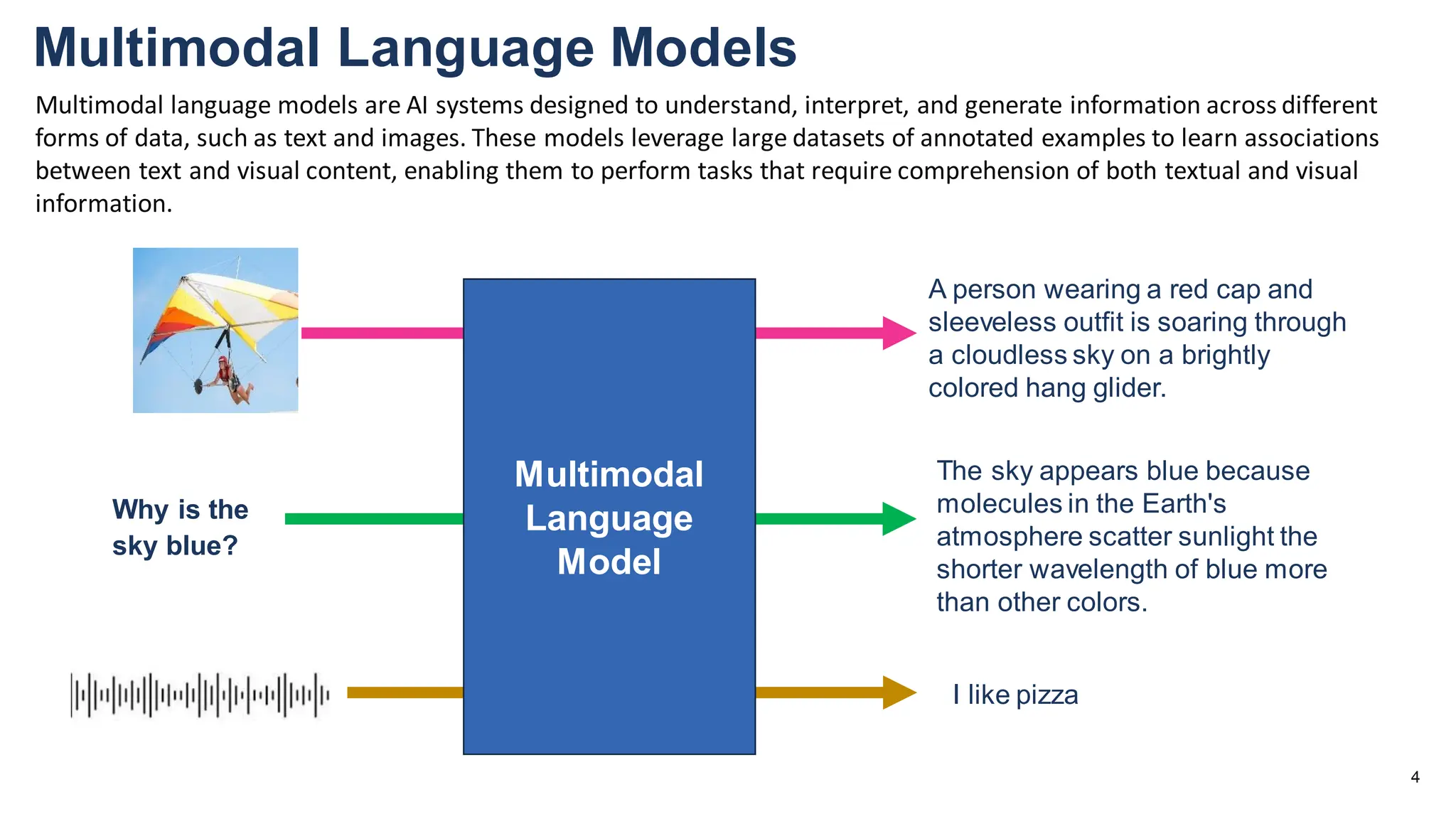
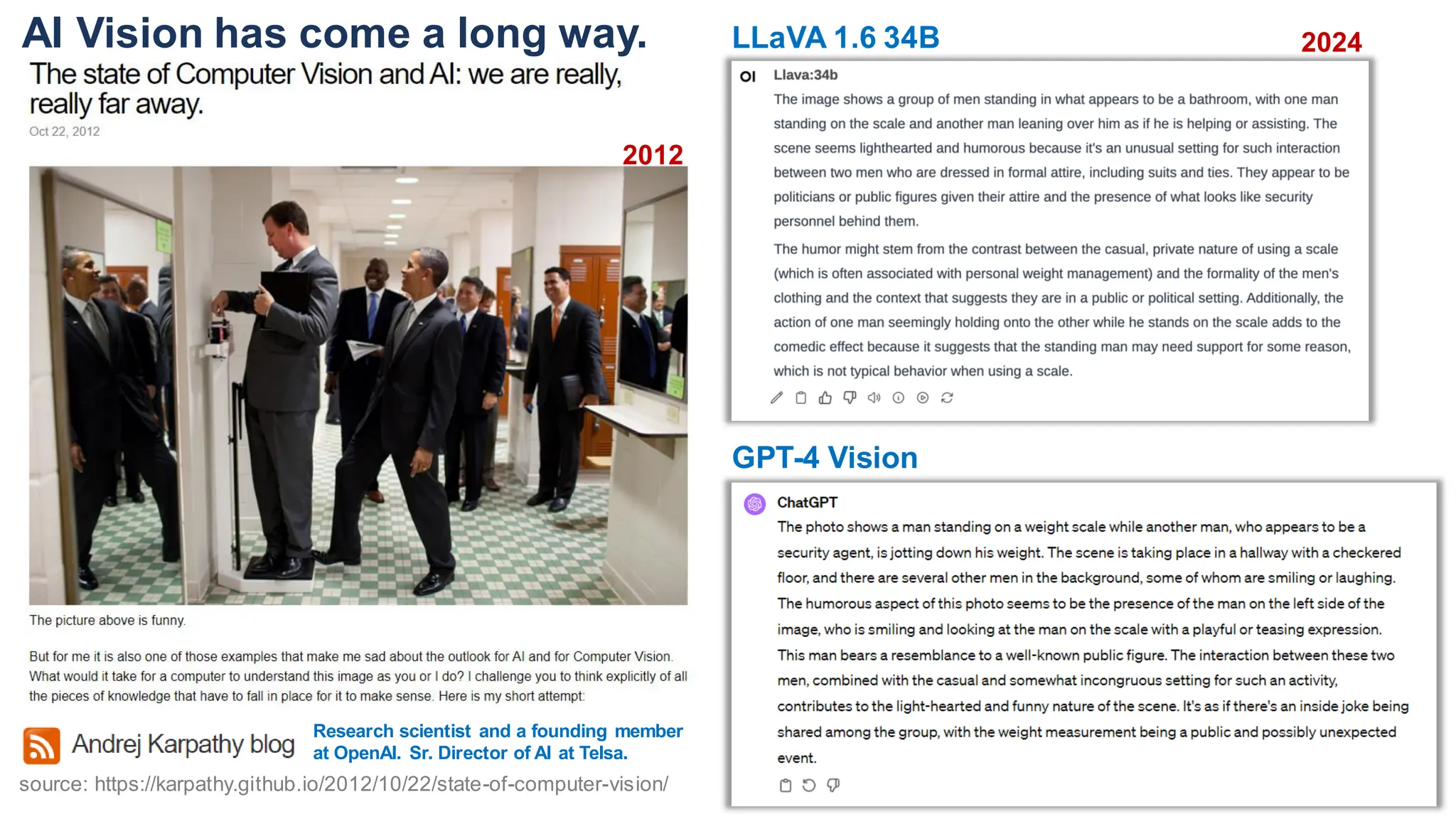
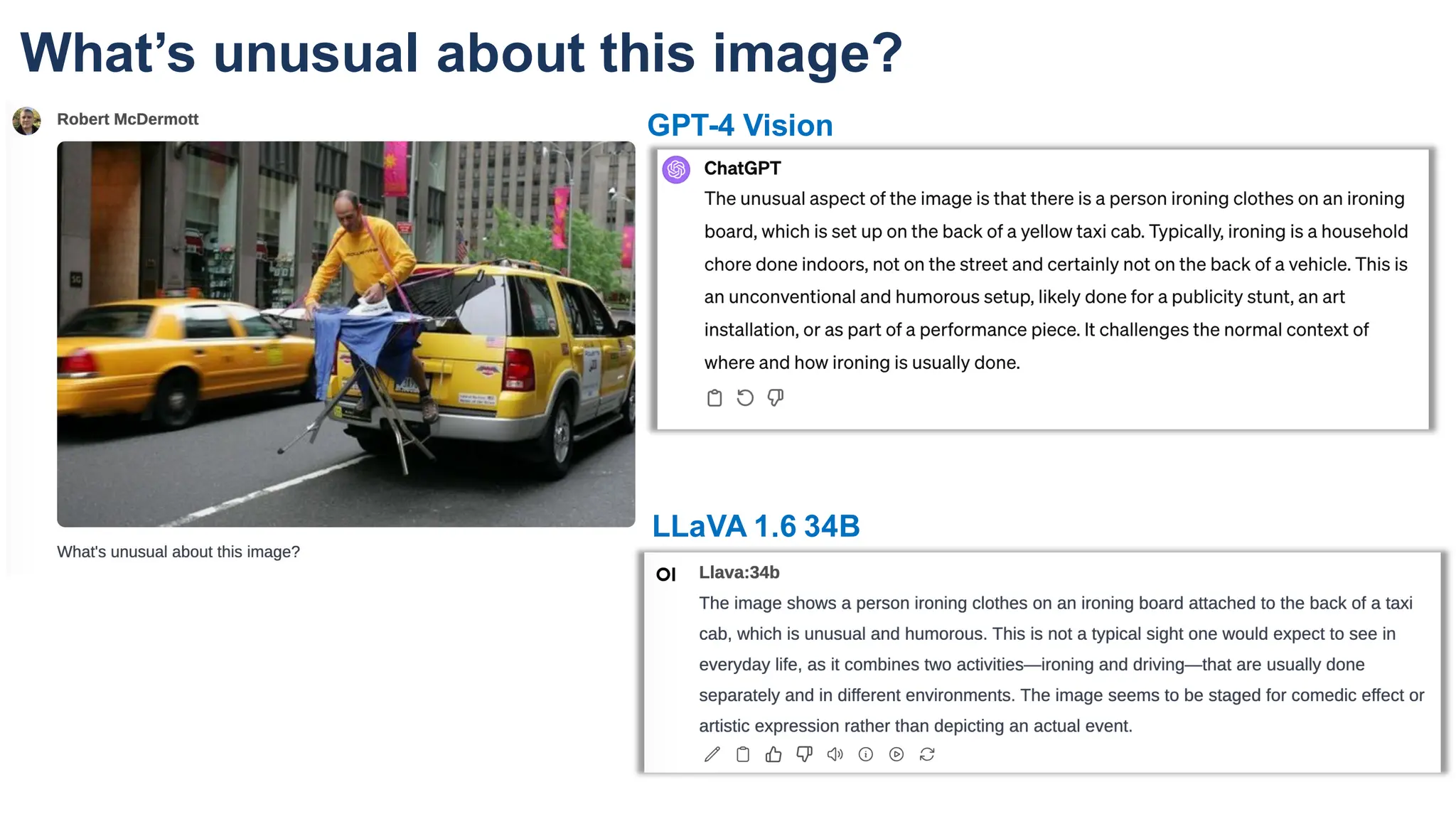
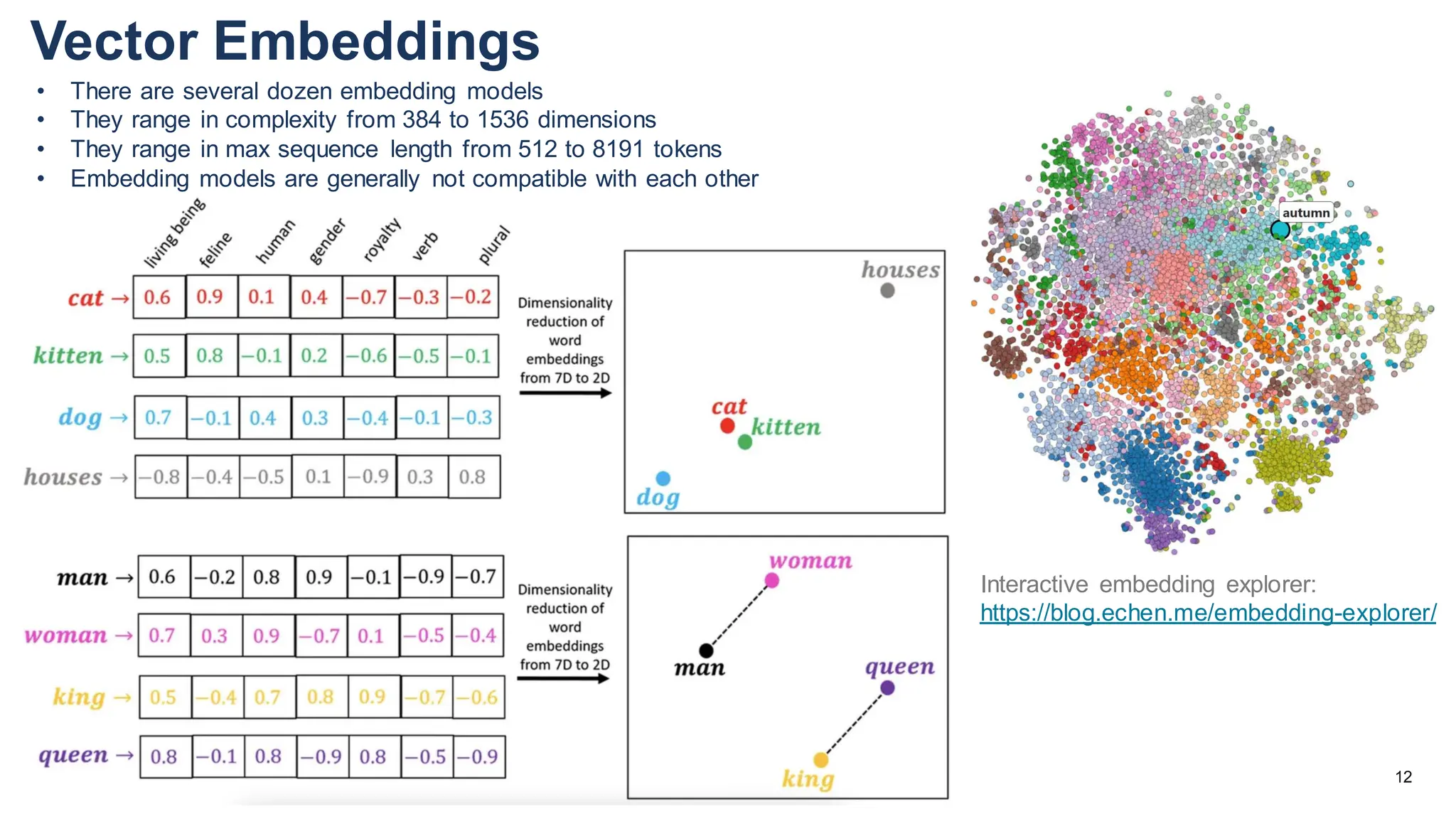
