Downloaded 72 times



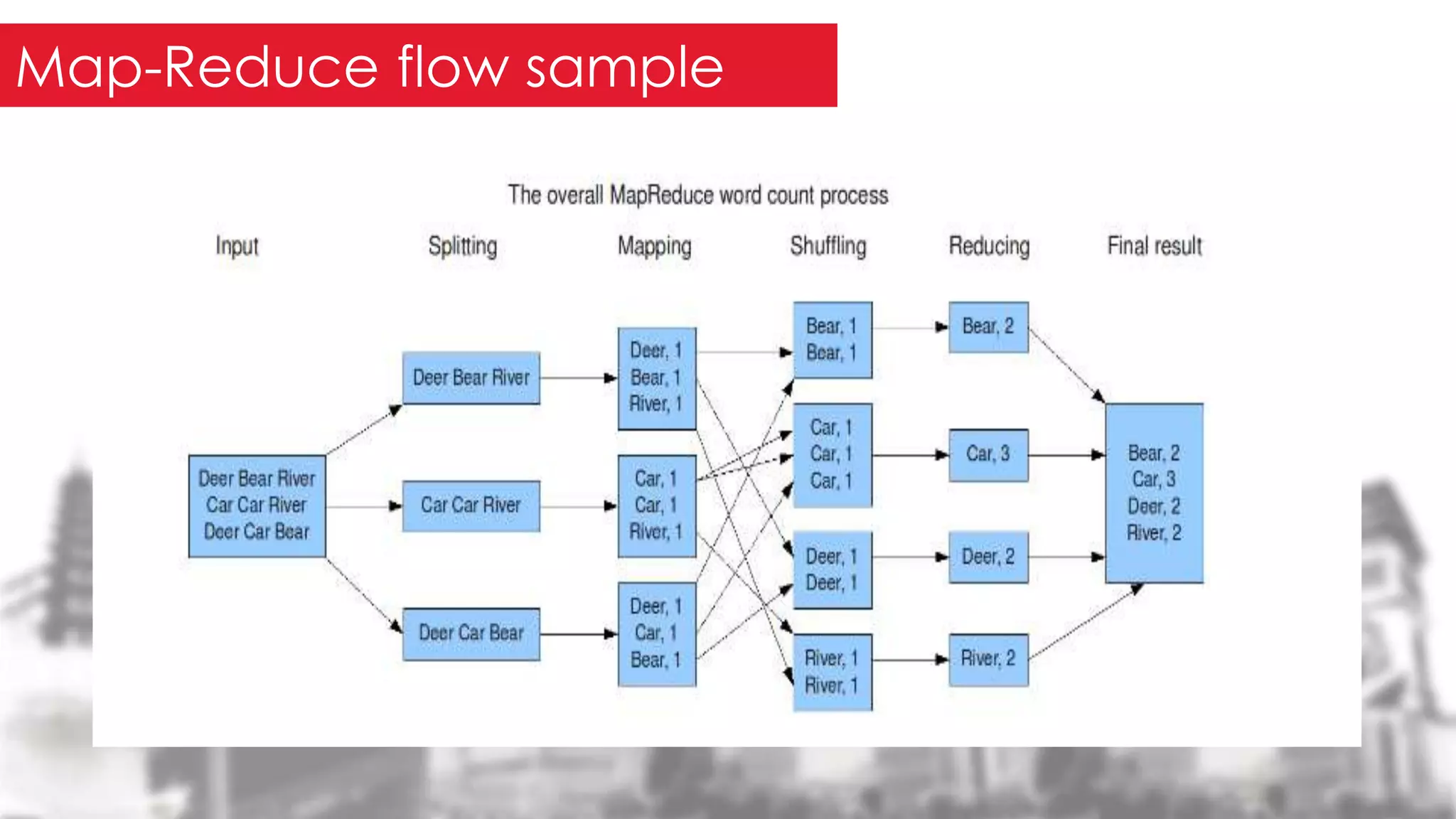
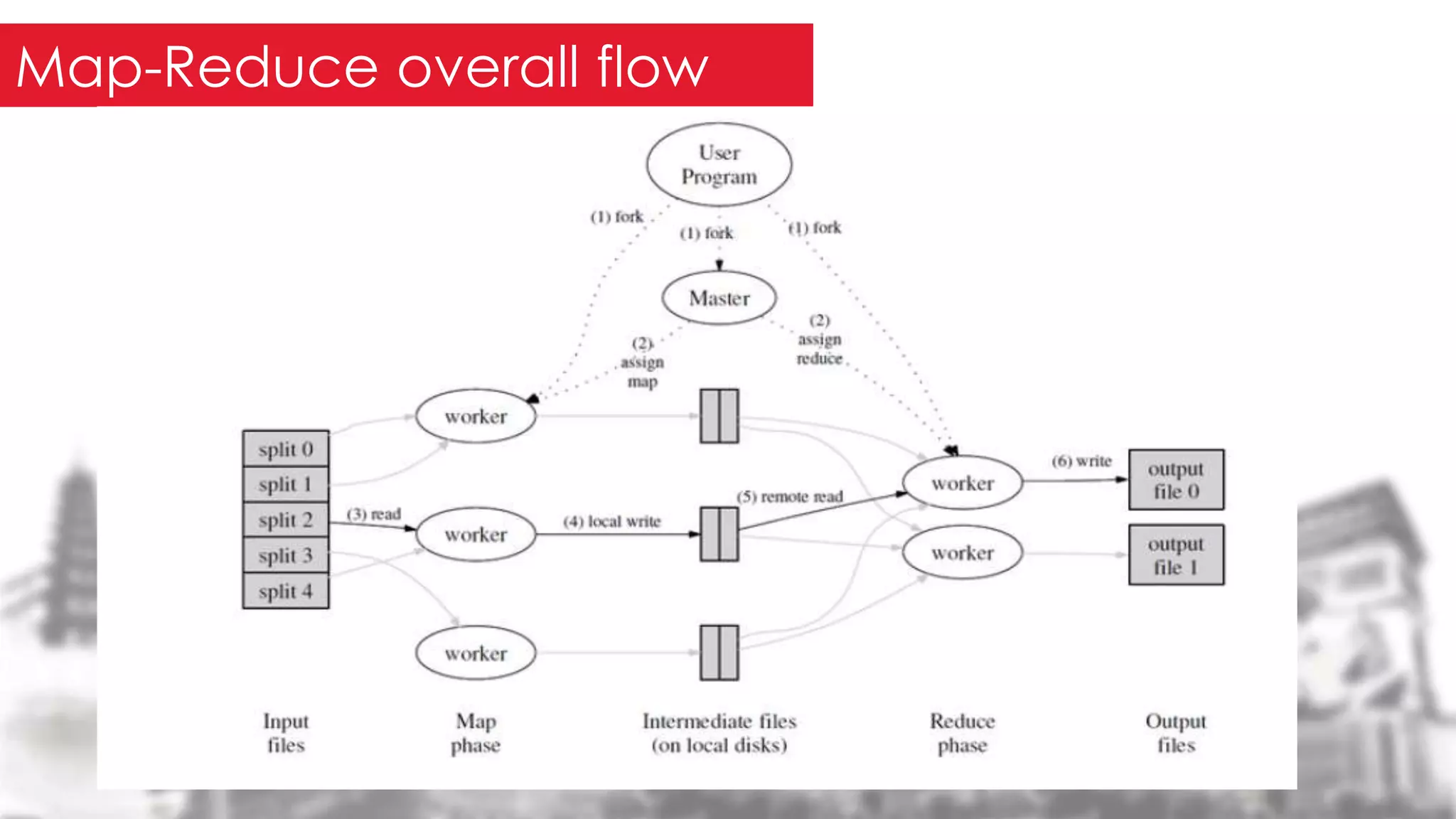


