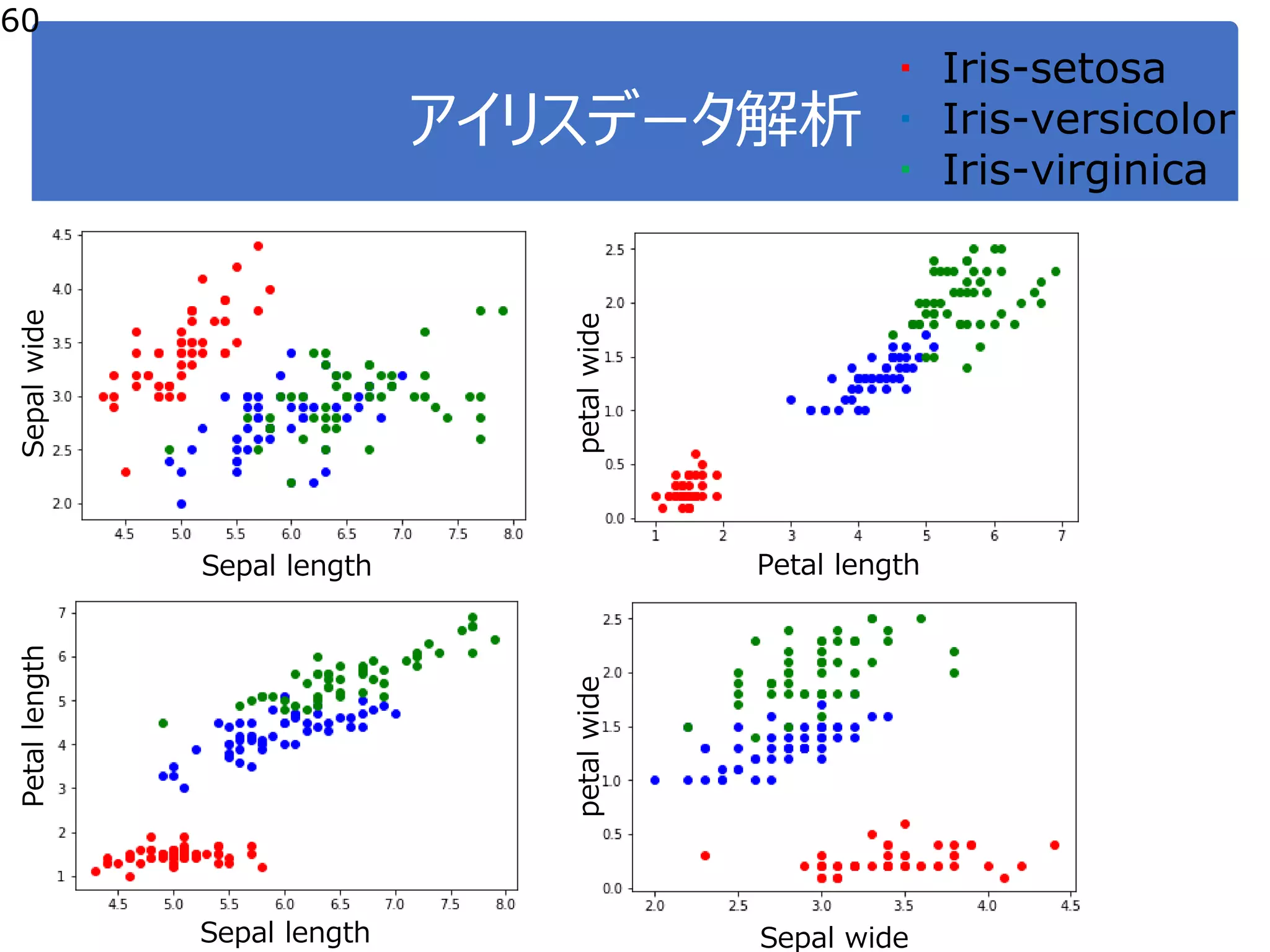
Practical data science course at Kyushu University. 九州大学 大学院システム情報科学府の講義「データサイエンス概論第二」,「データサイエンス演習第一」で使用している資料です.