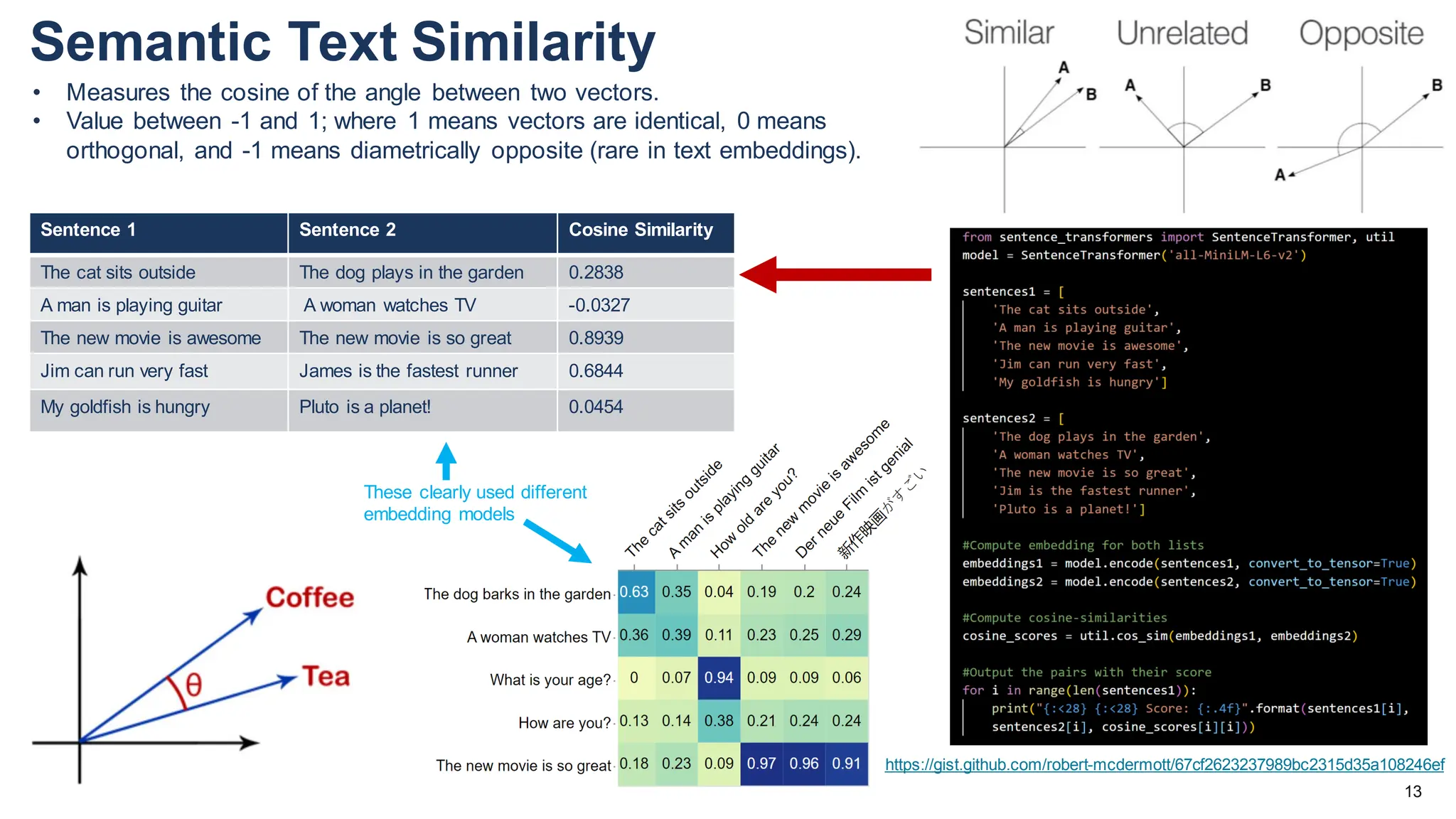
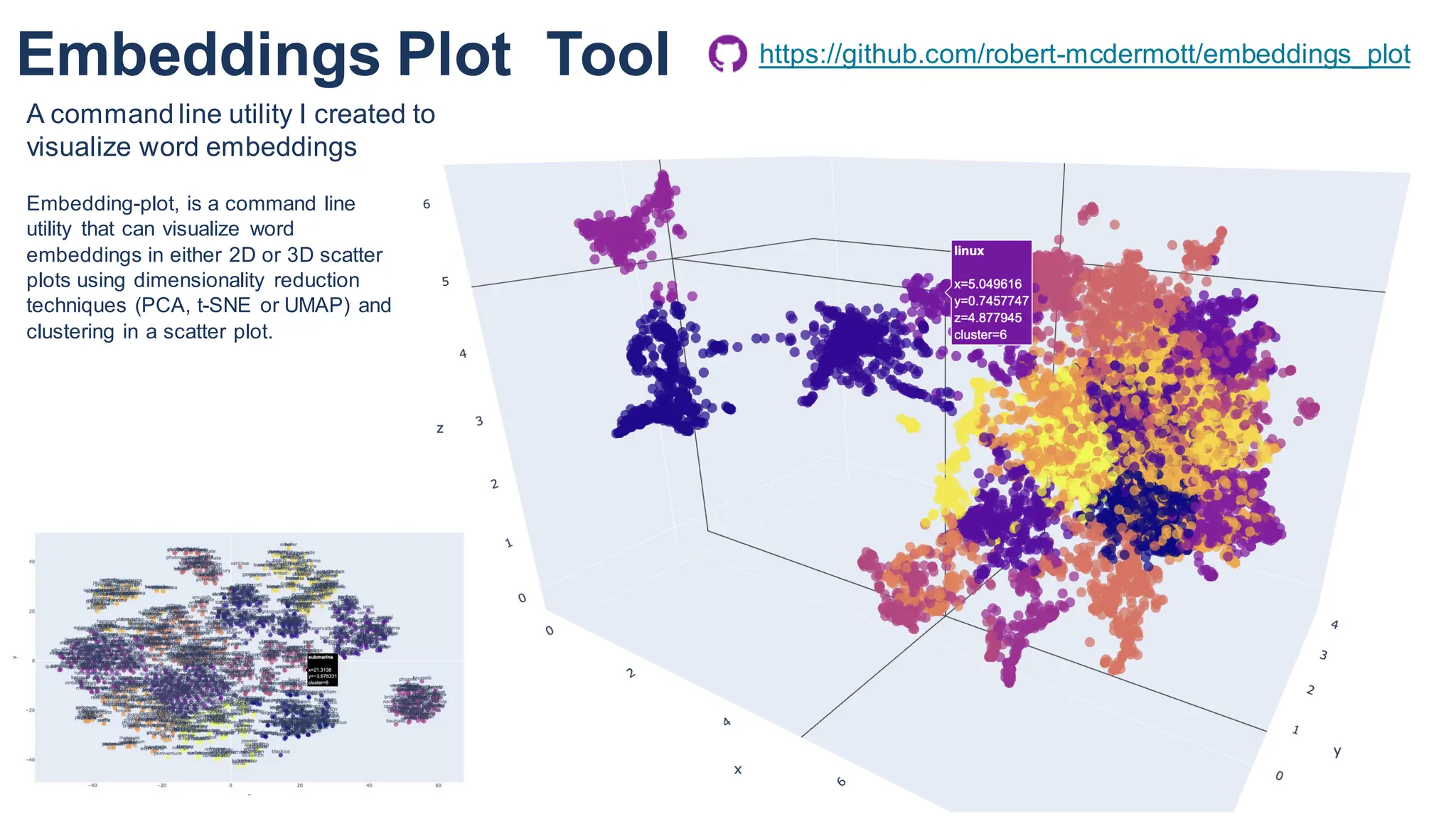
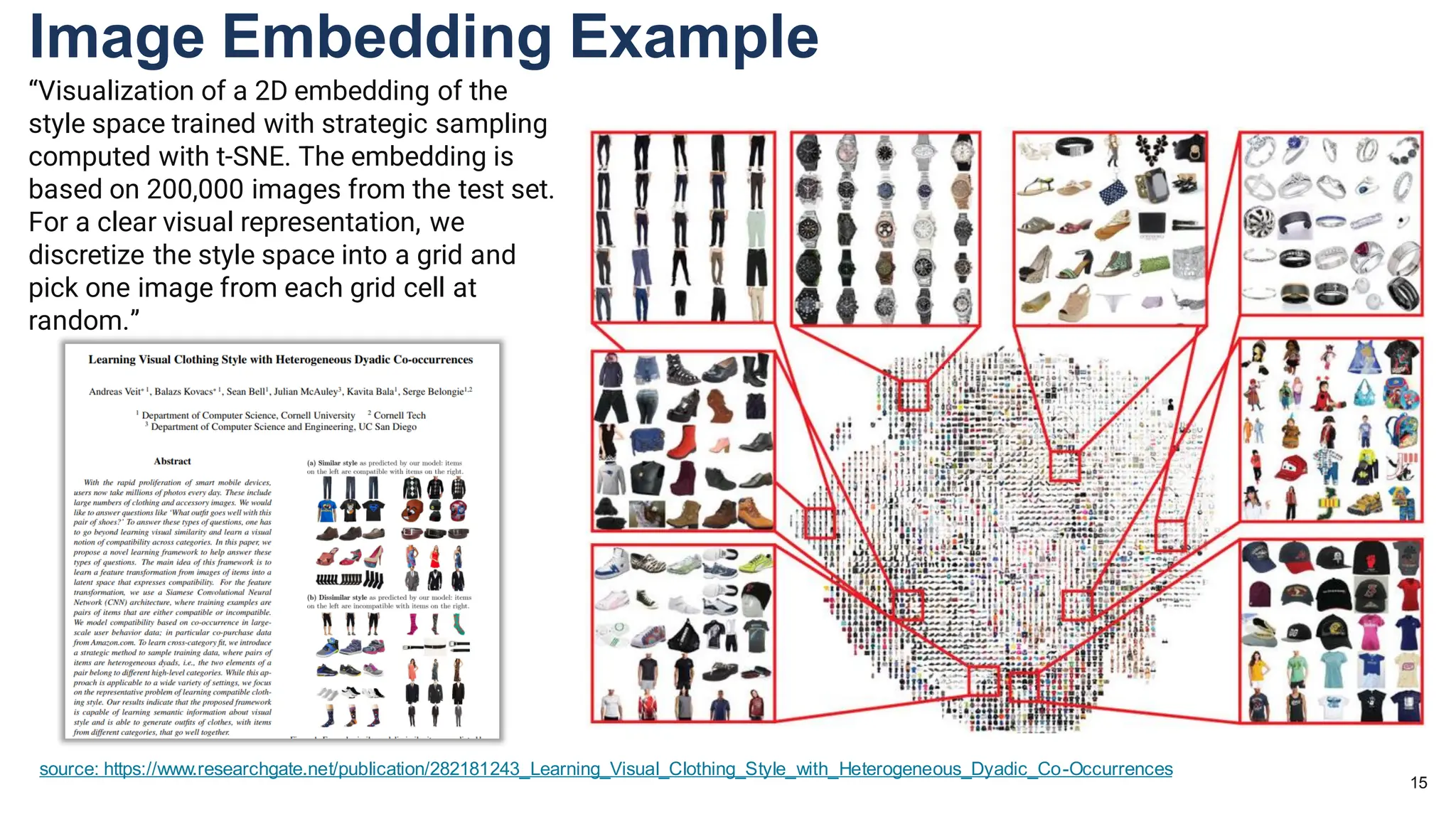
