This document discusses adapting an AI object identification (AOI) system to changes in domains. It proposes using attention and domain adaptation techniques. Specifically:
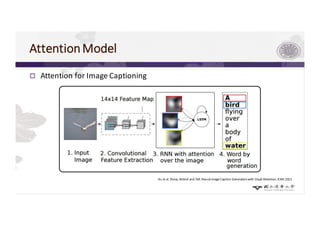
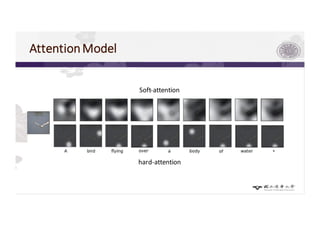
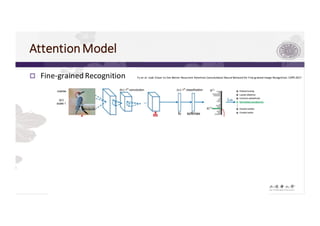
1) AOI is like fine-grained recognition, which can benefit from attention models that focus on discriminative regions.
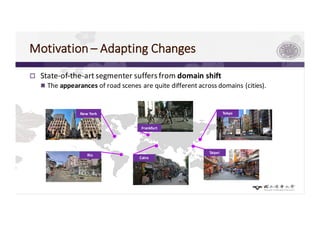
2) Domain shift between different sensors/viewpoints can degrade performance, but domain adaptation methods like attention models and domain adversarial learning can help address this.
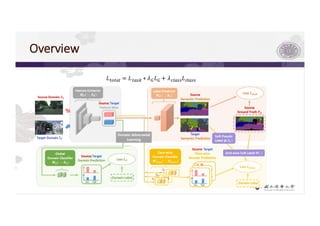
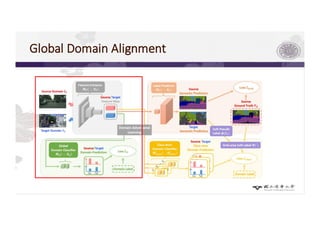
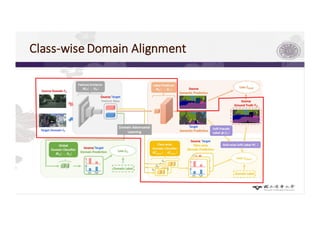
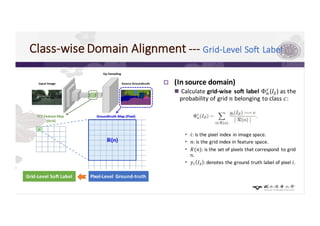
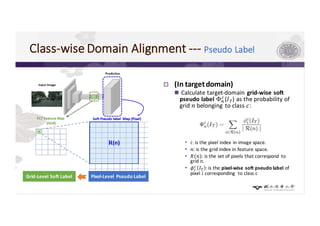
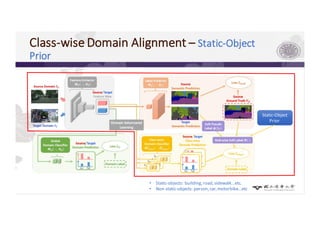
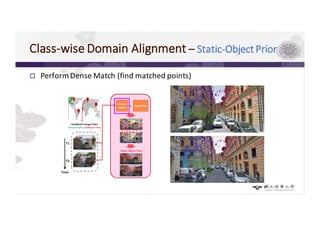
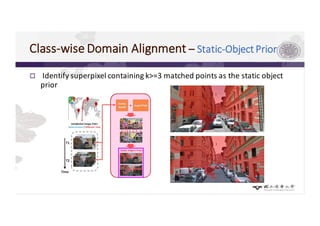
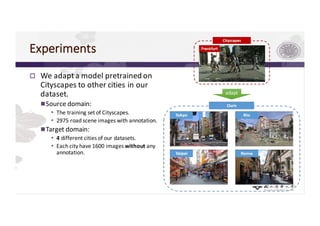
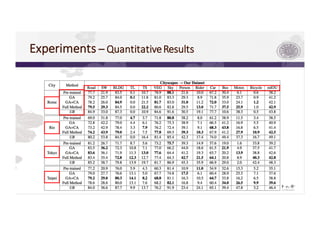
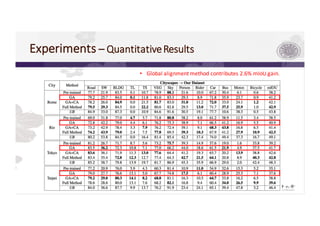
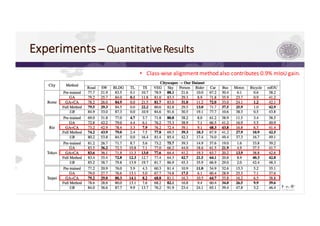
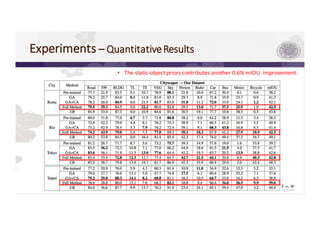
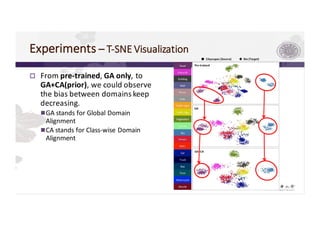
3) The paper proposes a method for unsupervised cross-city adaptation of road scene segmenters using global and class-wise domain alignment with an attention-based static object prior. This achieves state-of-the-art performance adapting models between cities.