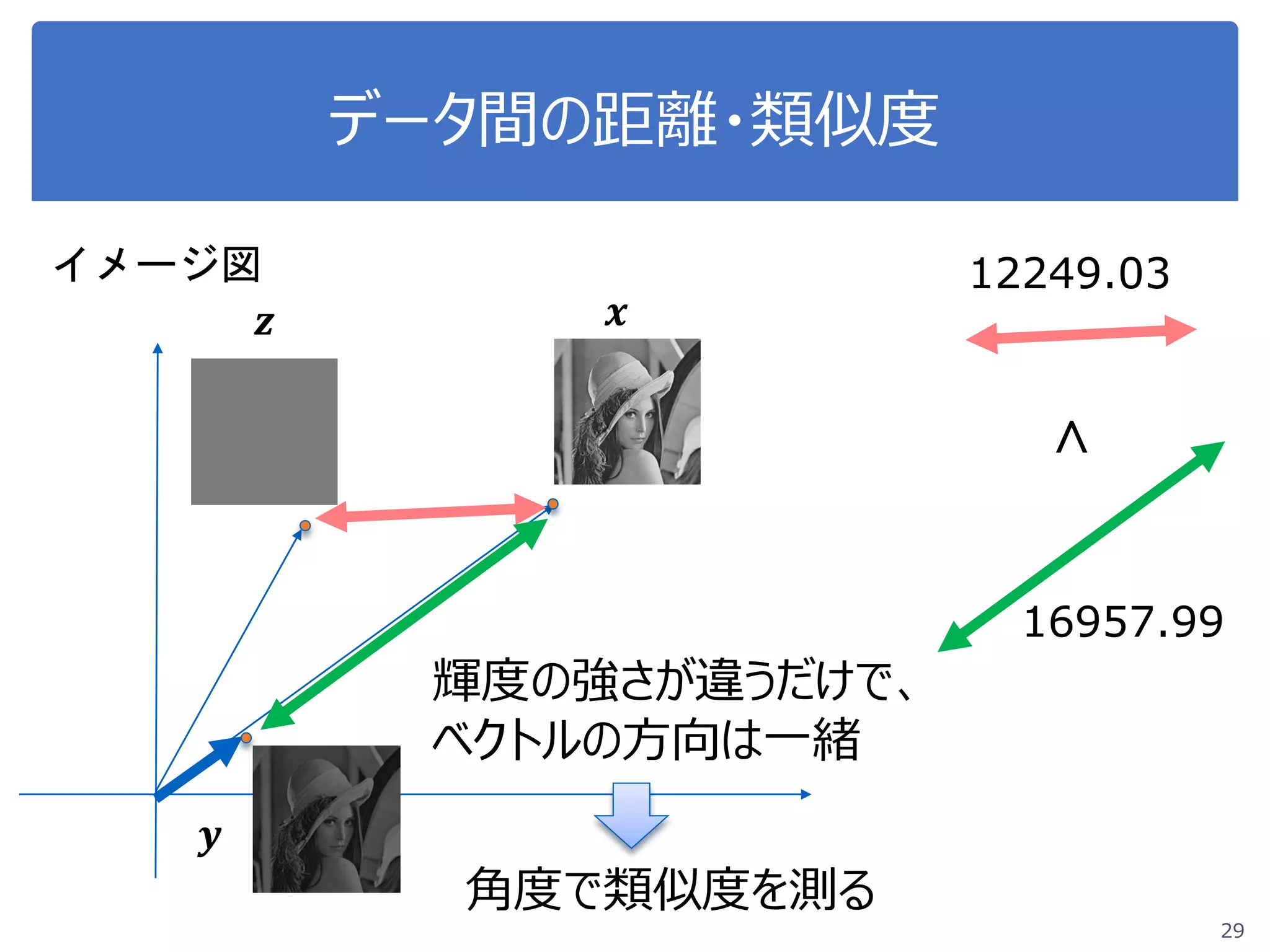
