Download to read offline









![11
SAMPLE DATA SCHEMA
scala> f
res9: org.apache.spark.sql.Dataset[Flight] =
[year: int, month: int ... 3 more fields]
scala> f.printSchema
root
|-- year: integer (nullable = true)
|-- month: integer (nullable = true)
|-- domestic_flights: long (nullable = true)
|-- international_flights: long (nullable = true)
|-- total_flights: long (nullable = true)
scala> p
res11: org.apache.spark.sql.Dataset[Passenger] =
[year: int, month: int ... 3 more fields]
scala> p.printSchema
root
|-- year: integer (nullable = true)
|-- month: integer (nullable = true)
|-- domestic_passengers: long (nullable = true)
|-- international_passengers: long (nullable = true)
|-- total_passengers: long (nullable = true)](https://image.slidesharecdn.com/apache-big-data-2017-scala-sql-170609140130/85/Apache-big-data-2017-scala-sql-11-320.jpg)










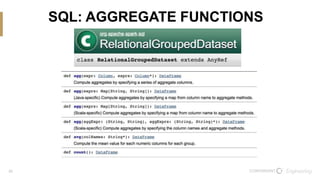


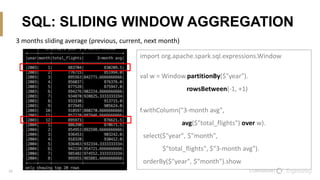
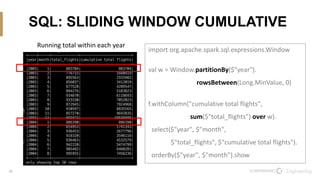



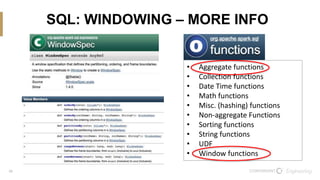






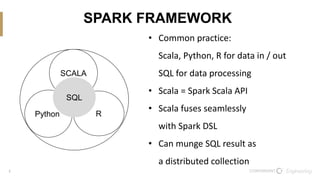
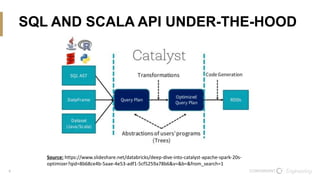
The document discusses the integration of Scala and SQL within the Spark framework, highlighting key similarities and differences. It aims to demonstrate the versatility of the Scala API in data processing compared to traditional SQL methods, featuring various examples such as data schema definitions, selection clauses, joins, aggregation functions, and window functions. The content is intended to improve comfort levels in using the Scala API for data manipulation and analysis.






















































