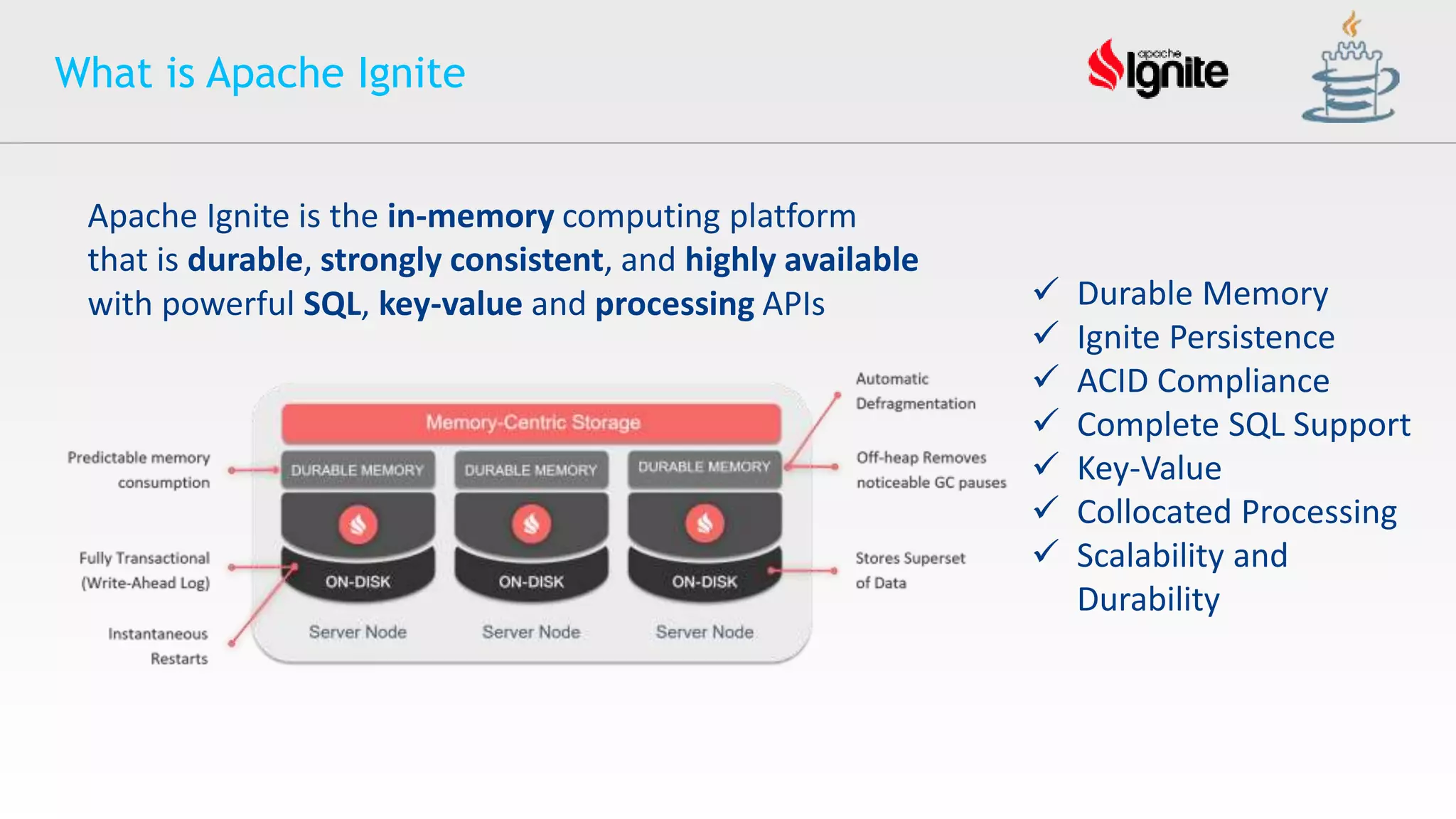
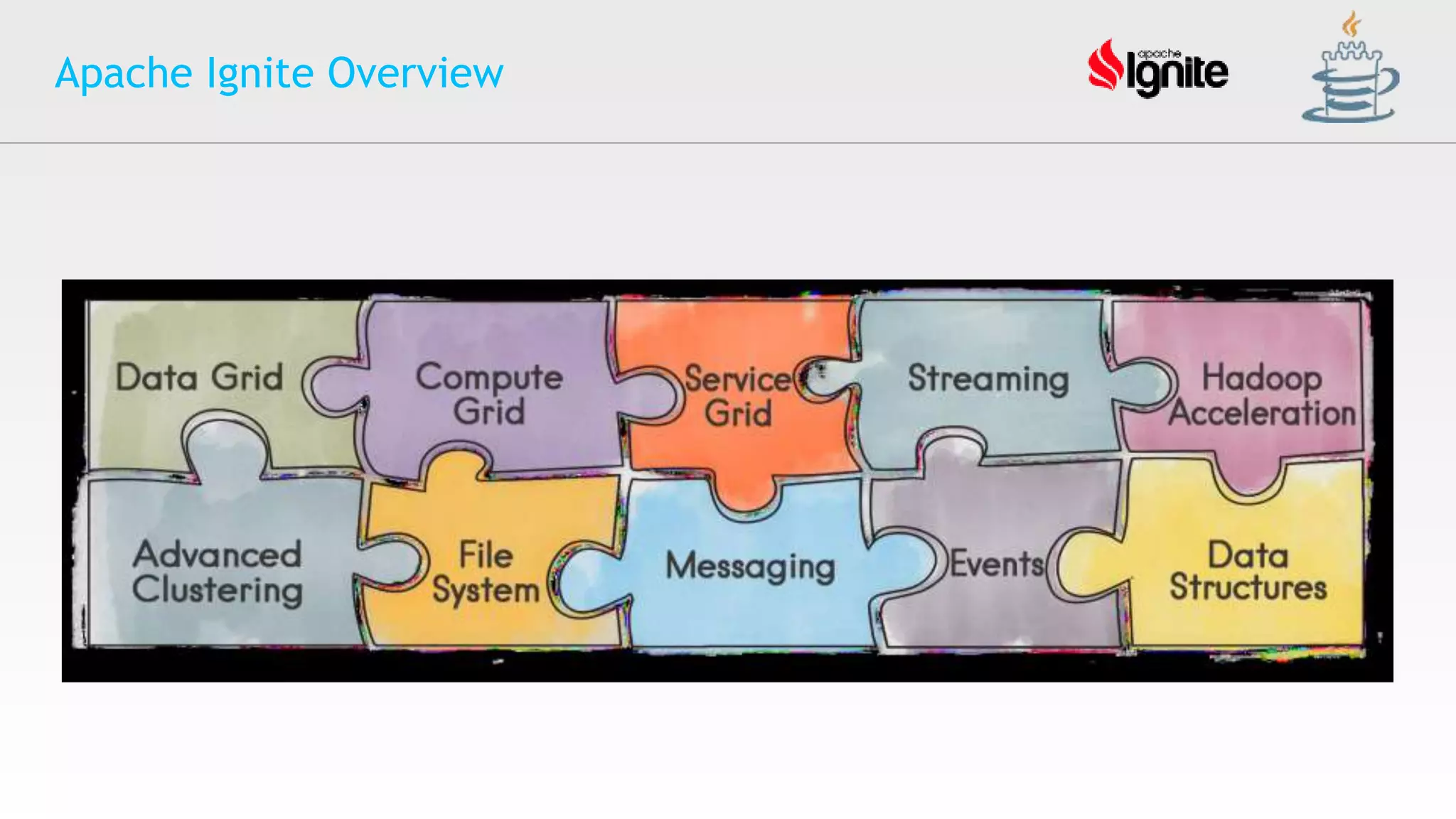
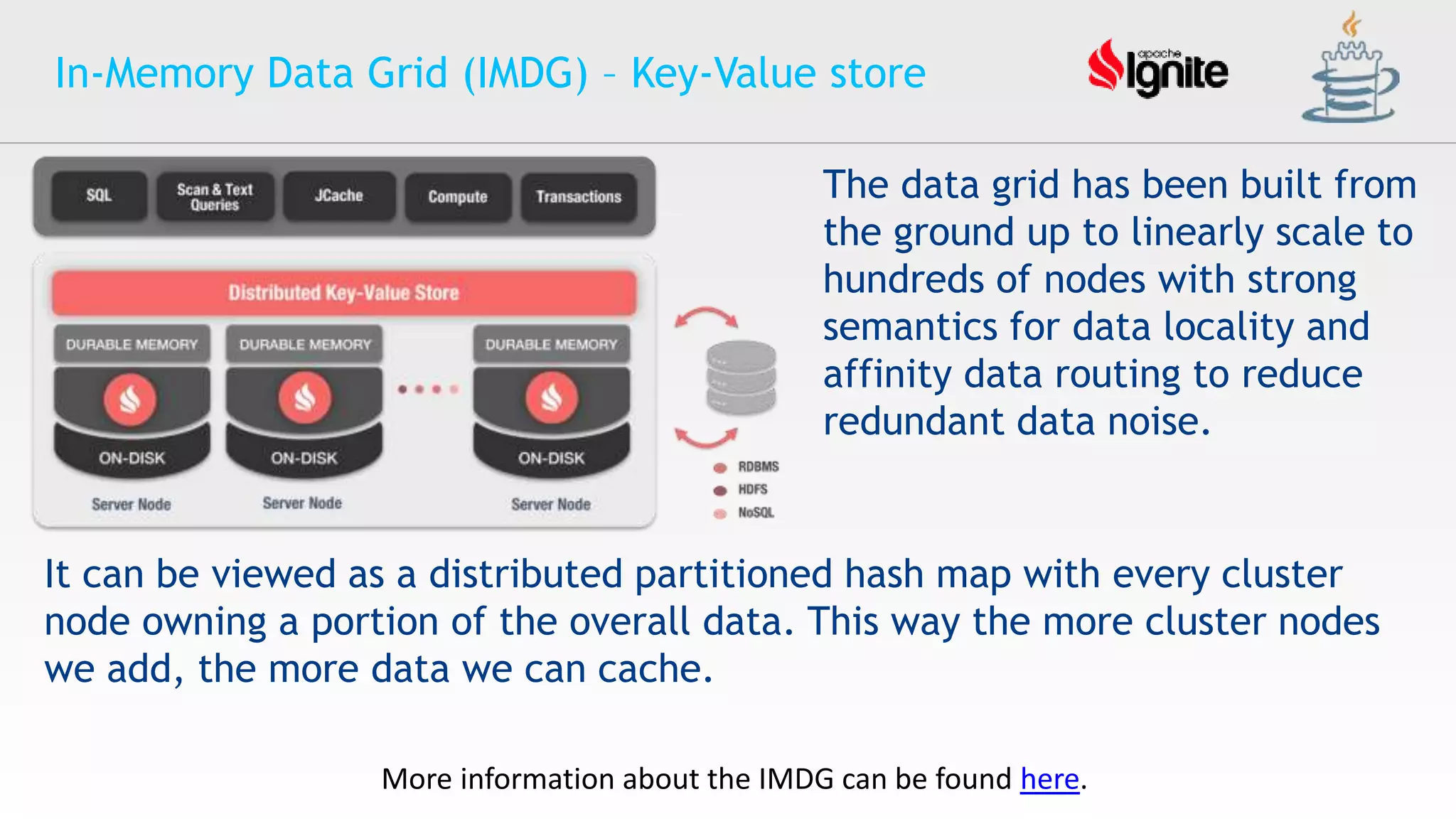
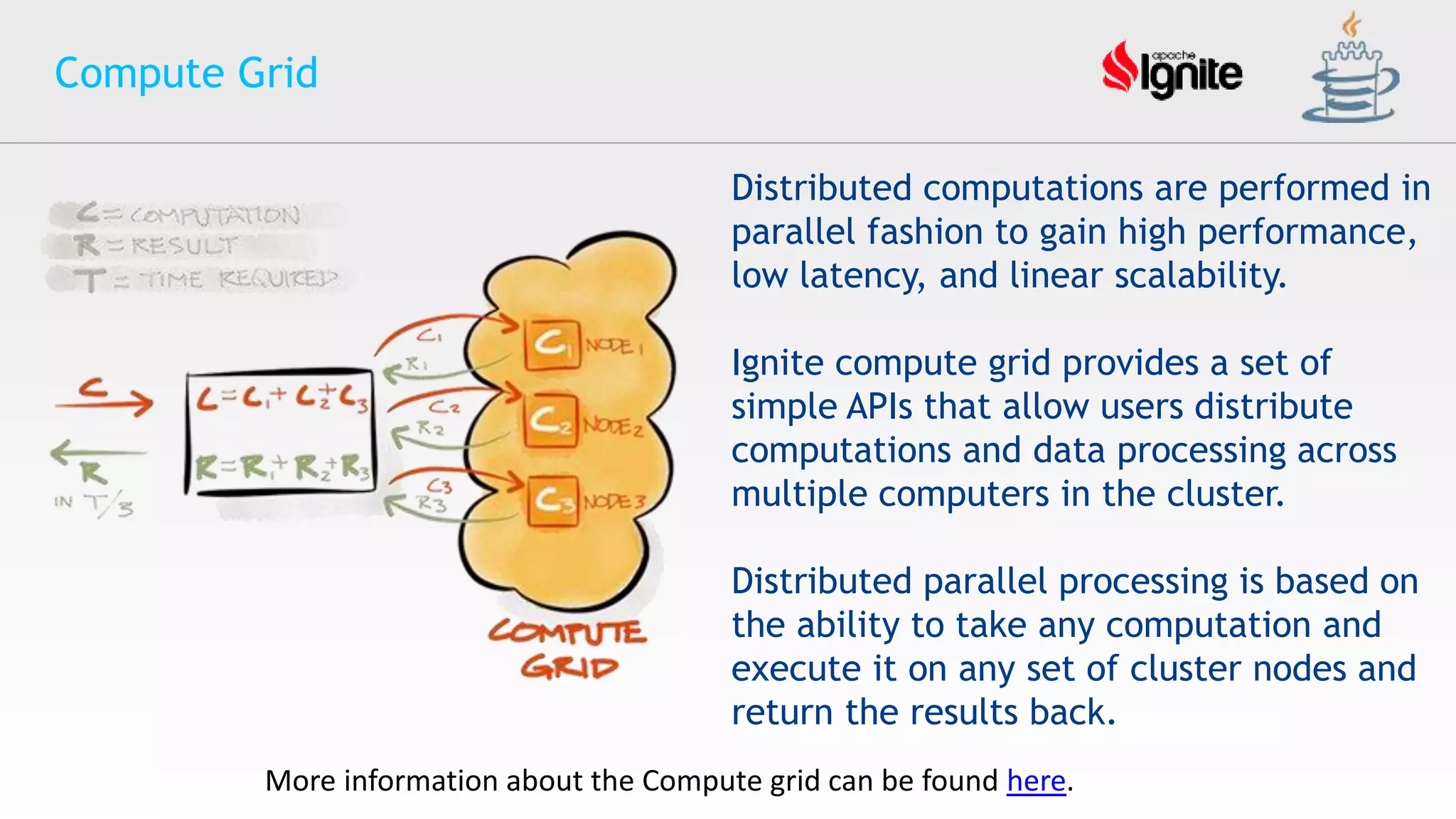
