Large Language Models: Diving into GPT, LLaMA, and More
This project looks at a research paper that breaks down how Large Language Models like GPT and LLaMA are trained, what makes them powerful, and how they're being used in real-world AI tools from chatbots to reasoning agents.
Introduction
● This projectlooks at a research paper
that breaks down how Large Language
Models (LLMs) like GPT and LLaMA are
trained, what makes them powerful,
and how they're used in real-world AI
tools from chatbots to reasoning
agents.
● LLMs are central to the current wave of
generative AI.
● Will look at how LLMs evolved, how
they’re built and evaluated.
The Evolution ofLanguage Models
● 1950s–1990s: Early models used statistical techniques like
n-grams
● 2000s: Neural language models emerged
● 2010s: RNNs and LSTMs improved context understanding
but had difficulty with long-range dependencies.
● 2017: The Transformer architecture was introduced
● 2020s: LLMs like GPT-3, PaLM, and LLaMA became active
Transformers
● Replaced recurrencewith self-attention
○ Parallel processing of sequences
○ Long-range context
○ Good scalability
● All modern LLMs like GPT, PaLM, and
LLaMA started using them
● Encoder-decoder architecture
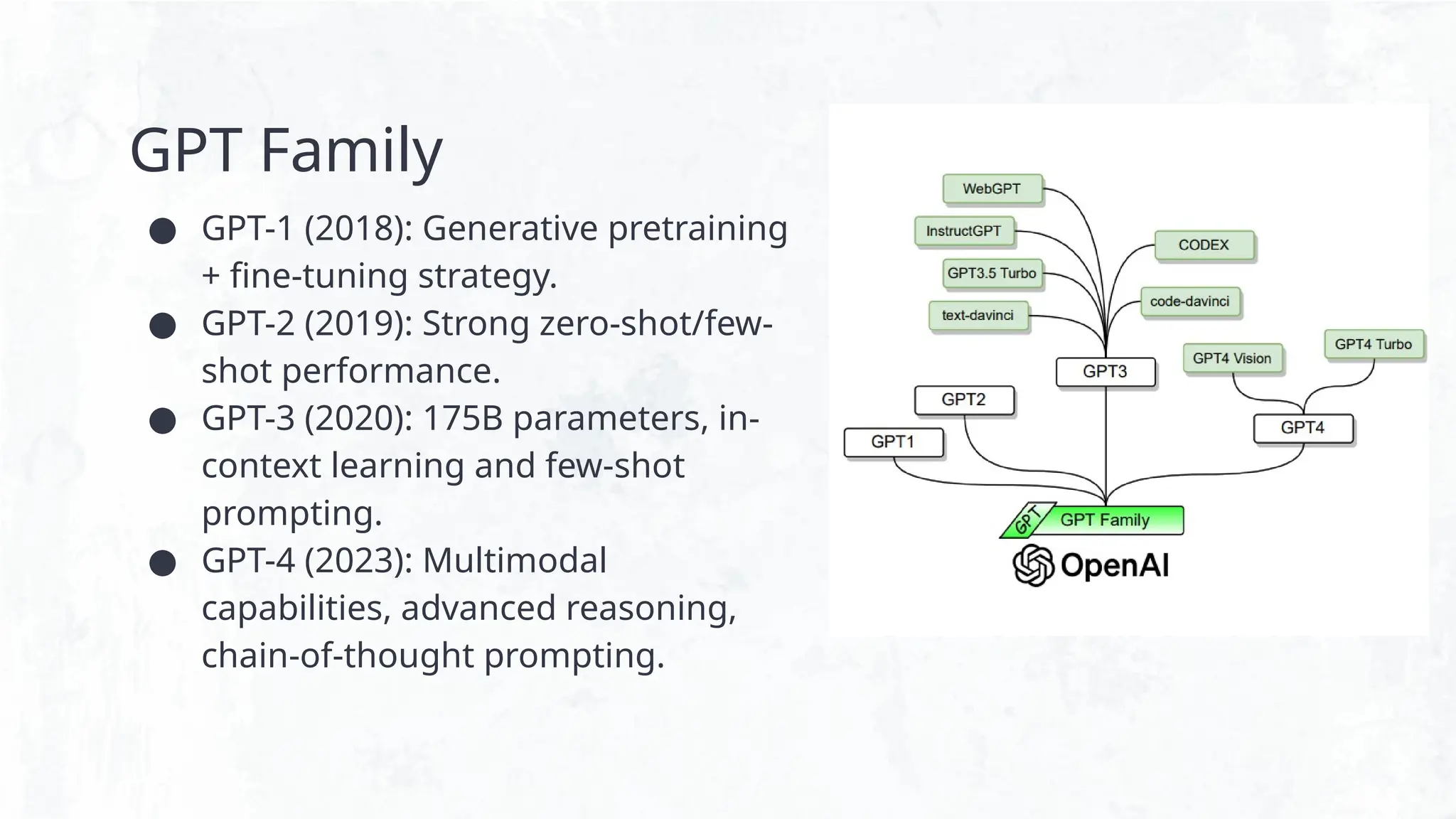
LLaMA
● LLaMA (Meta,2023): Released
models from 7B to 65B parameters
● Focus on efficiency
● Uses curated, high-quality datasets.