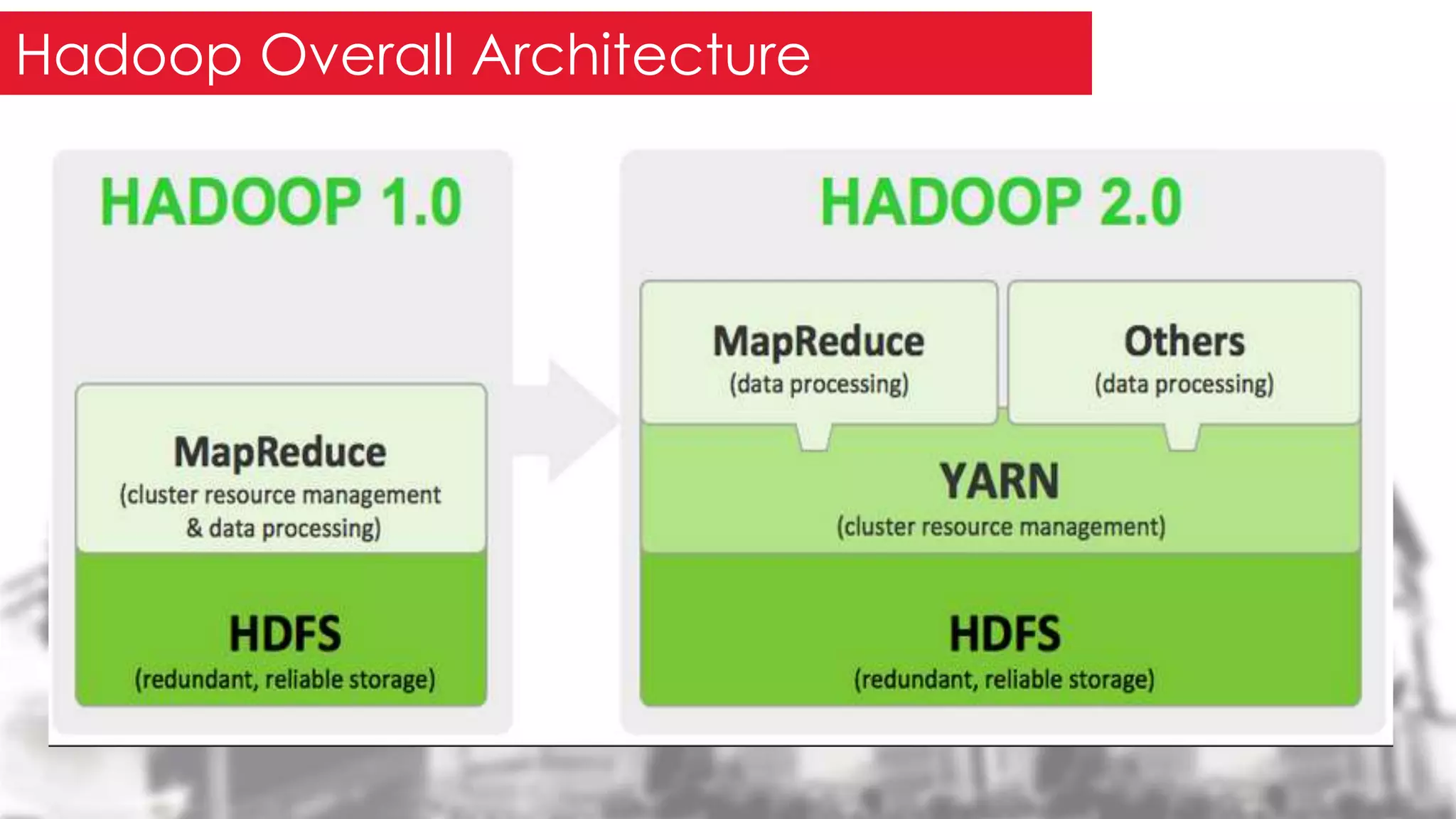

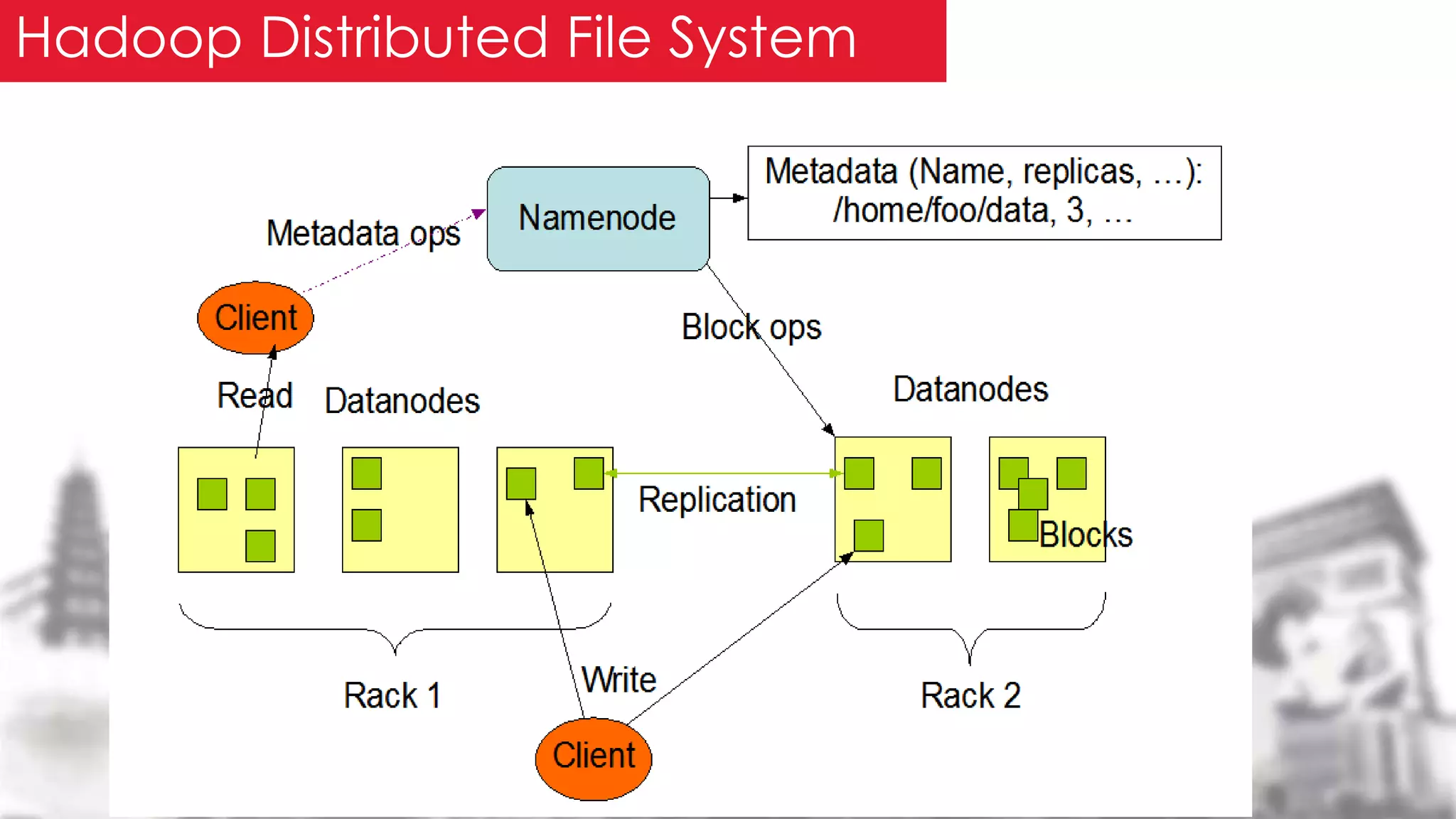
