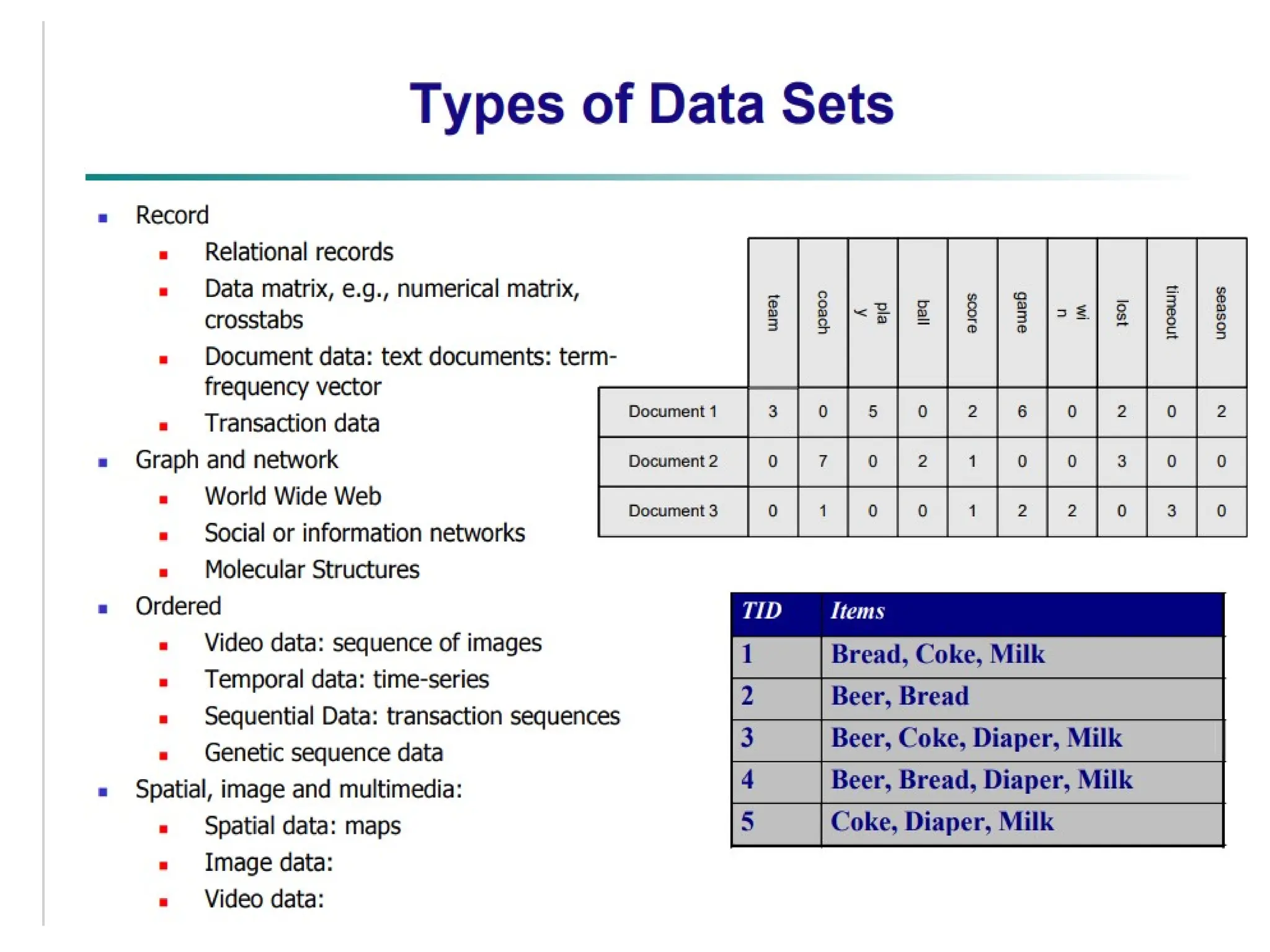
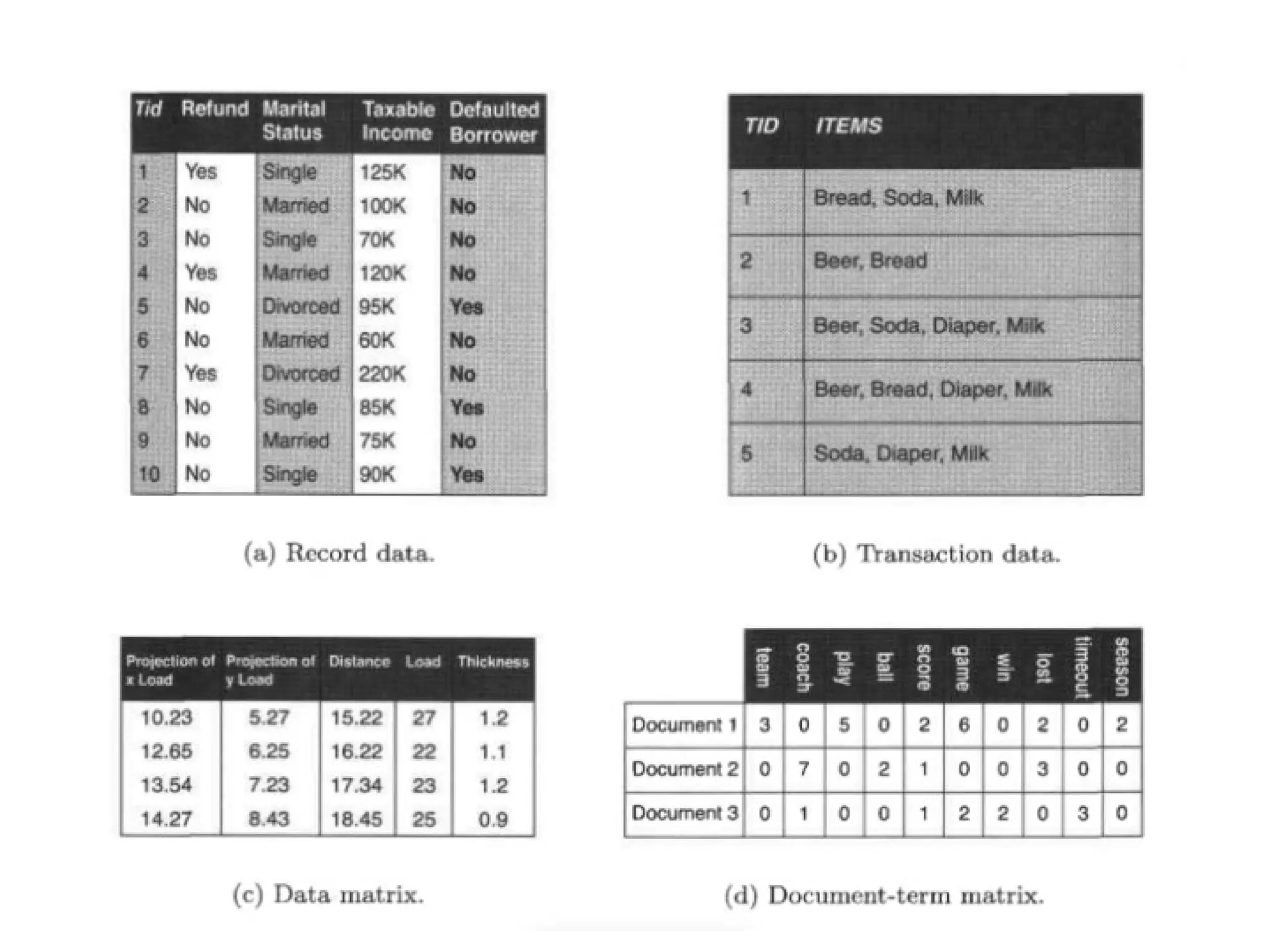
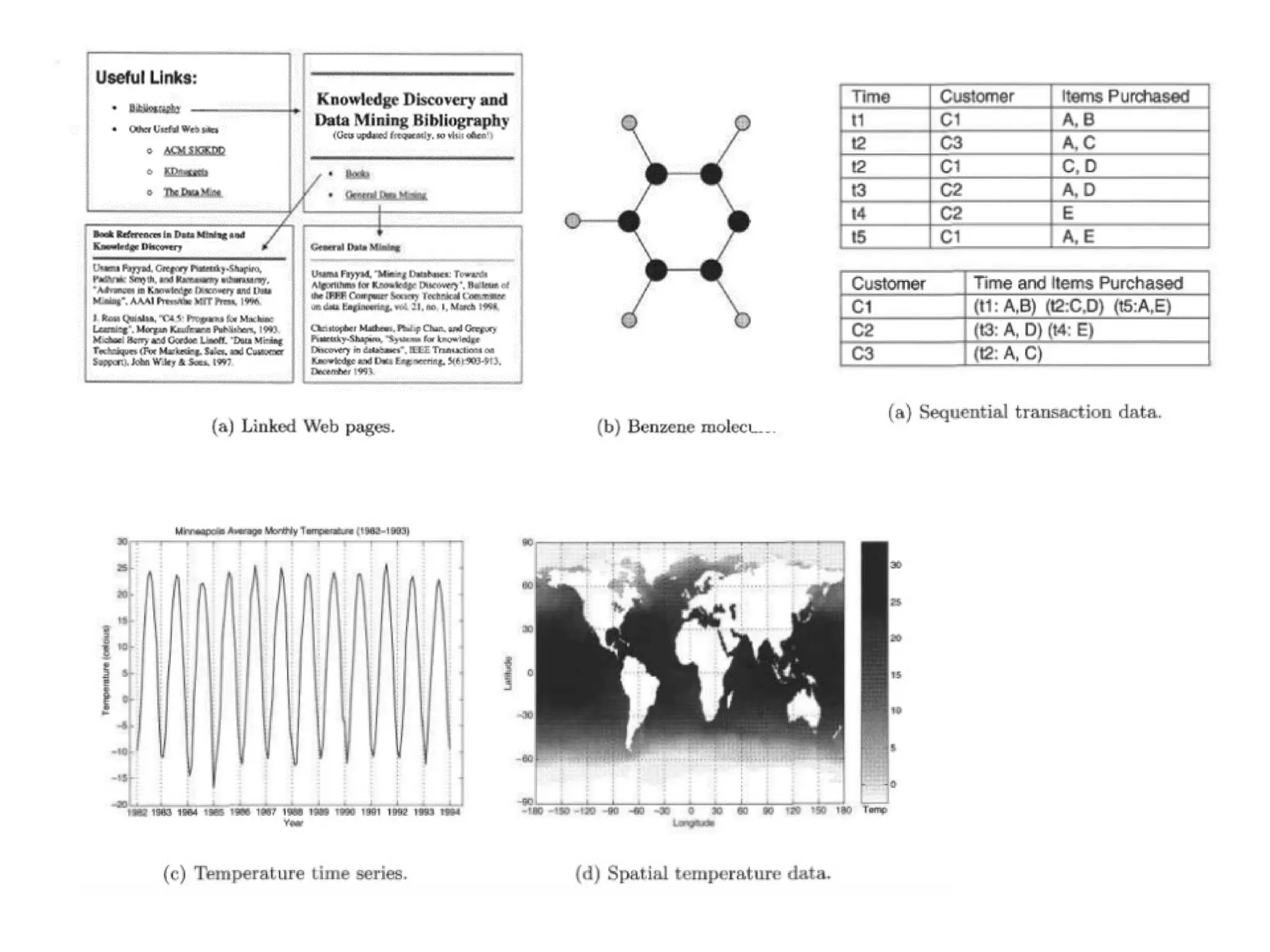
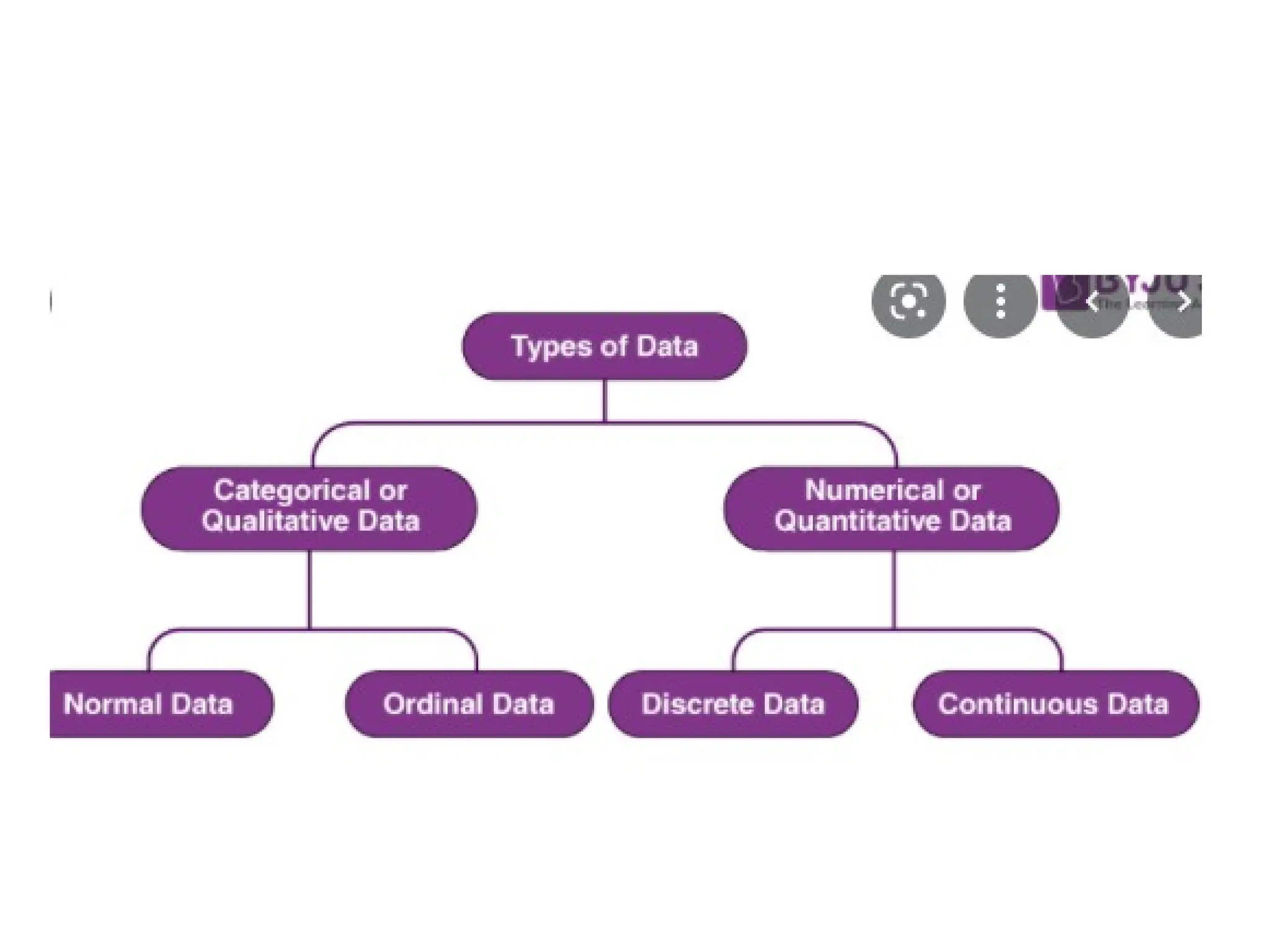
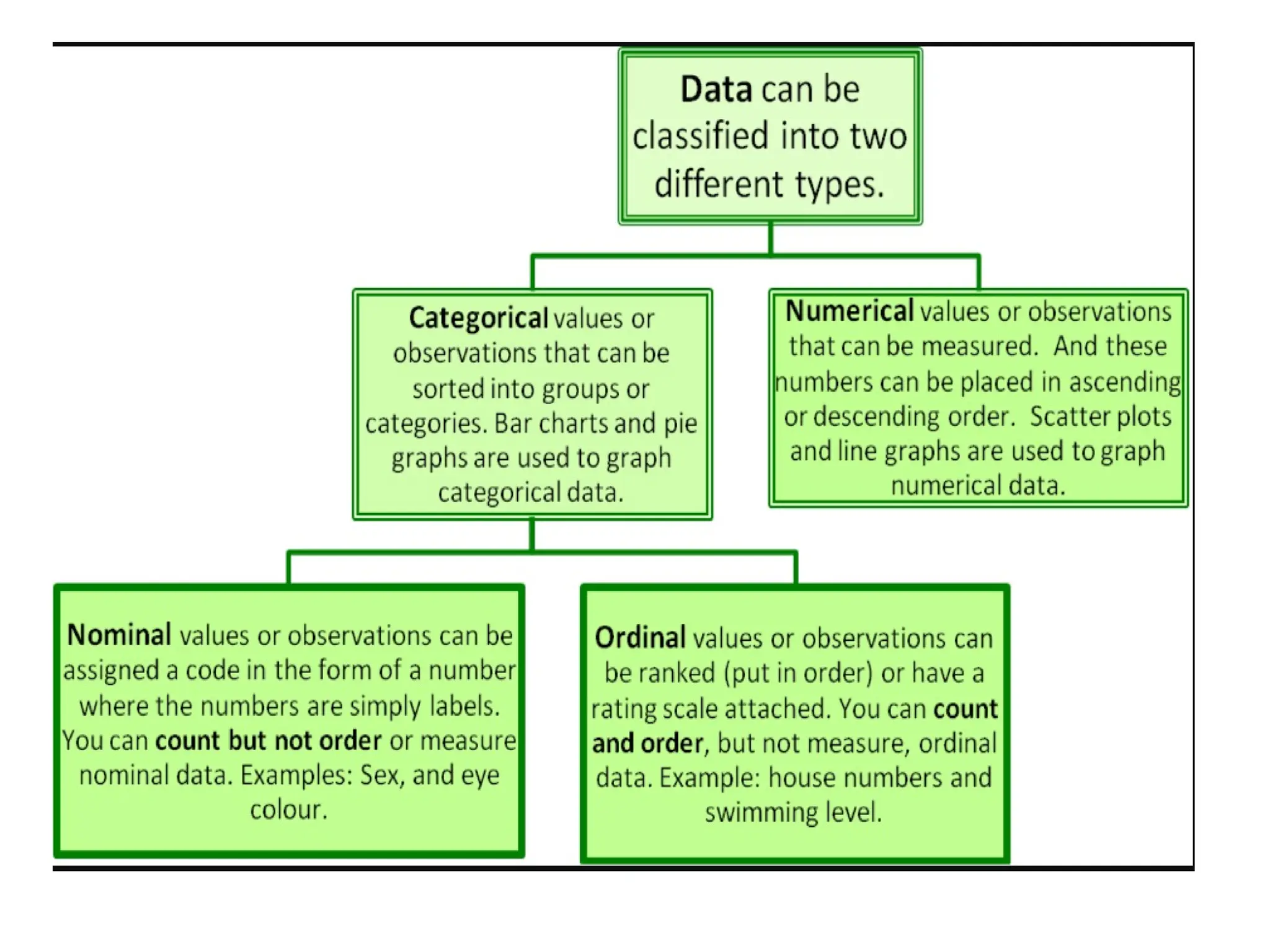
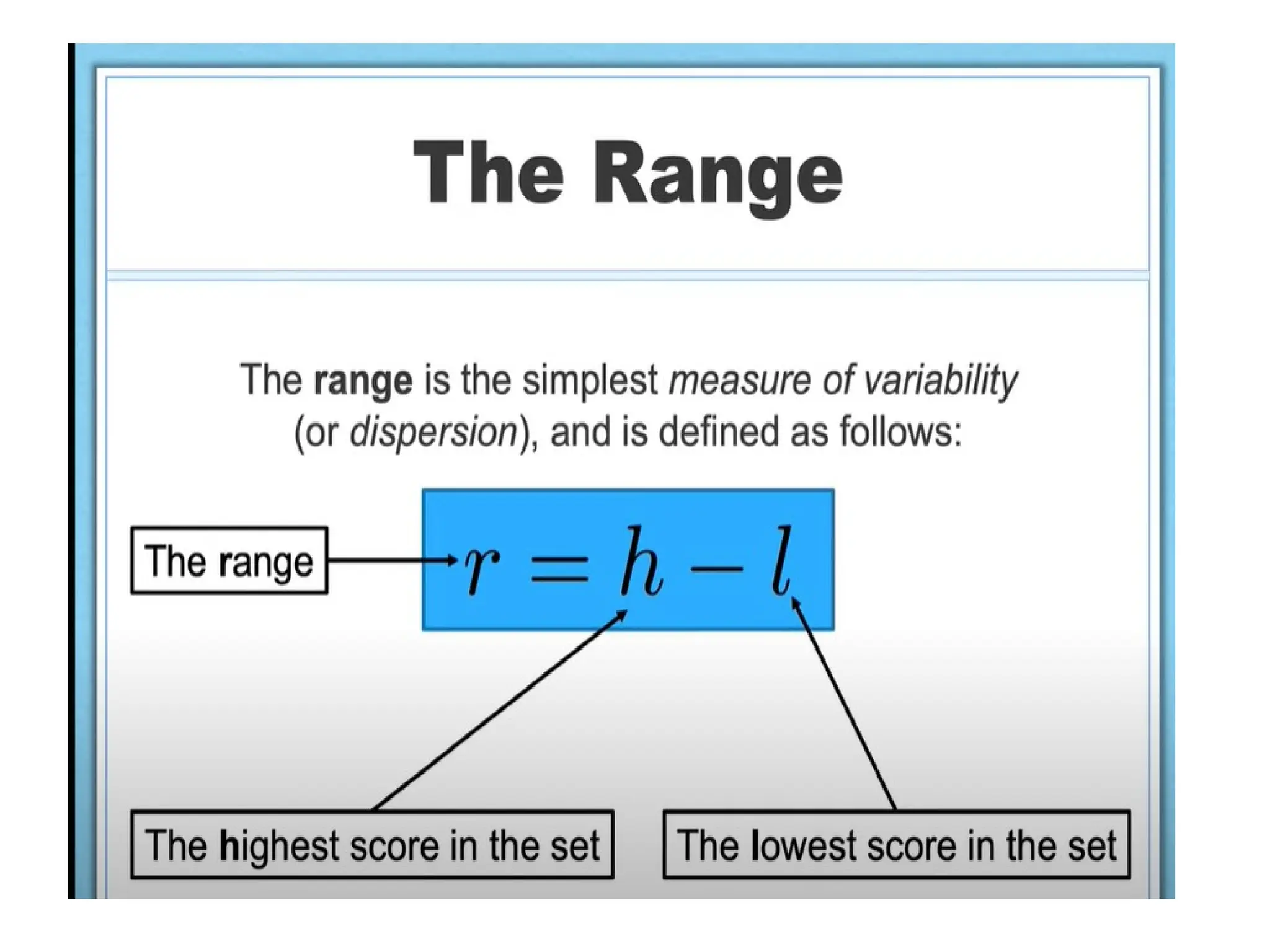
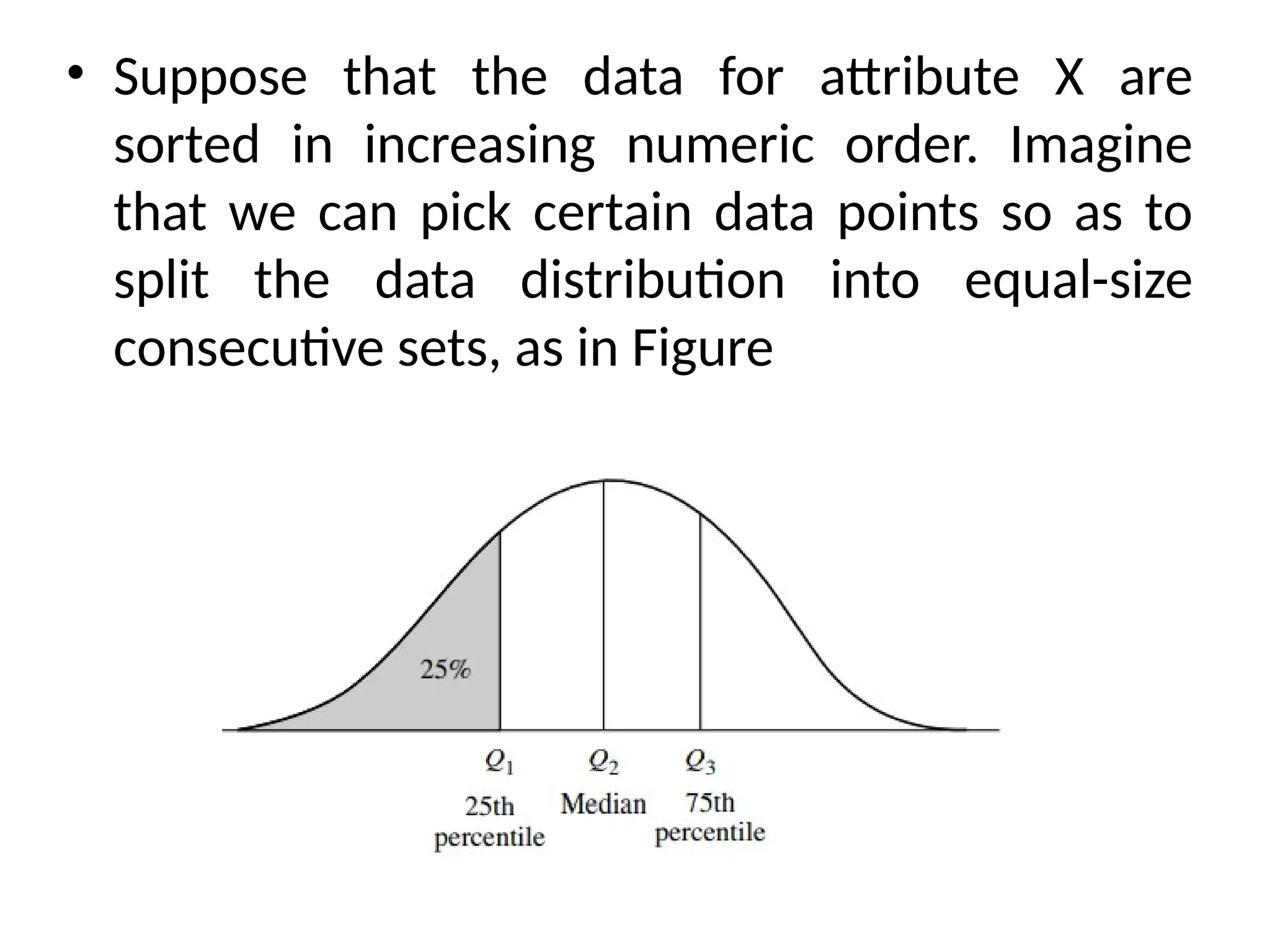