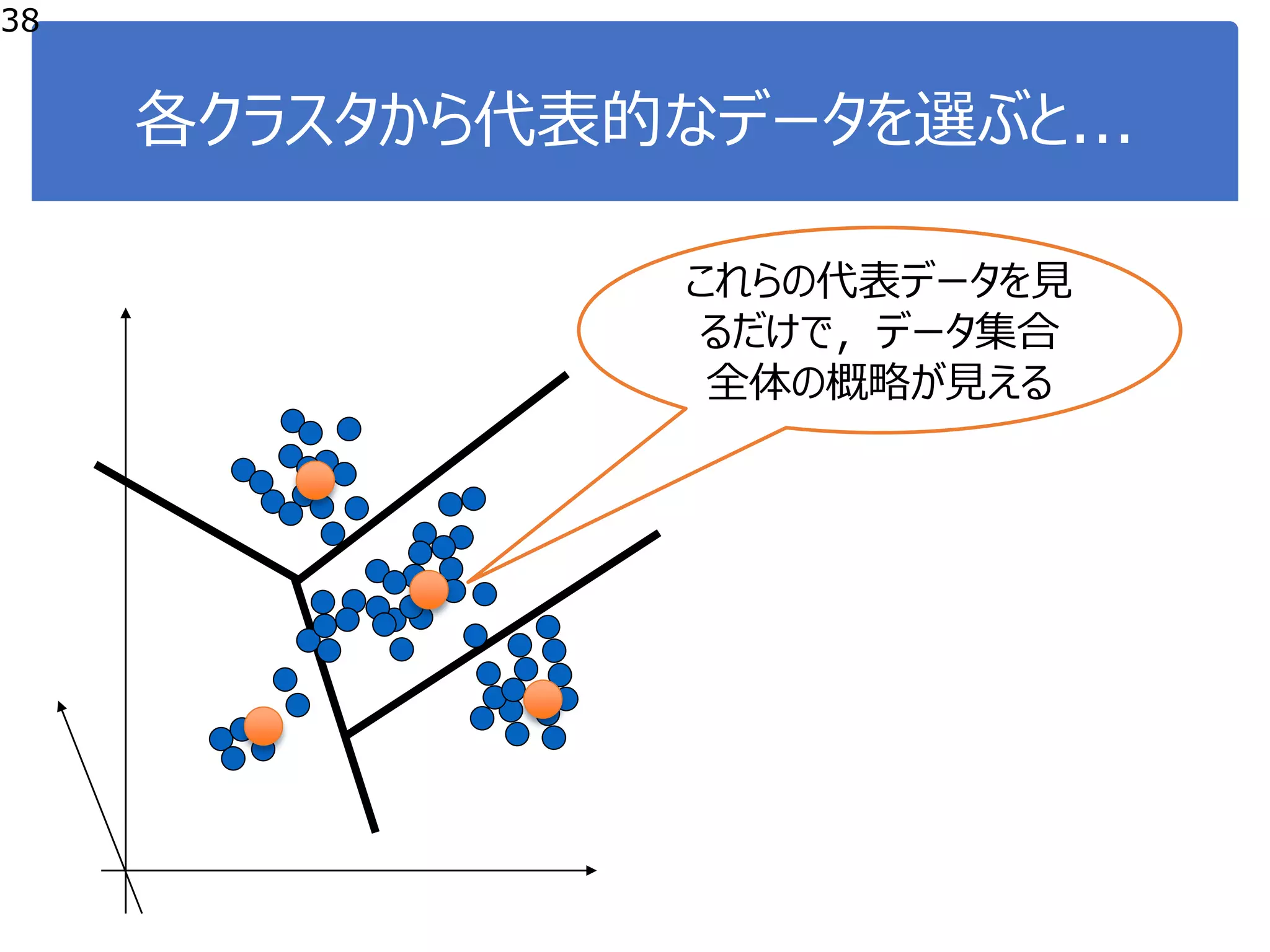
![距離がわかると何に使えるか?
実は超便利!
