











![Athens Big Data - Meetup - 2016
THANK YOU :-)
[ Updates / Questions / Comments ]
@qiozas
@christoupat](https://image.slidesharecdn.com/4thathensbigdatameetup-1sttalk-181127115108/75/4th-Athens-Big-Data-Meetup-1st-Talk-Big-Data-Streaming-Processing-Using-Apache-Storm-29-2048.jpg)

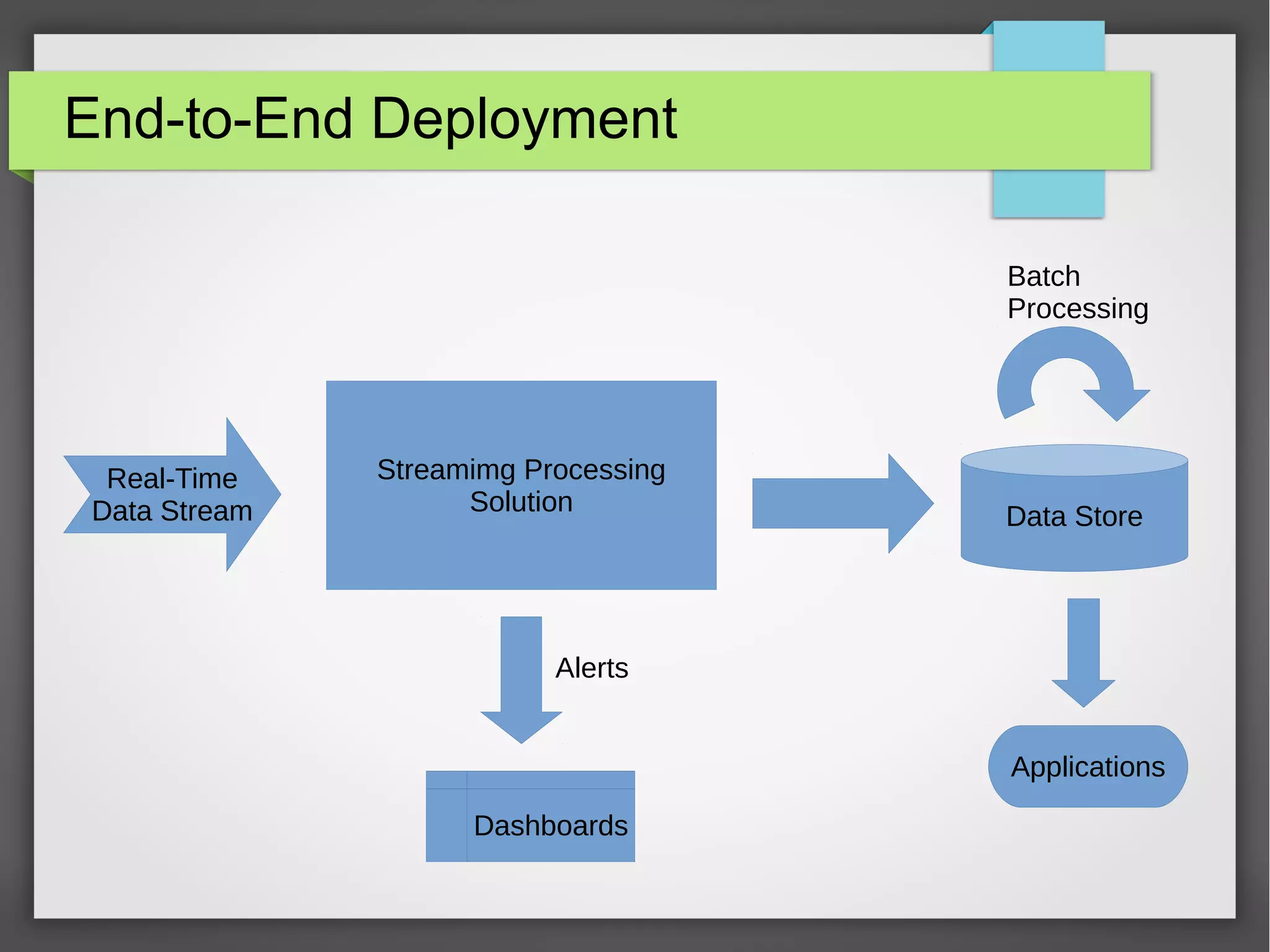
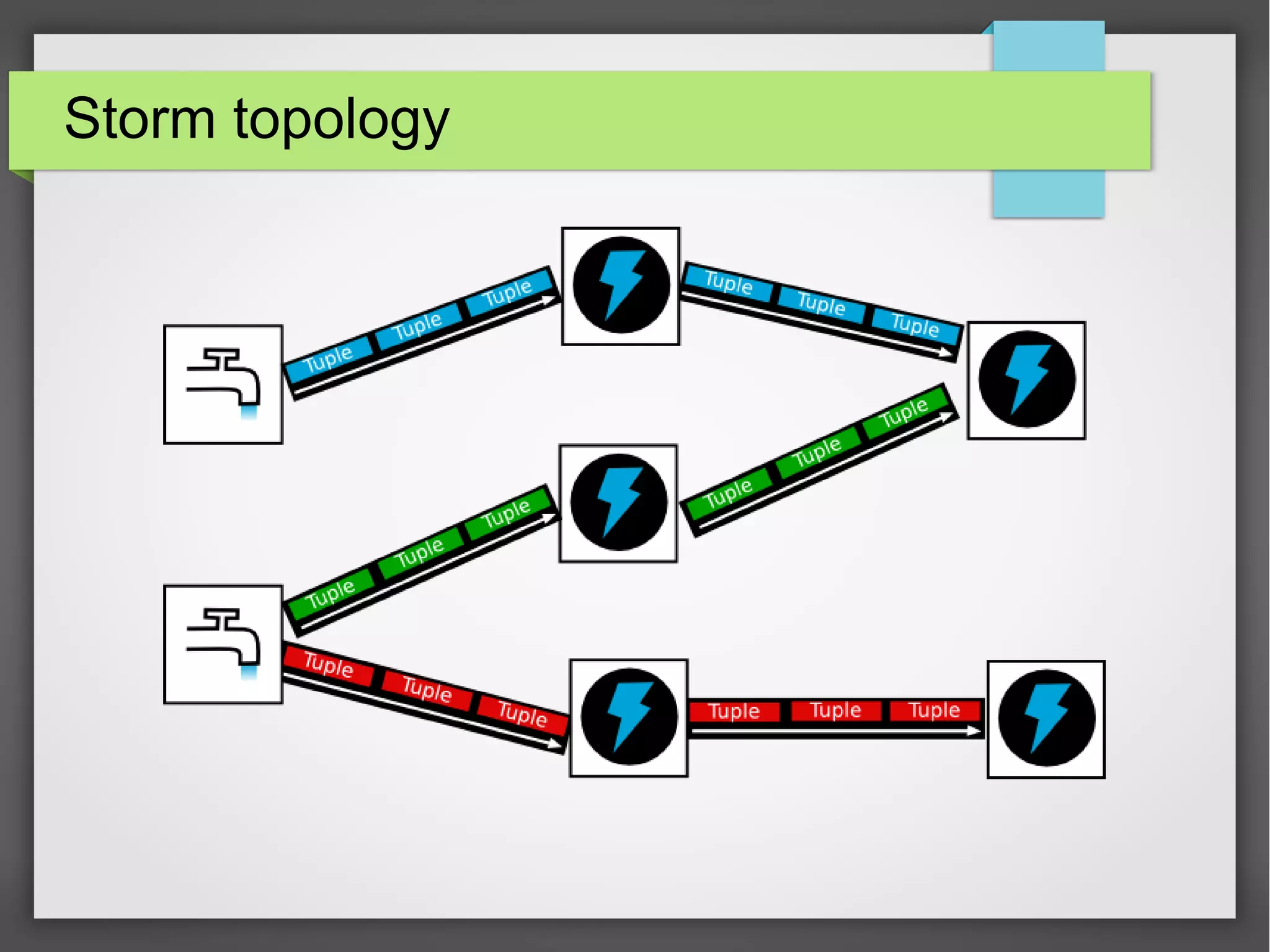