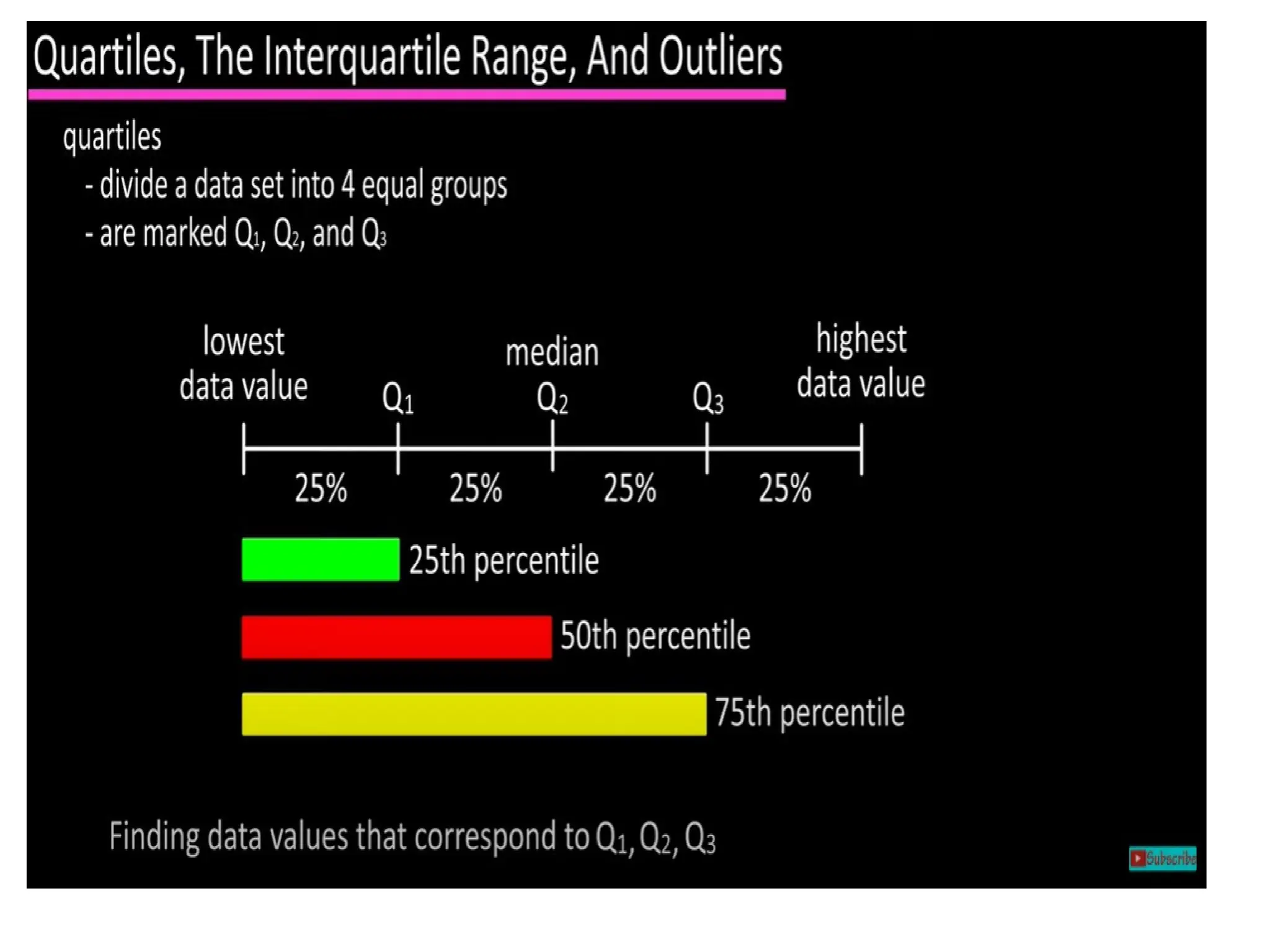
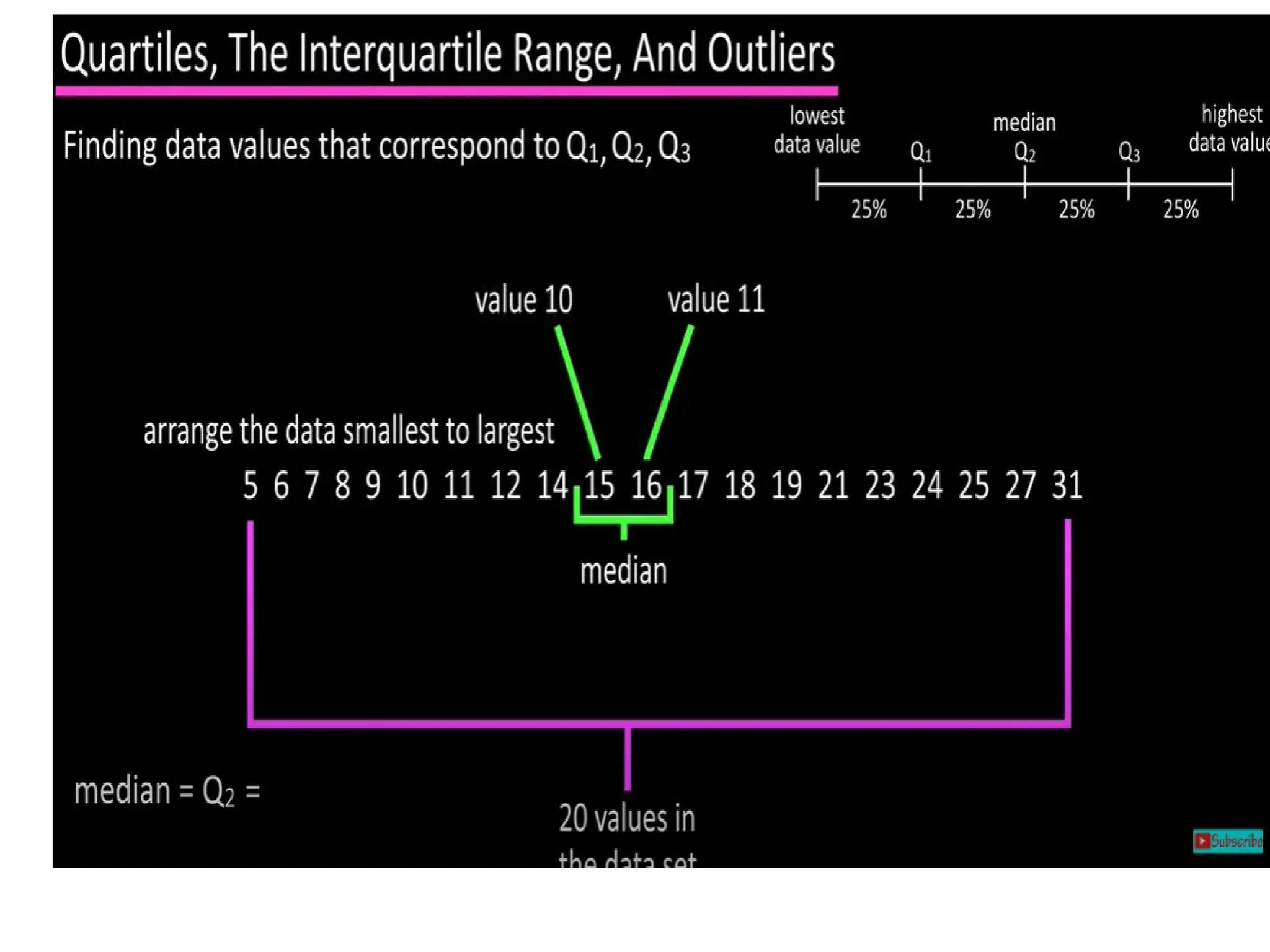
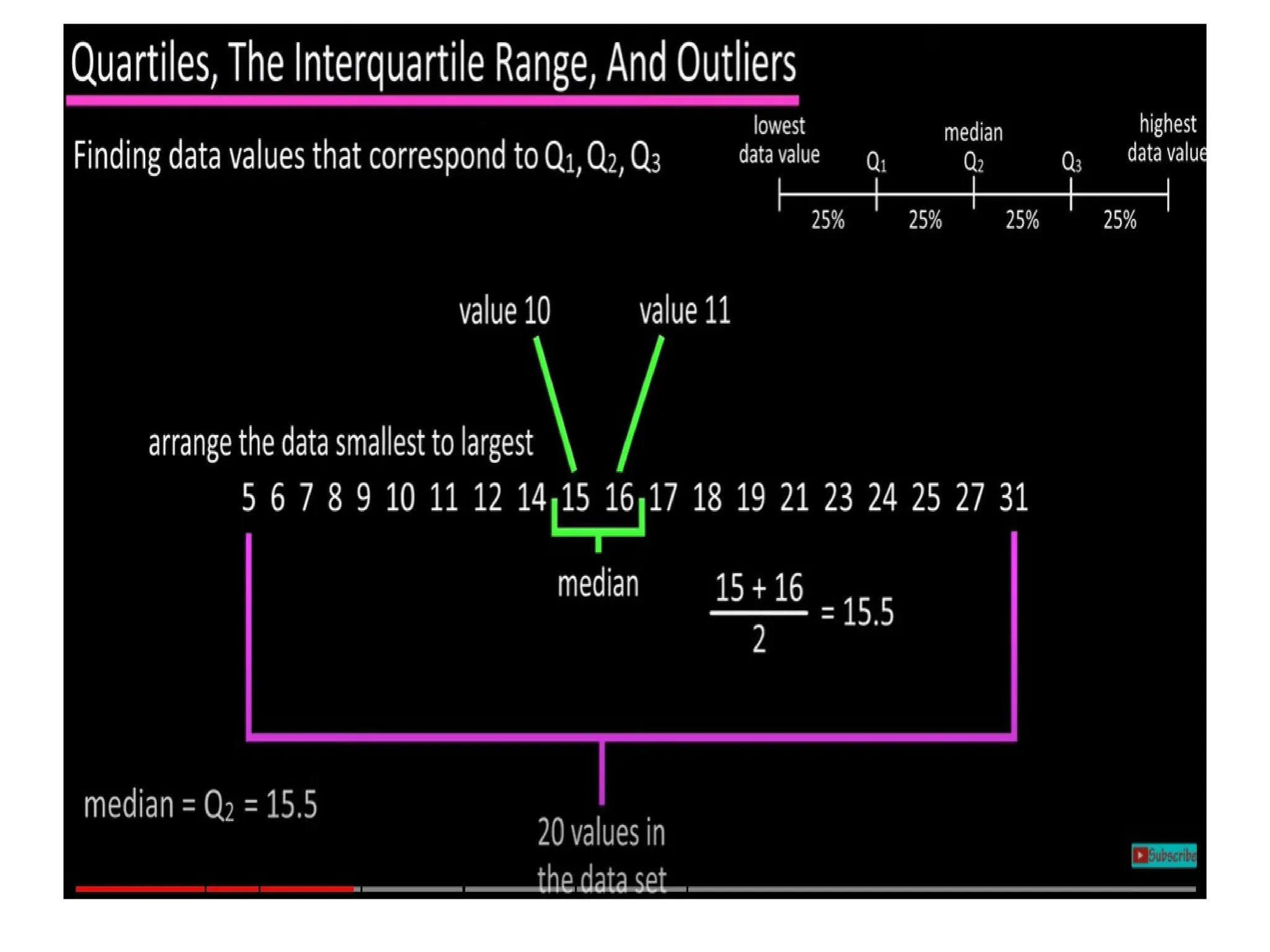
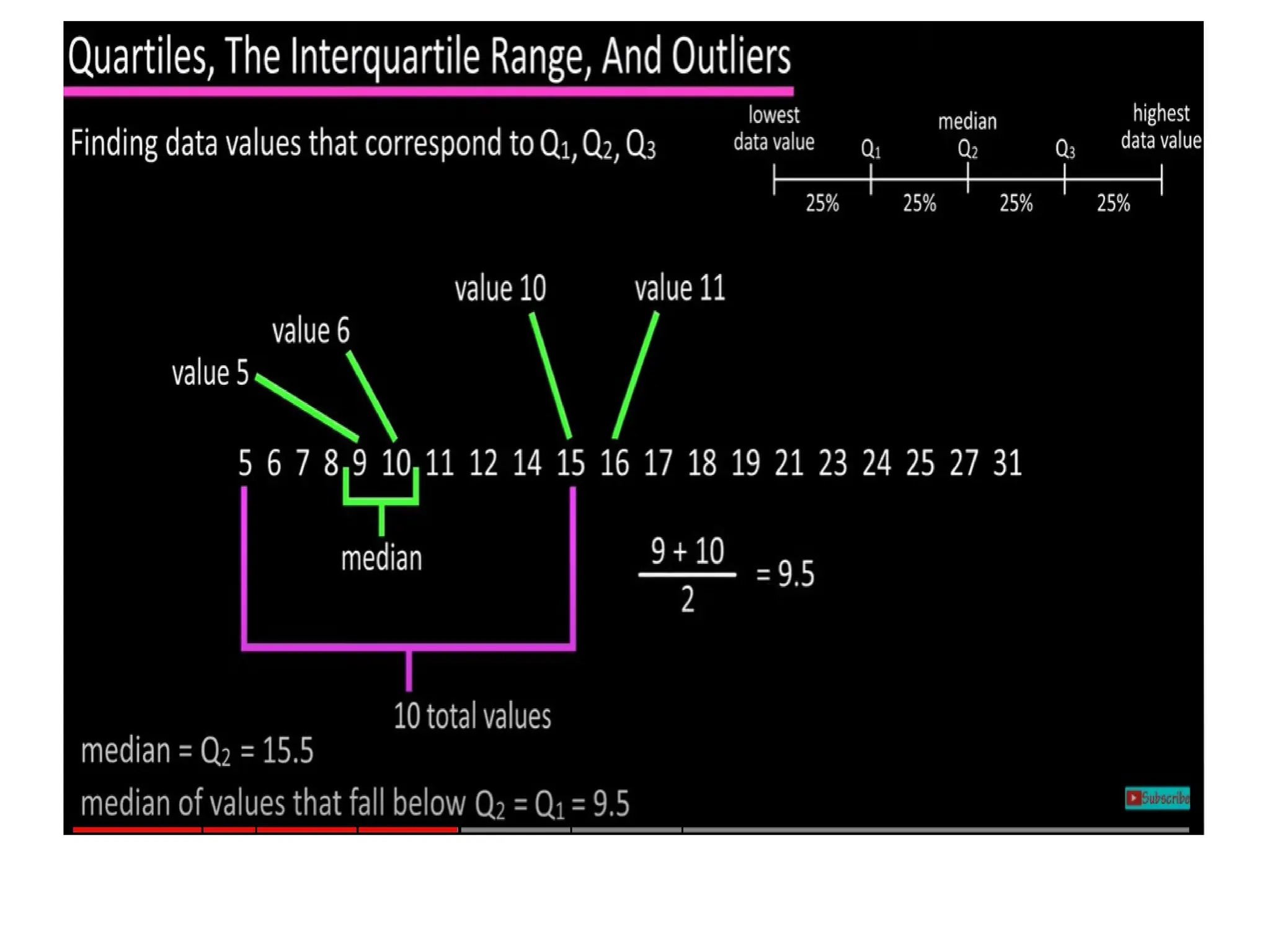
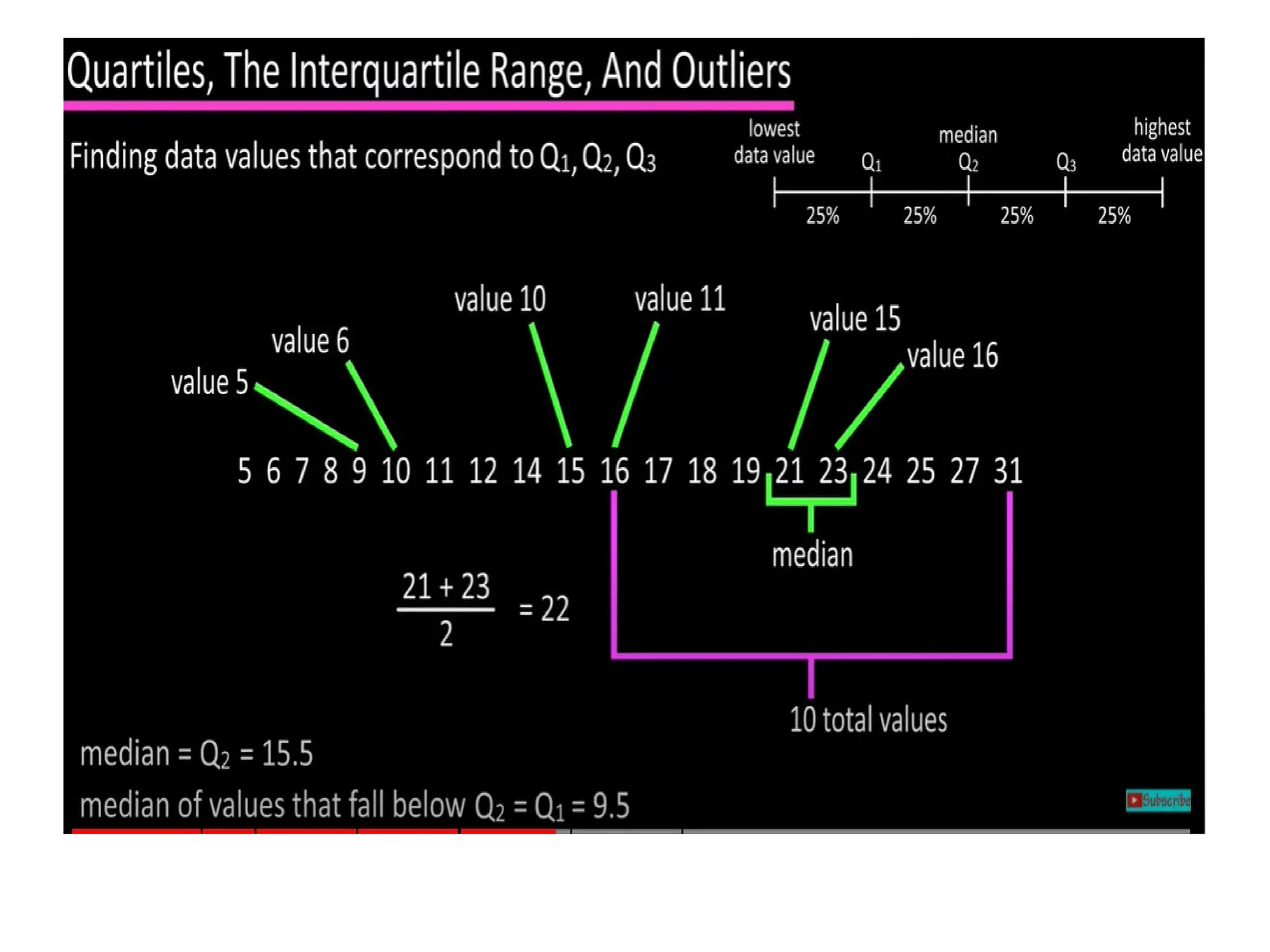
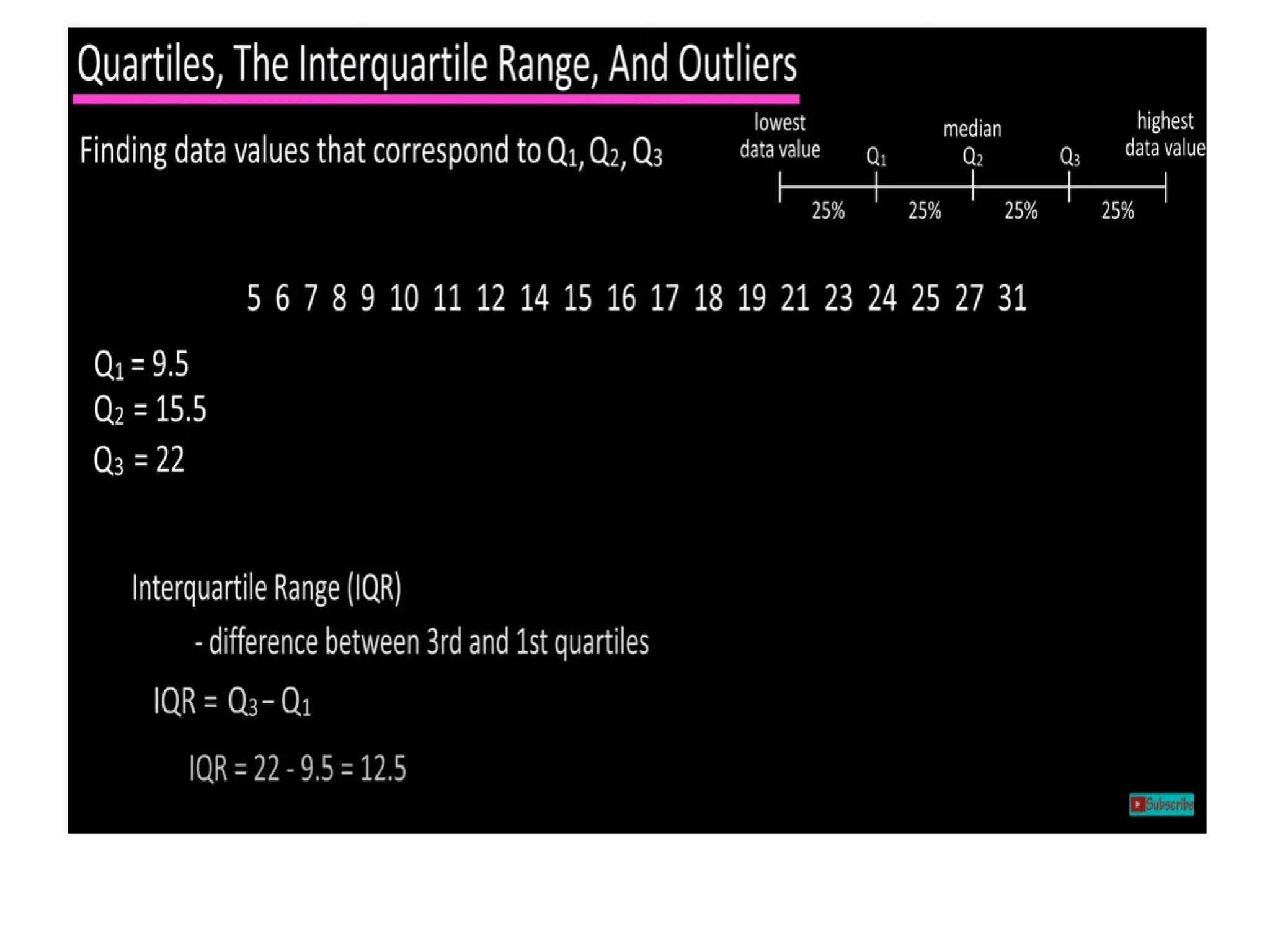
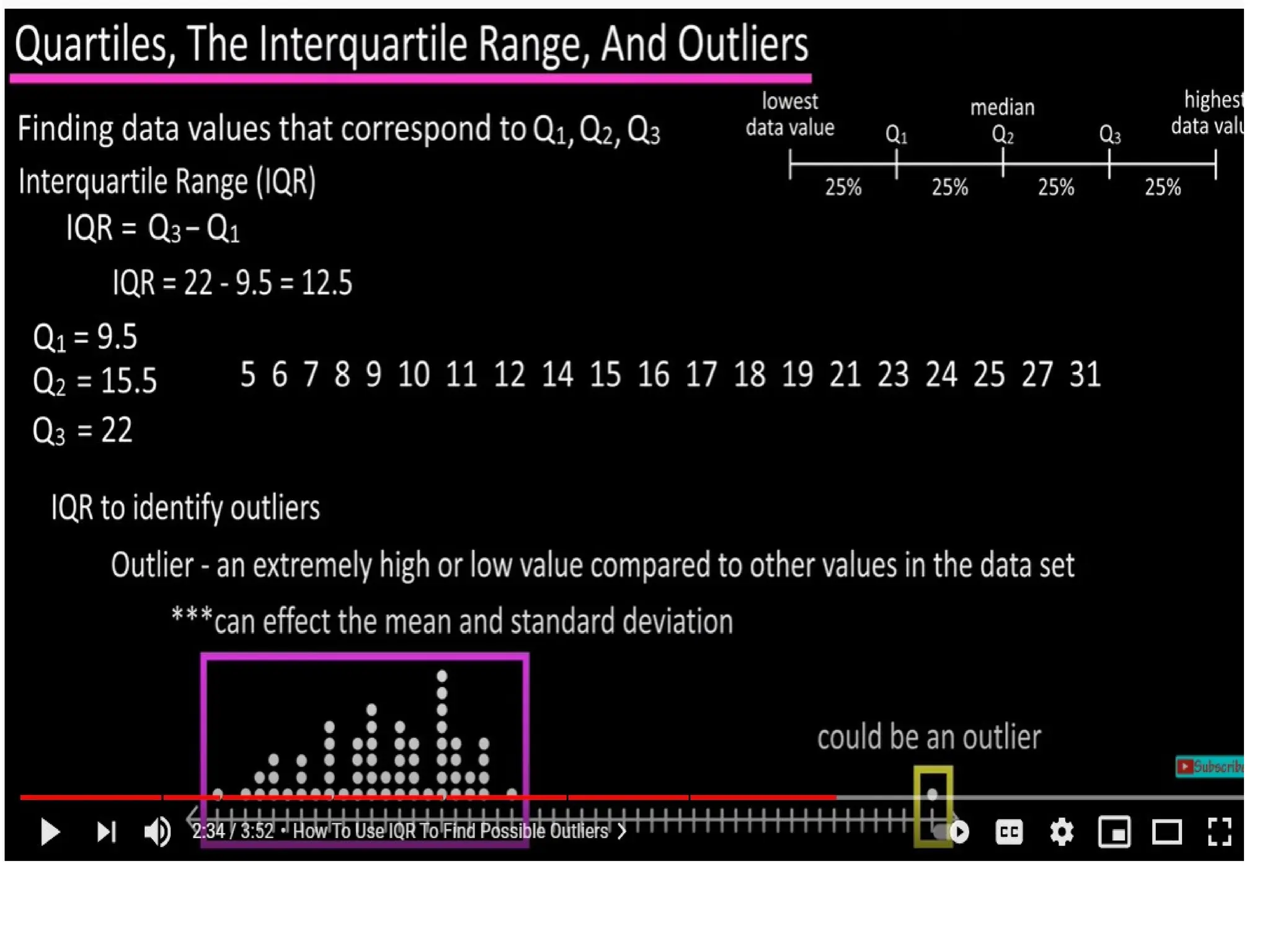
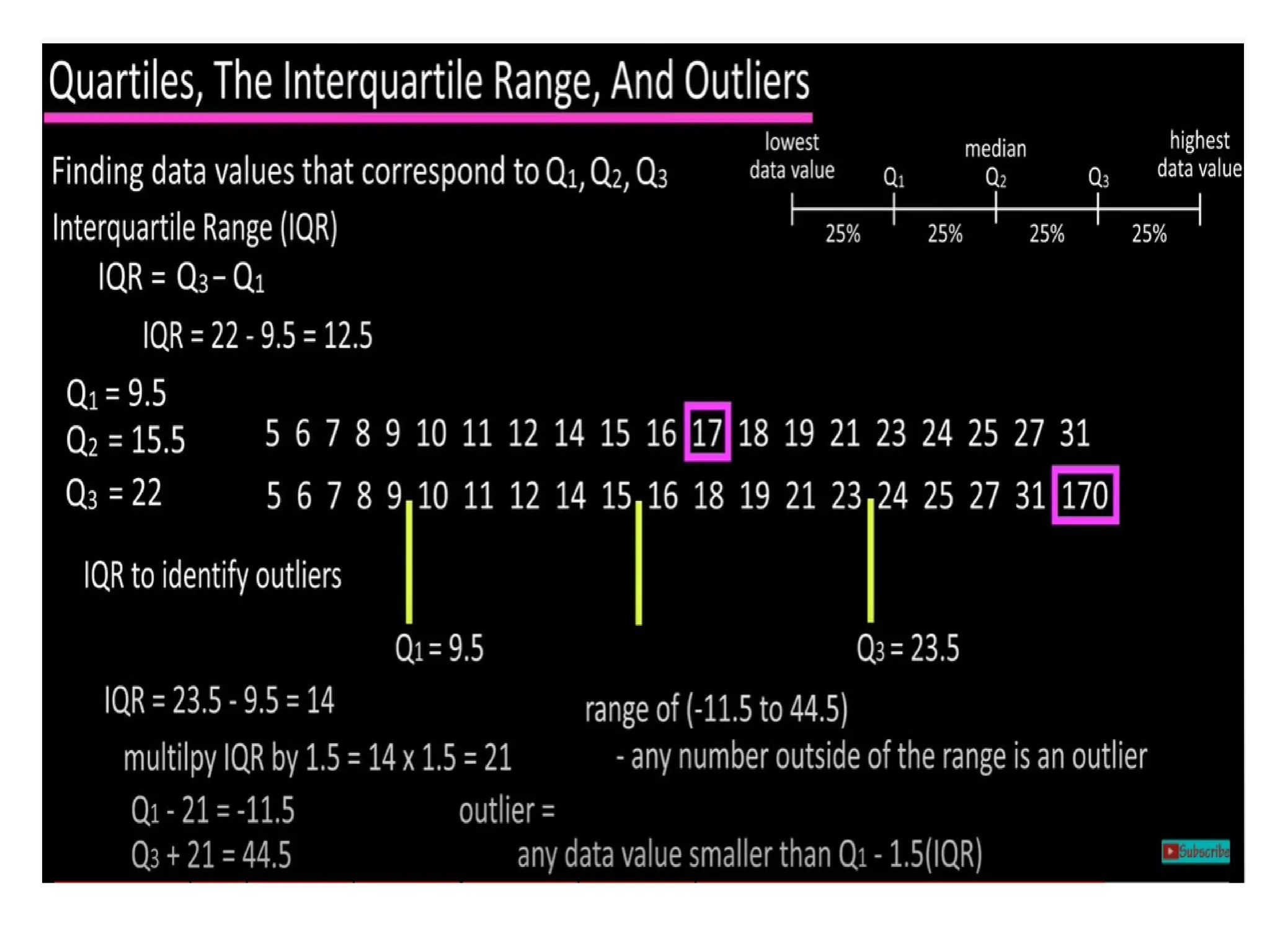