● Popular for research and fine-tuning
due to open source
● Enabled low-cost adaptation via
techniques like:
○ LoRA
○ QLoRA
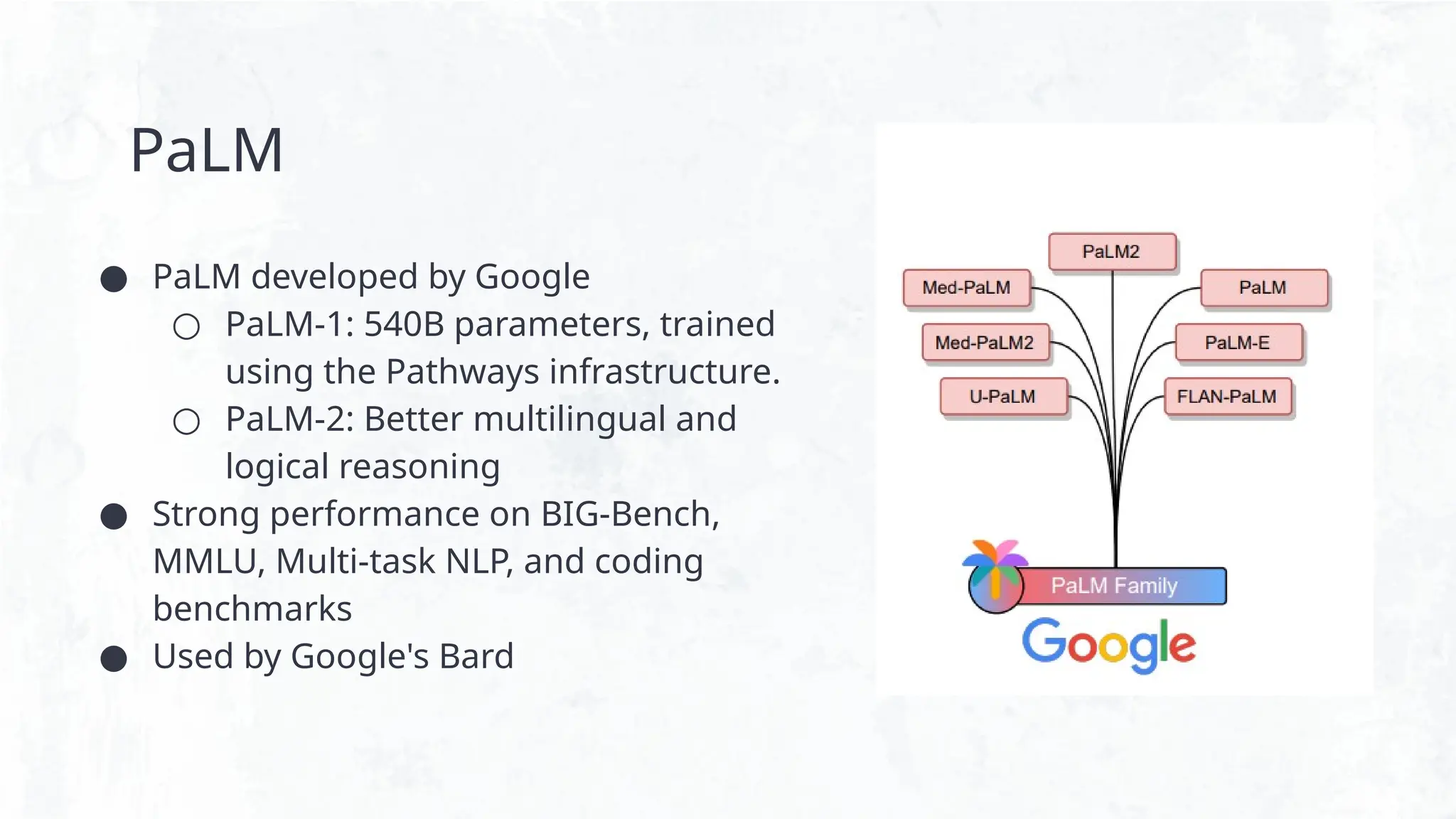
PaLM
● PaLM developedby Google
○ PaLM-1: 540B parameters, trained
using the Pathways infrastructure.
○ PaLM-2: Better multilingual and
logical reasoning
● Strong performance on BIG-Bench,
MMLU, Multi-task NLP, and coding
benchmarks
● Used by Google's Bard
Building LLMs
● LLMsare trained on massive text
● Data quality matters: deduplication,
cleaning
● Tokenization breaks text into chunks
● Training efficiency
● Model generalization
Model Architecture &Fine-Tuning
● Transformers use self-attention to model relationships
between all words in a sequence.
● They don’t know word order, that’s where positional
encoding comes in.
● Supervised Fine-Tuning: Adjust model on specific tasks
● RLHF (Reinforcement Learning from Human Feedback)
● DPO (Direct Preference Optimization)
● Decoding Strategies:
○ Greedy, Beam Search, Top-k, Top-p
LLM Augmentation
● RAG(Retrieval-Augmented Generation):
○ Adds knowledge to LLMs by fetching context
● Tool Use:
○ LLMs can call APIs, use calculators, run code
● Multimodal Extensions:
○ LLMs that handle images, audio, and video
Challenges & Future
●Challenges:
○ LLMs can generate incorrect or
made-up information.
○ Outputs can reflect training data
bias, raising concerns.
○ Compute Cost: Training and
inference require massive
resources
○ Closed-Source Limitations
