Download as PDF, PPTX































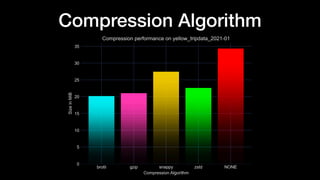
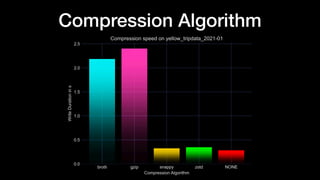
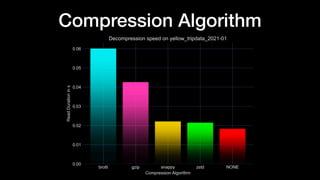

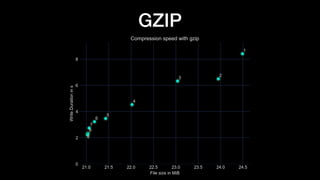
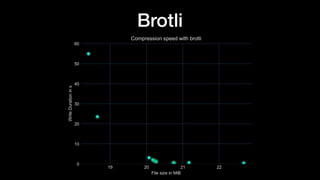
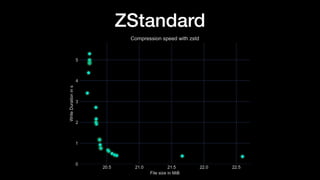
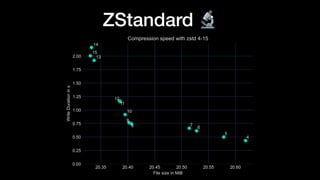
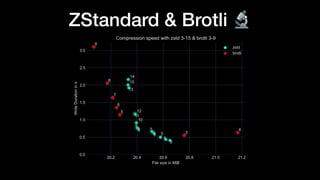





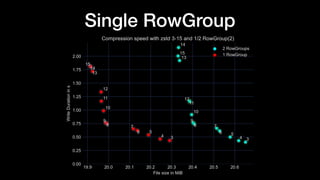

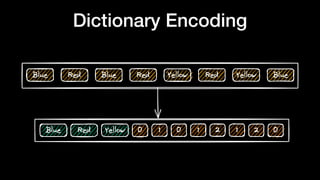
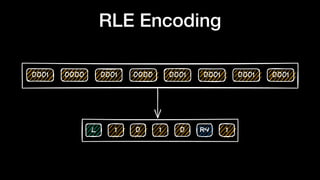
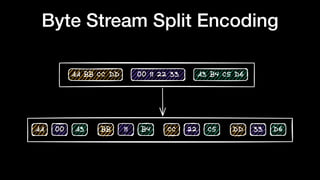

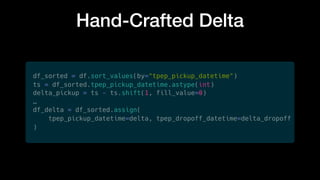



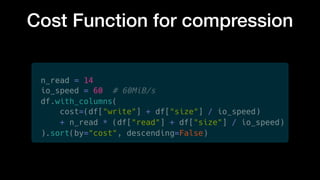

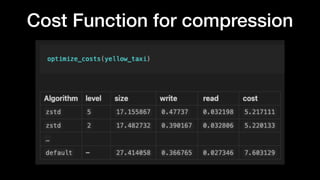
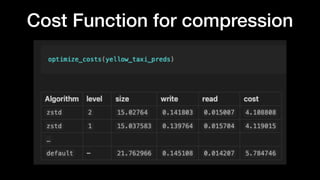



The document discusses optimizing Apache Parquet file settings, including compression algorithms, data types, and file structure for efficient data storage and access. Key recommendations include utilizing Zstandard for compression, fine-tuning rowgroup sizes, and implementing delta encoding where beneficial. Practical examples are provided, emphasizing the importance of testing different configurations to enhance performance with real datasets like New York taxi trips and others.








































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)













![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)