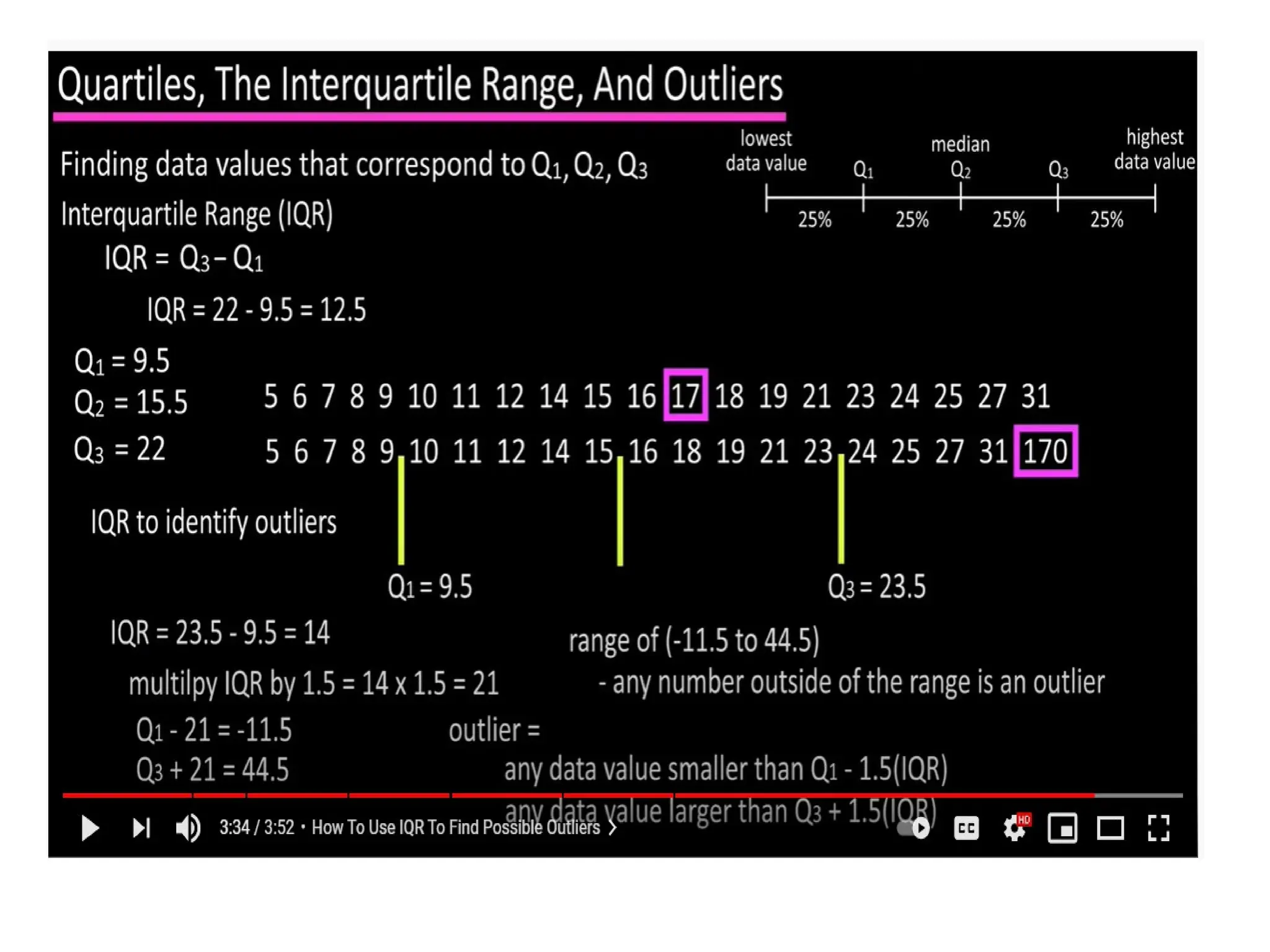
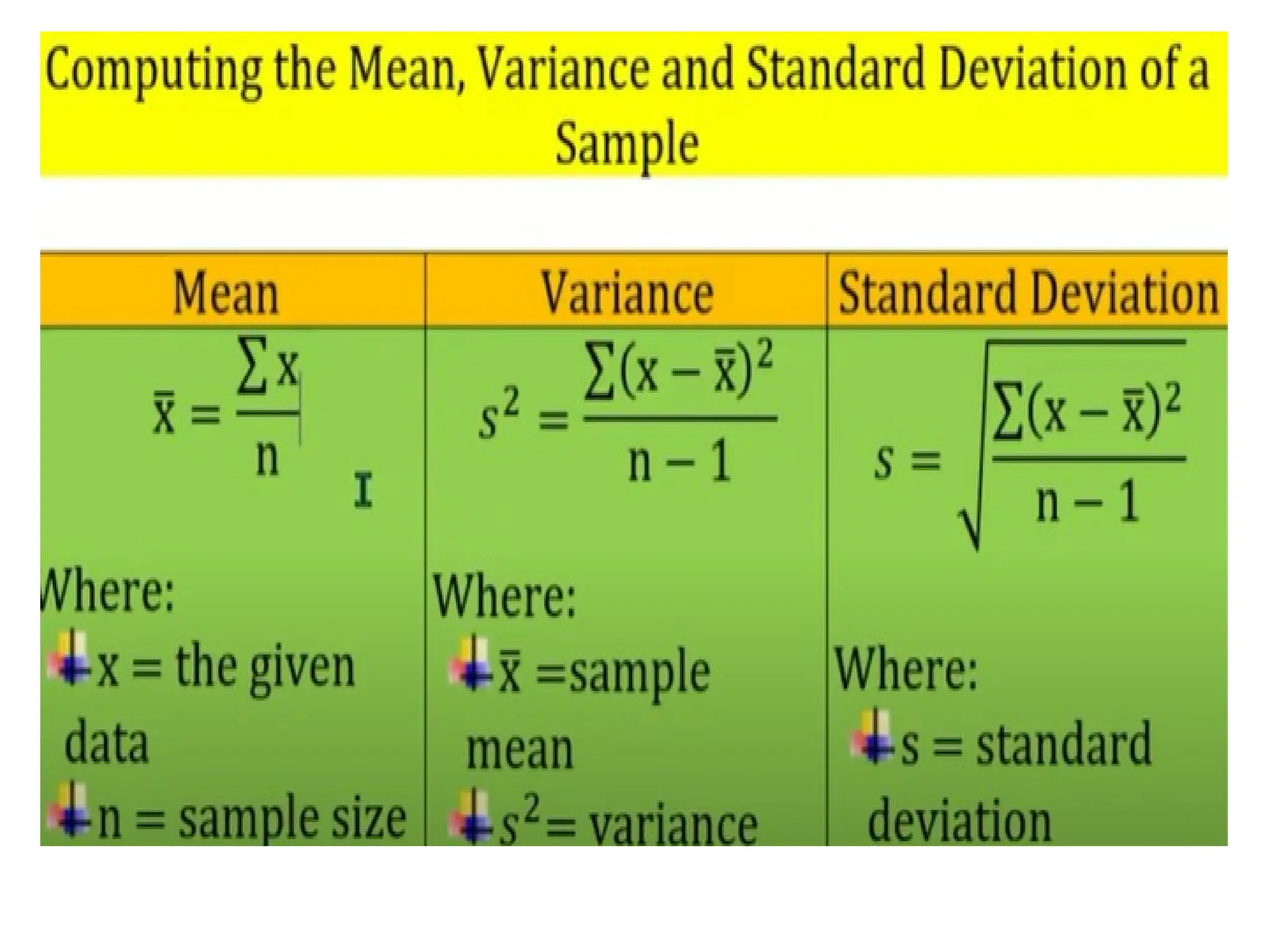
The document provides an overview of basic statistical concepts, including data collection, analysis, and interpretation, emphasizing the role of statistics in data mining and modeling. It explains various concepts