A Near-linear TimeApproximation
for Angle-based Outlier Detection
in High-dimensional Data [KDD’12]
by N. Pham & R. Pagh Univ. of Copenhagen
発表者:数理情報学専攻 修士2年 山田直敬
1
2.
発表の流れ
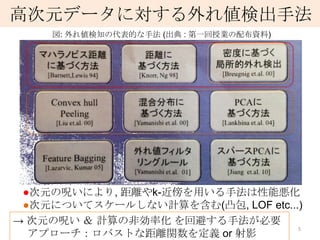
1. Outlier Detectionin High-dimensional data
- 高次元では次元の呪いによる性能悪化が発生する
2. Angle-based Outlier Detection (ABOD)
- 距離や密度による手法よりも高次元でロバストな手法
3. A Near Linear Time Approximation for ABOD
- ABODの計算量は O(dn3). 近似でこれを大幅に高速化
本論文のcontribution
2
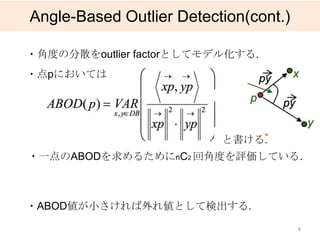
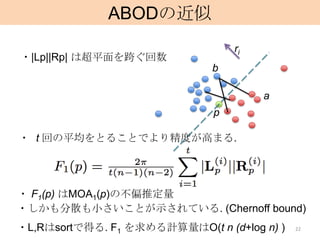
ABODの近似
ri
・|Lp||Rp| は超平面を跨ぐ回数
b
a
p
・ t 回の平均をとることでより精度が高まる.
・ F1(p) はMOA1(p)の不偏推定量
・しかも分散も小さいことが示されている. (Chernoff bound)
・L,Rはsortで得る. F1 を求める計算量はO(t n (d+log n) ) 22
References [年代順]
1. H.P.Kriegel, M.Schubert, & A. Zimek. Angle-based
outlier detection in high-dimensional data. In KDD
2008.
1. H.P. Kriegel, M. Schubert, & A. Zimek. Outlier
detection techniques. In tutorial at KDD 2010.
1. N. Pham & R. Pagh. A Near-linear Time
Approximation Algorithm for Angle-based Outlier
Detection in High-dimensional Data. In KDD 2012.
29
![A Near-linear Time Approximation
for Angle-based Outlier Detection
in High-dimensional Data [KDD’12]
by N. Pham & R. Pagh Univ. of Copenhagen
発表者:数理情報学専攻 修士2年 山田直敬
1](https://image.slidesharecdn.com/yamanishi-121226023216-phpapp02/85/Angle-Based-Outlier-Detection-1-320.jpg)
![A Near-linear Time Approximation
for Angle-based Outlier Detection
in High-dimensional Data [KDD’12]
by N. Pham & R. Pagh Univ. of Copenhagen
発表者:数理情報学専攻 修士2年 山田直敬
1](https://image.slidesharecdn.com/yamanishi-121226023216-phpapp02/75/Angle-Based-Outlier-Detection-1-2048.jpg)


![次元の呪い
図:次元数増加に伴う距離の同質化 [2]
次元数: 順に
2, 4,
20, 50
横軸 : マハラノビス距離の値
縦軸:観測頻度
・高次元化が進むと,距離の近接性が意味を成さなくなる.
・実際 となる. [1]
・データは非常にスパース. ほとんどの点が外れ値になる. 4](https://image.slidesharecdn.com/yamanishi-121226023216-phpapp02/85/Angle-Based-Outlier-Detection-4-320.jpg)

