Downloaded 55 times



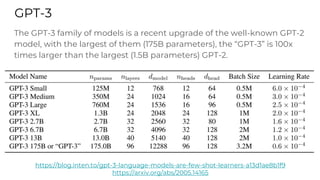
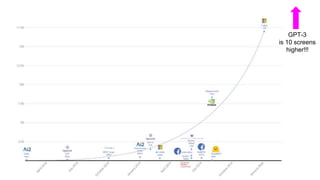
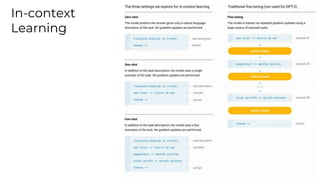



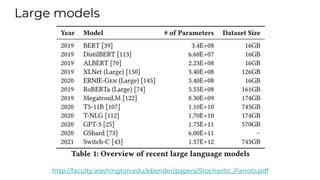
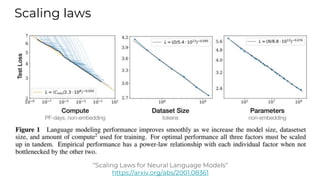
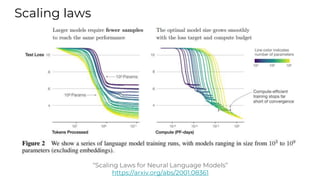











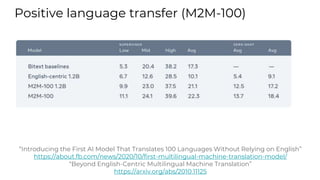

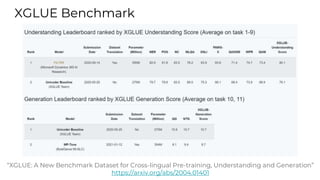
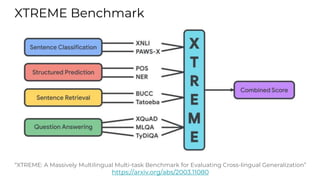
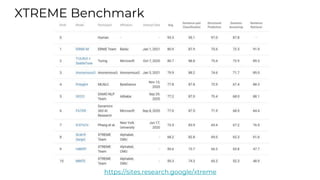

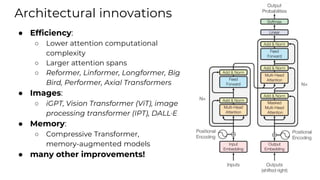
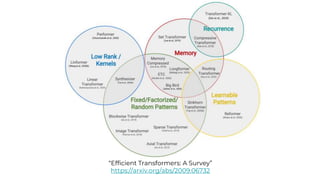










This document summarizes developments in natural language processing (NLP) in 2020. It discusses large language models like GPT-3, the increasing sizes of transformer-based models, issues with large models, multilingual models, more efficient transformer architectures, benchmarks for evaluating NLP systems, conversational agents, and APIs and cloud services for NLP.

















































![Artificial Intelligence (lecture for schoolchildren) [rus]](https://cdn.slidesharecdn.com/ss_thumbnails/artificialintelligencelectureforschoolchildrenrus-200823192321-thumbnail.jpg?width=640&height=640&fit=bounds)





