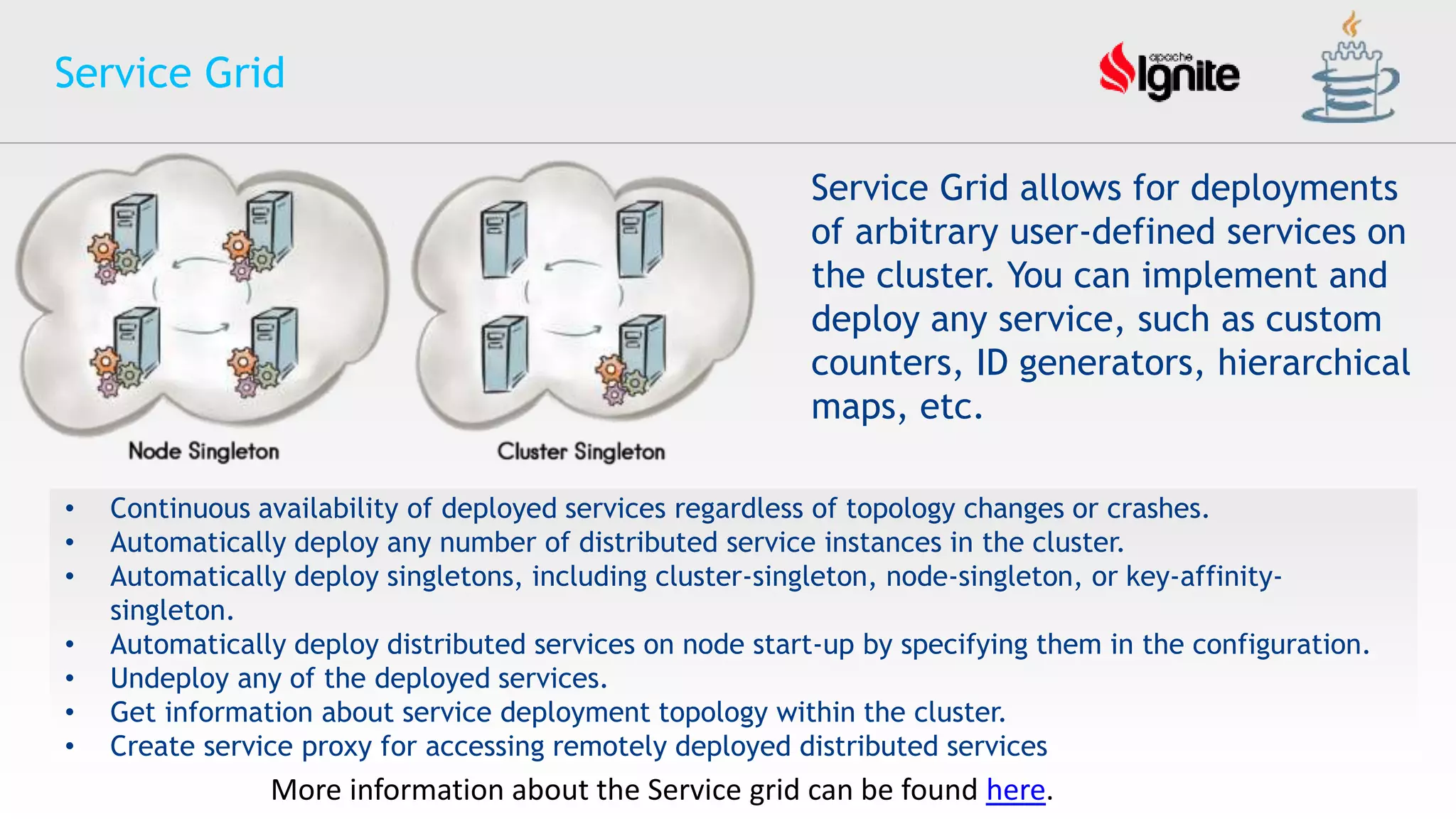
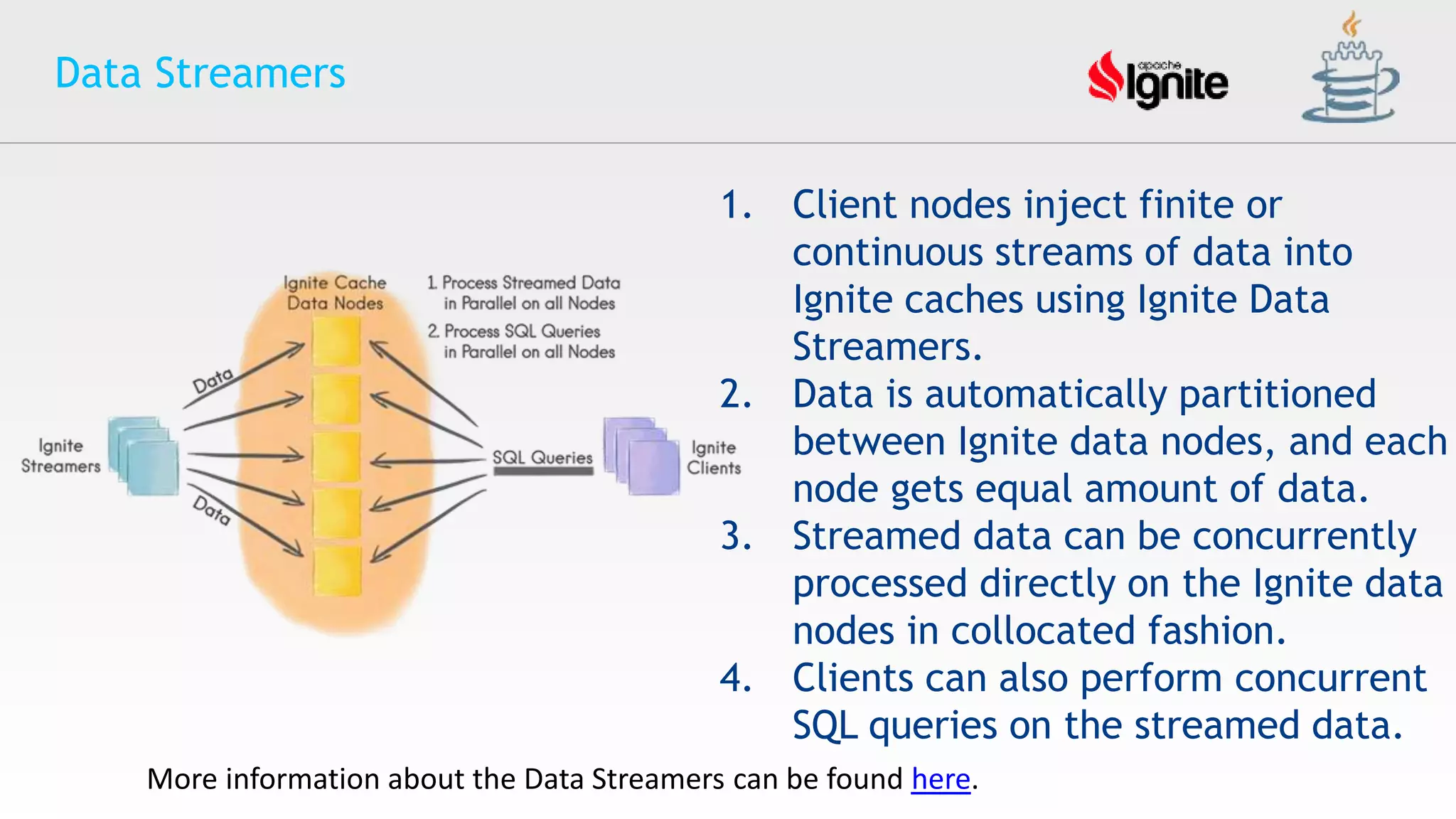
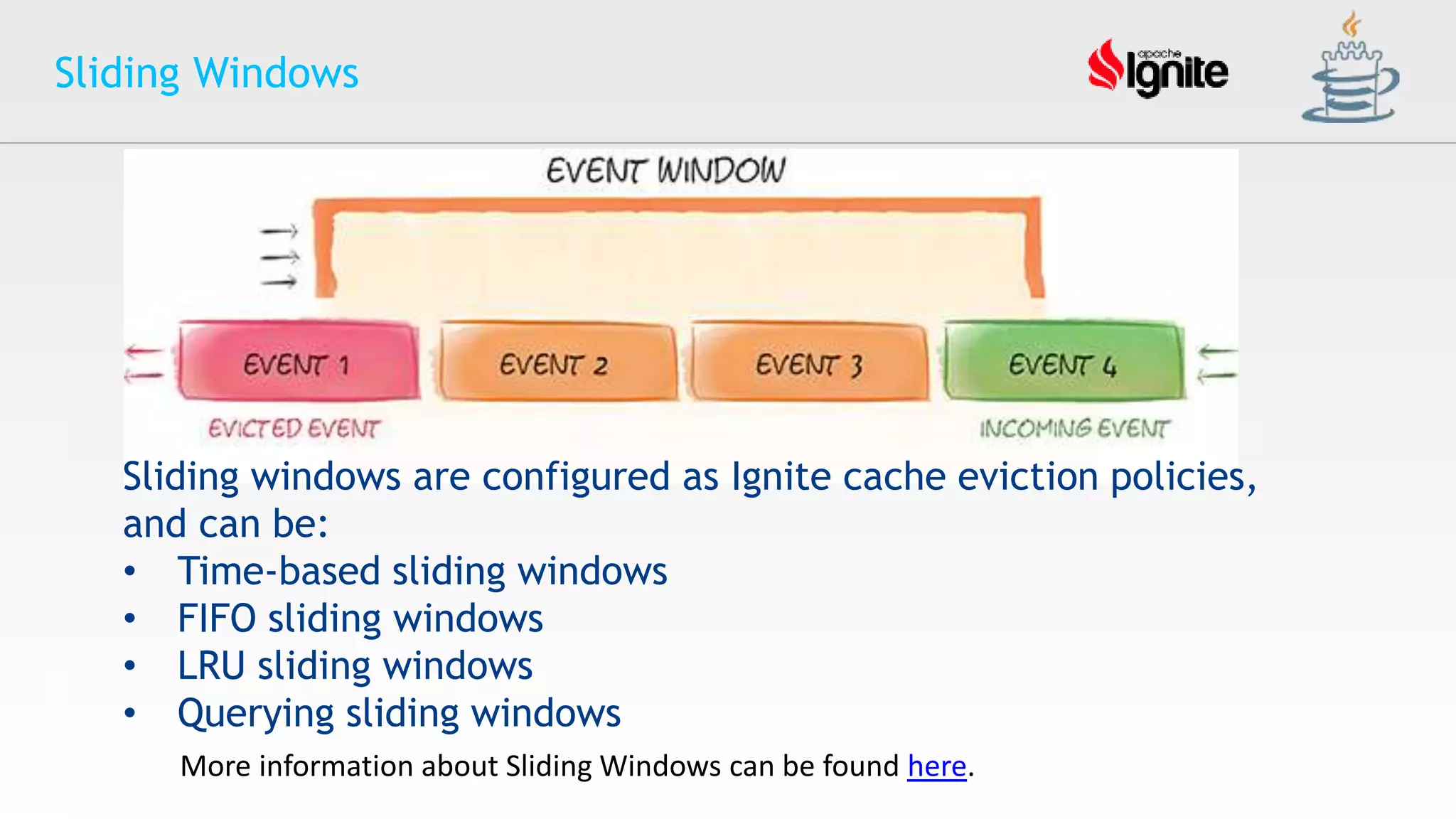
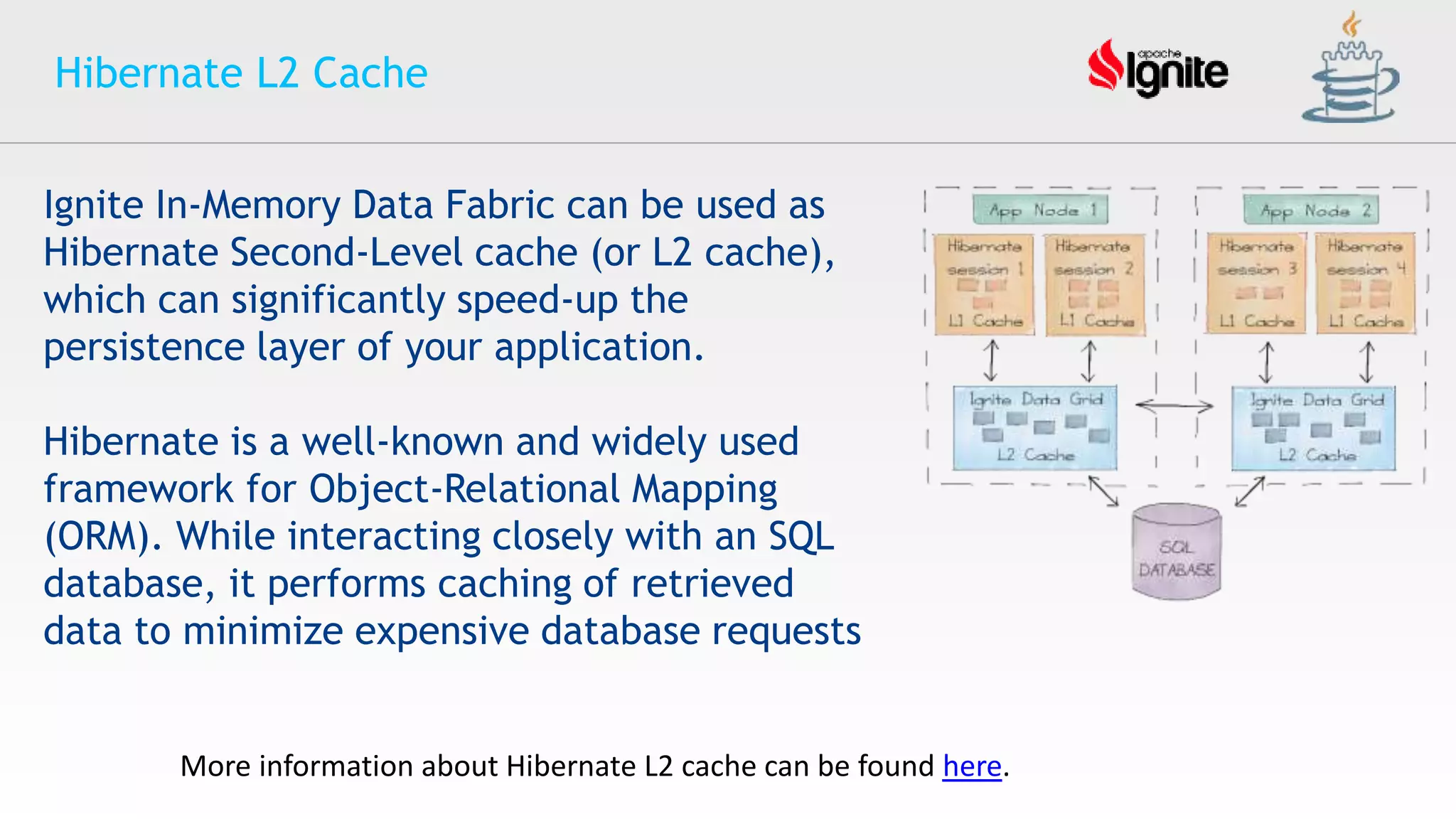