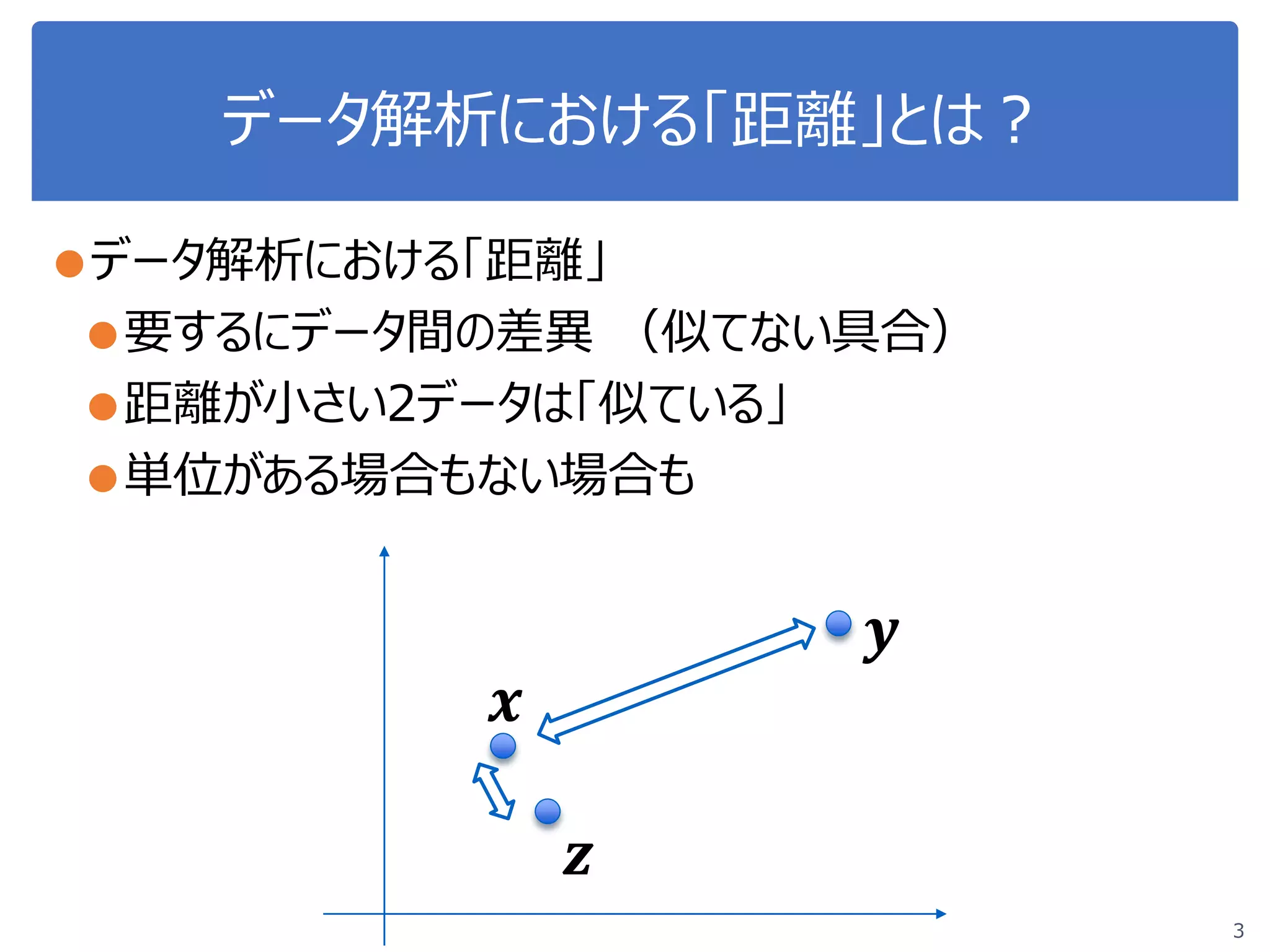
●データ間の比較が定量的にできる
●「xとyは全然違う/結構似ている」 「xとyは28ぐらい違う」
●「xにとっては,yよりもzのほうが似ている」
●データ集合のグルーピングができる
●似たものとどおしでグループを作る
●データの異常度が測れる
●他に似たデータがたくさんあれば正常,
