Download as PDF, PPTX



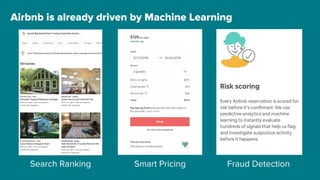




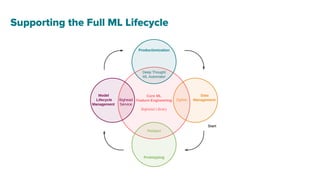







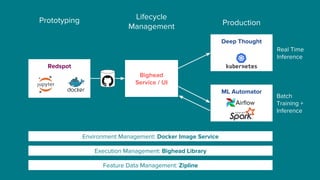
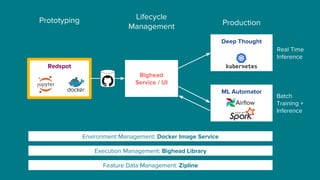



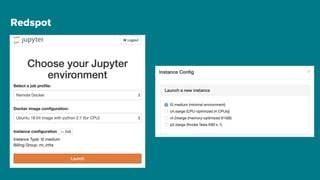

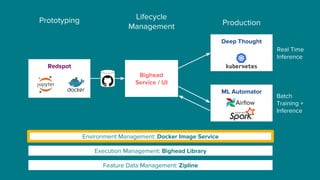


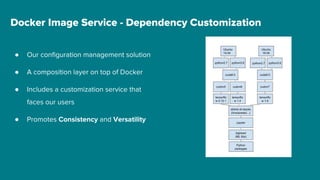
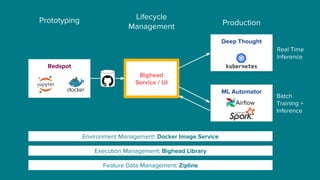


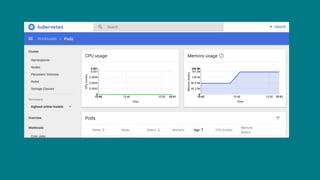
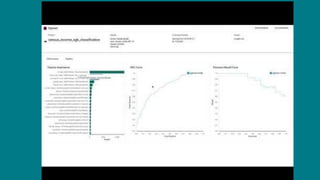

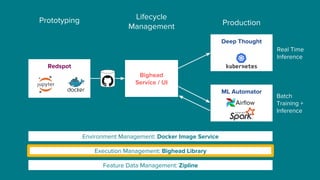





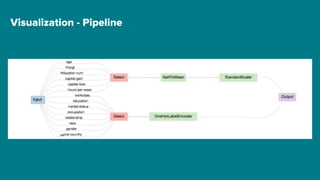



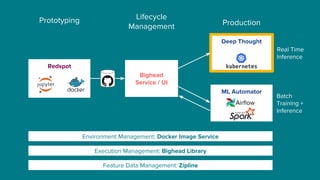



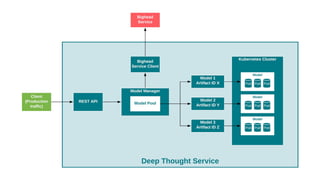
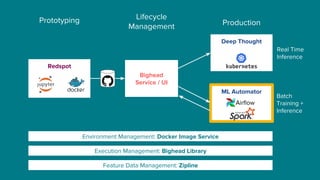



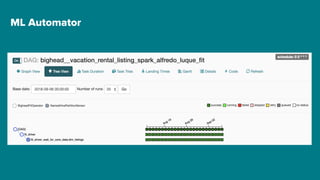
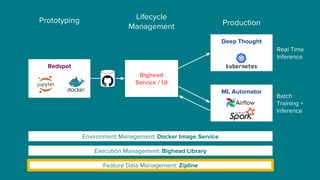



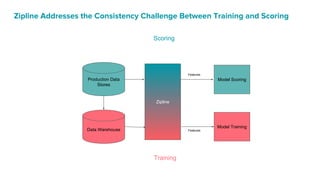




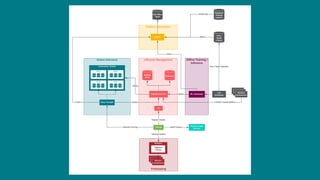

The document details Airbnb's machine learning infrastructure, designed to support various ML applications and streamline the development process. It outlines the architecture and key components like Bighead, Redspot, and Zipline, emphasizing scalability, consistency, and ease of use in deploying models. The infrastructure aims to enhance ML workflows by automating tasks, ensuring model lifecycle management, and integrating multiple data management frameworks.





































































![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)

