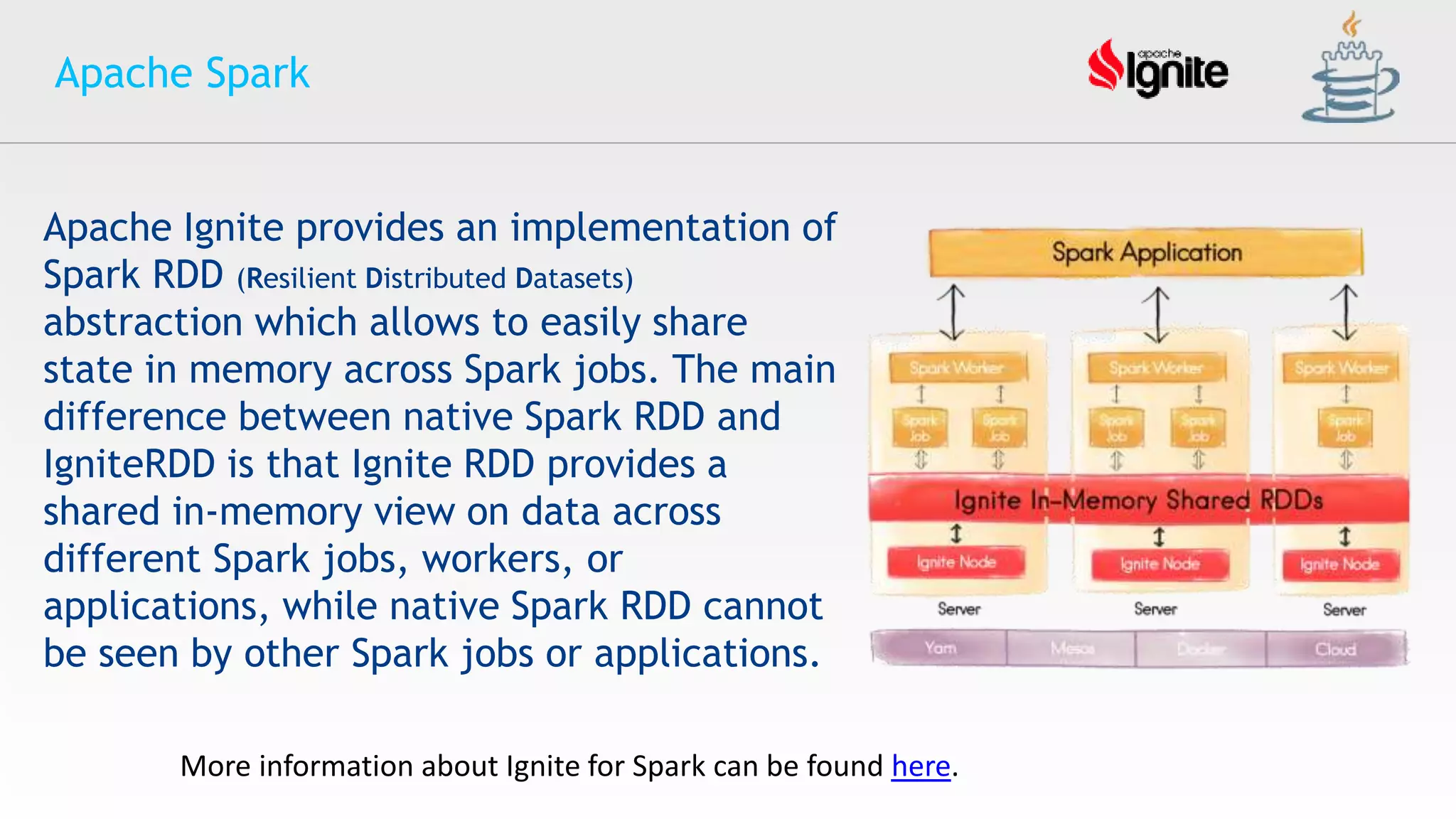
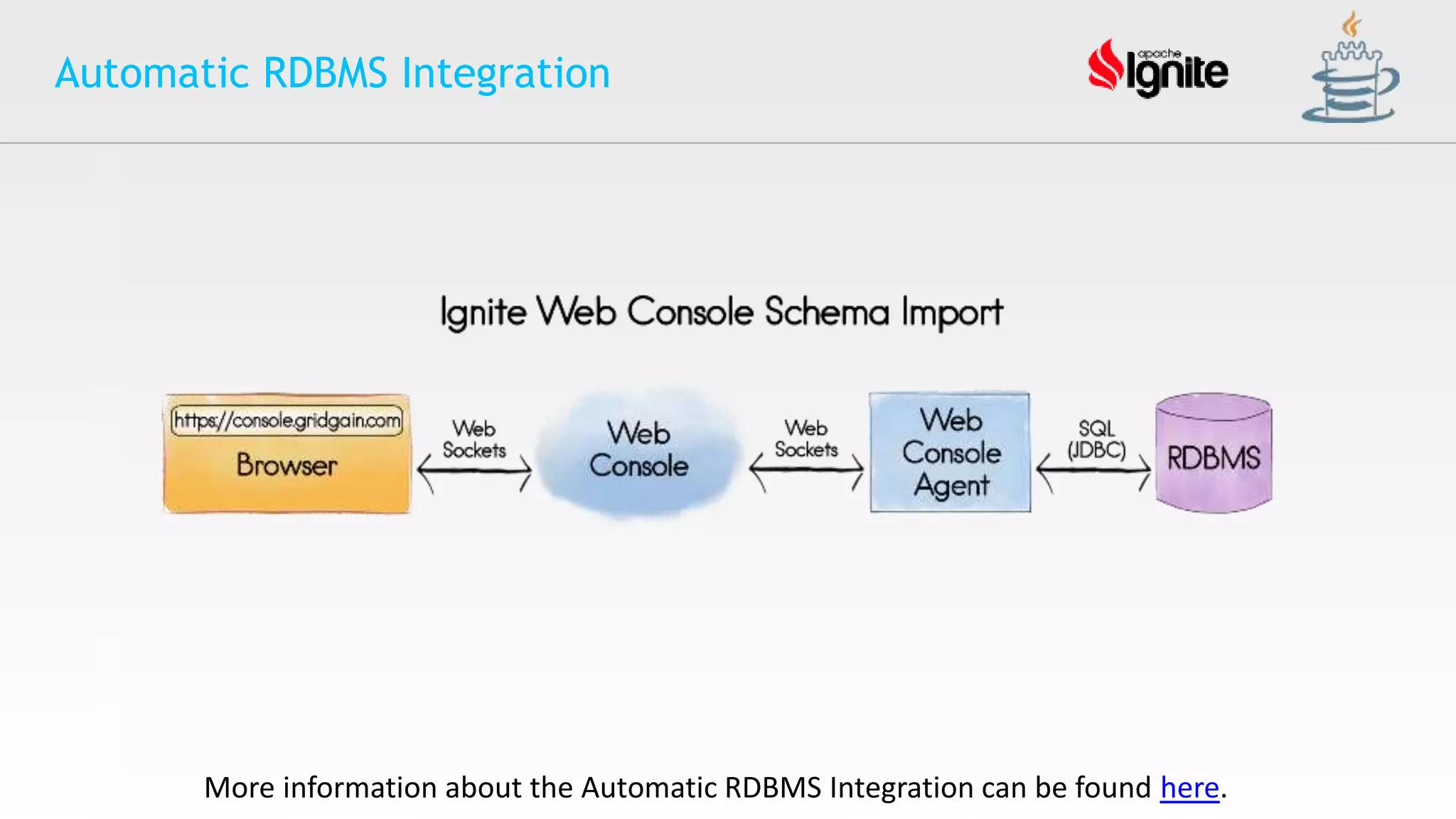
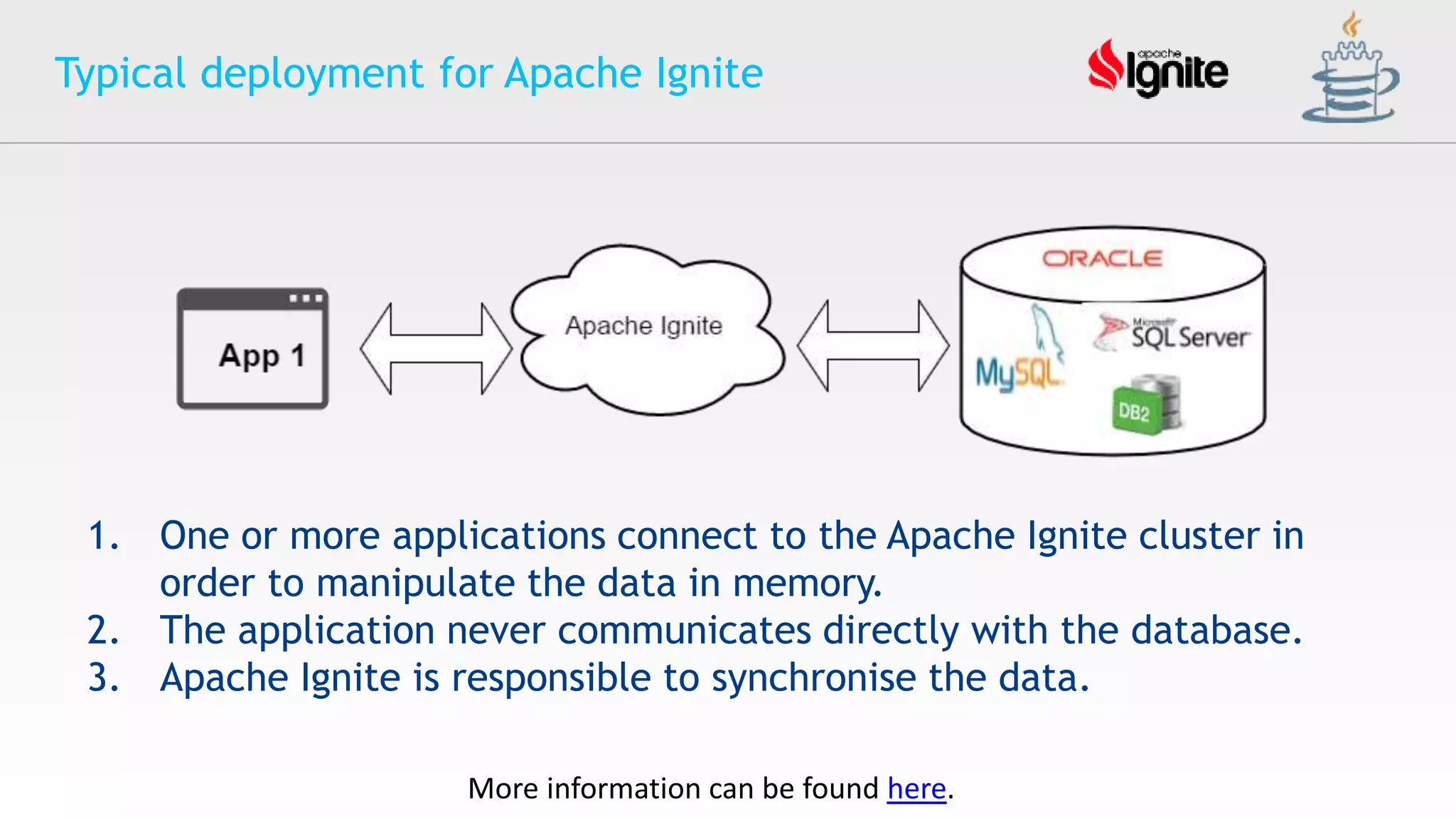
The document provides an overview of Apache Ignite, an in-memory computing platform that enhances the speed and scalability of data-intensive applications. It discusses the limitations of traditional RDBMS and NoSQL solutions and highlights Ignite's key features such as SQL support, ACID compliance, and the ability to integrate with various data storage systems. Additionally, it details Ignite's various functionalities, including compute grids, service grids, and messaging capabilities, while addressing use cases and deployment strategies.
























