::bigtop_repo_uri: http://bigtop-repos.s3.amazonaws.com/
releases/1.2.0/debian/8/x86_64
hadoop::hadoop_storage_dirs: [/data/1, /data/2]
hadoop_cluster_node::cluster_components: [hdfs, yarn, spark]](https://image.slidesharecdn.com/leveragingdockerforhadoopbuildautomationandbigdatastackprovisioningdataworkssummit2017-170621165935/85/Leveraging-docker-for-hadoop-build-automation-and-big-data-stack-provisioning-45-320.jpg)



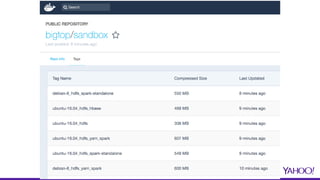
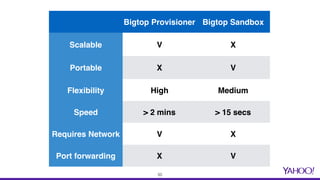
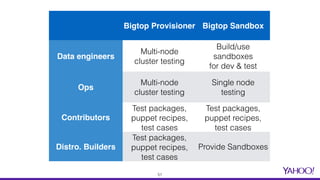
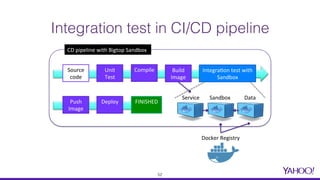










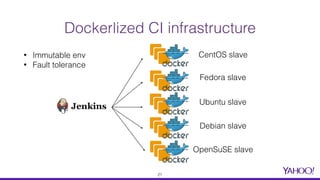
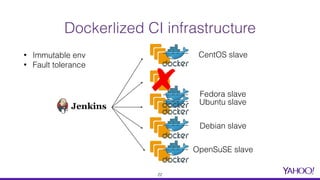
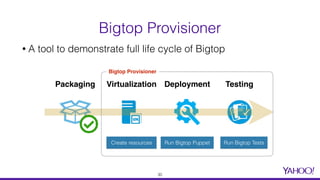
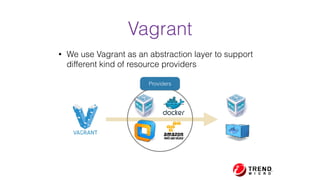
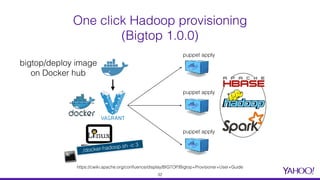
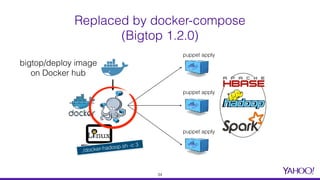
The document presents a comprehensive overview of using Docker for Hadoop build automation and provisioning within the Apache Bigtop ecosystem. It details the various components and tools offered by Bigtop, including packaging, provisioning, and sandbox setups, while also discussing the transition from Vagrant to Docker for better compatibility and performance. The presentation highlights the latest features, enhancements, and upcoming releases, inviting contributions and collaboration within the Apache Bigtop community.








![[OpenStack Day in Korea] Keynote#2 - Bringing OpenStack to the Enterprise Dat...](https://cdn.slidesharecdn.com/ss_thumbnails/koreaopenstackdubuque20140218r7-140218091223-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)


![[OpenStack Day in Korea 2015] Track 1 - Triple O를 이용한 빠르고 쉬운 OpenStack 설치](https://cdn.slidesharecdn.com/ss_thumbnails/11-150213041431-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)



































































