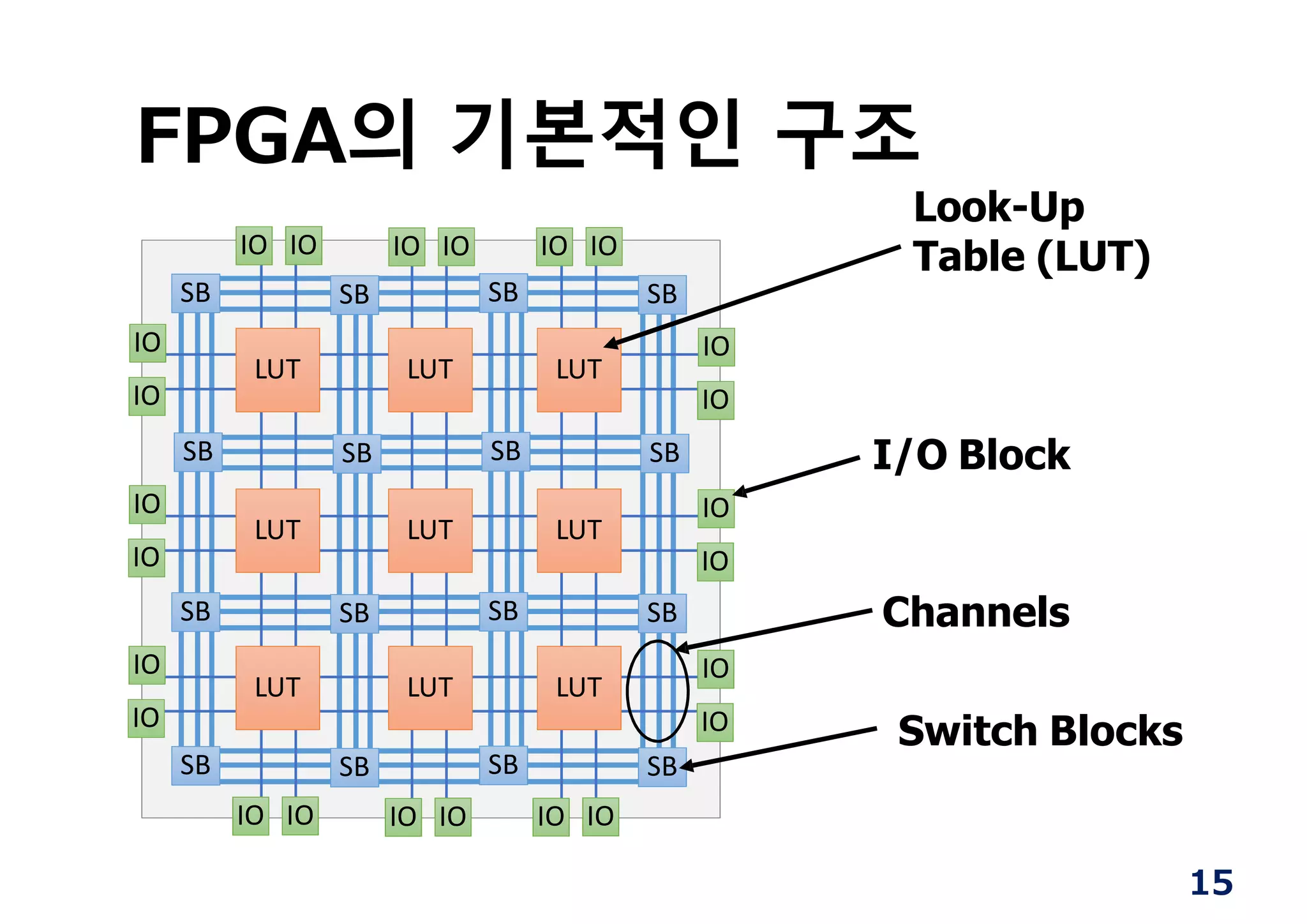
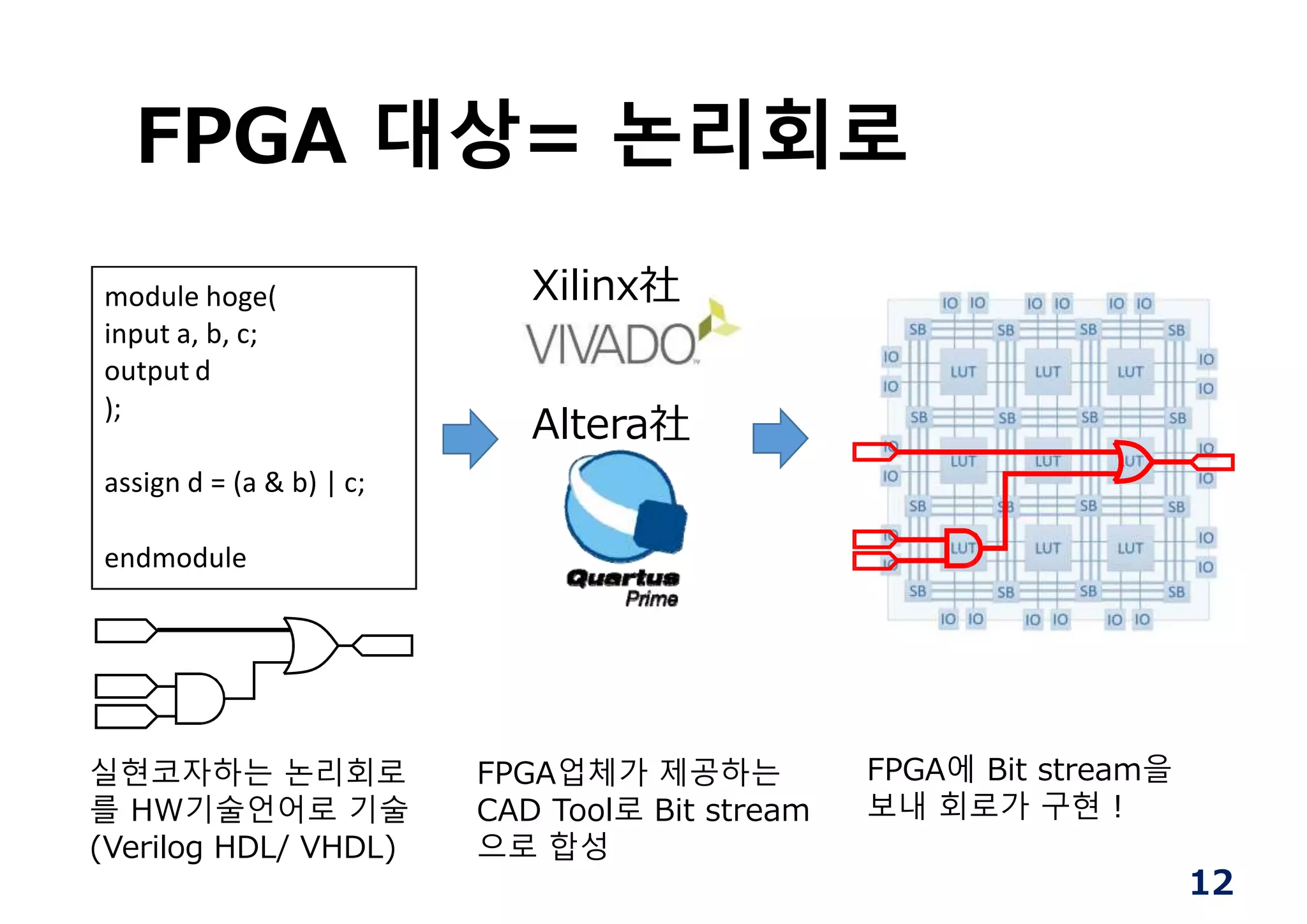
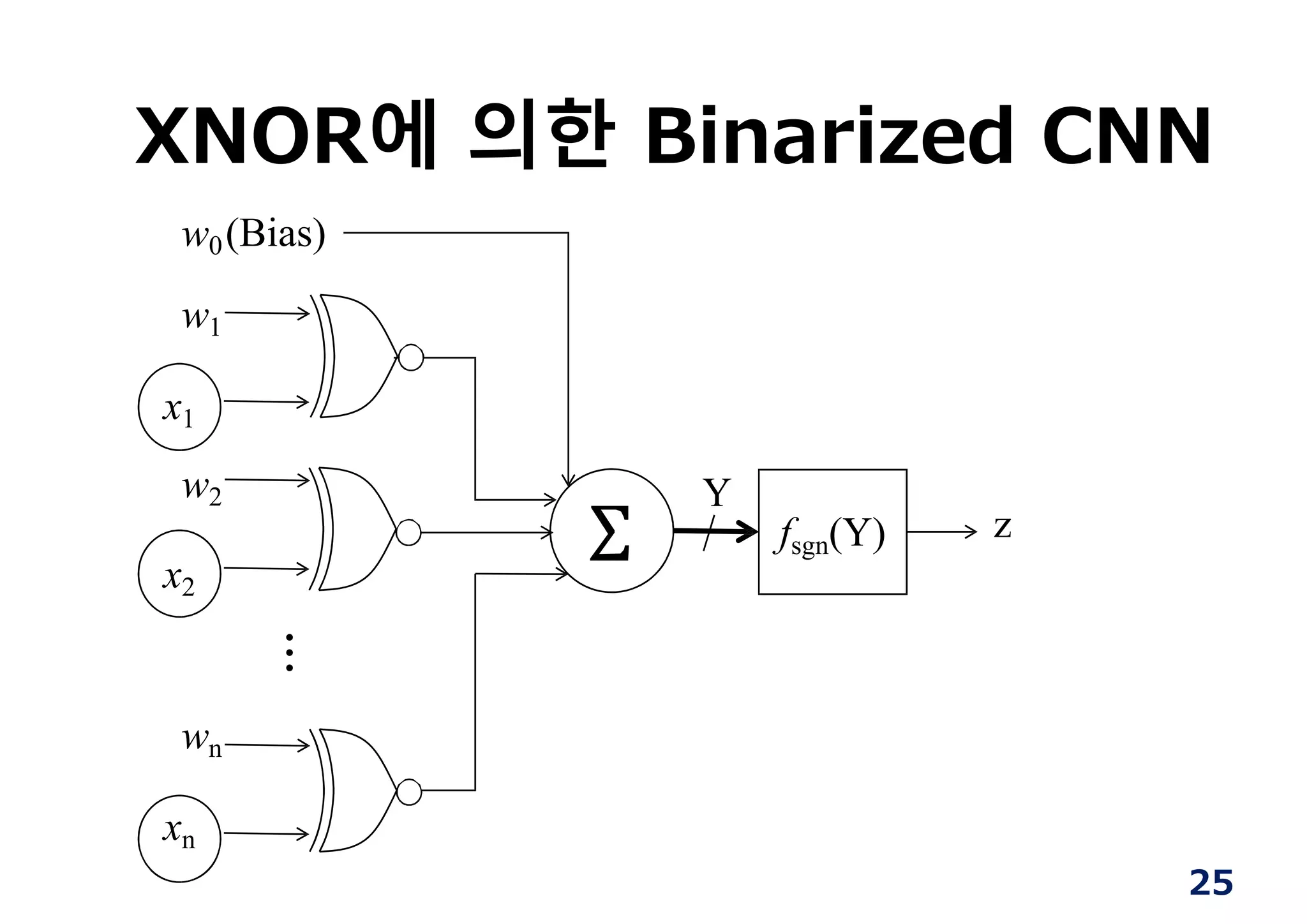
FPGA 대상= 논리회로
modulehoge(
input a, b, c;
output d
);
assign d = (a & b) | c;
endmodule
Xilinx社
Altera社
실현코자하는 논리회로
를 HW기술언어로 기술
(Verilog HDL/ VHDL)
12
FPGA업체가 제공하는
CAD Tool로 Bit stream
으로 합성
FPGA에 Bit stream을
보내 회로가 구현 !