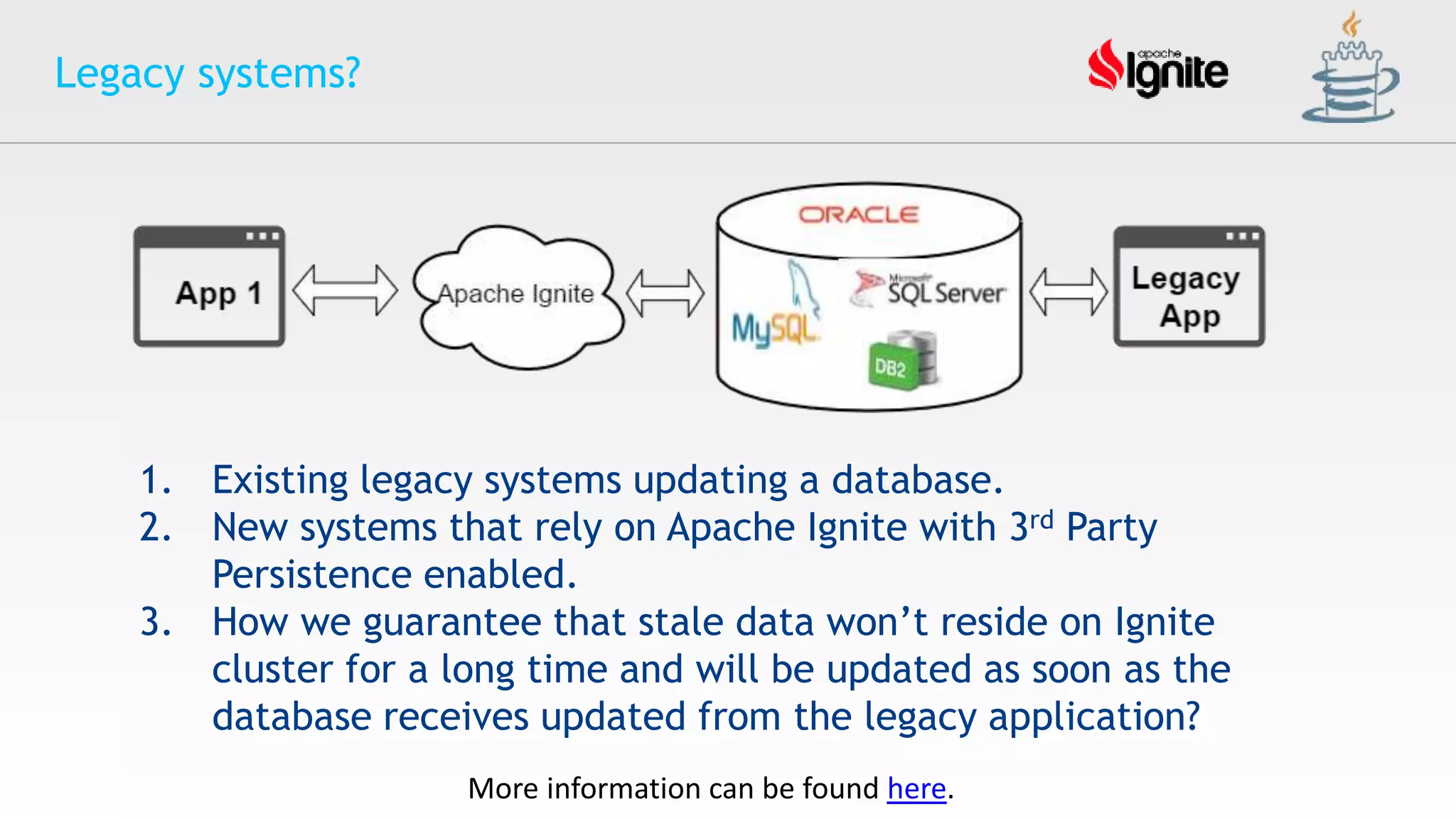
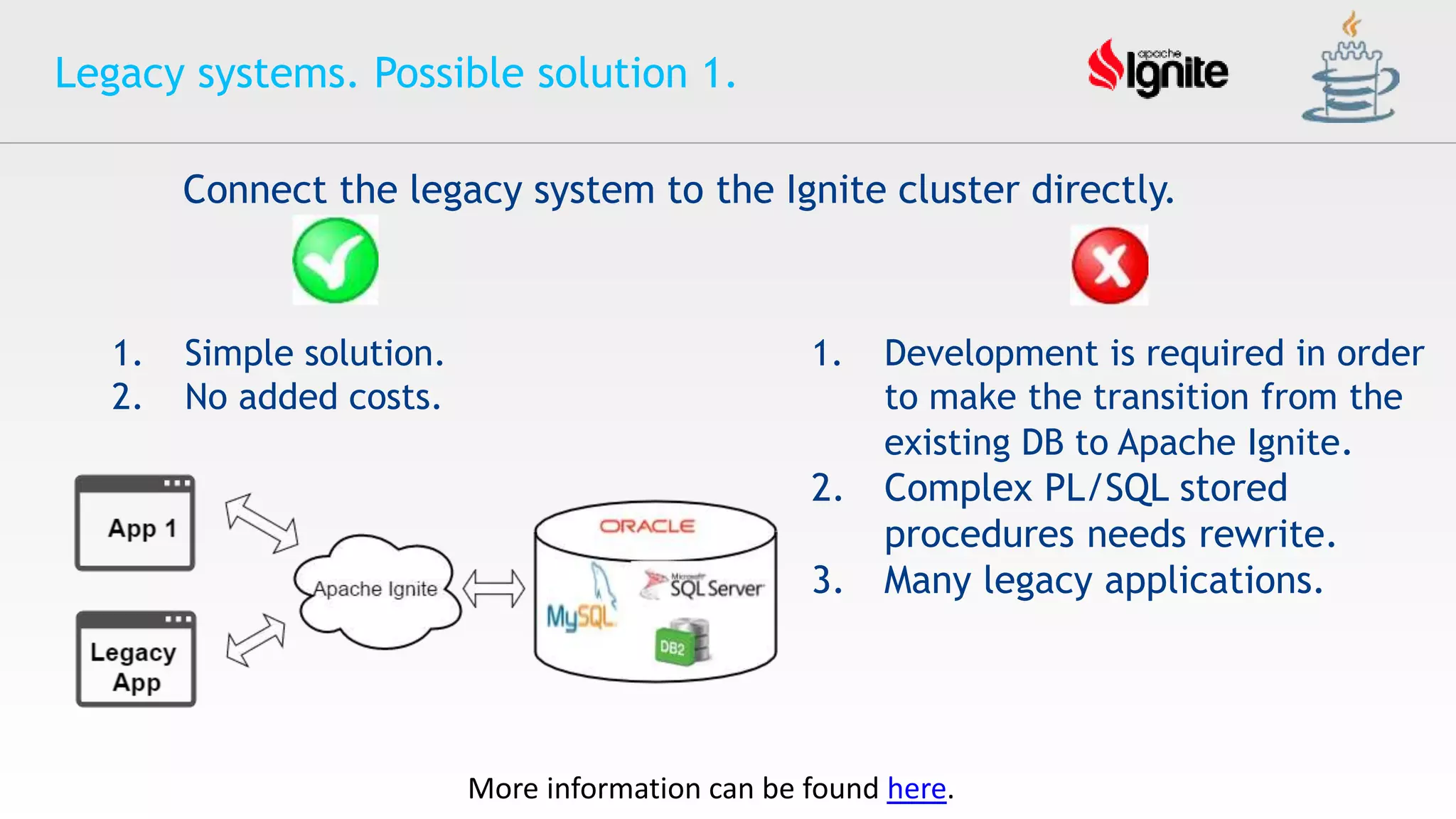
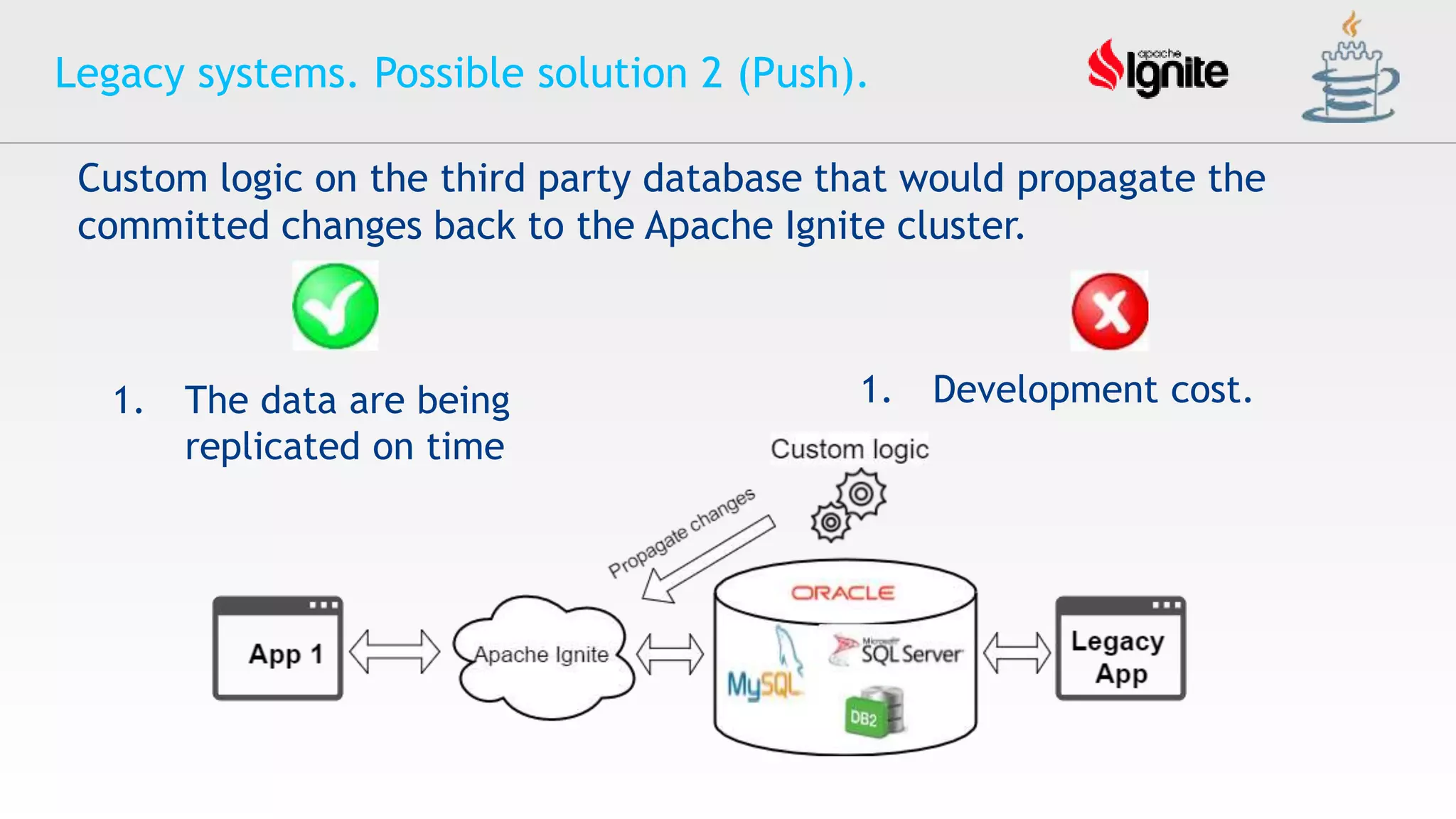
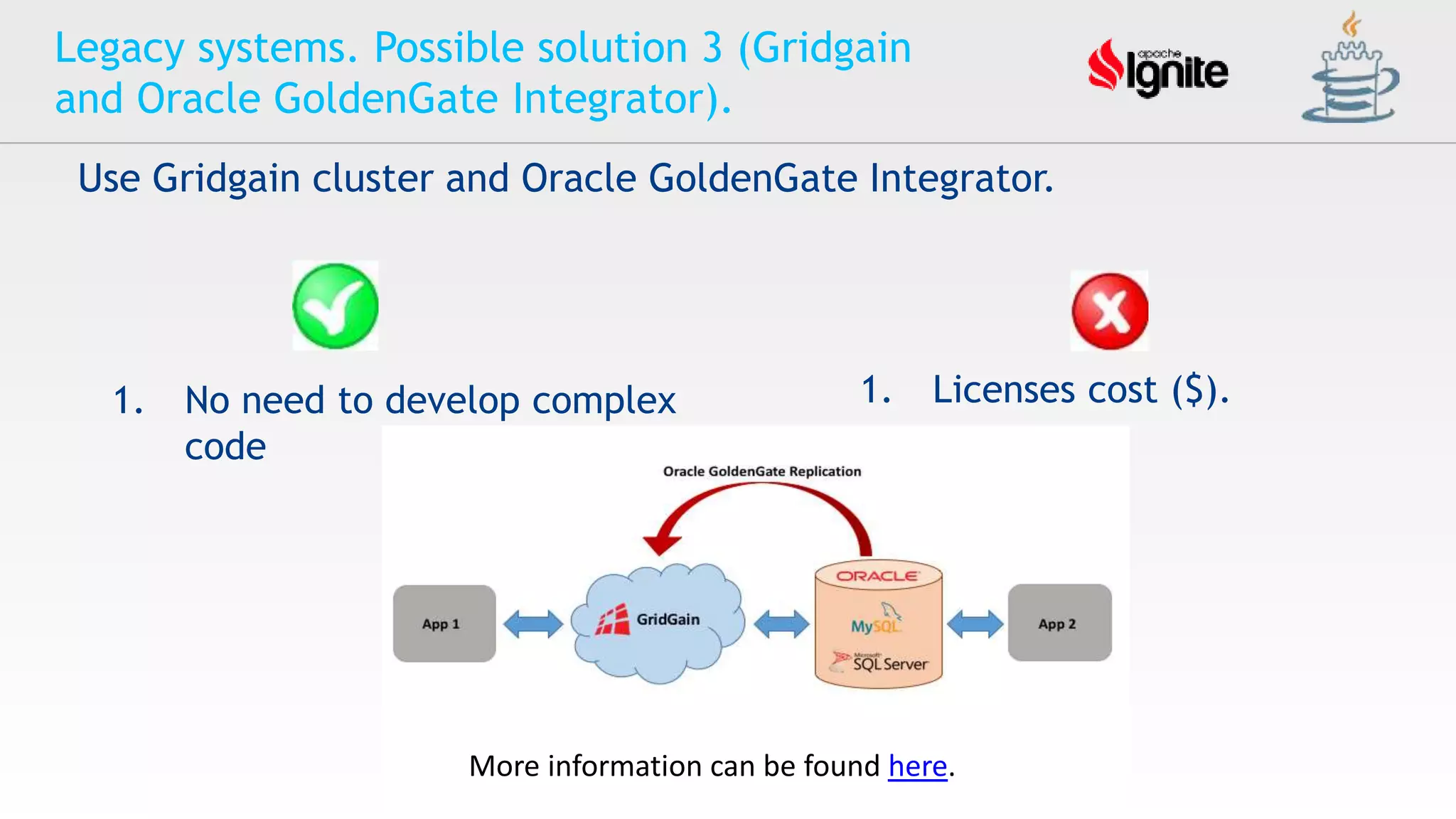



























![Oracle Cloud Infrastructure セキュリティの取り組み [2021年2月版]](https://cdn.slidesharecdn.com/ss_thumbnails/ocisecurityoverview202102-210219093947-thumbnail.jpg?width=640&height=640&fit=bounds)