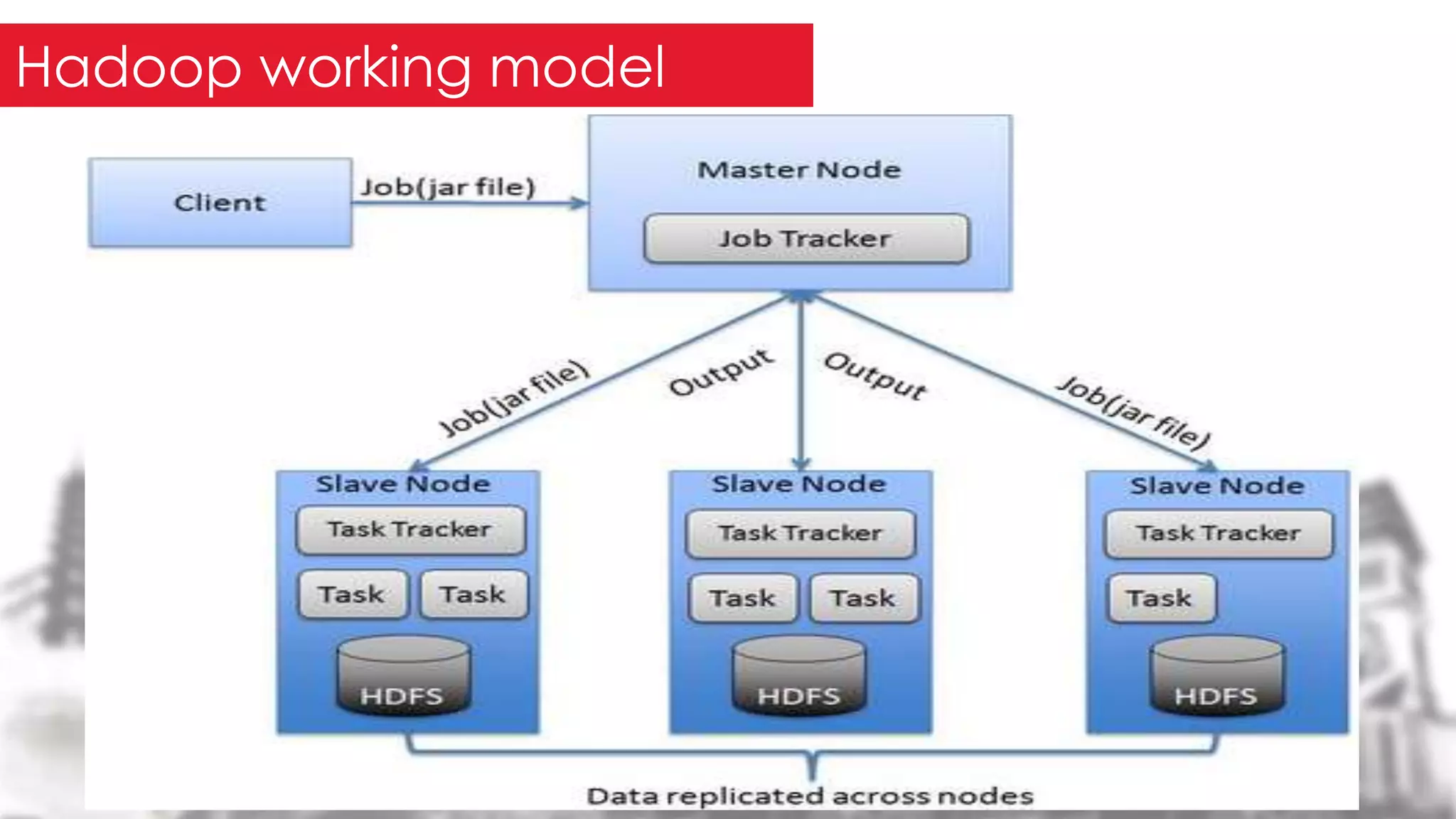

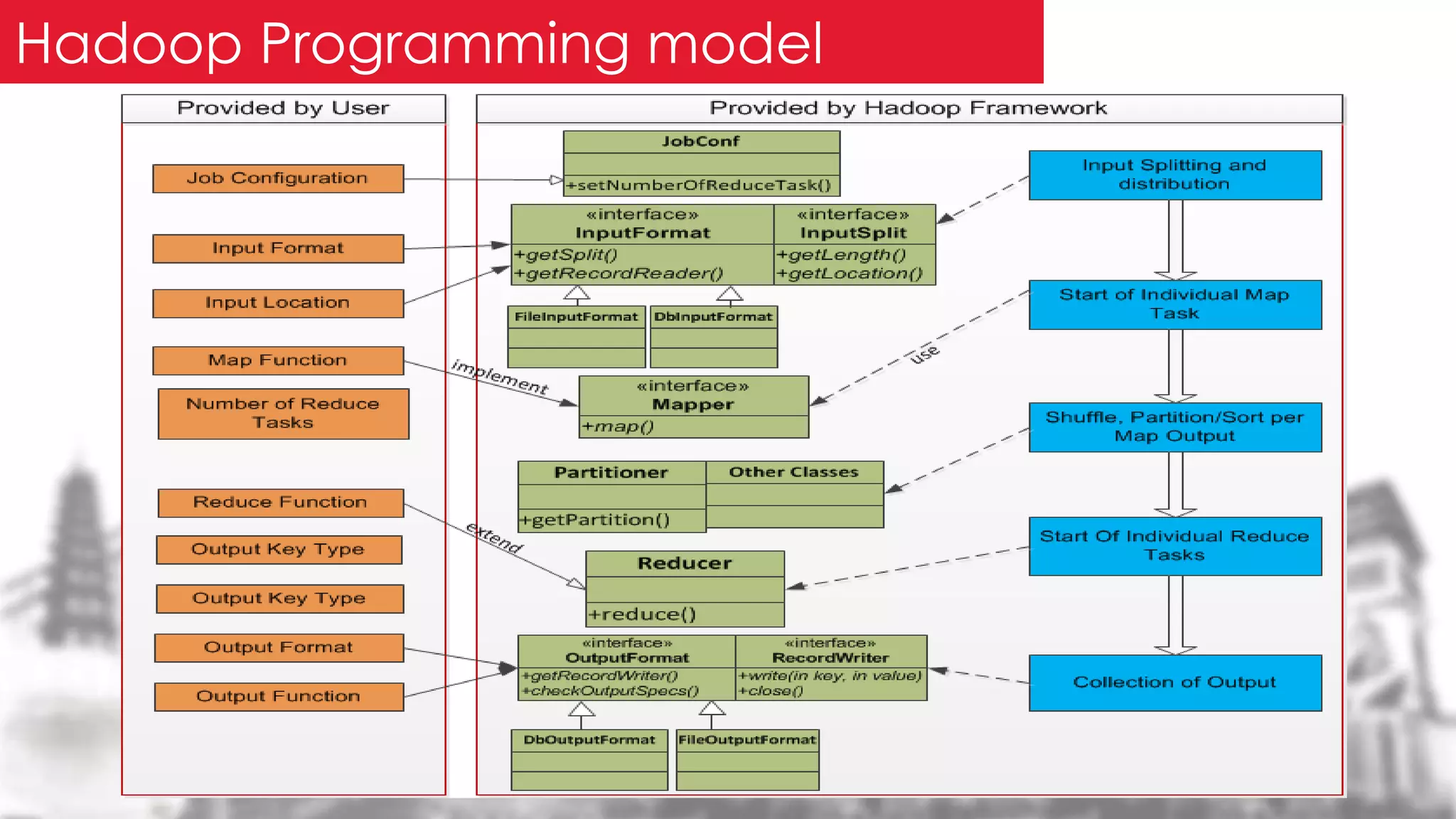