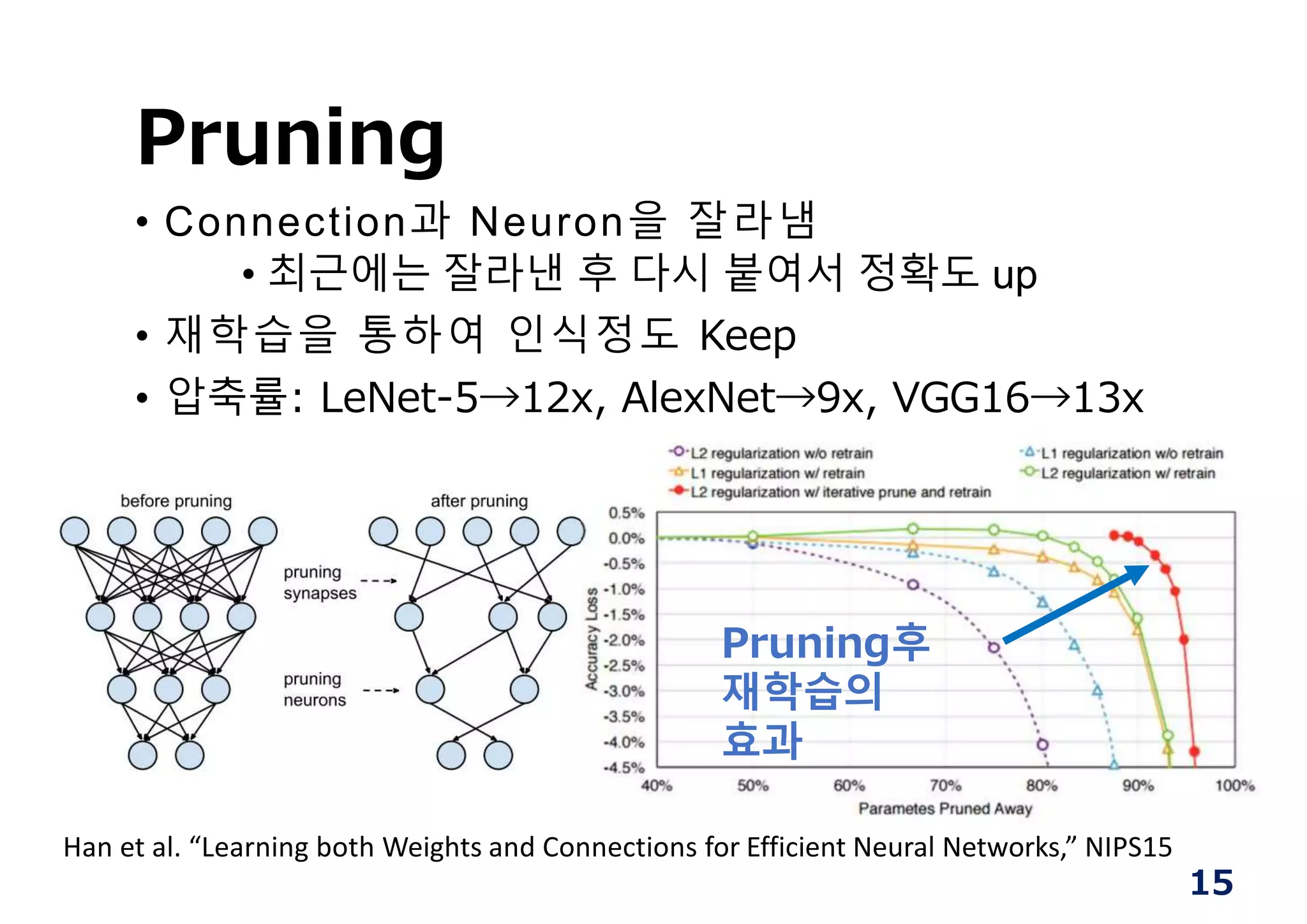
Pruning
• Connection과 Neuron을잘라냄
• 최근에는 잘라낸 후 다시 붙여서 정확도 up
• 재학습을 통하여 인식정도 Keep
• 압축률: LeNet-5→12x, AlexNet→9x, VGG16→13x
Pruning후
재학습의
효과
Han et al. “Learning both Weights and Connections for Efficient Neural Networks,” NIPS15
15
16.
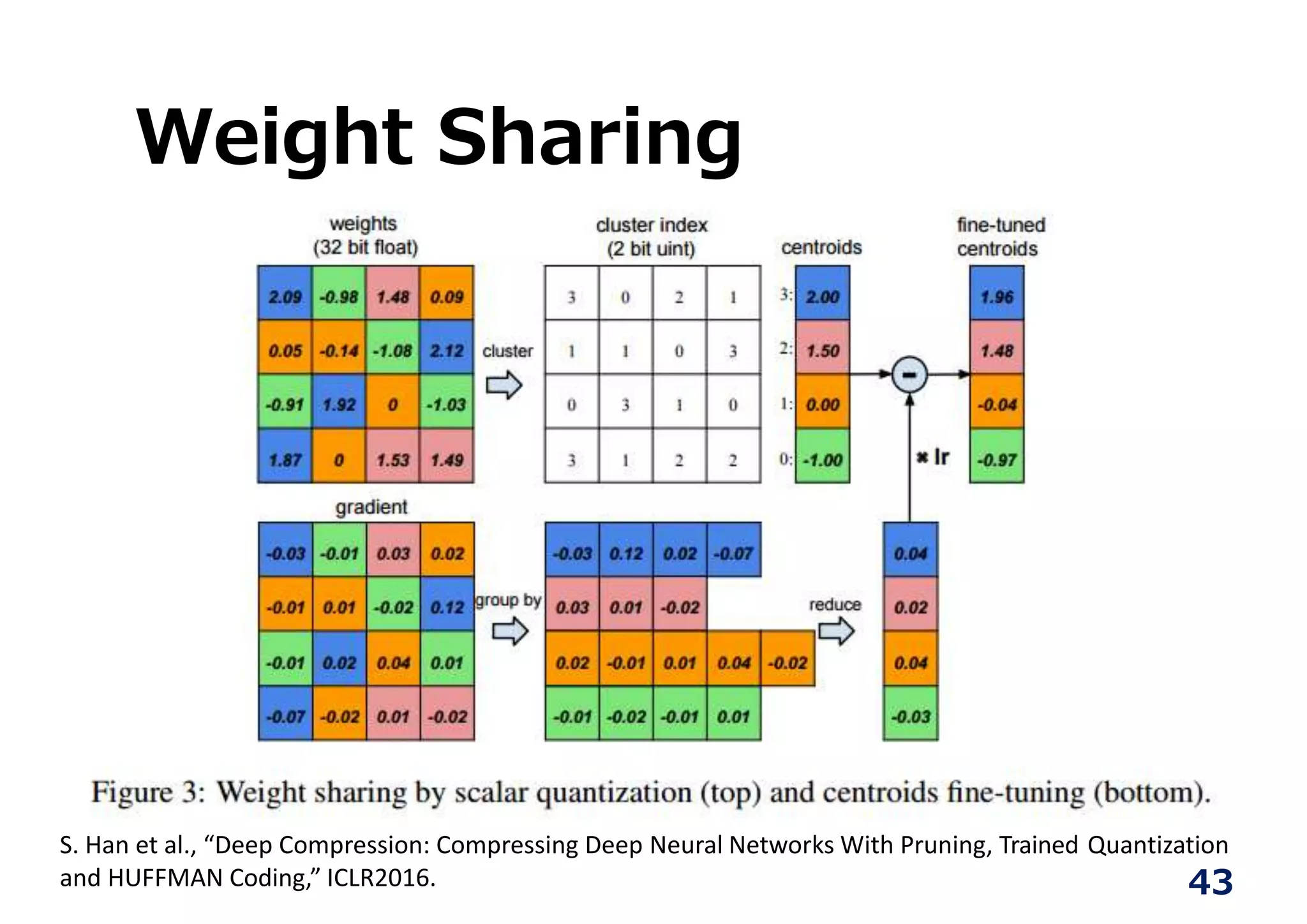
Weight Sharing
43
S. Hanet al., “Deep Compression: Compressing Deep Neural Networks With Pruning, Trained Quantization
and HUFFMAN Coding,” ICLR2016.
17.
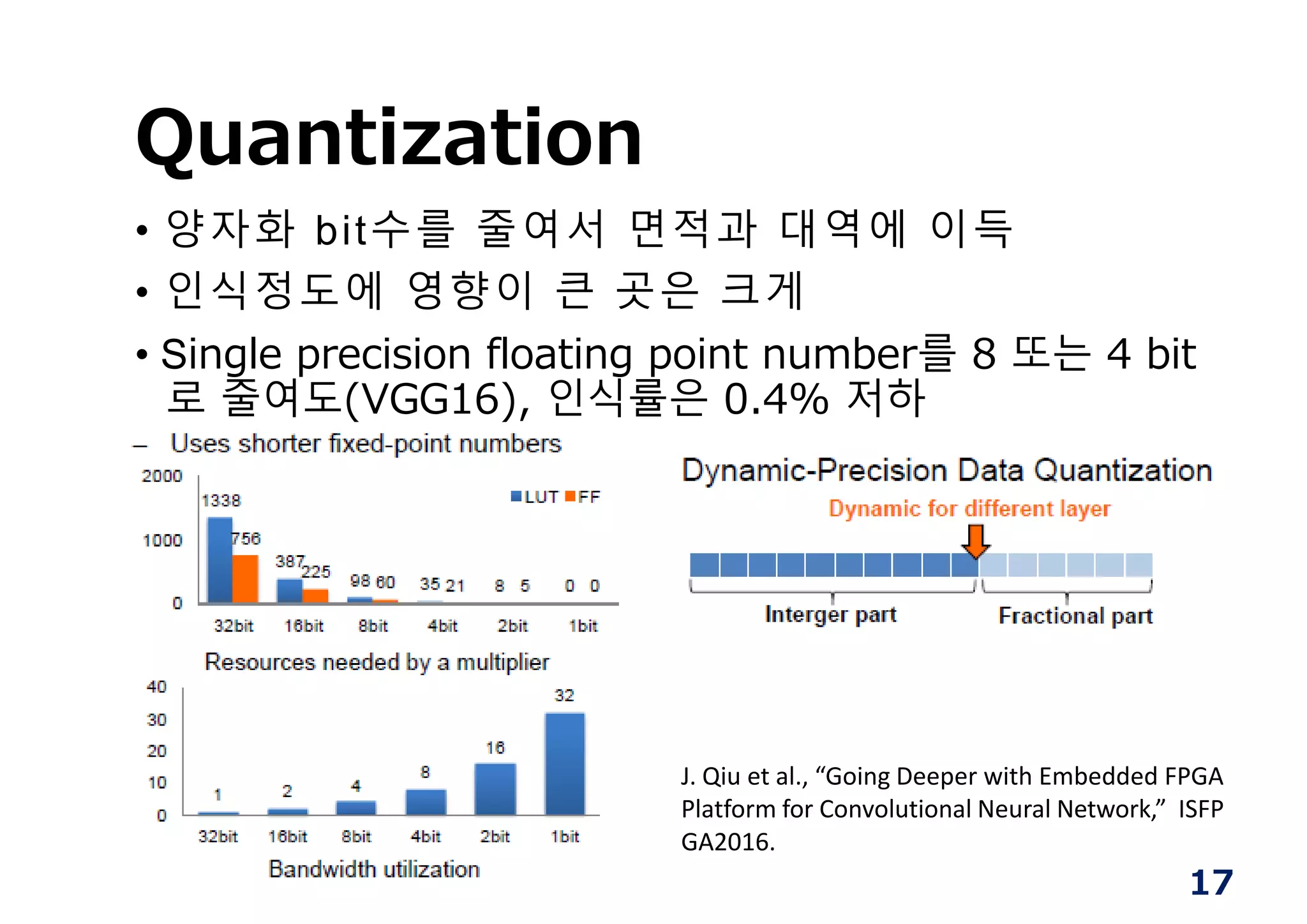
Quantization
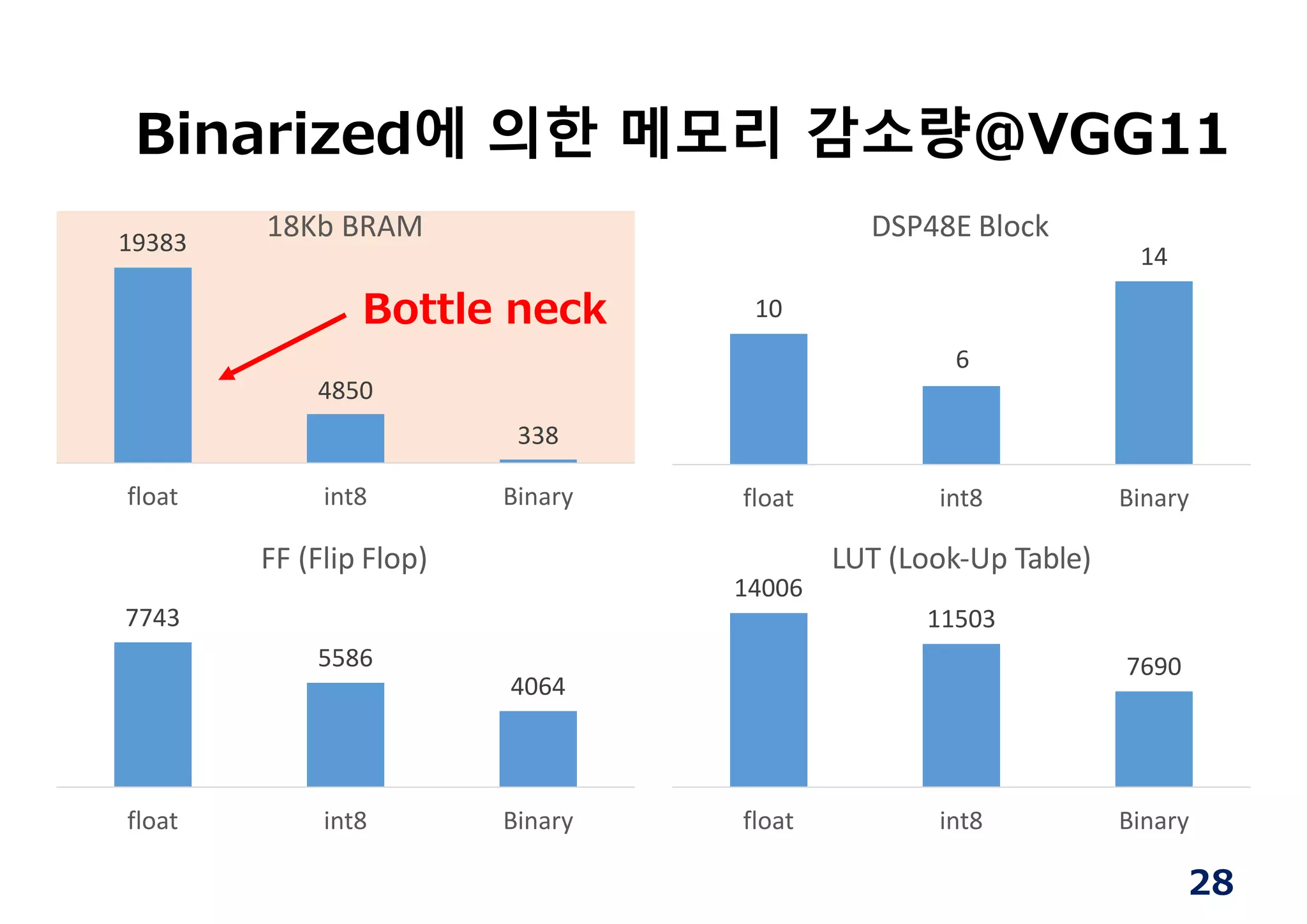
• 양자화 bit수를줄여서 면적과 대역에 이득
• 인식정도에 영향이 큰 곳은 크게
• Single precision floating point number를 8 또는 4 bit
로 줄여도(VGG16), 인식률은 0.4% 저하
J. Qiu et al., “Going Deeper with Embedded FPGA
Platform for Convolutional Neural Network,” ISFP
GA2016.