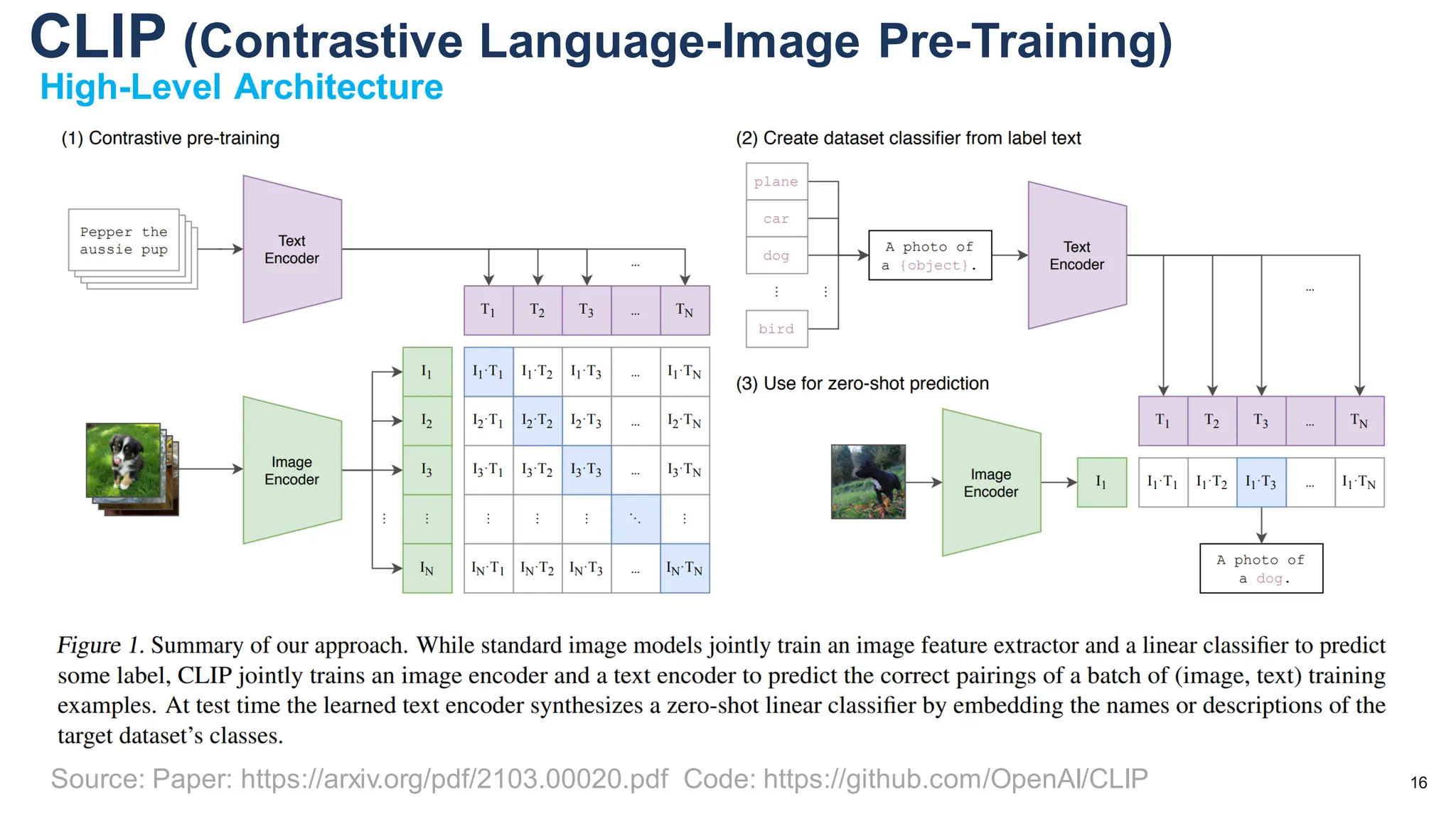
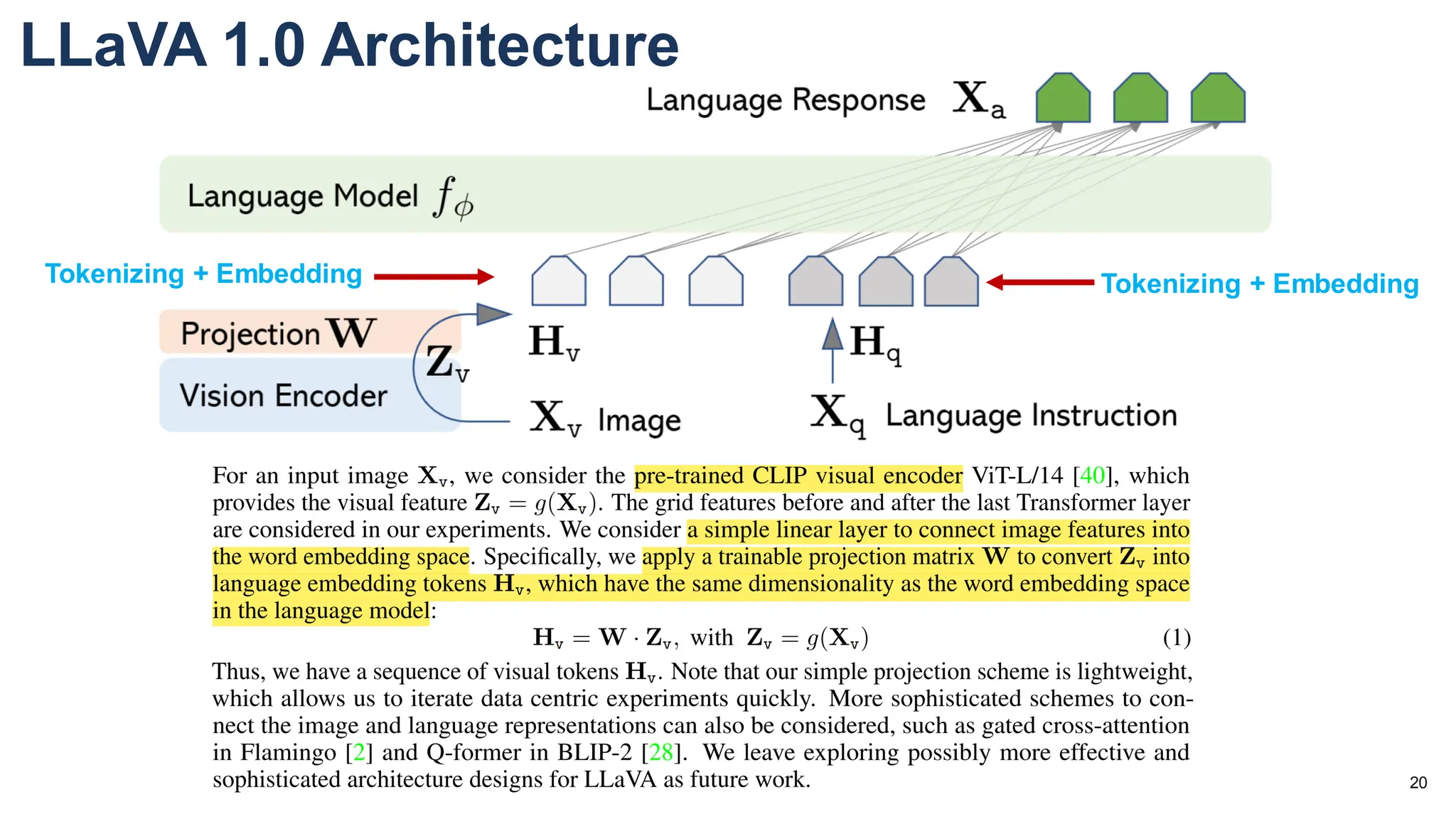
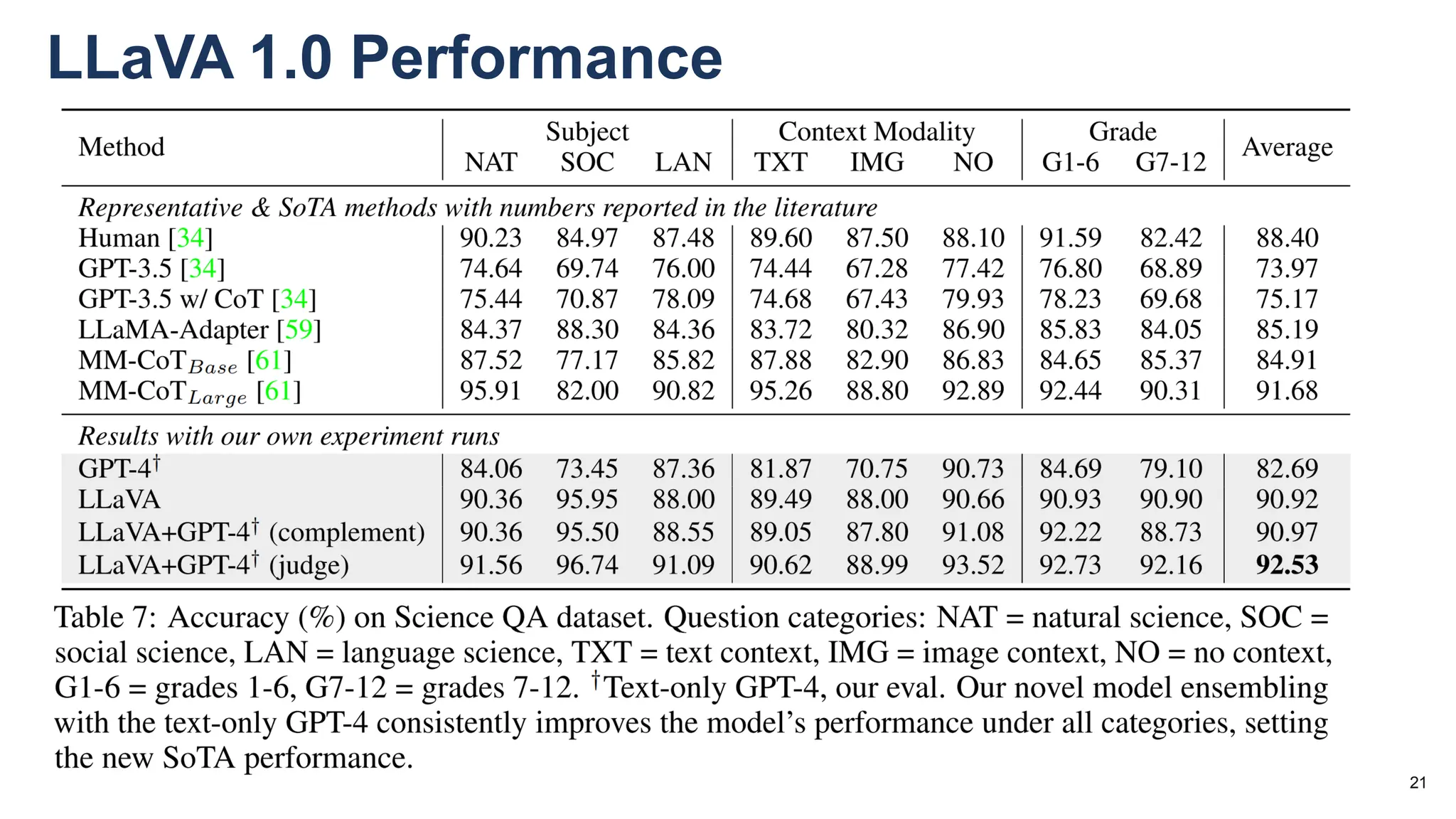
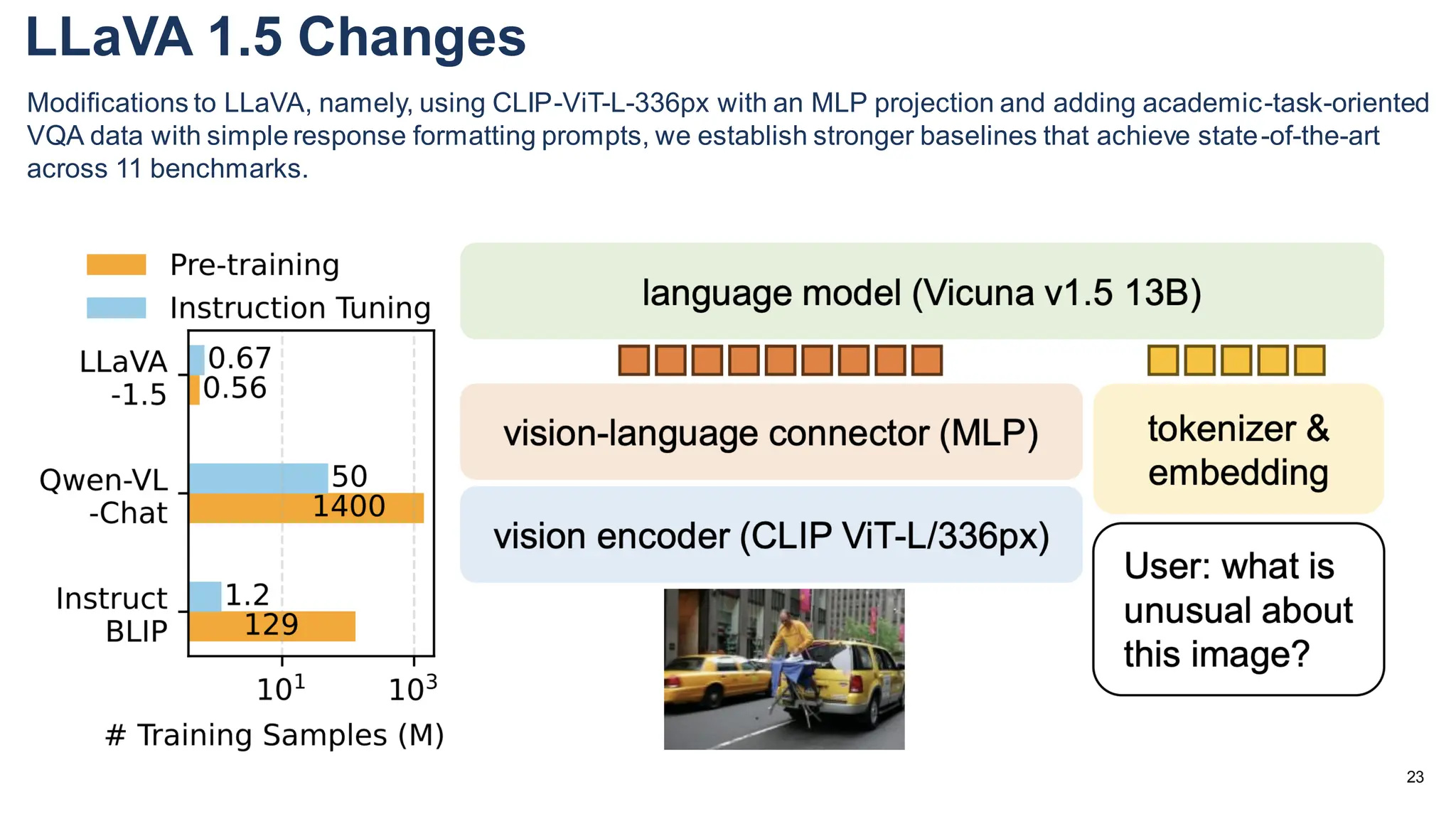
