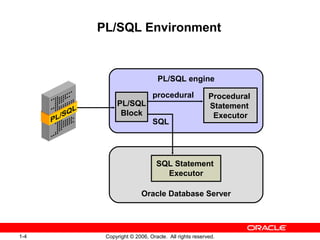
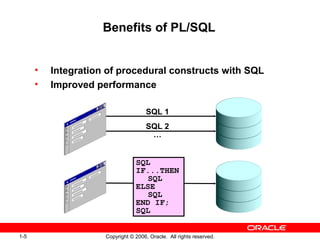
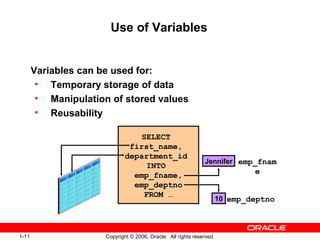
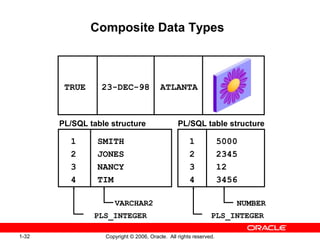
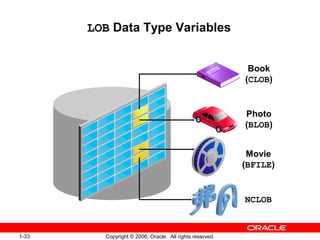
PL/SQL is Oracle's standard language for accessing and manipulating data in Oracle databases. It allows developers to integrate SQL statements with procedural constructs like variables, conditions, and loops. PL/SQL code is organized into blocks that define a declarative section for variable declarations and an executable section containing SQL and PL/SQL statements. Variables can be scalar, composite, reference, or LOB types and are declared in the declarative section before being used in the executable section.




![1-7 Copyright © 2006, Oracle. All rights reserved.
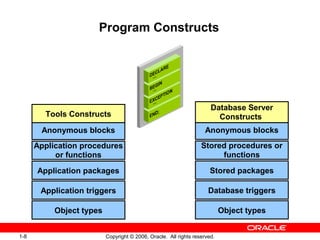
Block Types
Anonymous Procedure
Function
[DECLARE]
BEGIN
--statements
[EXCEPTION]
END;
PROCEDURE name
IS
BEGIN
--statements
[EXCEPTION]
END;
FUNCTION name
RETURN datatype
IS
BEGIN
--statements
RETURN value;
[EXCEPTION]
END;](https://image.slidesharecdn.com/class01-130704014024-phpapp02/85/1-Introduction-to-PL-SQL-7-320.jpg)







![1-18 Copyright © 2006, Oracle. All rights reserved.
Base Scalar Data Types
• CHAR [(maximum_length)]
• VARCHAR2 (maximum_length)
• LONG
• LONG RAW
• NUMBER [(precision, scale)]
• BINARY_INTEGER
• PLS_INTEGER
• BOOLEAN
• BINARY_FLOAT
• BINARY_DOUBLE](https://image.slidesharecdn.com/class01-130704014024-phpapp02/85/1-Introduction-to-PL-SQL-18-320.jpg)






























































![Les16[1]Declaring Variables](https://cdn.slidesharecdn.com/ss_thumbnails/les161-220214161043-thumbnail.jpg?width=640&height=640&fit=bounds)




















