17
FPGA와 타 디바이스의비교
• FPGA의 이점
• 바꿔쓰기 가능(알고리즘 변경에 대응)→ASIC에 비해 이점
• 전력성능효율이 우수→CPU, GPU에 비해 이점
• FPGA의 단점
• CPU에 비해 → 비쌈
• GPU에 비해 → 일반적으로 느리고 개발기간이 길다.
• ASIC에 비해 →비쌈, 전력효율 낮음
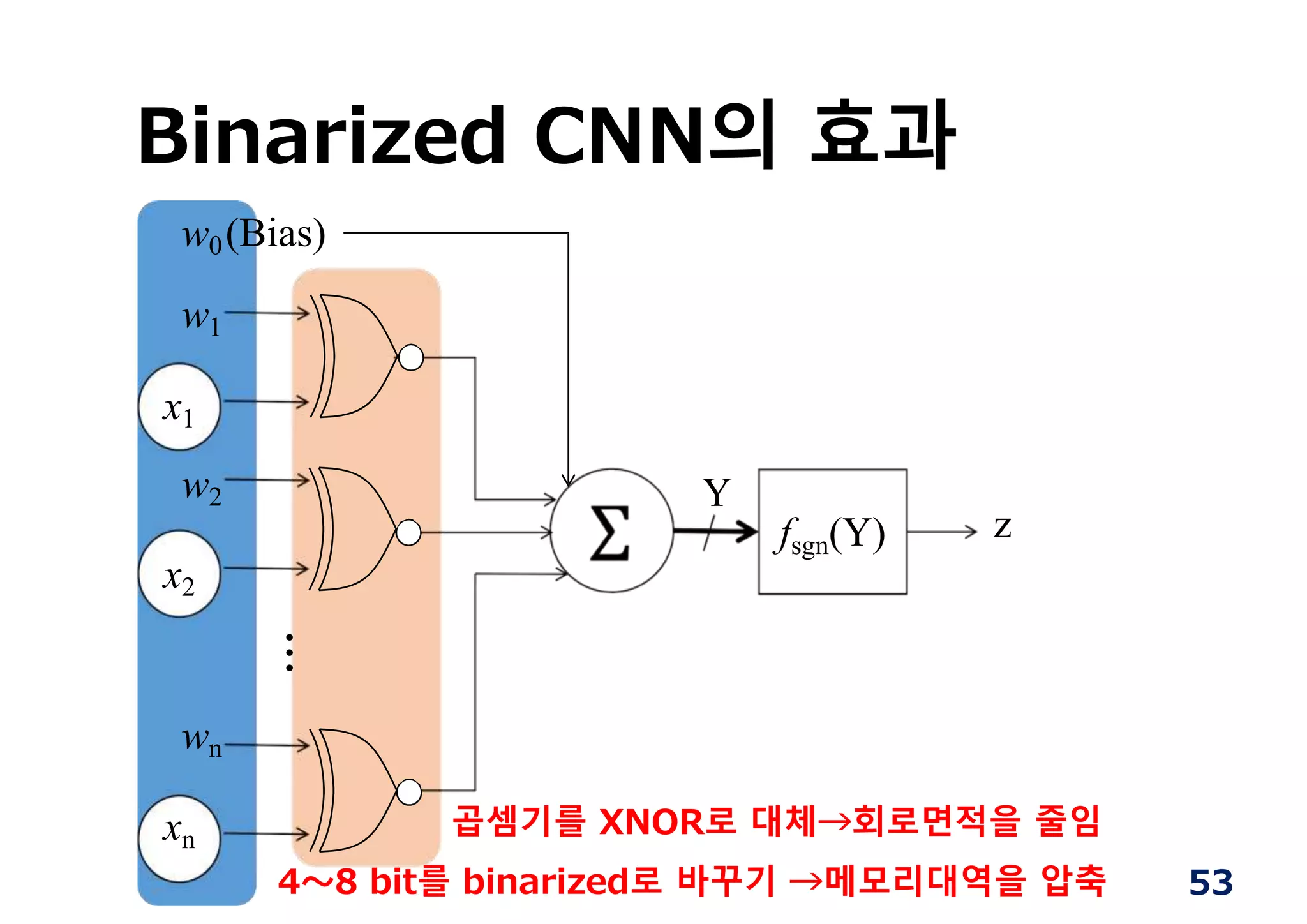
Binarized CNN의 도입 →고속화・메모리 줄이고
(=비용절감・저전력)
19
20.
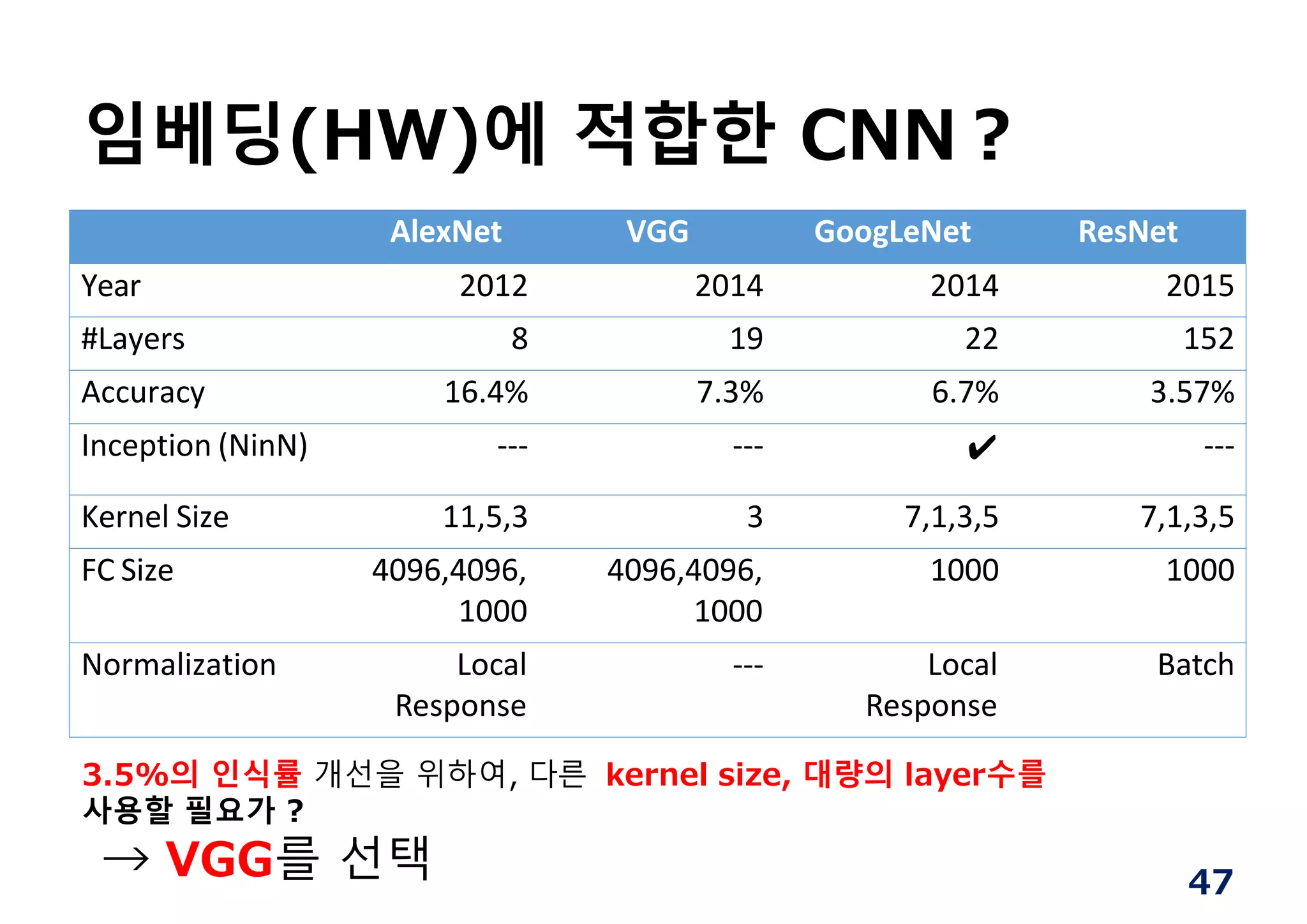
임베딩(HW)에 적합한 CNN︖
AlexNetVGG GoogLeNet ResNet
Year 2012 2014 2014 2015
#Layers 8 19 22 152
Accuracy 16.4% 7.3% 6.7% 3.57%
Inception (NinN) ‐‐‐ ‐‐‐ ✔ ‐‐‐
Kernel Size 11,5,3 3 7,1,3,5 7,1,3,5
FC Size 4096,4096,
1000
4096,4096,
1000
1000 1000
Normalization Local
Response
‐‐‐ Local
Response
Batch
3.5%의 인식률 개선을 위하여, 다른 kernel size, 대량의 layer수를
사용할 필요가 ?
→ VGG를 선택 47
21.