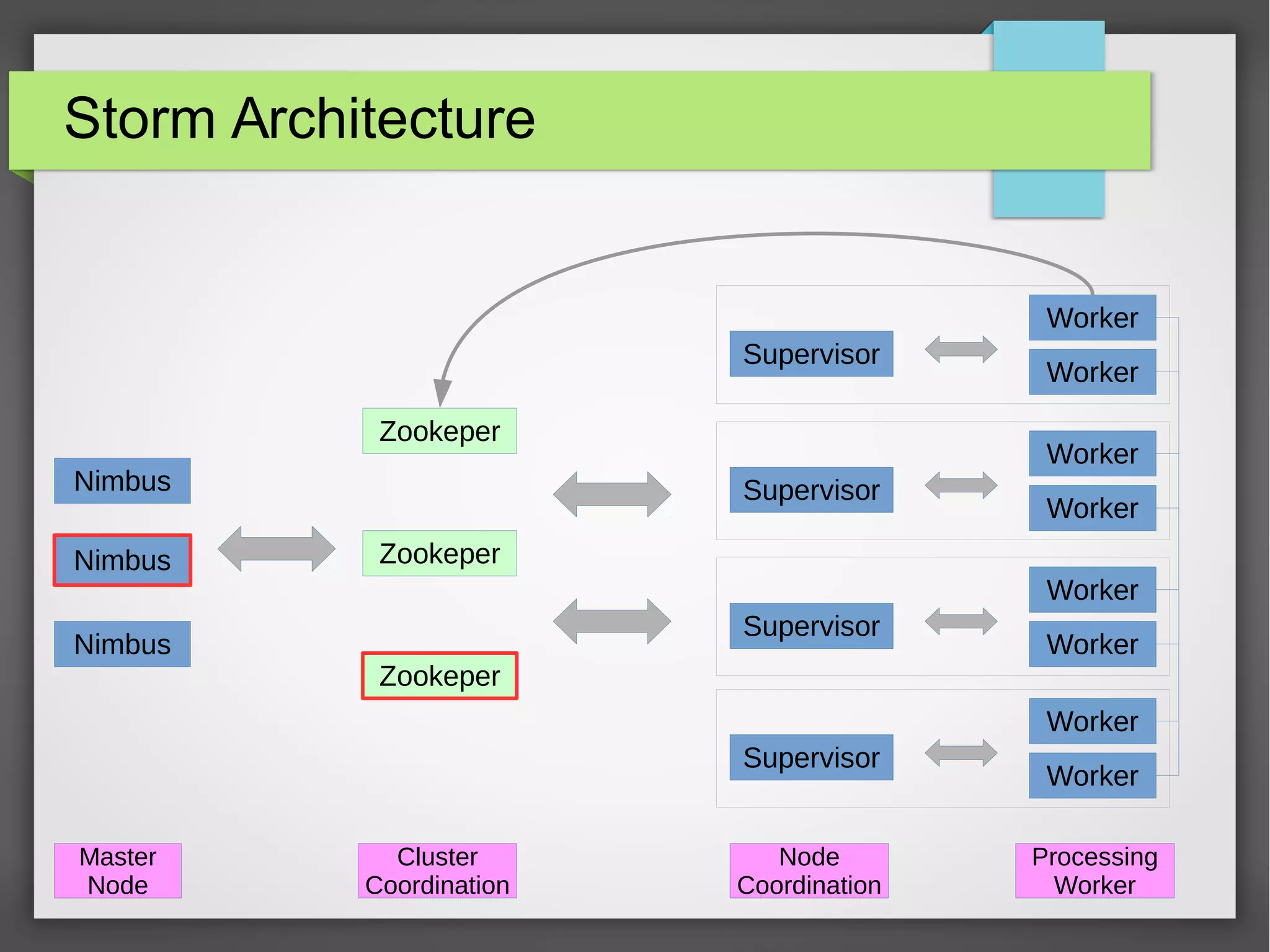
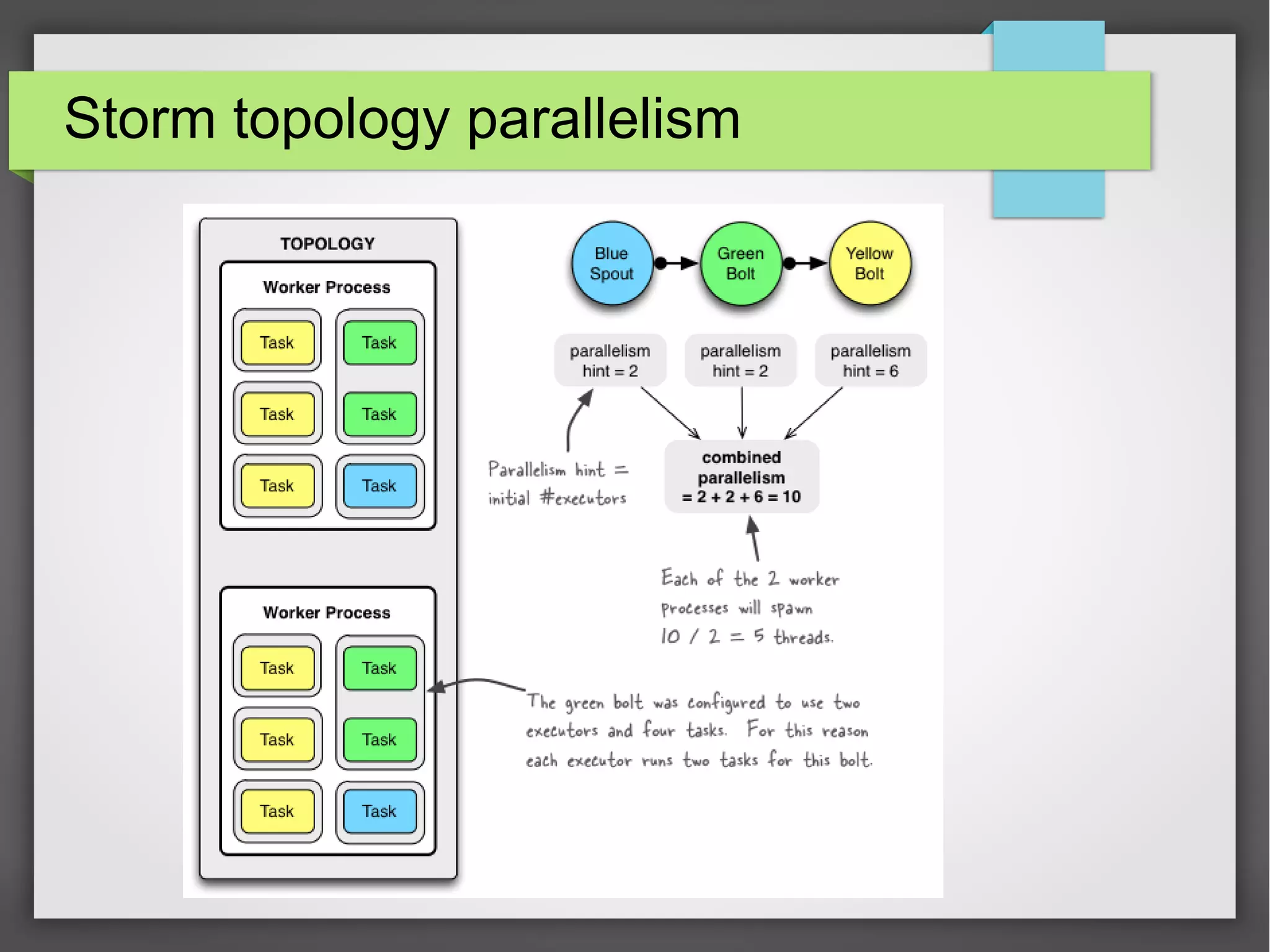
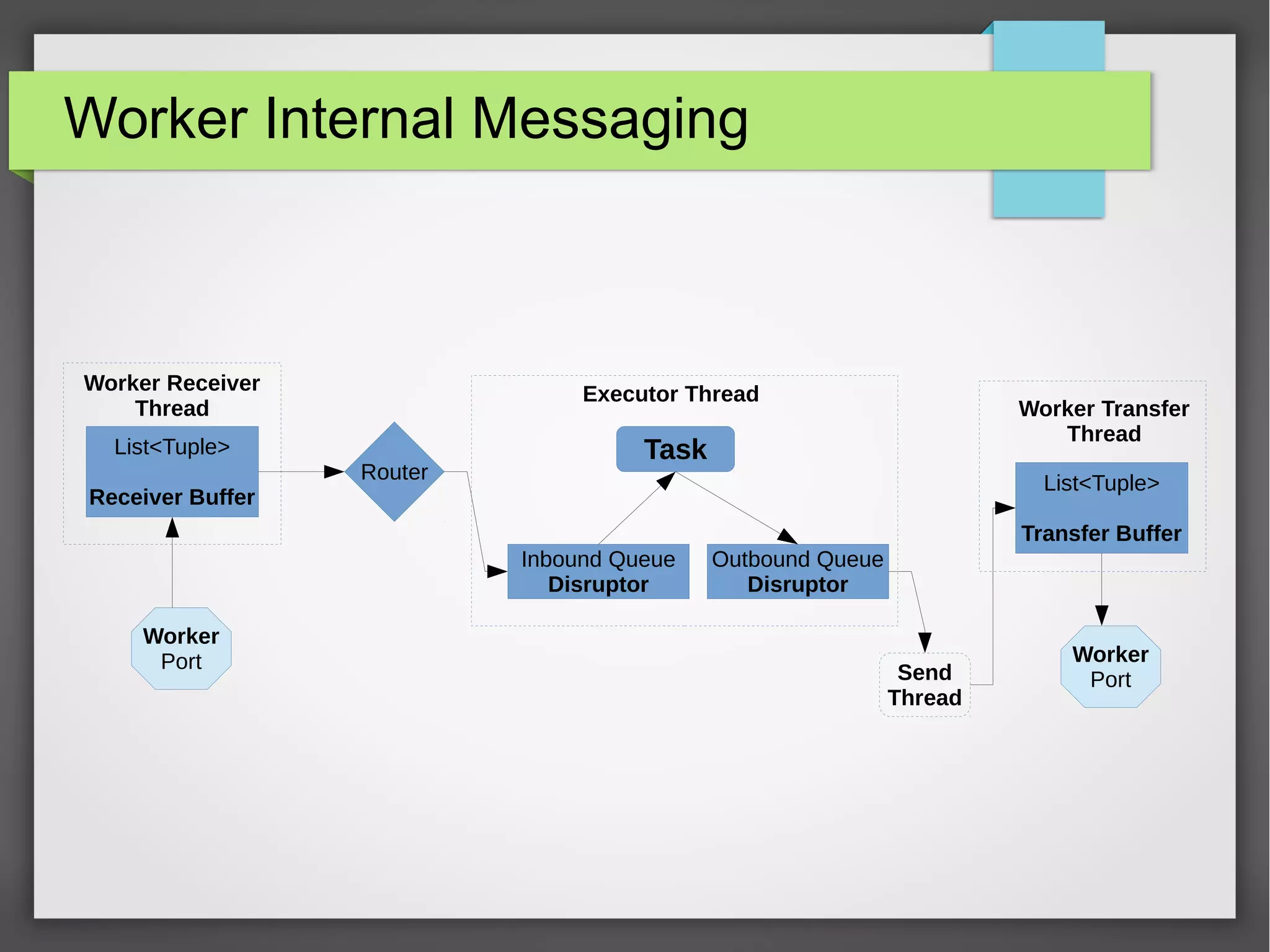
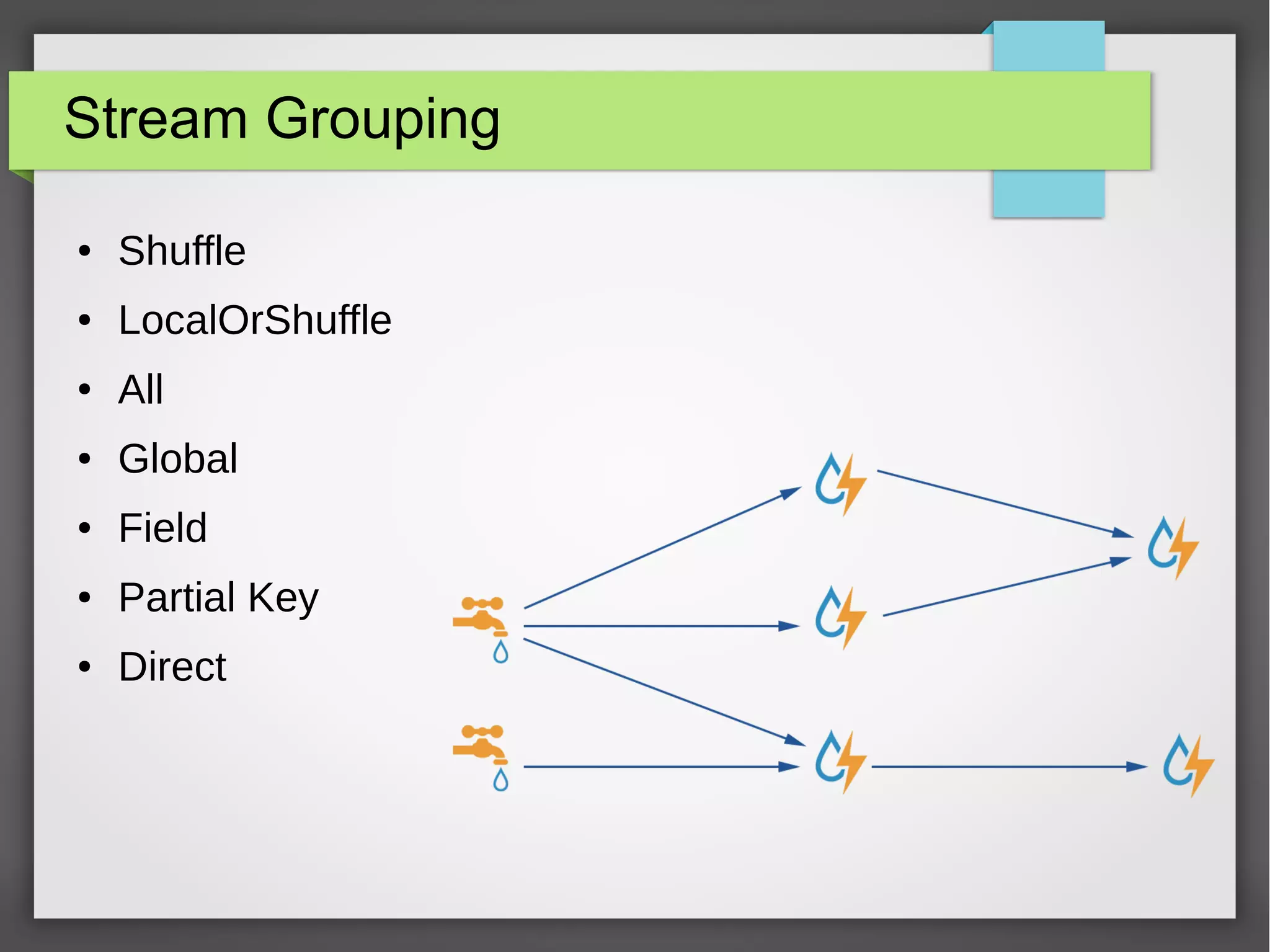