![Angle-Based Outlier Detection
by Kriegel+ ’08 [1]
発想
・角度は高次元においてマハラノビス距離よりもロバスト
e.g. コサイン類似度は文書に対しても良く用いられる.
・外れ値では他の二点間との角度がどれも似ている
図: 外れ値、正常値、境界点での角度の分布
縦軸:
角度(rad)
Outlier Factorを角度の分散としてモデル化
7
出典: [3]](https://image.slidesharecdn.com/yamanishi-121226023216-phpapp02/85/Angle-Based-Outlier-Detection-7-320.jpg)
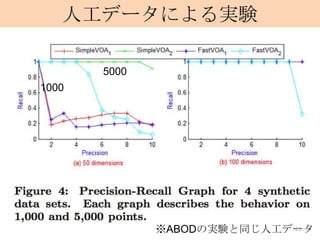
![ABOD vs. LOF (Local Outlier Factor)
・人工データによる実験. 5つの混合ガウス+10個のoutlier
・precision recallともにABODが上回る.
9
出典: [1]](https://image.slidesharecdn.com/yamanishi-121226023216-phpapp02/85/Angle-Based-Outlier-Detection-9-320.jpg)
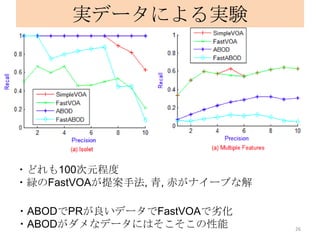
![ABODの欠点
・全ての点でABODを求めるための計算量は O(dn3).
・データ数 n の増加に対してスケールしない.
10
出典: [1]より見やすく編集](https://image.slidesharecdn.com/yamanishi-121226023216-phpapp02/85/Angle-Based-Outlier-Detection-10-320.jpg)
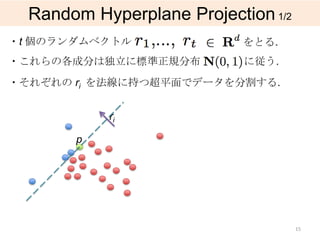
![3.
A Near Linear Approximation for
Angle-based Outlier Detection
[main part]
11](https://image.slidesharecdn.com/yamanishi-121226023216-phpapp02/85/Angle-Based-Outlier-Detection-11-320.jpg)











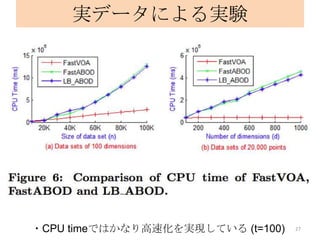

![References [年代順]
1. H.P. Kriegel, M.Schubert, & A. Zimek. Angle-based
outlier detection in high-dimensional data. In KDD
2008.
1. H.P. Kriegel, M. Schubert, & A. Zimek. Outlier
detection techniques. In tutorial at KDD 2010.
1. N. Pham & R. Pagh. A Near-linear Time
Approximation Algorithm for Angle-based Outlier
Detection in High-dimensional Data. In KDD 2012.
29](https://image.slidesharecdn.com/yamanishi-121226023216-phpapp02/85/Angle-Based-Outlier-Detection-29-320.jpg)





![[DL輪読会] Spectral Norm Regularization for Improving the Generalizability of De...](https://cdn.slidesharecdn.com/ss_thumbnails/dlhackspectralnorm1-170907072536-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Vision Transformer with Deformable Attention (Deformable Attention Tra...](https://cdn.slidesharecdn.com/ss_thumbnails/dl0114-220114032933-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DL輪読会]NVAE: A Deep Hierarchical Variational Autoencoder](https://cdn.slidesharecdn.com/ss_thumbnails/nvaeadeephierarchicalvariationalautoencoder-201113004930-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2021 [OS2-01] 転移学習の基礎:異なるタスクの知識を利用するための機械学習の方法](https://cdn.slidesharecdn.com/ss_thumbnails/os2-02final-210610091211-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]相互情報量最大化による表現学習](https://cdn.slidesharecdn.com/ss_thumbnails/20190913iwasawa-190913002312-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning Transferable Visual Models From Natural Language Supervision](https://cdn.slidesharecdn.com/ss_thumbnails/dlkobayashi0115-210115012308-thumbnail.jpg?width=640&height=640&fit=bounds)






![SSII2022 [SS2] 少ないデータやラベルを効率的に活用する機械学習技術 〜 足りない情報をどのように補うか?〜](https://cdn.slidesharecdn.com/ss_thumbnails/ss2ssii2022-220607054716-2760bd30-thumbnail.jpg?width=640&height=640&fit=bounds)

![[Dl輪読会]introduction of reinforcement learning](https://cdn.slidesharecdn.com/ss_thumbnails/dlintroductionofreinforcementlearning-161121061444-thumbnail.jpg?width=640&height=640&fit=bounds)




