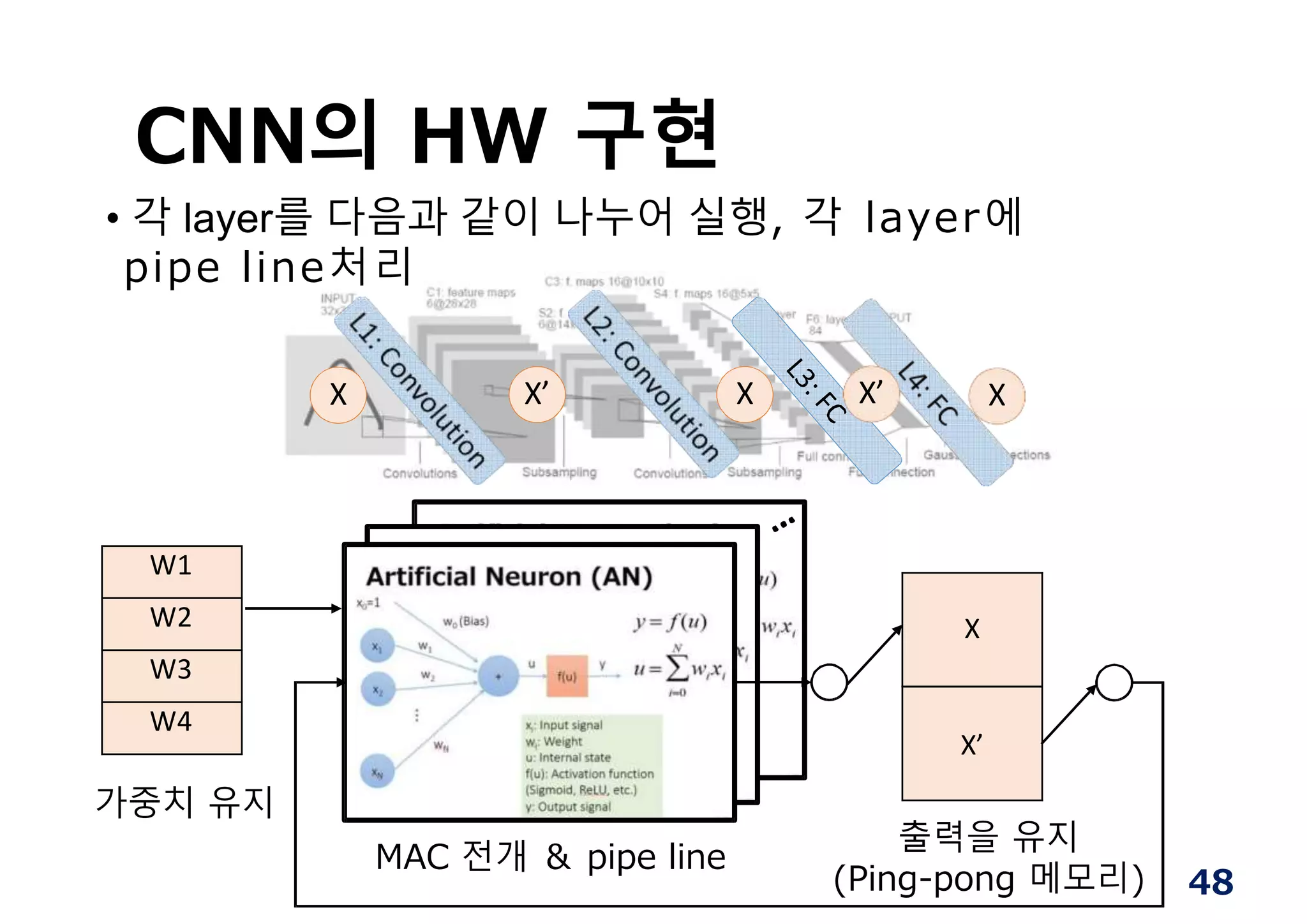
CNN의 HW 구현
W1
W2
W3
W4
X
X’
가중치유지
출력을 유지
(Ping-pong 메모리)
X X’ X X’ X
48
MAC 전개 & pipe line
• 각 layer를 다음과 같이 나누어 실행, 각 layer에
pipe line처리
22.
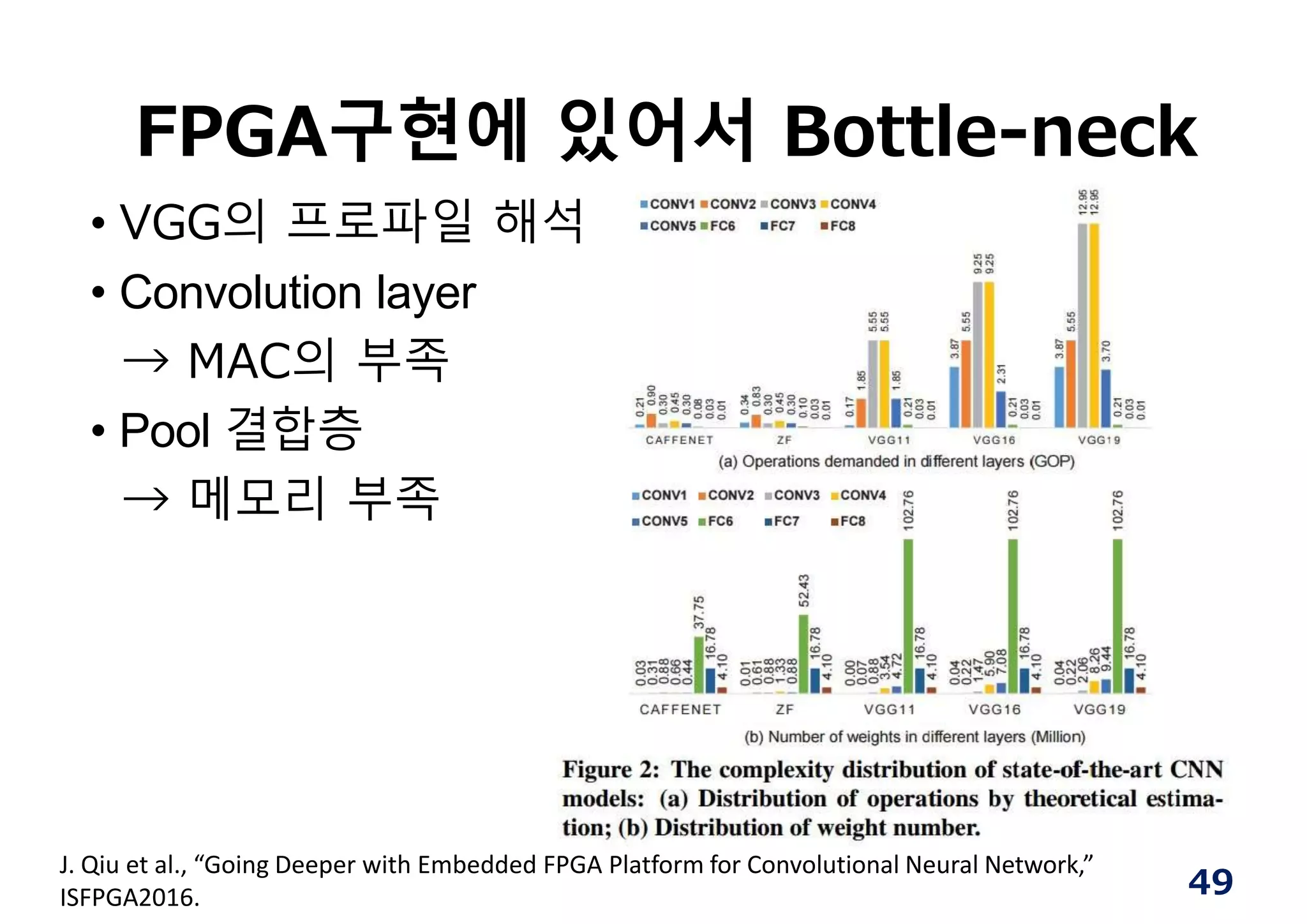
FPGA구현에 있어서 Bottle-neck
•VGG의 프로파일 해석
• Convolution layer
→ MAC의 부족
• Pool 결합층
→ 메모리 부족
J. Qiu et al., “Going Deeper with Embedded FPGA Platform for Convolutional Neural Network,”
ISFPGA2016. 49
27
Binarized on FPGA가트렌드
• FPT2016 (12월)
• E. Nurvitadhi (Intel) et al., “Accelerating Binarized Neural
Networks: Comparison of FPGA, CPU, GPU, and ASIC”
• H. Nakahara (東⼯⼤), “A Memory-Based Realization of a
Binarized Deep Convolutional Neural Network”
• ISFPGA2017
• Ritchie Zhao et al., “Accelerating Binarized Convolutional Neural
Networks with Software-Programmable FPGAs”
• Y. Umuroglu (Xilinx) et al., FINN: A Framework for Fast,
Scalable Binarized Neural Network Inference
• H. Nakahara, H. Yonekawa (東⼯⼤), et al. “A Batch Nor
malization Free Binarized Convolutional Deep Neural N
etwork on an FPGA”
• Y. Li et al., “A 7.663-TOPS 8.2-W Energy-efficient FPGA
Accelerator for Binary Convolutional Neural Networks,”
• G. Lemieux, “TinBiNN: Tiny Binarized Neural Network Overlay
in Less Than 5,000 4-LUTs,”
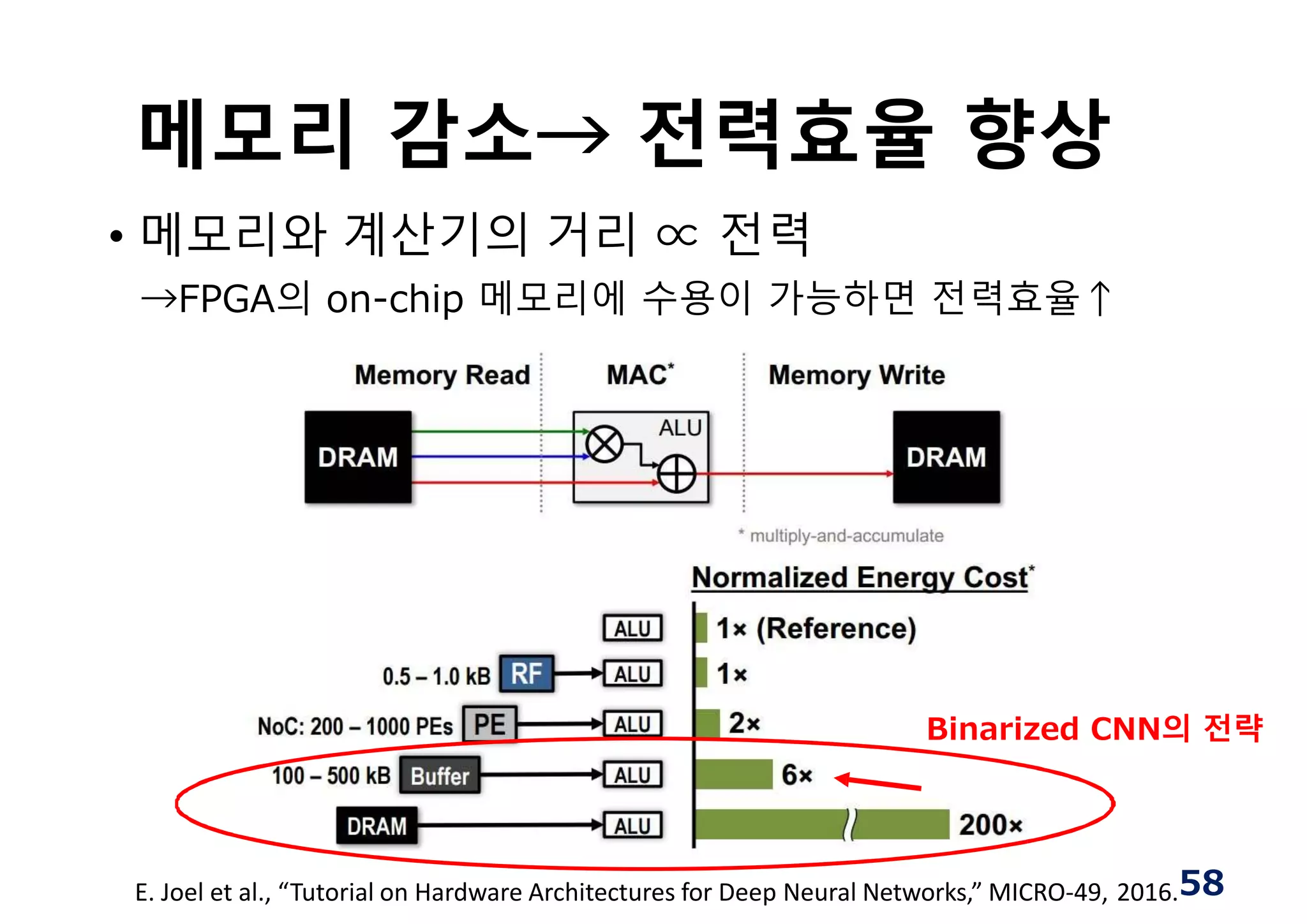
메모리 감소→ 전력효율향상
• 메모리와 계산기의 거리 ∝ 전력
→FPGA의 on-chip 메모리에 수용이 가능하면 전력효율↑
E. Joel et al., “Tutorial on Hardware Architectures for Deep Neural Networks,” MICRO‐49, 2016.58
Binarized CNN의 전략
30.