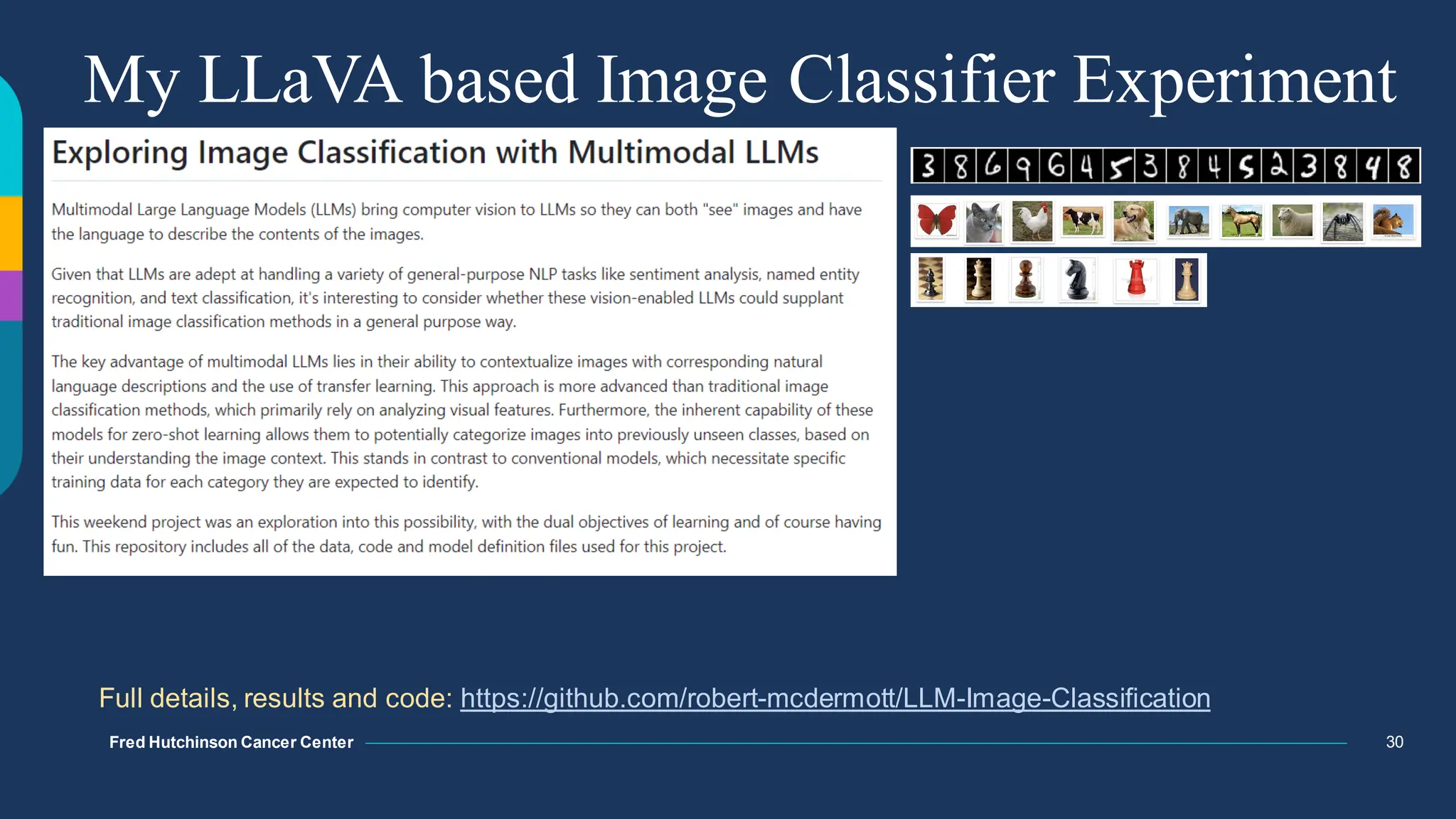
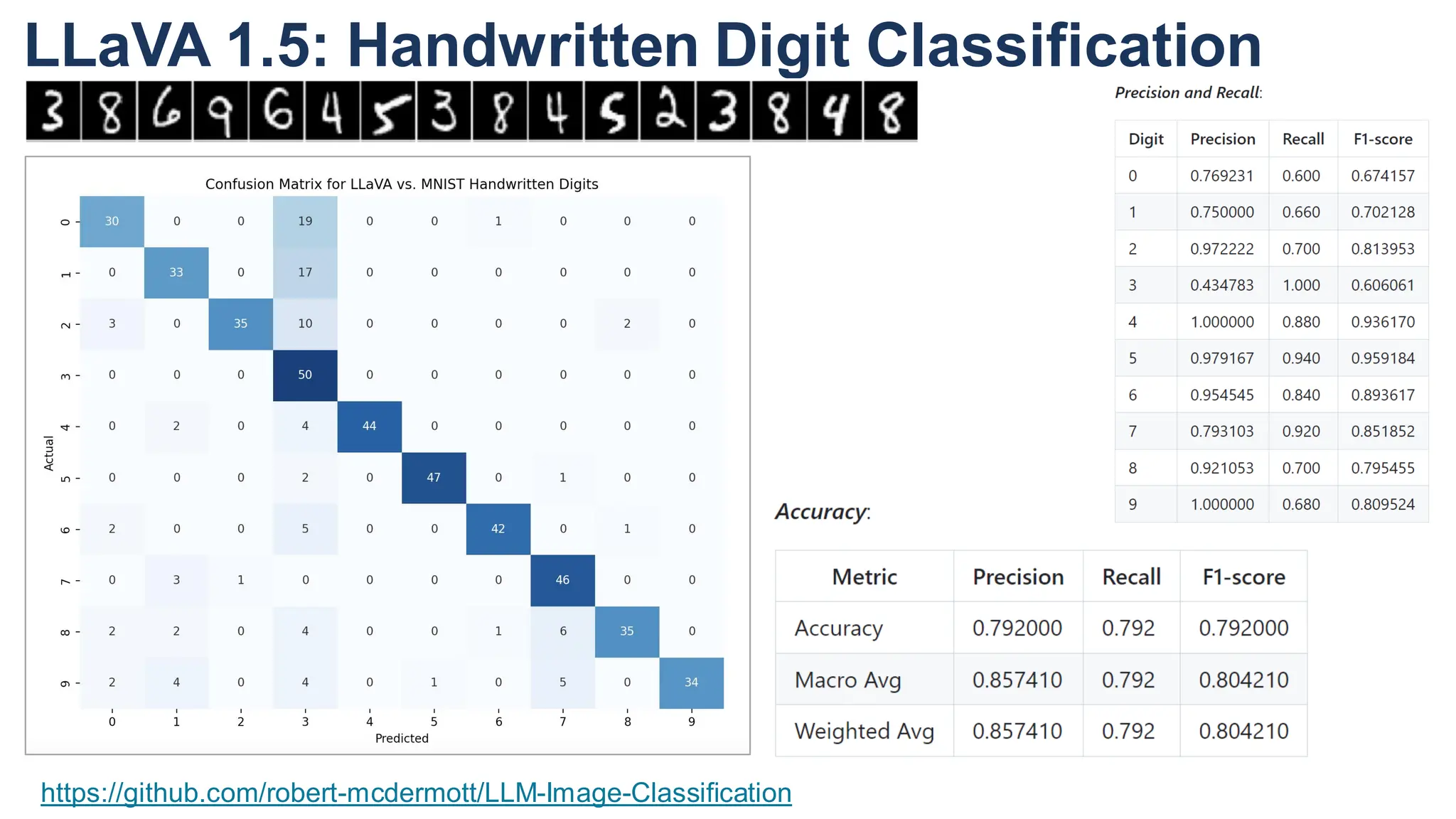
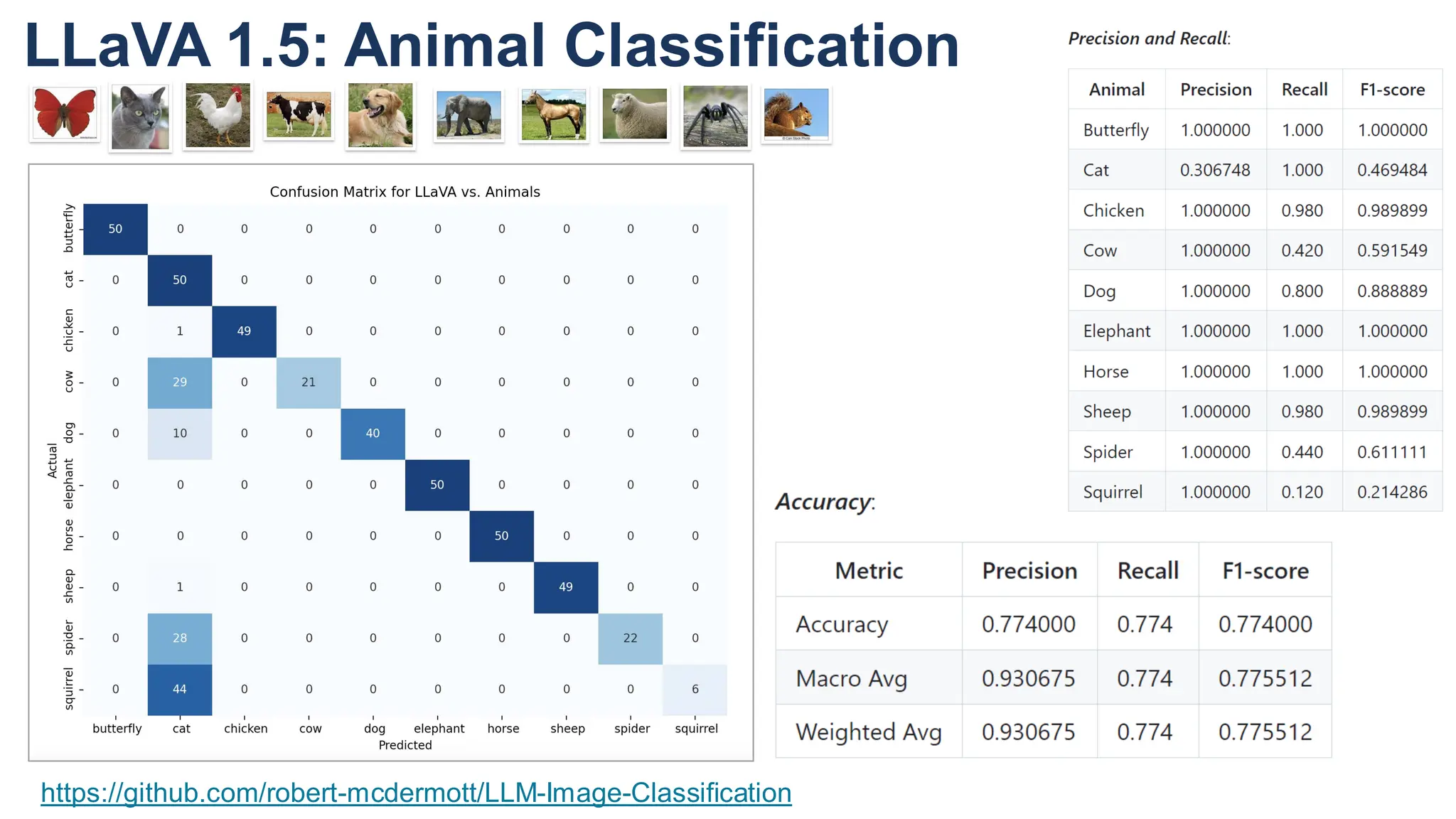
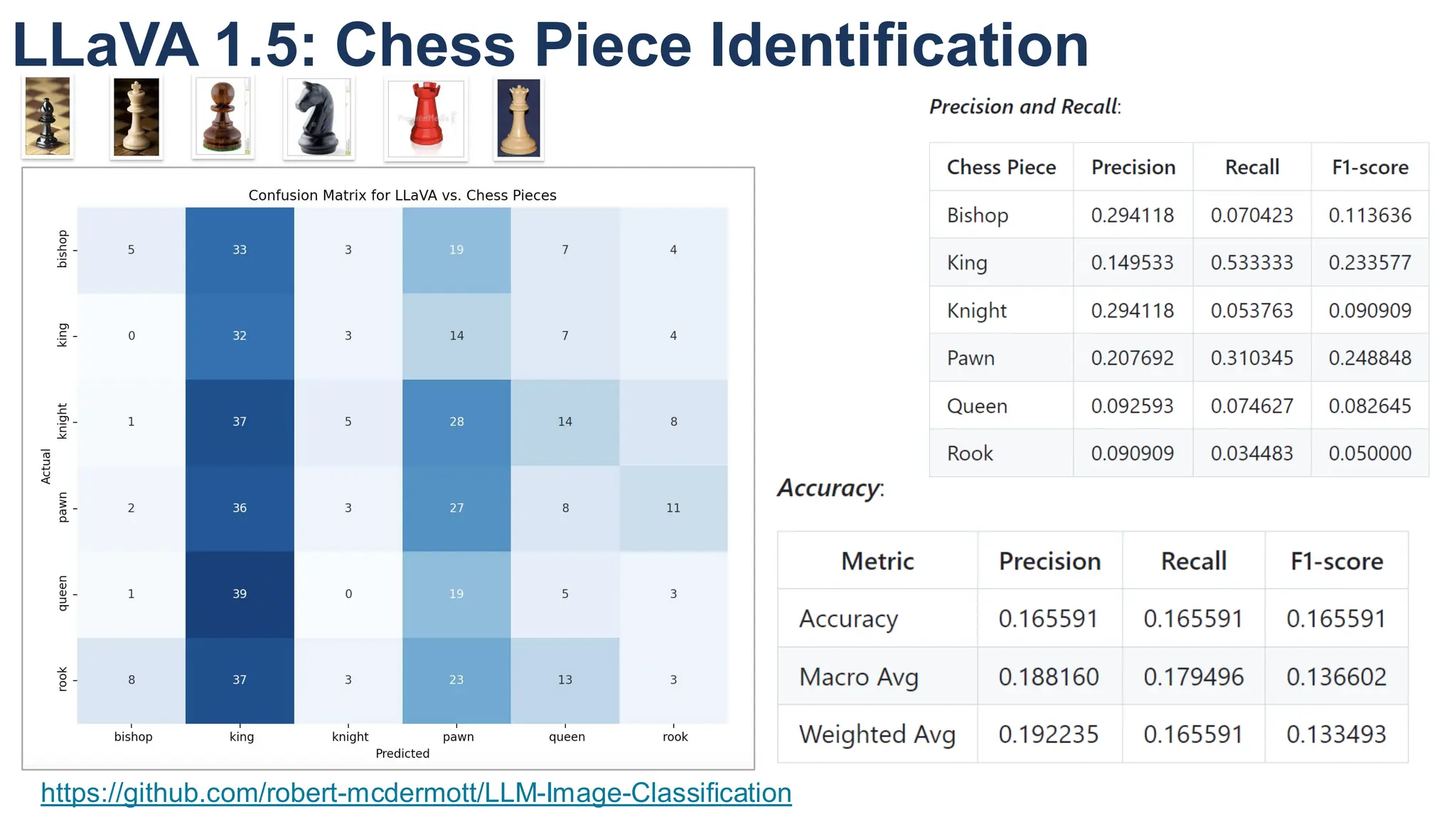