● Future Directions:
○ Multimodal LLMs: Text + vision
+ audio + video in one model
○ LLMs with planning, memory,
and long-term goals
○ Long-Context Models: Extend
input size from 2k 100k+
→
tokens
○ More Open-Source Efforts
Conclusion
● LLMs likeGPT, LLaMA, and PaLM show a major future in AI
● They are built using transformers, massive datasets, and fine-
tuning techniques.
● LLMs are increasingly used in real-world tools
● Despite challenges like bias, research is rapidly evolving.
● The future is multimodal, agentic, and more open-source.

























































![[DSC Europe 25] Boris Perkovic - Lost in performance.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/uq5hrp7vsuahqkxzifux-1-251204082258-fd2ee09d-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Nikola Rajovic - Hardware Technologies Under the Hood: RISC-V...](https://cdn.slidesharecdn.com/ss_thumbnails/o2gptrmtoyqndgoshwgq-dsc2025-tenstorrent-rajovic-251205090438-814685f5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragana Ilic - AI for Big Data in Astronomy.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/8palya86qaatvjhva1ms-2-dragana-ilic-ai-ilic-251208151906-652b819c-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Max Talanov - Non digital NNs.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/wif8tr3gtua74qvtopke-non-digital-nns-251205090438-26b0eea6-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)