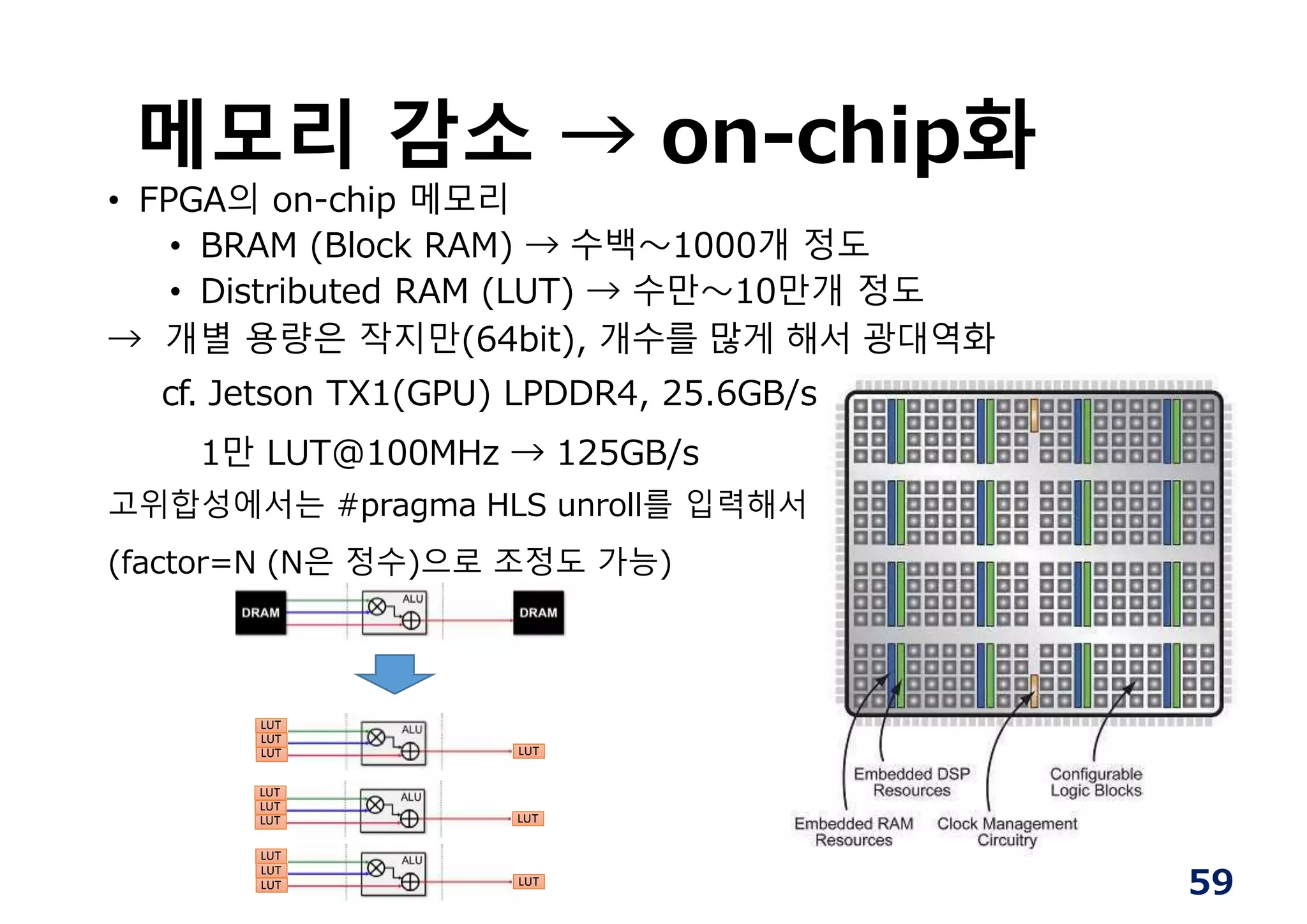
메모리 감소 →on-chip화
• FPGA의 on-chip 메모리
• BRAM (Block RAM) → 수백〜1000개 정도
• Distributed RAM (LUT) → 수만〜10만개 정도
→ 개별 용량은 작지만(64bit), 개수를 많게 해서 광대역화
cf. Jetson TX1(GPU) LPDDR4, 25.6GB/s
1만 LUT@100MHz → 125GB/s
고위합성에서는 #pragma HLS unroll를 입력해서
(factor=N (N은 정수)으로 조정도 가능)
59
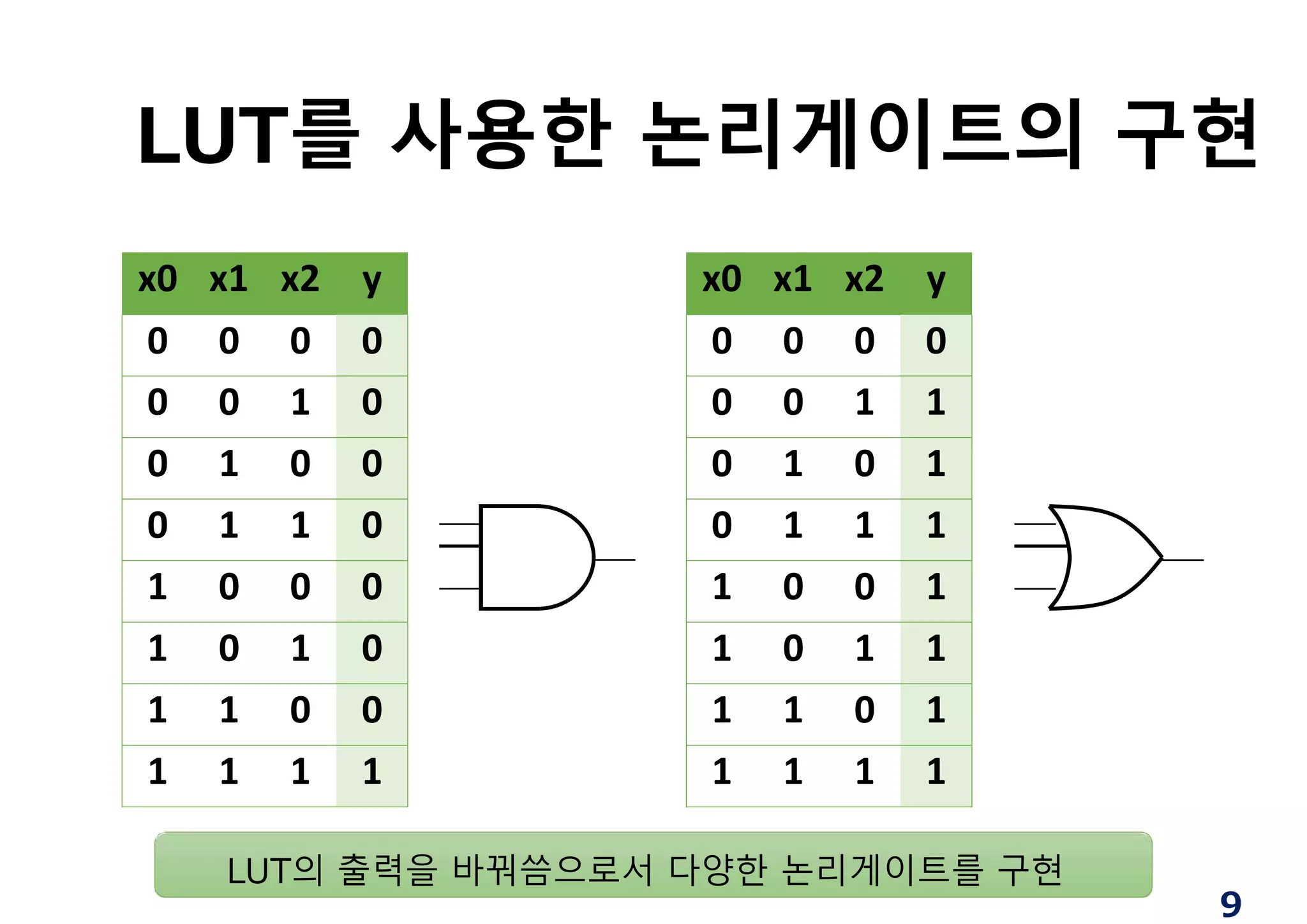
LUT
LUT
LUT LUT
LUT
LUT
LUT LUT
LUT
LUT
LUT LUT
31.
인식정확도 저하에 대하여
•Batch Normalization을 도입
0
20
40
60
80
100
Classificationerror(%)
1 80 160 200
# of epochs
0
20
40
60
80
100
Classificationerror(%)
1 80
# of epochs
160 200
단순히 binarized한 경우
제안방법
(a) float32 bit precision CNN (b) Binarized CNN
약 6%의 차이(VGG‐16를 사용)
H. Nakahara et al., “A memory‐based binarized convolutional deep neural network,”
FPT2016, pp285‐288, 2016.
31
32.