such as datasets, data objects, attributes, measures of central tendency (mean, median, mode), and dispersion (variance and standard deviation). Additionally, it discusses skewness, quartiles, interquartile range, and their significance in understanding data distributions.






















![Skewness
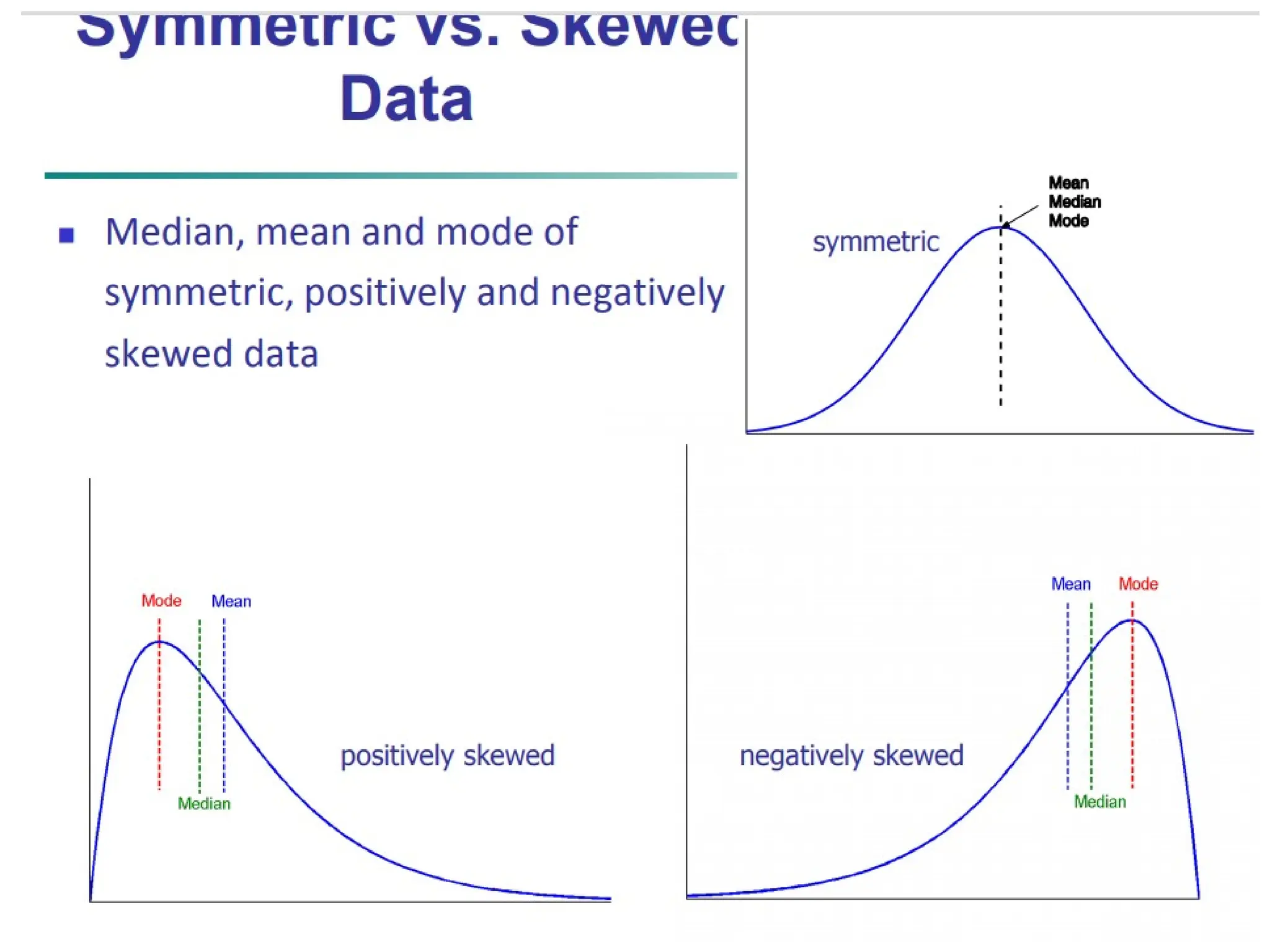
• Skewness is used to measure symmetry of data
along with the mean value. Symmetry means equal
distribution of observation above or below the mean.
• skewness = 0: if data is symmetric along with mean
• skewness = Negative: if data is not symmetric and
right side tail is longer than left side tail of density
plot.
• skewness = Positive: if data is not symmetric and
left side tail is longer than right side tail in density
plot.
• We can find skewness of given variable by below
given formula.
• data[‘A’].skew()](https://image.slidesharecdn.com/basicstatisticaldescriptionsofdata-241111121434-0b714641/75/Basic-Statistical-descriptions-of-Data-pptx-29-2048.jpg)




































































![[DSC Europe 25] Dusan Jovicic - AI Story: From on-prem to cloud and back agai...](https://cdn.slidesharecdn.com/ss_thumbnails/8kp49m6uq22ifnbwhfnk-2-251205085715-964d11a6-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Bogdan Daniel Maruneac - AI - It starts with you.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/odov3snhrcqs9hx5ny2n-4-251205085715-f1daacfe-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)
