Download as ODP, PPTX









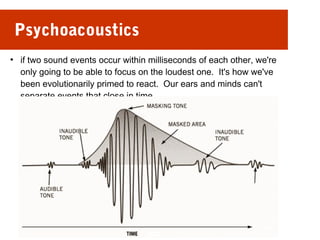
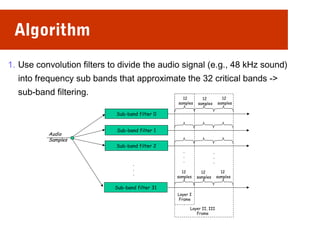








This document discusses audio compression techniques. It begins by defining audio and compression. There are two main types of audio compression: lossy and lossless. Lossy compression reduces file sizes but results in some quality loss, while lossless compression decompresses the file back to its original quality. Common lossy audio compression methods are discussed, including those based on psychoacoustics involving how humans perceive sound. MPEG layers are then introduced as a standard for audio compression, with Layer I being highest quality but also highest bitrate, and Layer III providing greater compression but still high quality at lower bitrates like 64kbps. Effectiveness is shown to increase with each newer layer.



































