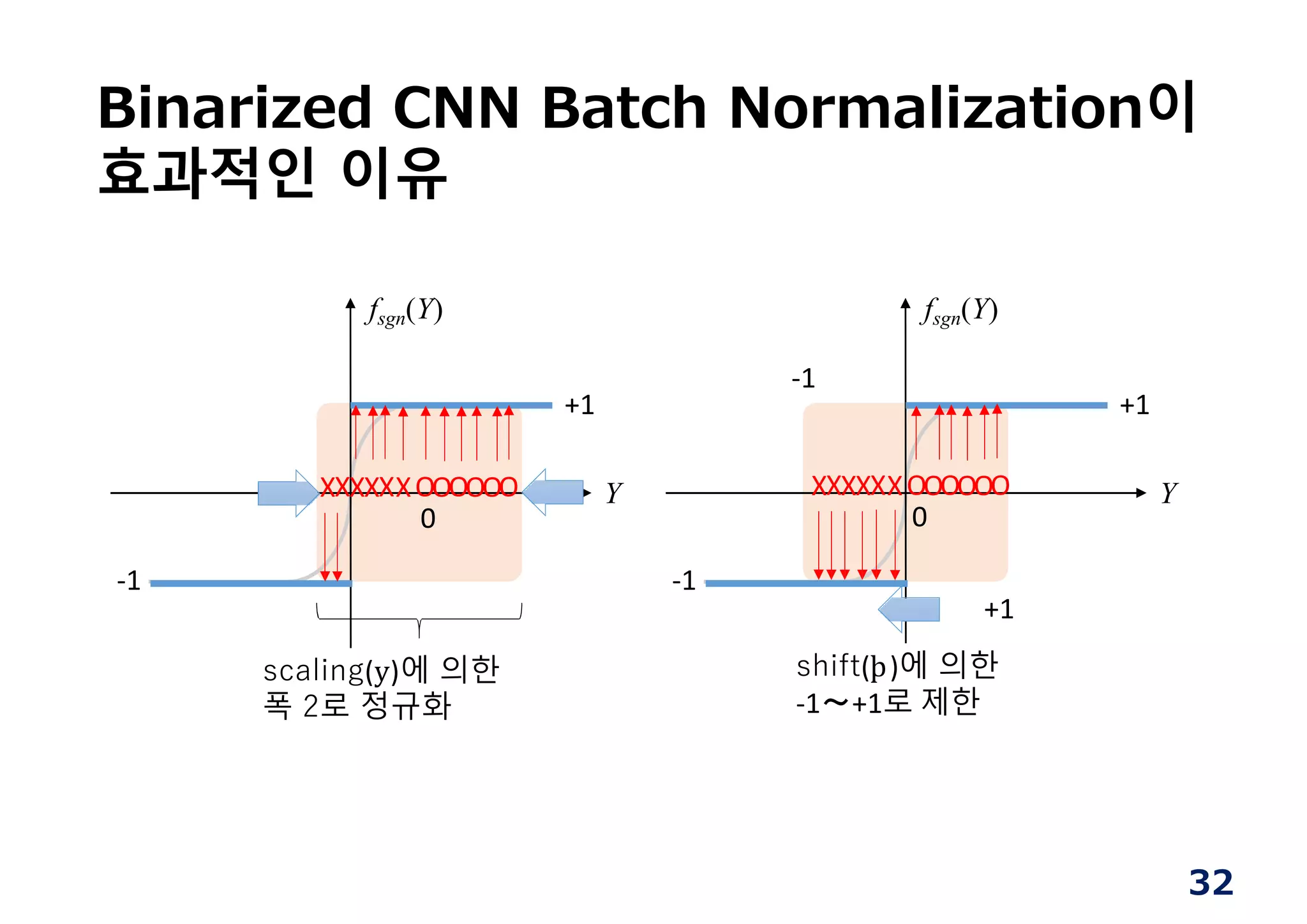
Binarized CNN BatchNormalization이
효과적인 이유
Y
fsgn(Y)
‐1
+1
XXXXXXOOOOOO
0
Y
fsgn(Y)
‐1
+1
XXXXXXOOOOOO
0
+1
‐1
scaling(y)에 의한
폭 2로 정규화
shift(þ)에 의한
‐1〜+1로 제한
32
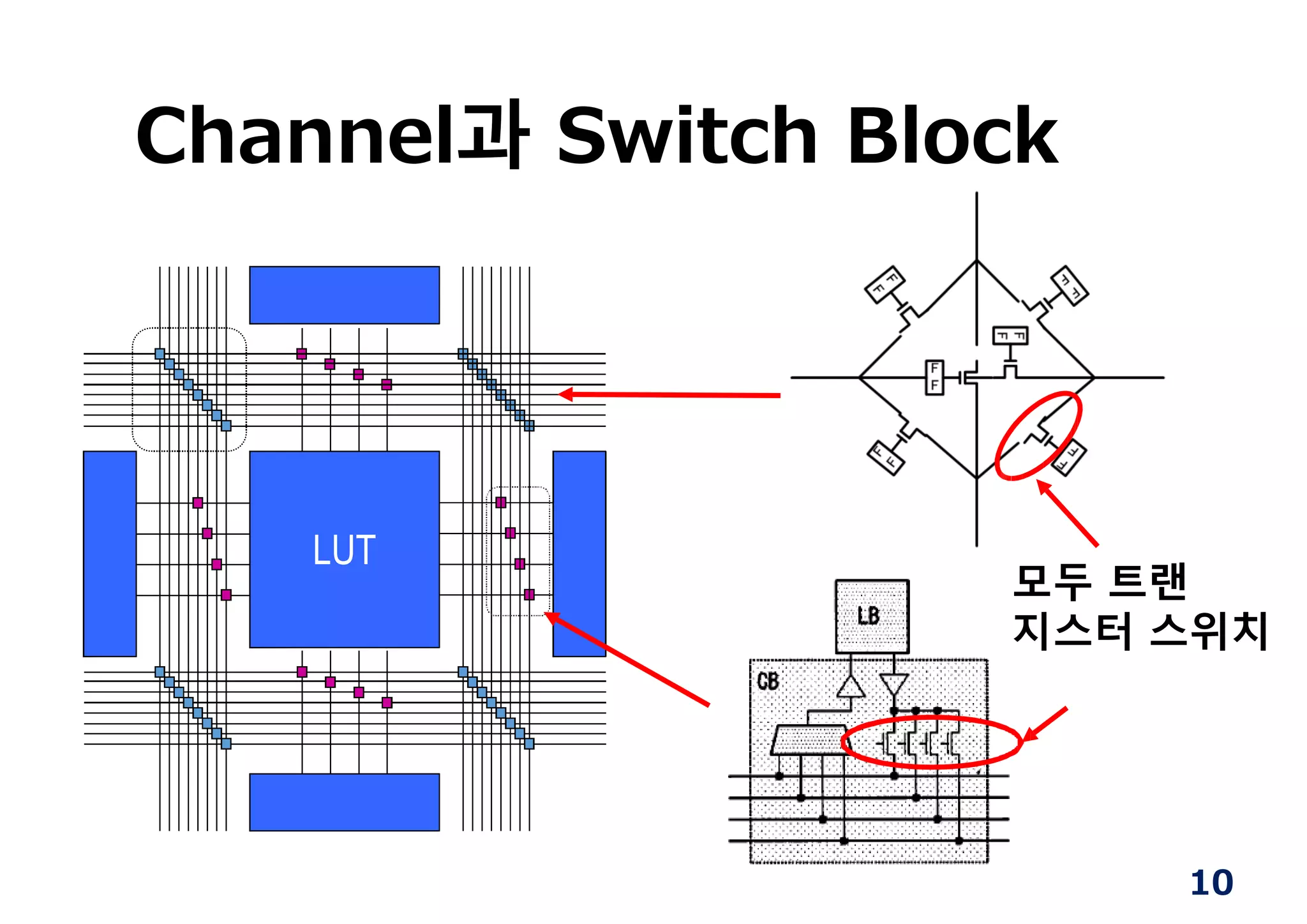
실제 구현시…
63
module hoge(
inputa, b, c;
output d
);
assign d = (a & b) | c;
endmodule
실현하고자하는 논리회로를
하드웨어 기술언어로
대량의 HDL로 쓰기
(Verilog HDL / VHDL)
Y = X.dot(W)+B
학습한 딥 뉴럴네트웍의 행렬연산을
간단하게 1줄로
High-Level Synthesis
(HLS)
• C/C++로설계→소규모 업체에서도
HW를 설계 가능
• Binarized Neural Net을 1개월만에
제작
짧은 개발기간(Turn around time, TAT)이란
FPGA의 장점을 이끌어냄
36
37.
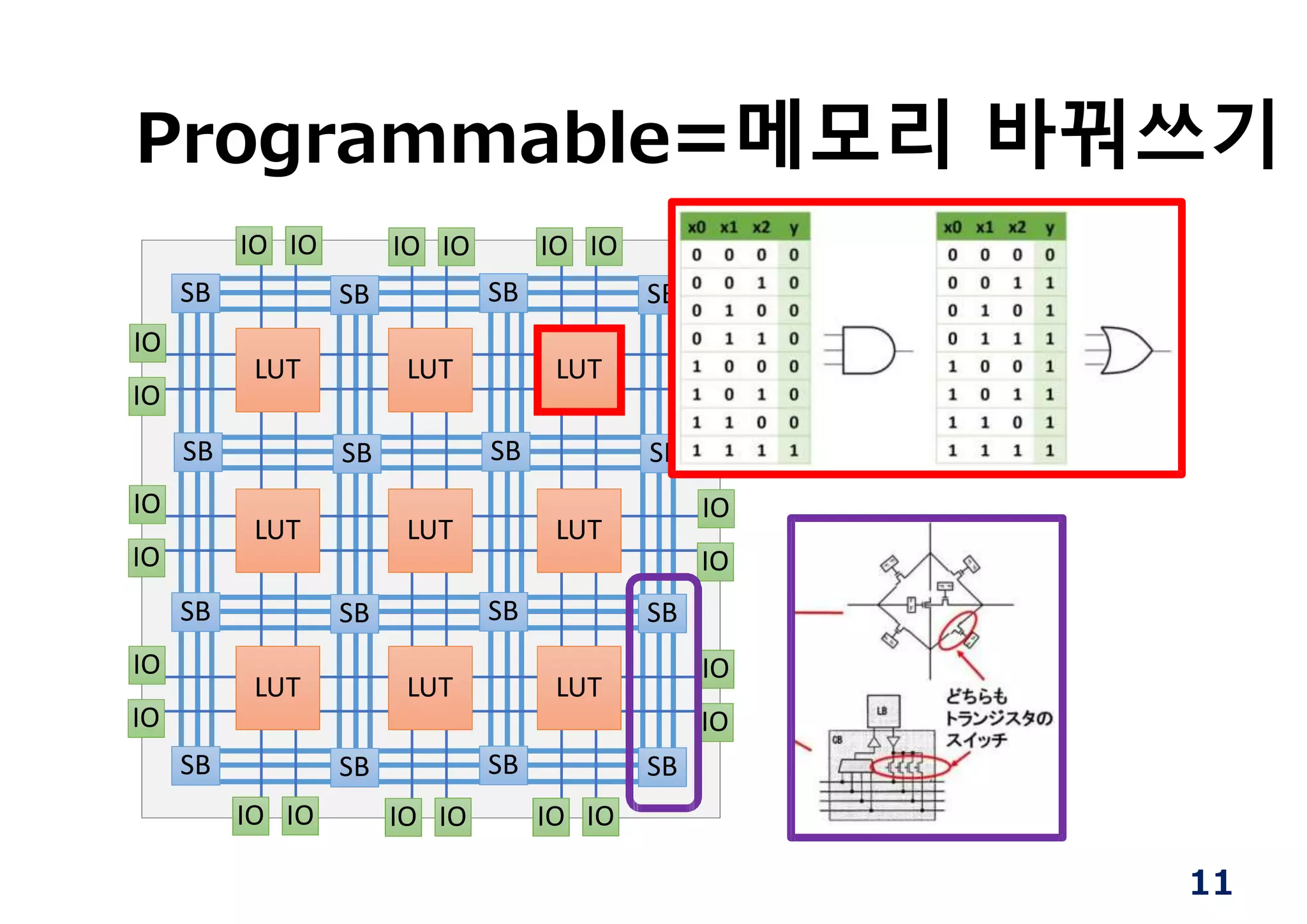
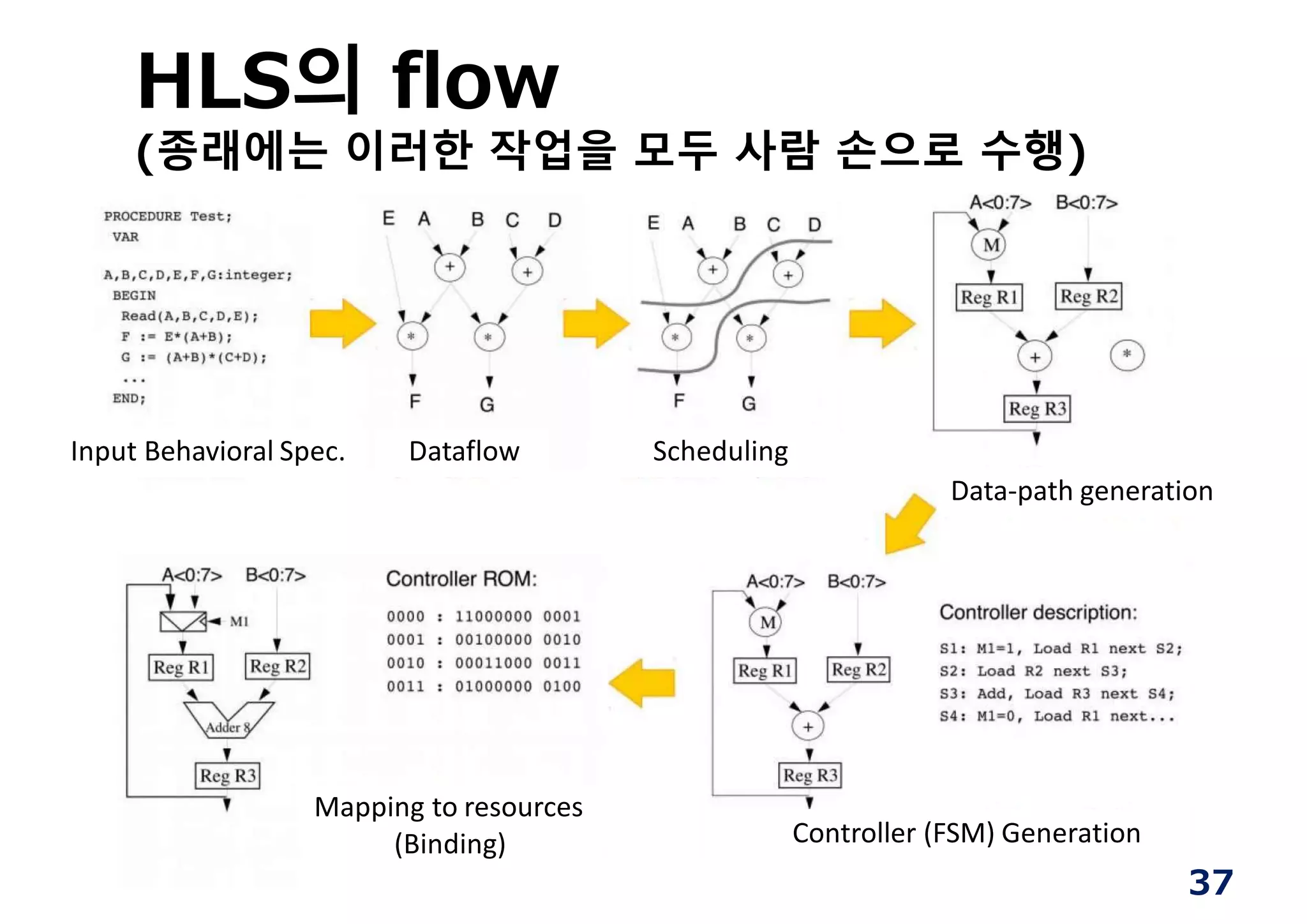
HLS의 flow
(종래에는 이러한작업을 모두 사람 손으로 수행)
Input Behavioral Spec. Dataflow Scheduling
Data‐path generation
Controller (FSM) Generation
Mapping to resources
(Binding)
37
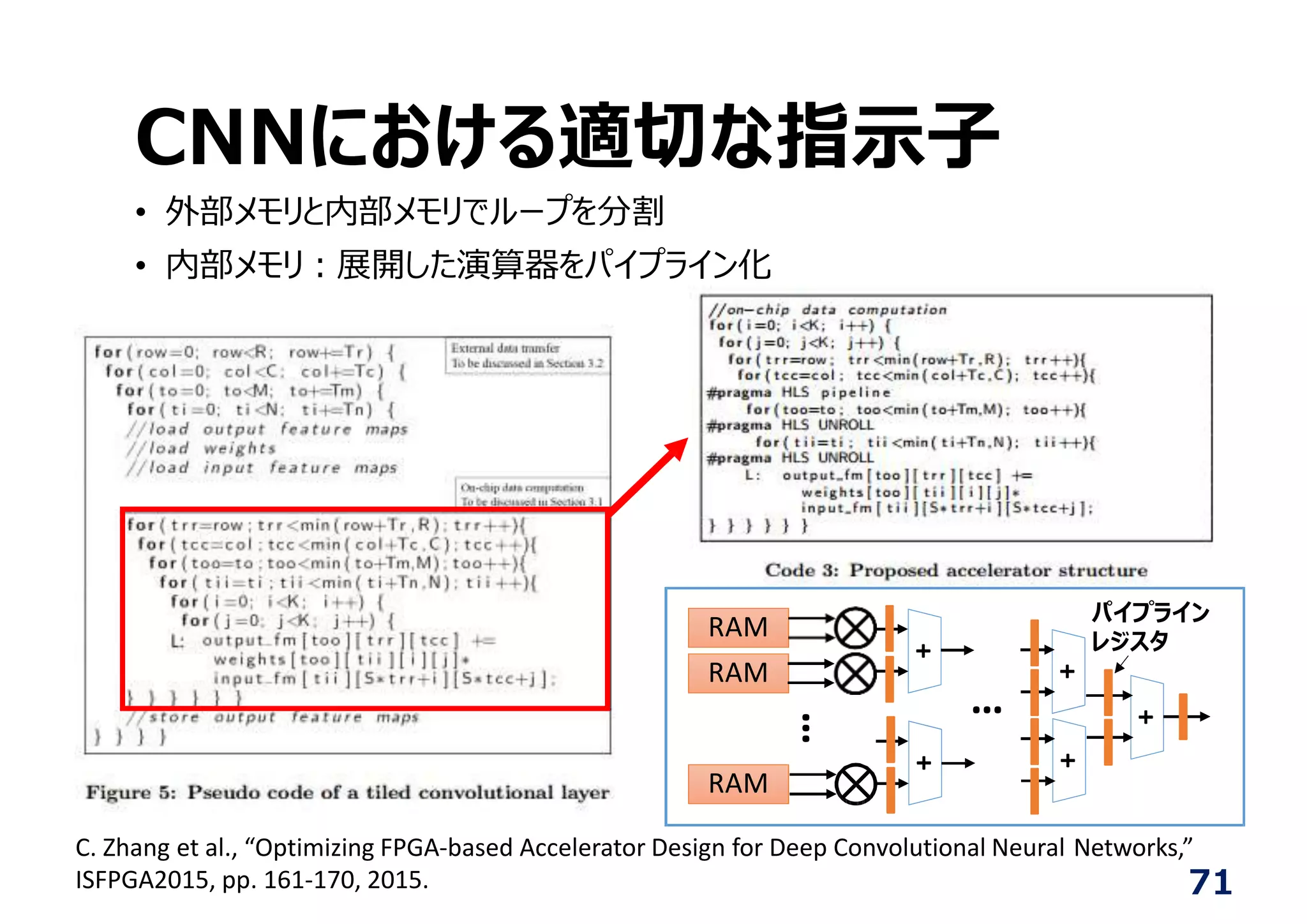
38.
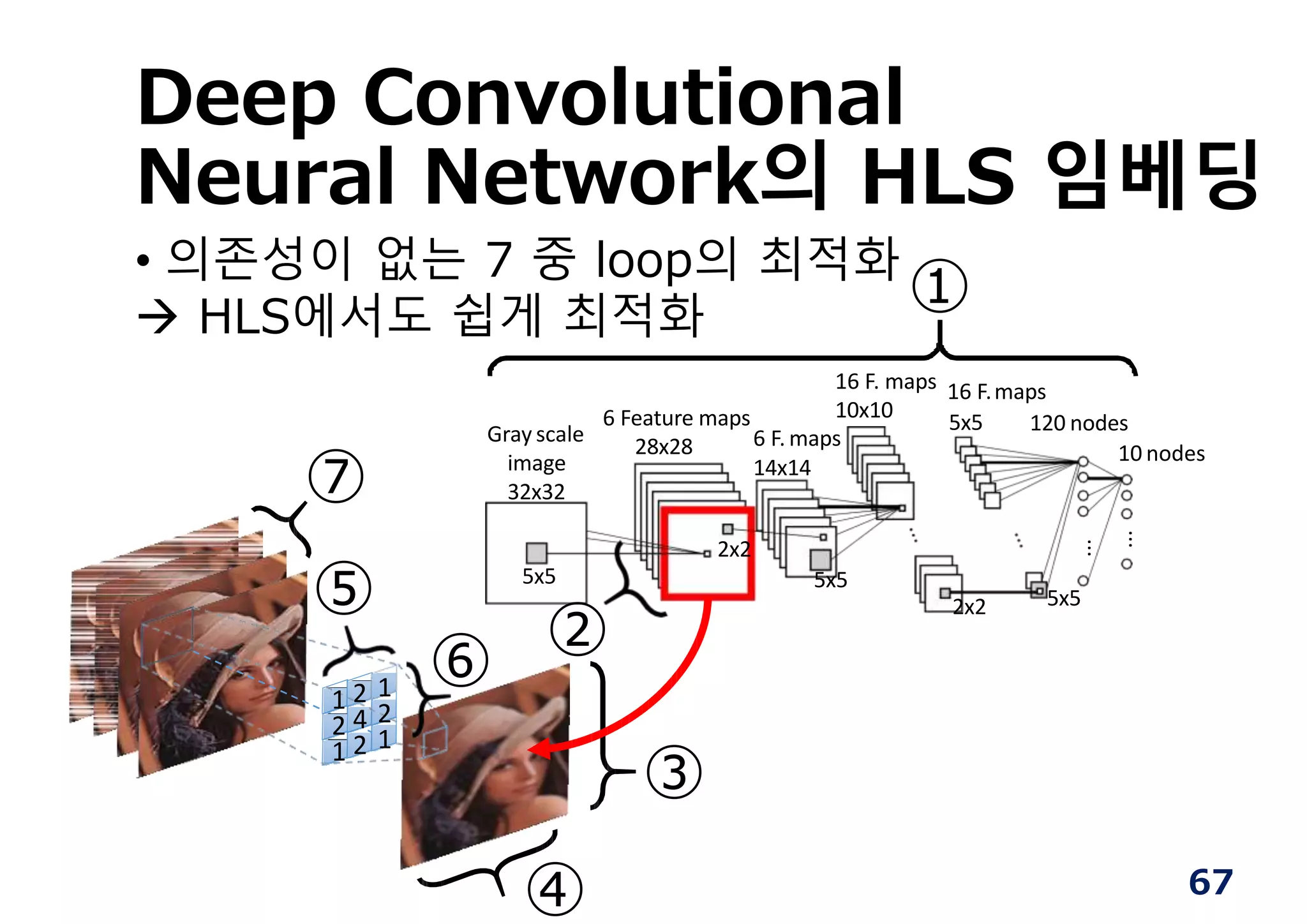
Deep Convolutional
Neural Network의HLS 임베딩
• 의존성이 없는 7 중 loop의 최적화
HLS에서도 쉽게 최적화
...
...