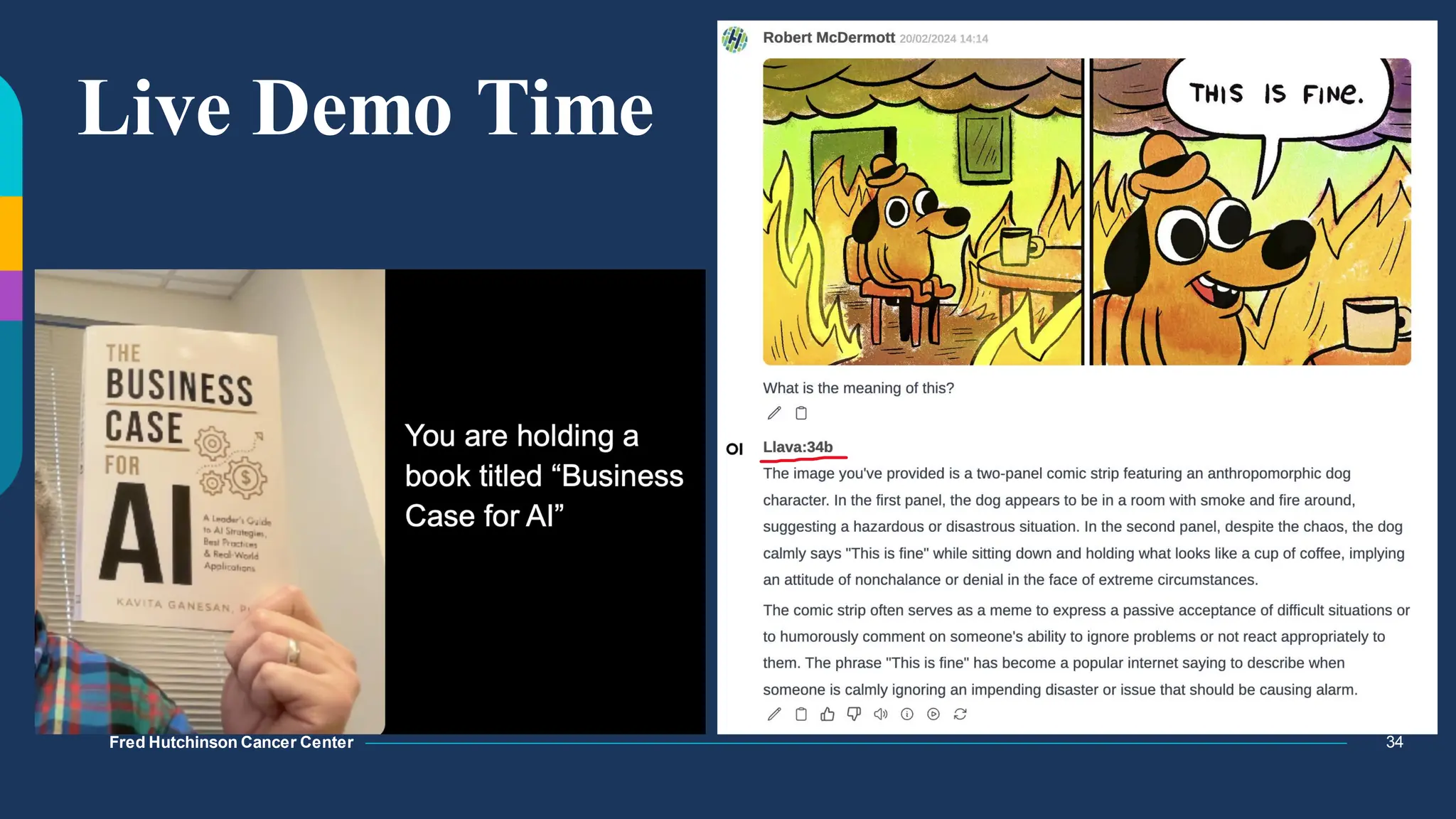
The document discusses multimodal language models, particularly highlighting the development and capabilities of the llava model series, which integrates vision and language understanding. It outlines the methodology, experiments, and improvements in performance metrics, emphasizing the transition from llava 1.0 to llava 1.6 and the formation of llava-med for biomedical applications. The text aims to provide foundational knowledge on tokens, embeddings, and their applications in various domains, as well as links to supporting literature and resources.