Downloaded 178 times




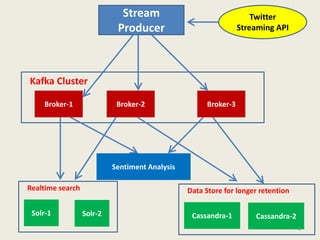
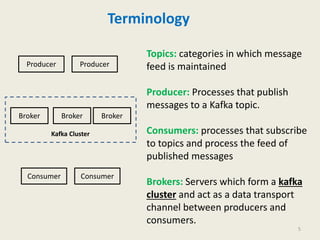
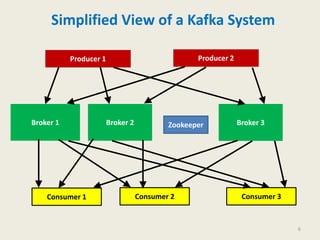
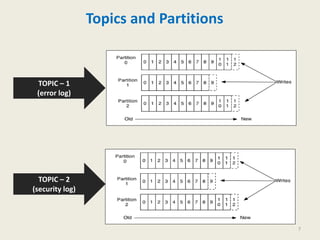





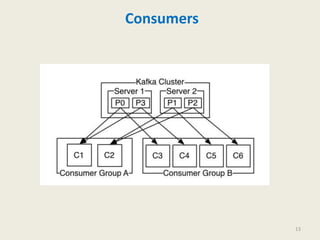
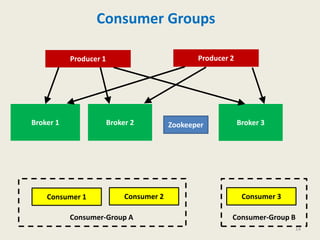
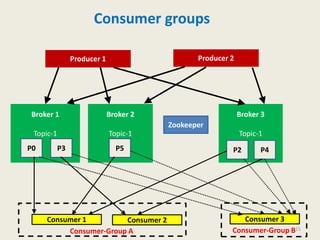







Kafka is a distributed, replicated, and partitioned platform for handling real-time data feeds. It allows both publishing and subscribing to streams of records, and is commonly used for applications such as log aggregation, metrics, and streaming analytics. Kafka runs as a cluster of one or more servers that can reliably handle trillions of events daily.

























![[245] presto 내부구조 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/245presto-150915054242-lva1-app6891-thumbnail.jpg?width=640&height=640&fit=bounds)





























