120 nodes
10 nodes
5x5
16 F. maps 16 F.maps
10x10
6 F. maps
14x14
6 Feature maps
28x28
Gray scale
image
32x32
5x5
2x2
5x5
2x2 5x5
1 2 1
2 4 2
1 2 1
①
②
③
④
⑥
⑦
⑤
67
39.
HLS에 의한 자동합성
행렬연산 라이브러리의 중심
을 C/C++로 작성
하지만 HDL보다는 추상적
Y=0;
for(i=0; i < m; i++){ f
or( j = 0; j < n; j++){
Y += X[i][j]*W[j][i];
}
}
FPGA업체의
HLS tool이 HDL
을 작성
↓
기존의 방법
으로 FPGA로 구현
자동합성
DNN을 기존 frame work
로 설계 (학습은 GPU로)
학습 된 CNN을
이진화로 변환
(개발중)
68
40.
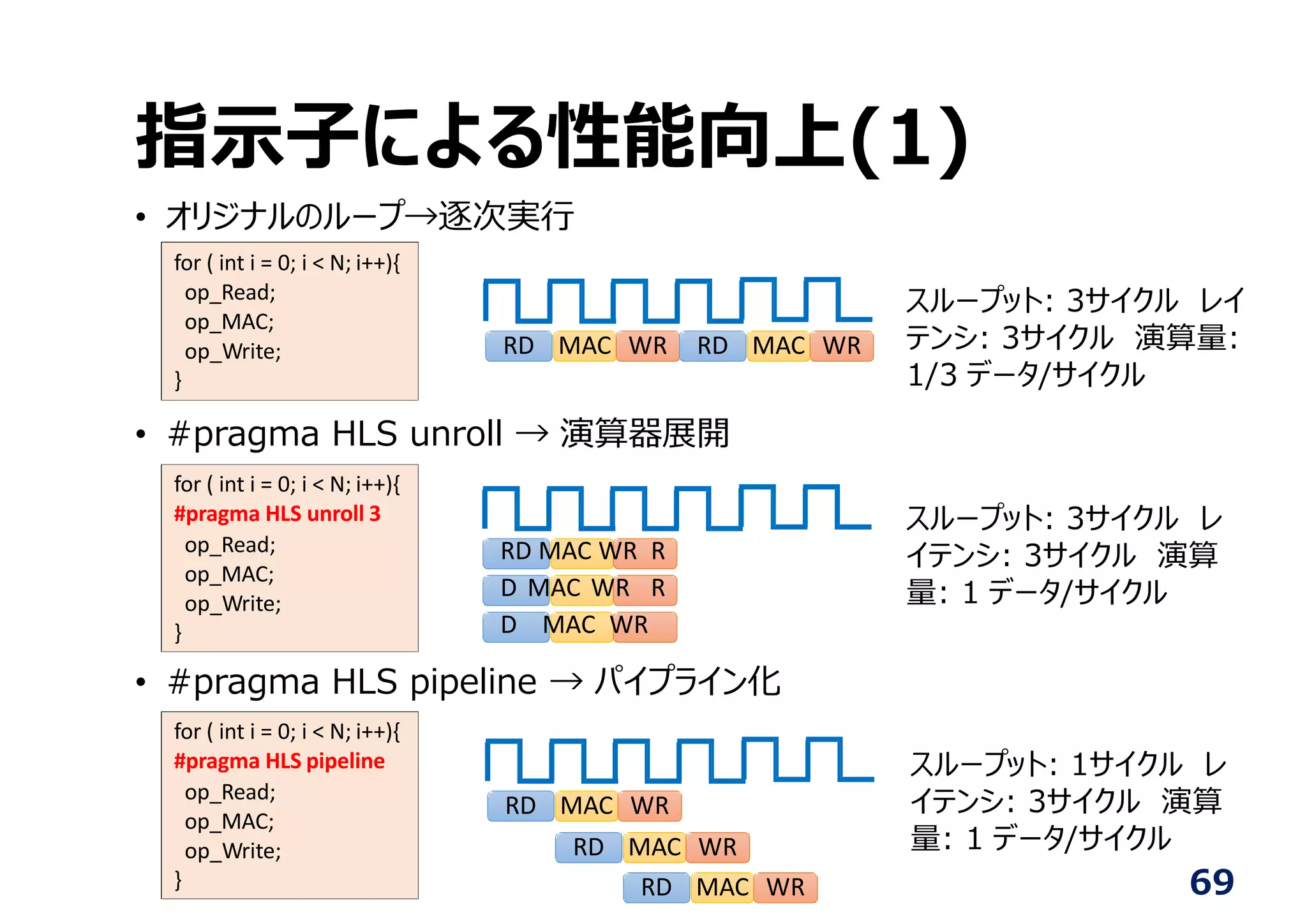
指⽰⼦による性能向上(1)
• オリジナルのループ→逐次実⾏
• #pragmaHLS unroll → 演算器展開
• #pragma HLS pipeline → パイプライン化
for ( int i = 0; i < N; i++){
op_Read;
op_MAC;
op_Write;
}
for ( int i = 0; i < N; i++){
#pragma HLS pipeline
op_Read;
op_MAC;
op_Write;
}
for ( int i = 0; i < N; i++){
#pragma HLS unroll 3
op_Read;
op_MAC;
op_Write;
}
RD MAC WR RD MAC WR
RD MAC WR
RD MAC WR
RD MAC WR
RD MAC WR R
D MAC WR R
D MAC WR
スループット: 3サイクル レイ
テンシ: 3サイクル 演算量:
1/3 データ/サイクル
スループット: 3サイクル レ
イテンシ: 3サイクル 演算
量: 1 データ/サイクル
スループット: 1サイクル レ
イテンシ: 3サイクル 演算
量: 1 データ/サイクル
69
41.