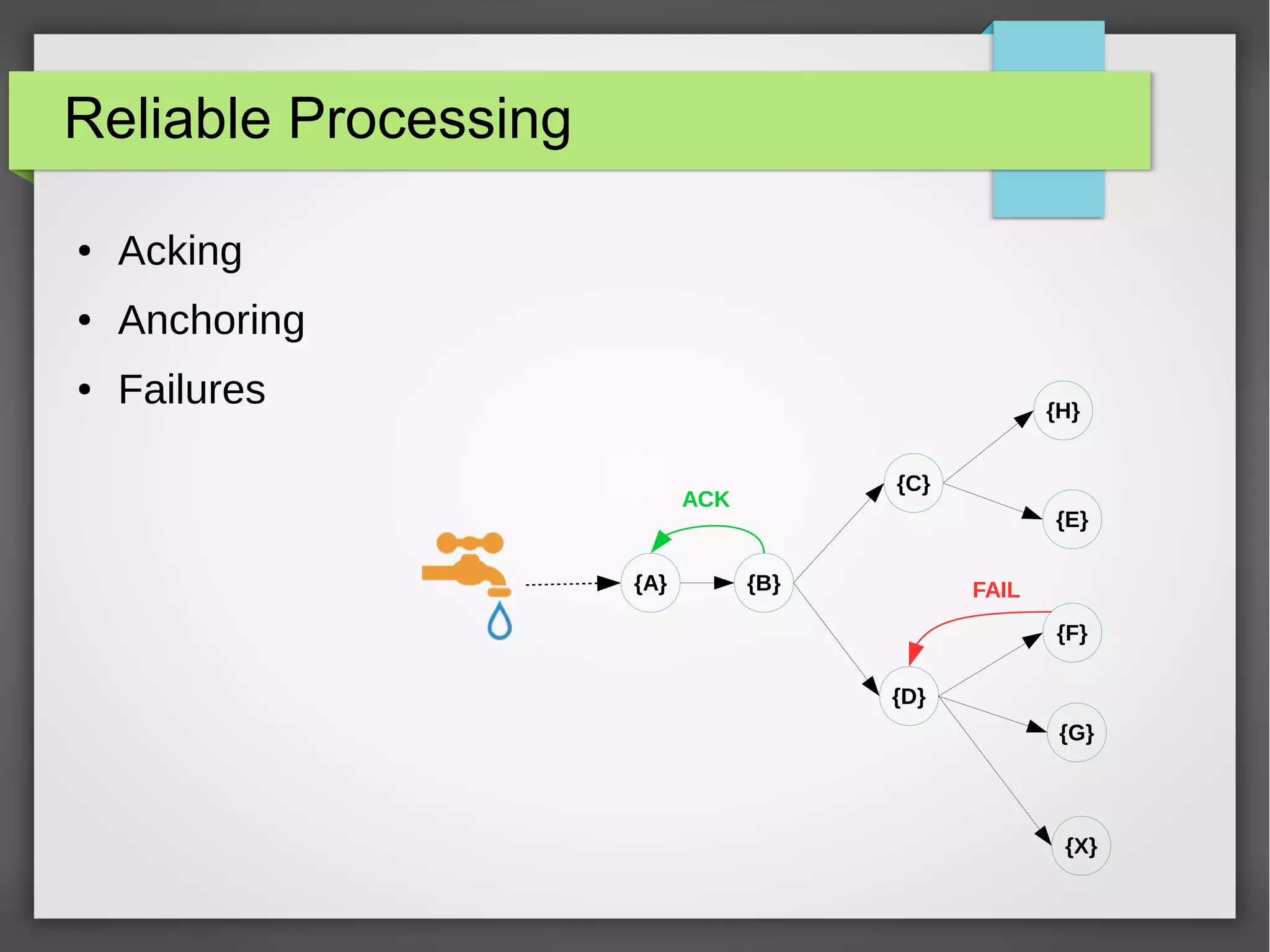
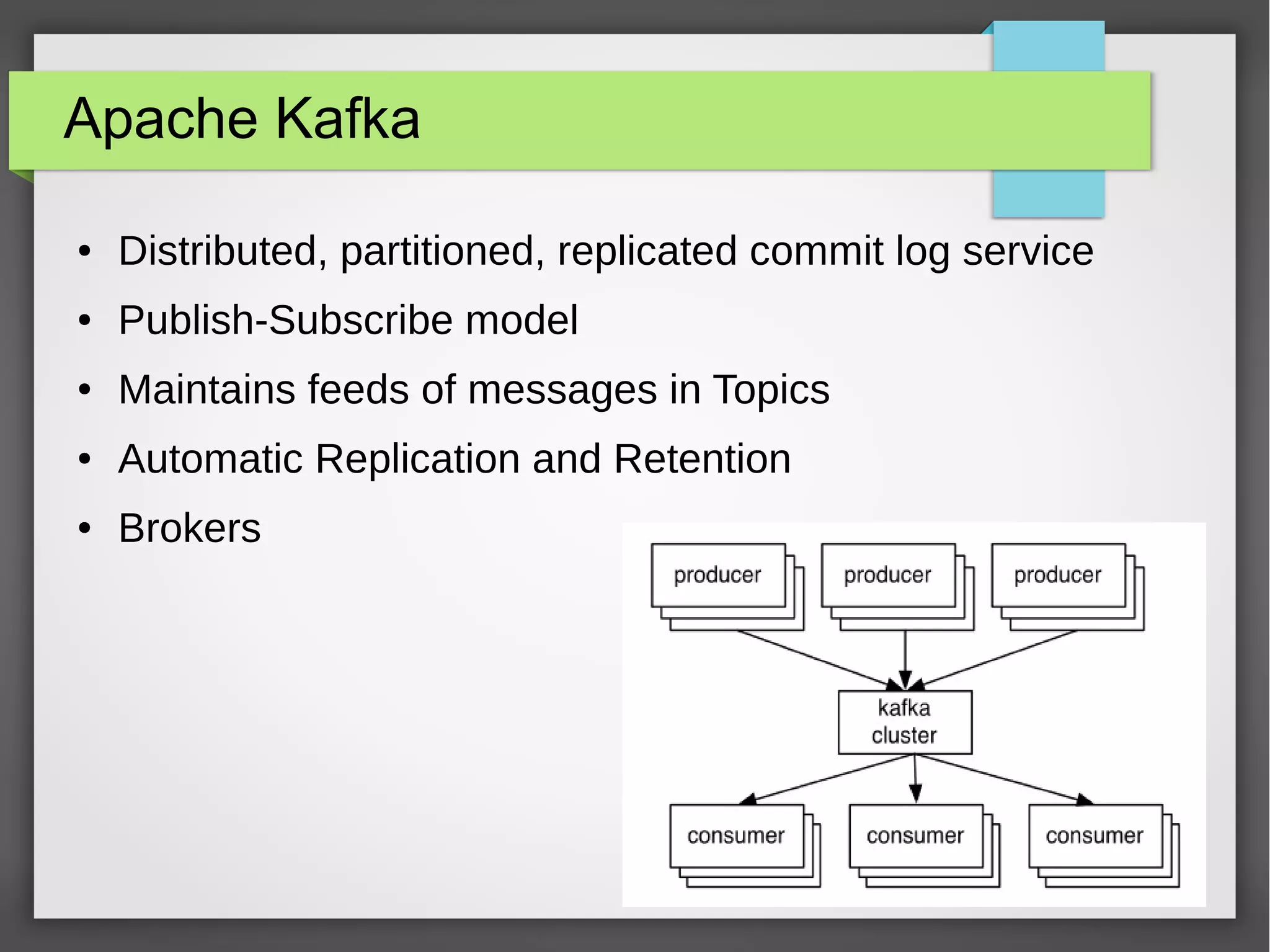
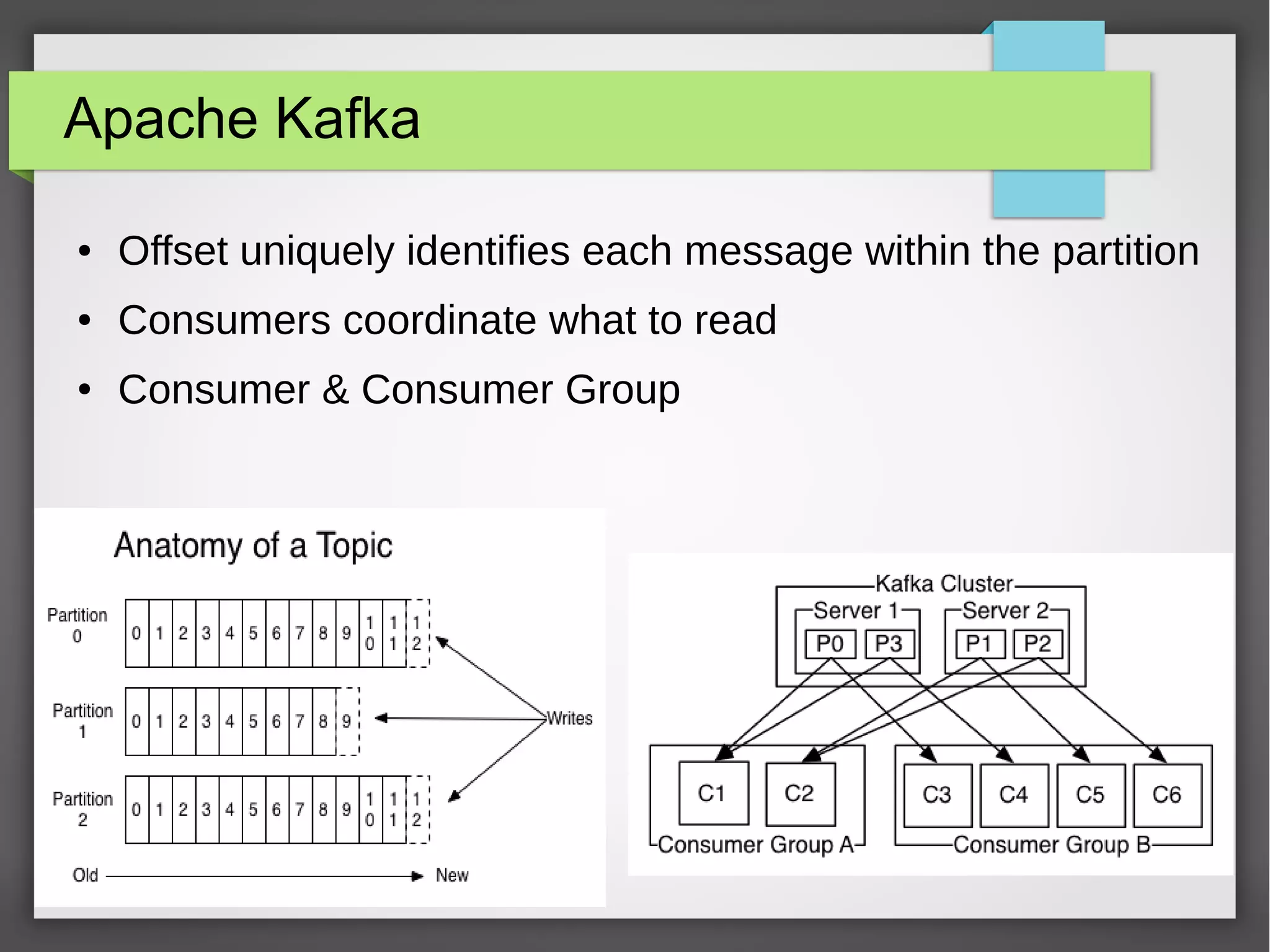
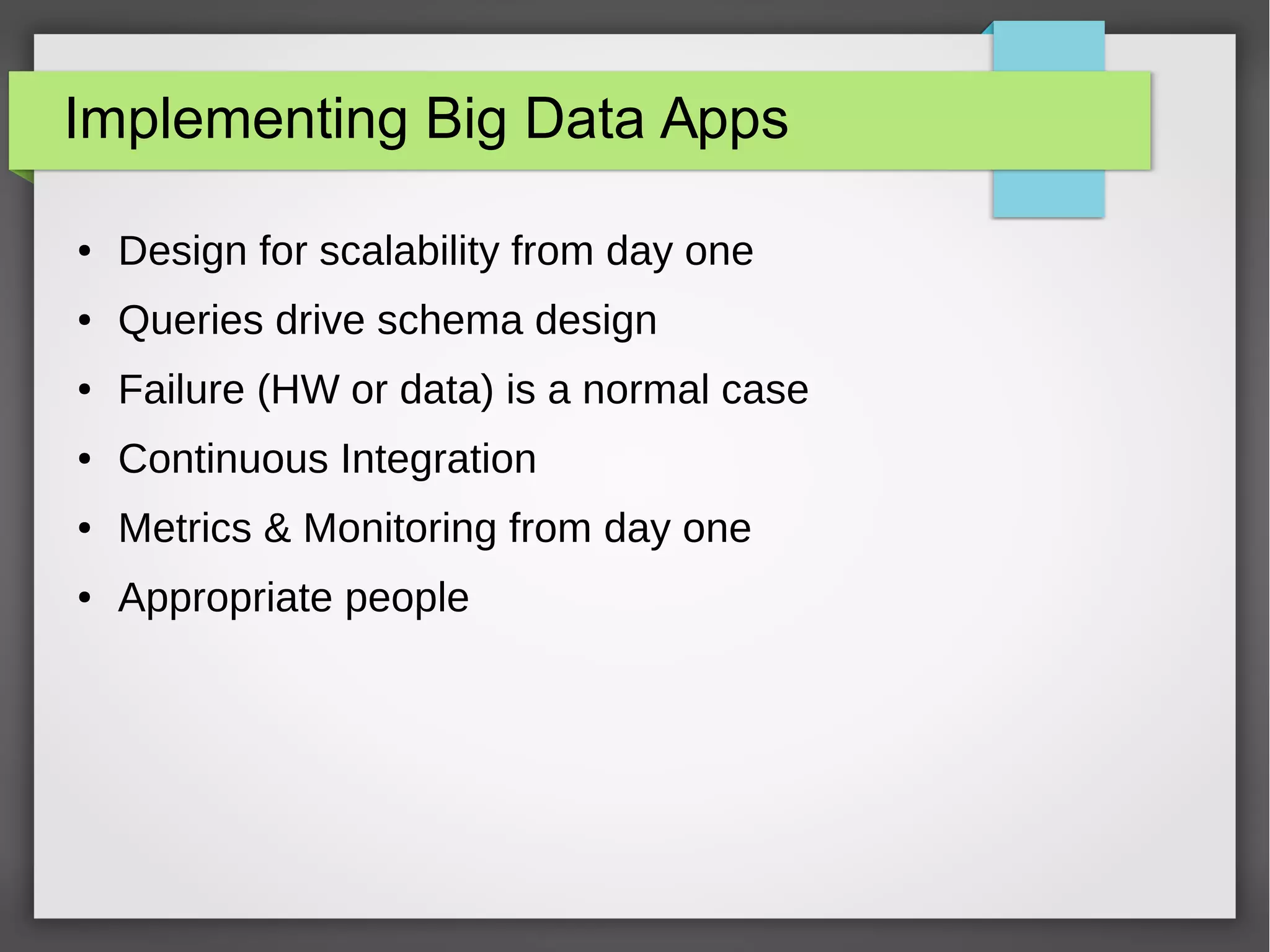
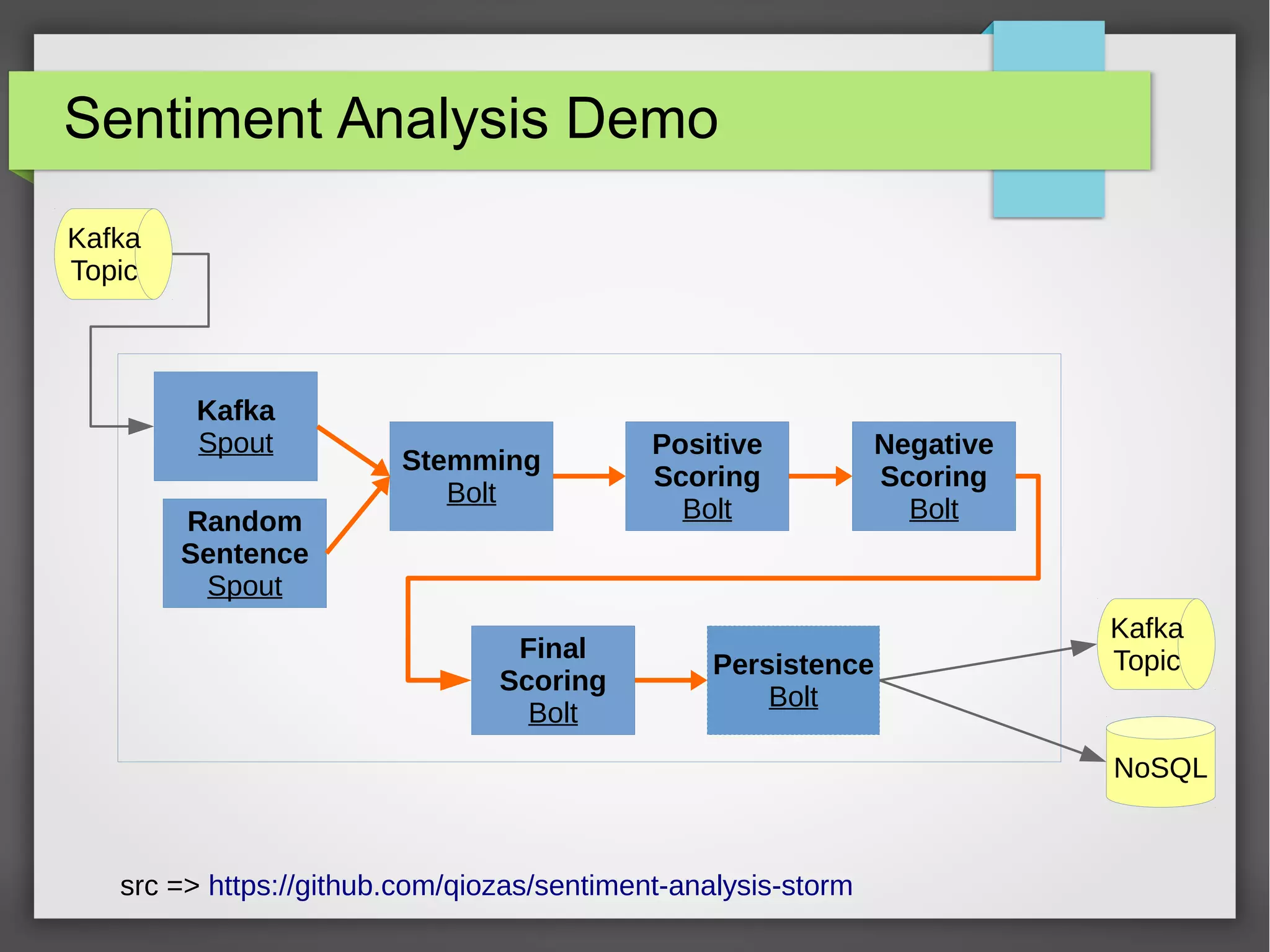
The document outlines a meetup presentation on big data stream processing using Apache Storm, focusing on its architecture, features, and real-time data use cases such as fraud detection and network monitoring. It discusses the core concepts of Storm, including the role of spouts and bolts, as well as integrations with systems like Apache Kafka. Additionally, it emphasizes the importance of designing big data applications for scalability and continuous integration.






![[Virtual Meetup] Using Elasticsearch as a Time-Series Database in the Endpoin...](https://cdn.slidesharecdn.com/ss_thumbnails/2020-200909133305-thumbnail.jpg?width=640&height=640&fit=bounds)














































