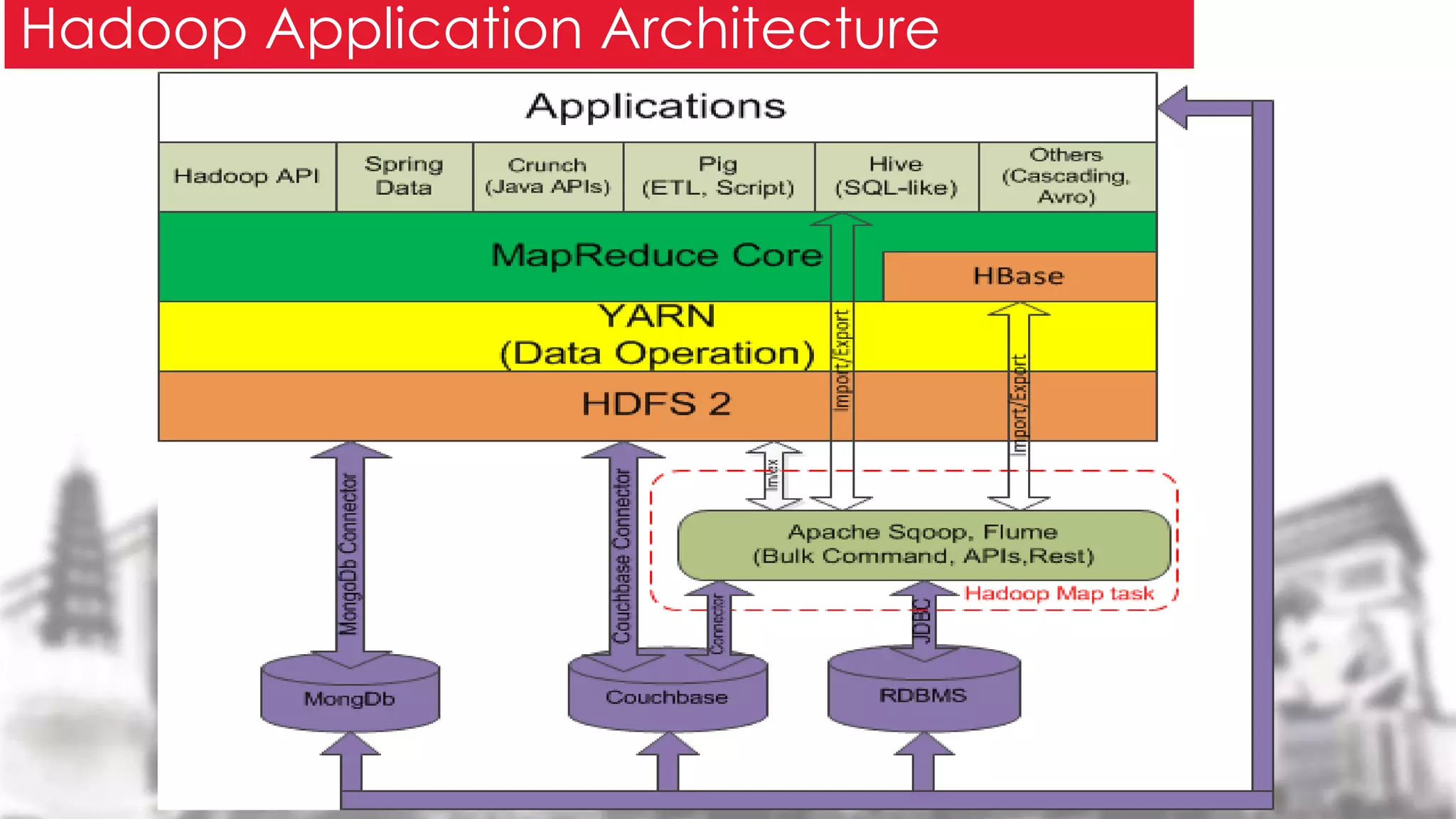

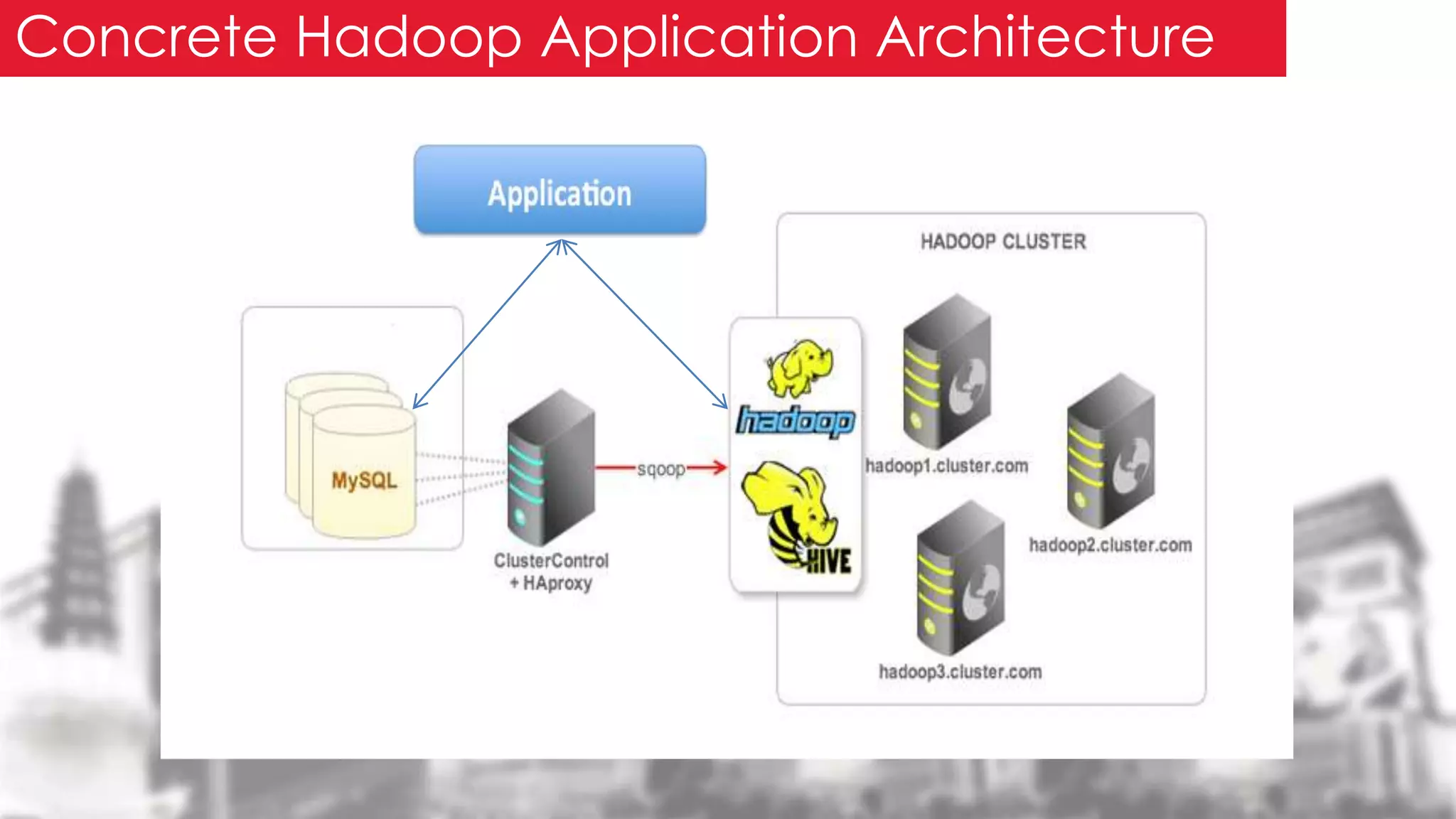





This document provides an overview of the Hadoop framework. It introduces MapReduce and Hadoop, describes the Hadoop application architecture including HDFS, MapReduce programming model, and developing a typical Hadoop application. It discusses setting up a Hadoop environment and provides a sample word count demo to practice Hadoop.



































