指⽰⼦による性能向上(2)
• #pragma HLSunroll → 演算器展開
• #pragma HLS pipeline → パイプライン化
Int X[100];
#pragma HLS array partition
for ( int i = 0; i < N; i++){
#pragma HLS pipeline
op_Read;
op_MAC;
op_Write;
}
Int X[100];
#pragma HLS array partition
for ( int i = 0; i < N; i++){
#pragma HLS unroll 3
op_Read;
op_MAC;
op_Write;
}
RD MAC WR R
D MAC WR R
D MAC WR
スループット: 3サイクル レ
イテンシ: 3サイクル 演算
量: 1 データ/サイクル
スループット: 1サイクル レ
イテンシ: 3サイクル 演算
量: 1 データ/サイクル
70
Mem Mem
Mem Mem
Mem Mem
RD MAC WR
RD MAC WR
RD MAC WR
RD MAC WR
Mem Mem
Mem Mem
49
결론
• HW용 CNN의트렌드를 소개
• 기술은 정신없이 발전 중
• 올해에도 중요한 발표가 있을 가능성이 매우 높음
• Binarized CNN의 소개
• 연산기를 XOR 게이트, 메모리를 내부 메모리로 구현
• FPGA에서도 고성능이면서 저전력화를 달성
• HLS에 의해 단기간에 설계
• Deep learning framework과의 연대로
소규모 업체에서도 고성능 HW 개발 가능
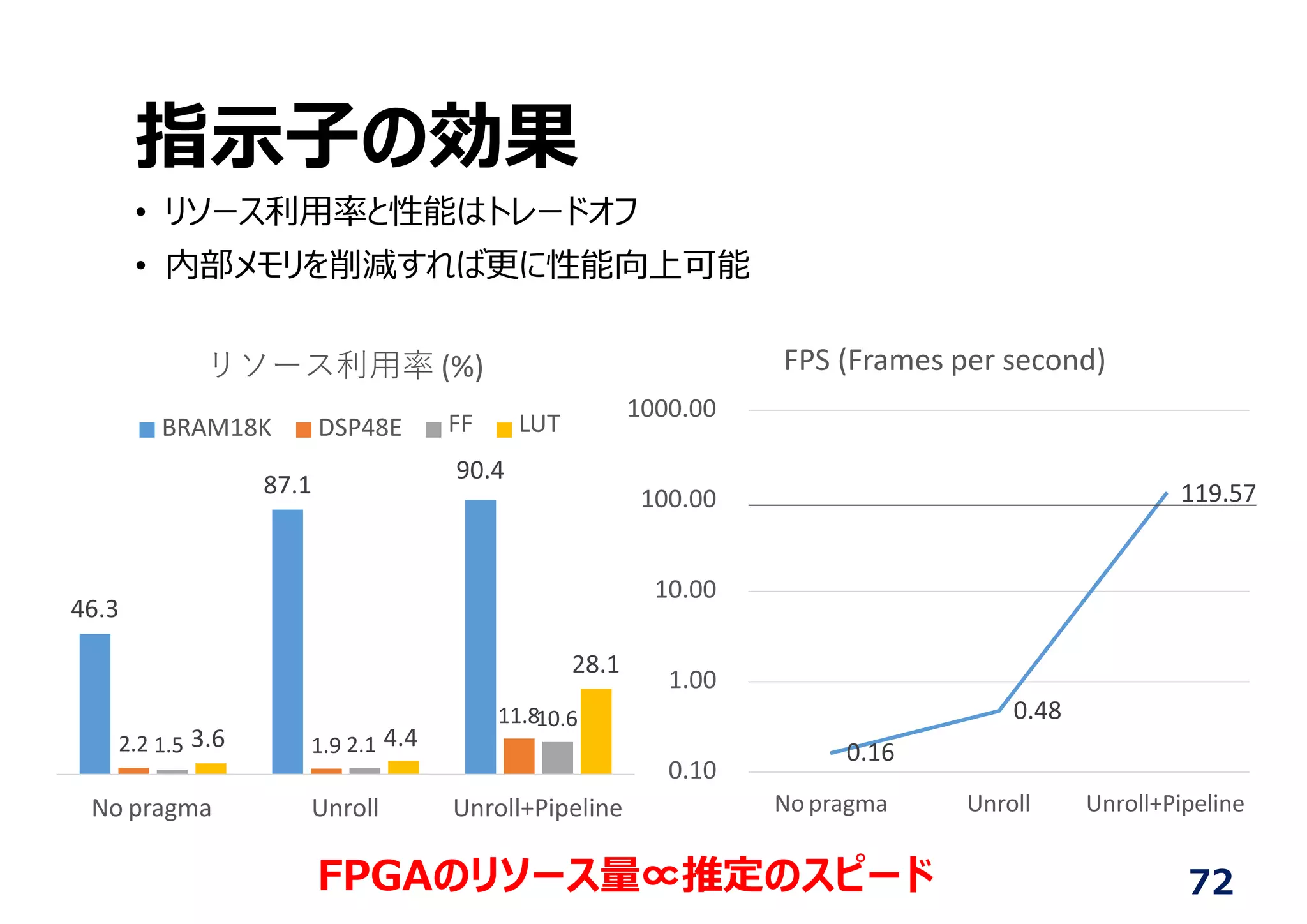
• FPGA의 리소스량∝성능, 하지만 전력・비용과의 trade-off
• GPU, CPU와의 비교
• GPU보다 고속이며, 인식정도는 5% 정도 낮음, 전력효율은 5.5배
• 인식정도 저하는 학습기법을 통해 커버가능











![24
Low-precision CNN 관련논문
• Binary Connected [NIPS, Dec., 2015]
• Binarized Neural Networks [arXiv, Mar., 2016]
• Ternary-Net [arXiv, May, 2016]
→ Intel이 ResNet을 구현. 인식정확도 2% 저하로
GPU (Titan X)과 동일한 성능[ISFPGA, Feb., 2017]
• Local Binary CNNs [Aug., 2016]
• XNOR-Net [ECCV, Oct., 2016]](https://image.slidesharecdn.com/cnnonfpga-170415010210/75/Binarized-CNN-on-FPGA-24-2048.jpg)






![HLS에 의한 자동 합성
행렬연산 라이브러리의 중심
을 C/C++로 작성
하지만 HDL보다는 추상적
Y=0;
for(i=0; i < m; i++){ f
or( j = 0; j < n; j++){
Y += X[i][j]*W[j][i];
}
}
FPGA업체의
HLS tool이 HDL
을 작성
↓
기존의 방법
으로 FPGA로 구현
자동합성
DNN을 기존 frame work
로 설계 (학습은 GPU로)
학습 된 CNN을
이진화로 변환
(개발중)
68](https://image.slidesharecdn.com/cnnonfpga-170415010210/75/Binarized-CNN-on-FPGA-39-2048.jpg)
![指⽰⼦による性能向上(2)
• #pragma HLS unroll → 演算器展開
• #pragma HLS pipeline → パイプライン化
Int X[100];
#pragma HLS array partition
for ( int i = 0; i < N; i++){
#pragma HLS pipeline
op_Read;
op_MAC;
op_Write;
}
Int X[100];
#pragma HLS array partition
for ( int i = 0; i < N; i++){
#pragma HLS unroll 3
op_Read;
op_MAC;
op_Write;
}
RD MAC WR R
D MAC WR R
D MAC WR
スループット: 3サイクル レ
イテンシ: 3サイクル 演算
量: 1 データ/サイクル
スループット: 1サイクル レ
イテンシ: 3サイクル 演算
量: 1 データ/サイクル
70
Mem Mem
Mem Mem
Mem Mem
RD MAC WR
RD MAC WR
RD MAC WR
RD MAC WR
Mem Mem
Mem Mem](https://image.slidesharecdn.com/cnnonfpga-170415010210/75/Binarized-CNN-on-FPGA-41-2048.jpg)


![GPU, CPU와의 비교
Platform
Device Artix 7Quad‐core ARM
Cortex‐A57
1.9 GHz
0.2
7
0.03
256‐core
Maxwell GPU
998 MHz
116.9
17
6.87
Clock Freq.
FPS
Power [W] Efficie
ncy [FPS/W] Accu
racy [%] 92.35
100 MHz
119.5
3
39.83
87.45
NVidia Jetson TX1
46
Digilent Nexys4 Video](https://image.slidesharecdn.com/cnnonfpga-170415010210/75/Binarized-CNN-on-FPGA-46-2048.jpg)



![[기초개념] Graph Convolutional Network (GCN)](https://cdn.slidesharecdn.com/ss_thumbnails/agistdkimgcn190507-190507153736-thumbnail.jpg?width=640&height=640&fit=bounds)


![[GTCJ2018]CuPy -NumPy互換GPUライブラリによるPythonでの高速計算- PFN奥田遼介](https://cdn.slidesharecdn.com/ss_thumbnails/gtcj2018cupypfnryosukeokuta-181009073034-thumbnail.jpg?width=640&height=640&fit=bounds)


















![[기초개념] Recurrent Neural Network (RNN) 소개](https://cdn.slidesharecdn.com/ss_thumbnails/agistpurnndkim190430-190430140949-thumbnail.jpg?width=640&height=640&fit=bounds)
























![[컴퓨터비전과 인공지능] 8. 합성곱 신경망 아키텍처 4 - ResNet](https://cdn.slidesharecdn.com/ss_thumbnails/lec8convolutionnetworksarcitecture4resnet-210214112234-thumbnail.jpg?width=640&height=640&fit=bounds)



![[GDG DevFest Gwangju 2018] 나도쓰고싶다 딥러닝: 통신/ IoT/ 웨어러블/ 에너지/ 의료헬스케어 적용하기](https://cdn.slidesharecdn.com/ss_thumbnails/gdgdevfestgwangju2018dkim-181212140243-thumbnail.jpg?width=640&height=640&fit=bounds)


![[컴퓨터비전과 인공지능] 8. 합성곱 신경망 아키텍처 5 - Others](https://cdn.slidesharecdn.com/ss_thumbnails/lec8convolutionnetworksarcitecture5others-210215060452-thumbnail.jpg?width=640&height=640&fit=bounds)

























