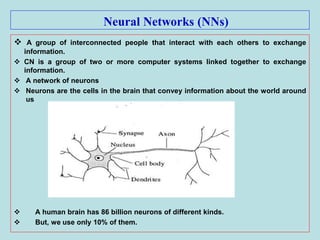
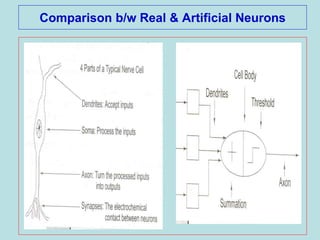
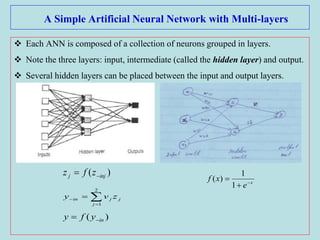
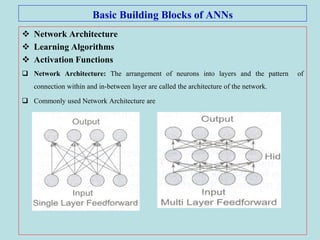
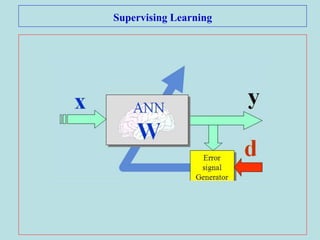
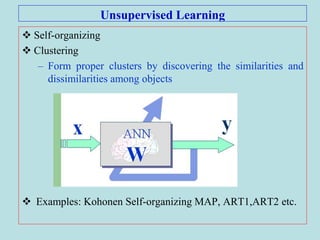
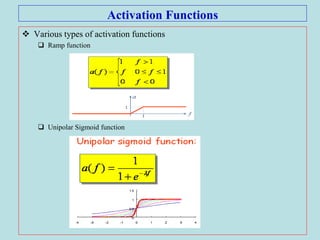
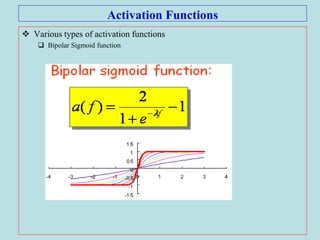
The document discusses soft computing and artificial neural networks. It provides an overview of soft computing techniques including artificial neural networks (ANNs), fuzzy logic, and evolutionary computing. It then focuses on ANNs, describing their biological inspiration from neurons in the brain. The basic components of ANNs are discussed including network architecture, learning algorithms, and activation functions. Specific ANN models are then summarized, such as the perceptron, ADALINE, and their learning rules. Applications of ANNs are also briefly mentioned.
















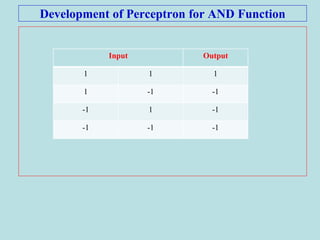
![Perceptron Training Algorithm for AND function
x=[1 1 -1 -1;1 -1 1 -1];
t=[1 -1 -1 -1];
w=[0 0];
b=0;
alpha=input('Enter Learning Rate=');
theta=input('Enter Threshold Value=');
epoch=0;
maxepoch=100;](https://image.slidesharecdn.com/ann-1-200421023735/85/Artificial-Neural-Networks-Supervised-Learning-Models-26-320.jpg)

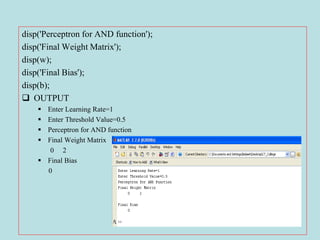
![Perceptron Testing Algorithm for AND function
x=[1 1 -1 -1;1 -1 1 -1];
w=[0 2];
b=0;
for i=1:4
yin=b*x(1,i)*w(1)+x(2,i)*w(2);
if yin>theta
y(i)=1;
end
if yin<=theta & yin>=-theta
y(i)=0;
end
if yin<-theta
y(i)=-1;
end
end
y
OUTPUT: 1 -1 1 -1
Input Target Actual
Output
1 1 1 1
1 -1 -1 -1
-1 1 -1 1
-1 -1 -1 -1](https://image.slidesharecdn.com/ann-1-200421023735/85/Artificial-Neural-Networks-Supervised-Learning-Models-29-320.jpg)









































































