Downloaded 203 times







![Start the shell
• Scala Spark-shell local
– spark-shell --master local[2] --driver-memory 1g
--executor-memory 1g
• Python Spark-shell local
– pyspark --master local[2] --driver-memory 1g --executor-
memory 1g
7](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-7-320.jpg)





![Creating an RDD
• Scala
scala> val rdd = sc.parallelize(1 to 1000)
• Python
>>> data = [1,2,3,4,5]
>>> rdd = sc.parallelize(data)
>>> rdd.count()
13](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-13-320.jpg)






![Passing Functions to Spark: Scala
• Class
scala> class MyClass {
| def func1(s: String): String = ???
| def doStuff(rdd: RDD[String]): RDD[String] = rdd.map(func1)
| }
• Class with a val
scala> class MyClass {
| val field = "hello"
| def doStuff(rdd: RDD[String]): RDD[String] = rdd.map(_ + field)
| }
20](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-20-320.jpg)





![Transformations: flatMap
26
Scala
scala> val list = List(“hello world”, “hi”)
scala> val values= sc.parallelize(list)
scala> numbers.flatMap(l => l.split(“”))
Python
>>> numbers = sc.parallelize([“hello world”, “hi”]))
>>> result = numbers.flatMap(lambda line: line.split(“ “))](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-26-320.jpg)







![Other Transformations
• pipe(command, [envVars]) => Pipe each partition of the RDD
through a shell command, e.g. a R or bash script. RDD
elements are written to the process's stdin and lines output
to its stdout are returned as an RDD of strings.
• coalesce(numPartitions) => Decrease the number of partitions
in the RDD to numPartitions. Useful, when a RDD is shrink
after a filter operation
34](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-34-320.jpg)





![Actions: count, first, take(n)
scala> val lines = sc.parallelize(1 to 1000)
scala> lines.count
res1: Long = 1000
scala> lines.first
res2: Int = 1
scala> lines.take(5)
res4: Array[Int] = Array(1, 2, 3, 4, 5)
40](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-40-320.jpg)
![Actions: takeSample, takeOrdered
scala> lines.takeSample(false,10)
res8: Array[Int] = Array(170, 26, 984, 688, 519, 282, 227, 812, 456,
460)
scala> lines.takeOrdered(10)
res10: Array[Int] = Array(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
41](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-41-320.jpg)



![Why key/value pairs
• Let us consider an example
scala> val lines = sc.parallelize(1 to 1000)
scala> val fakePairs = lines.map(v => (v.toString, v))
• The type of pairs is RDD[(String, Int)] and exposes basic RDD
functions
• But, Spark provides PairRDDFunctions with methods on
key/value pairs
scala> import org.apache.spark.rdd.RDD._
scala> val pairs = rddToPairRDDFunctions(lines.map(i => i -> i.toString))
//<- from spark 1.3.0
45](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-45-320.jpg)
![Transformations for key/value
• groupByKey([numTasks]) => Called on a dataset of (K, V)
pairs, returns a dataset of (K, Iterable<V>) pairs.
• reduceByKey(func, [numTasks]) => Called on a dataset of (K,
V) pairs, returns a dataset of (K, V) pairs where the values for
each key are aggregated using the given reduce function func,
which must be of type (V,V) => V.
46](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-46-320.jpg)
![Transformations for key/value
• sortByKey([ascending], [numTasks]) => Called on a dataset of
(K, V) pairs where K implements Ordered, returns a dataset of
(K, V) pairs sorted by keys in ascending or descending order,
as specified in the boolean ascending argument.
• join(otherDataset, [numTasks]) => Called on datasets of type
(K, V) and (K, W), returns a dataset of (K, (V, W)) pairs with all
pairs of elements for each key. Outer joins are supported
through leftOuterJoin, rightOuterJoin, and fullOuterJoin.
47](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-47-320.jpg)
![Transformations for key/value
• cogroup(otherDataset, [numTasks]) => Called on datasets of
type (K, V) and (K, W), returns a dataset of (K, (Iterable<V>,
Iterable<W>)) tuples. This operation is also called groupWith.
• cartesian(otherDataset) => Called on datasets of types T
and U, returns a dataset of (T, U) pairs (all pairs of elements).
48](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-48-320.jpg)

![Per Key Average
We use reduceByKey() with mapValues() to compute
per key average
>>> rdd.mapValues(lambda: x: (x,1)).reduceByKey(lambda x,y: (x[0] +
y[0], x[1] + y[1]))
scala> rdd.mapValues((_,1)).reduceByKey((x,y) => (x._1 + y._1, x._2 +
y._2))
50](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-50-320.jpg)






![Broadcast Variables
• Allow the programmer to keep a read-only variable
cached on each machine.
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
scala> broadcastVar.value
>>> broadcastVar = sc.broadcast([1, 2, 3])
>>> broadcastVar.value
57](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-57-320.jpg)
![Accumulators
• They can be used to implement counters (as in
MapReduce) or sums.
scala> val accum = sc.accumulator(0, "My Accumulator")
scala> sc.parallelize(Array(1, 2, 3, 4)).foreach(x => accum += x)
scala> accum.value
>>> accum = sc.accumulator(0)
>>> sc.parallelize([1, 2, 3, 4]).foreach(lambda x: accum.add(x))
>>> accum.value
58](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-58-320.jpg)





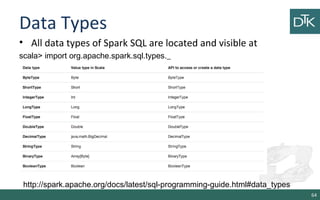



![Parquet.io
• Column-Oriented storage format that can store records with
nested fields efficiently.
• Spark SQL support reading and writing from this format
scala> val people: RDD[Person] = ...
scala> people.saveAsParquetFile("people.parquet")
scala> val parquetFile = sqlContext.parquetFile("people.parquet")
scala> parquetFile.registerTempTable("parquetFile")
scala> val teenagers = sqlContext.sql("SELECT name FROM parquetFile
WHERE age >= 13 AND age <= 19")
68](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-68-320.jpg)
















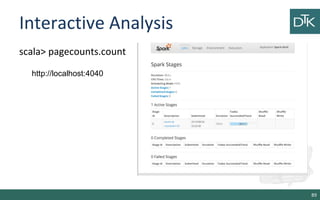
![Interactive Analysis
scala> sc
res: spark.SparkContext = spark.SparkContext@470d1f30
Load the data
scala> val pagecounts = sc.textFile("data/pagecounts")
INFO mapred.FileInputFormat: Total input paths to process : 74
pagecounts: spark.RDD[String] = MappedRDD[1] at textFile at <console>:12
87](https://image.slidesharecdn.com/11-150606091935-lva1-app6891/85/11-From-Hadoop-to-Spark-2-2-87-320.jpg)






Spark provides tools for distributed processing of large datasets across clusters. It includes APIs for distributed datasets called RDDs (Resilient Distributed Datasets) and transformations and actions that can be performed on those datasets in parallel. Key features of Spark include the Spark Shell for interactive use, DataFrames for structured data processing, and Spark Streaming for real-time data analysis.























































