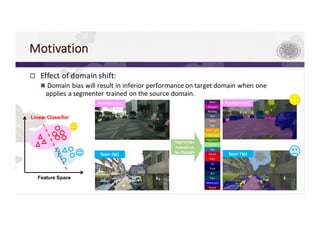

![Motivation
p Goal: use domain adaptation to mitigate the effect of domain shift.
p Approaches:
n Supervised Fine-Tuning: CAN access the label on the target domain.
• Straightforward but time-consuming and expensive.
n Unsupervised Adaptation: CAN’T access the label on the target domain.
• More challenging but low cost.
Pixel labeling of one
Cityscapes image takes
90 minutes on average.[4]
[4] M. Cordts, M.Omran, S. Ramos, T. Rehfeld,M. Enzweiler, R. Benenson,U.Franke,S.Roth, and B. Schiele, “The cityscapes dataset for semantic urban scene
understanding,” in CVPR,IEEE,2016.
a
Practical in real life !](https://image.slidesharecdn.com/201701-180815025708/85/AOI-11-320.jpg)
























![ViT (Vision Transformer) Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/vitreviewcdm-201012184226-thumbnail.jpg?width=640&height=640&fit=bounds)








![Deformable DETR Review [CDM]](https://cdn.slidesharecdn.com/ss_thumbnails/deformabledetrreviewcdm-201113070345-thumbnail.jpg?width=640&height=640&fit=bounds)













![[DL輪読会]"CyCADA: Cycle-Consistent Adversarial Domain Adaptation"&"Learning Se...](https://cdn.slidesharecdn.com/ss_thumbnails/20180803dlakuzawa-180803003349-thumbnail.jpg?width=640&height=640&fit=bounds)

![[NS][Lab_Seminar_241118]Relation Matters: Foreground-aware Graph-based Relati...](https://cdn.slidesharecdn.com/ss_thumbnails/nslabseminar241118fgrr-241118111529-1ff1aba4-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DL輪読会]Domain Adaptive Faster R-CNN for Object Detection in the Wild](https://cdn.slidesharecdn.com/ss_thumbnails/doikento20180615-180620021127-thumbnail.jpg?width=640&height=640&fit=bounds)










































