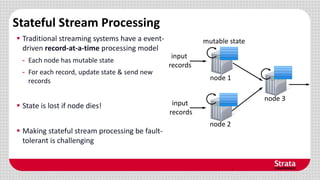
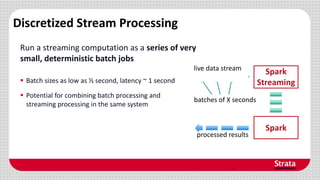
Spark Streaming is a framework for processing live data streams at large scale. It allows building streaming applications that are scalable, fault-tolerant, and can achieve low latencies of 1 second. The framework discretizes streams into batches and processes them using Spark's batch engine, providing simple APIs for stream transformations like maps, filters and windowing. This allows integrating streaming with Spark's interactive queries and batch jobs on static data. Spark Streaming has been used by companies to process millions of video sessions in real-time and perform traffic analytics on GPS data streams.













![Example 1 – Get hashtags from Twitter
val tweets = ssc.twitterStream(<Twitter username>, <Twitter password>)
val hashTags = tweets.flatMap (status => getTags(status))
flatMap flatMap flatMap
…
transformation: modify data in one Dstream to create another DStream
new DStream
new RDDs created for
every batch
batch @ t+1
batch @ t batch @ t+2
tweets DStream
hashTags Dstream
[#cat, #dog, … ]](https://image.slidesharecdn.com/stratasparkstreaming-230302122008-555d307a/85/strata_spark_streaming-ppt-16-320.jpg)




![Example 2 – Count the hashtags
val tweets = ssc.twitterStream(<Twitter username>, <Twitter password>)
val hashTags = tweets.flatMap (status => getTags(status))
val tagCounts = hashTags.countByValue()
flatMap
map
reduceByKey
flatMap
map
reduceByKey
…
flatMap
map
reduceByKey
batch @ t+1
batch @ t batch @ t+2
hashTags
tweets
tagCounts
[(#cat, 10), (#dog, 25), ... ]](https://image.slidesharecdn.com/stratasparkstreaming-230302122008-555d307a/85/strata_spark_streaming-ppt-21-320.jpg)















![Vision - one stack to rule them all
Explore data interactively using Spark
Shell / PySpark to identify problems
Use same code in Spark stand-alone
programs to identify problems in
production logs
Use similar code in Spark Streaming to
identify problems in live log streams
$ ./spark-shell
scala> val file = sc.hadoopFile(“smallLogs”)
...
scala> val filtered = file.filter(_.contains(“ERROR”))
...
scala> val mapped = file.map(...)
...
object ProcessProductionData {
def main(args: Array[String]) {
val sc = new SparkContext(...)
val file = sc.hadoopFile(“productionLogs”)
val filtered = file.filter(_.contains(“ERROR”))
val mapped = file.map(...)
...
}
}
object ProcessLiveStream {
def main(args: Array[String]) {
val sc = new StreamingContext(...)
val stream = sc.kafkaStream(...)
val filtered = file.filter(_.contains(“ERROR”))
val mapped = file.map(...)
...
}
}](https://image.slidesharecdn.com/stratasparkstreaming-230302122008-555d307a/85/strata_spark_streaming-ppt-37-320.jpg)
![Vision - one stack to rule them all
Explore data interactively using Spark
Shell / PySpark to identify problems
Use same code in Spark stand-alone
programs to identify problems in
production logs
Use similar code in Spark Streaming to
identify problems in live log streams
$ ./spark-shell
scala> val file = sc.hadoopFile(“smallLogs”)
...
scala> val filtered = file.filter(_.contains(“ERROR”))
...
scala> val mapped = file.map(...)
...
object ProcessProductionData {
def main(args: Array[String]) {
val sc = new SparkContext(...)
val file = sc.hadoopFile(“productionLogs”)
val filtered = file.filter(_.contains(“ERROR”))
val mapped = file.map(...)
...
}
}
object ProcessLiveStream {
def main(args: Array[String]) {
val sc = new StreamingContext(...)
val stream = sc.kafkaStream(...)
val filtered = file.filter(_.contains(“ERROR”))
val mapped = file.map(...)
...
}
}
Spark
+
Shark
+
Spark
Streaming](https://image.slidesharecdn.com/stratasparkstreaming-230302122008-555d307a/85/strata_spark_streaming-ppt-38-320.jpg)

















































