Downloaded 178 times









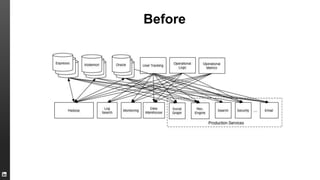
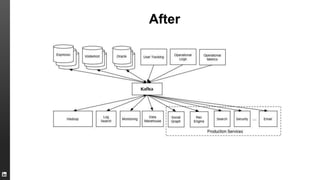



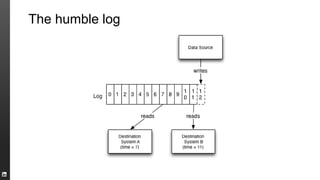
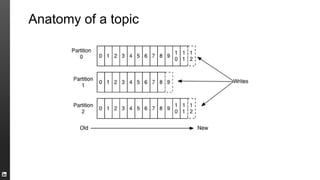
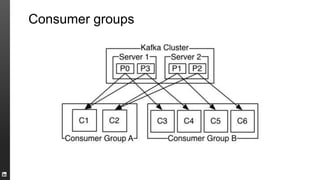
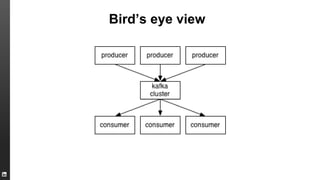
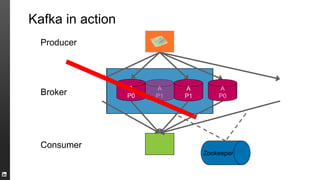




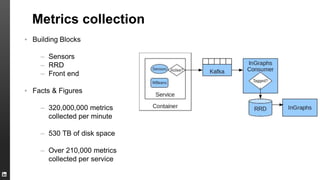
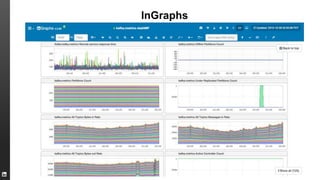
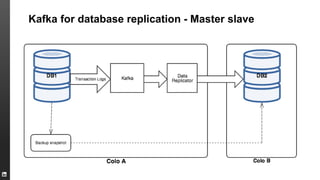
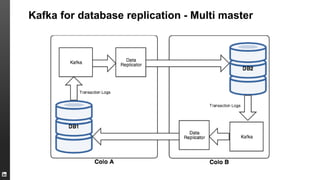



The document provides an overview of Kafka, a high-throughput distributed messaging system originally developed at LinkedIn, focusing on its functionalities, use cases, and performance metrics. Kafka ensures at least once delivery and strong ordering while supporting real-time data processing across multiple data centers. It discusses its application at LinkedIn, including monitoring, user tracking, and database replication, alongside encouraging community involvement in its development.




















































