一つもなければ異常
[Goldstein, Uchida, PLoSONE, 2016]](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-4-2048.jpg)
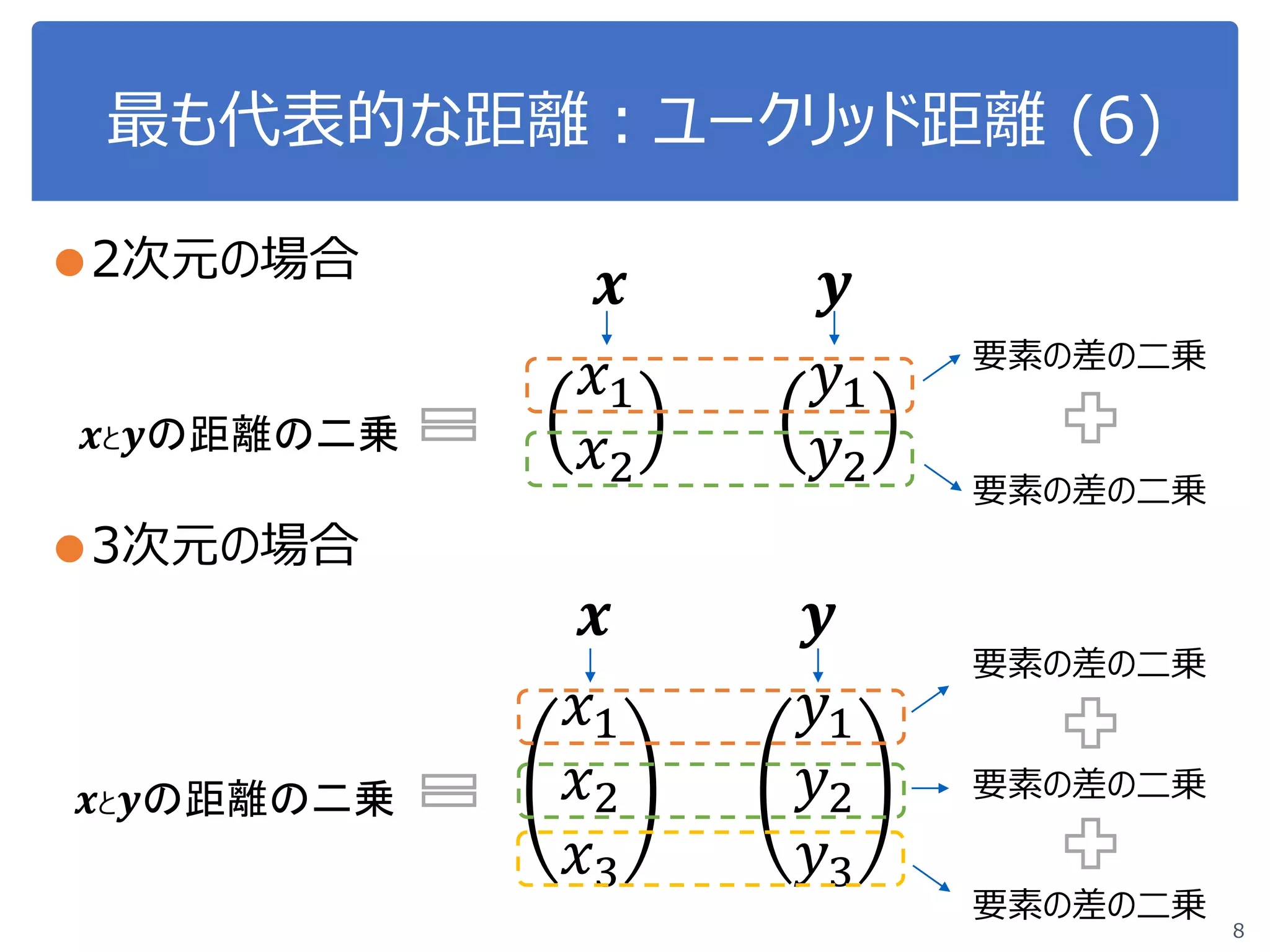


![ユークリッド距離:プログラミング (10)
12
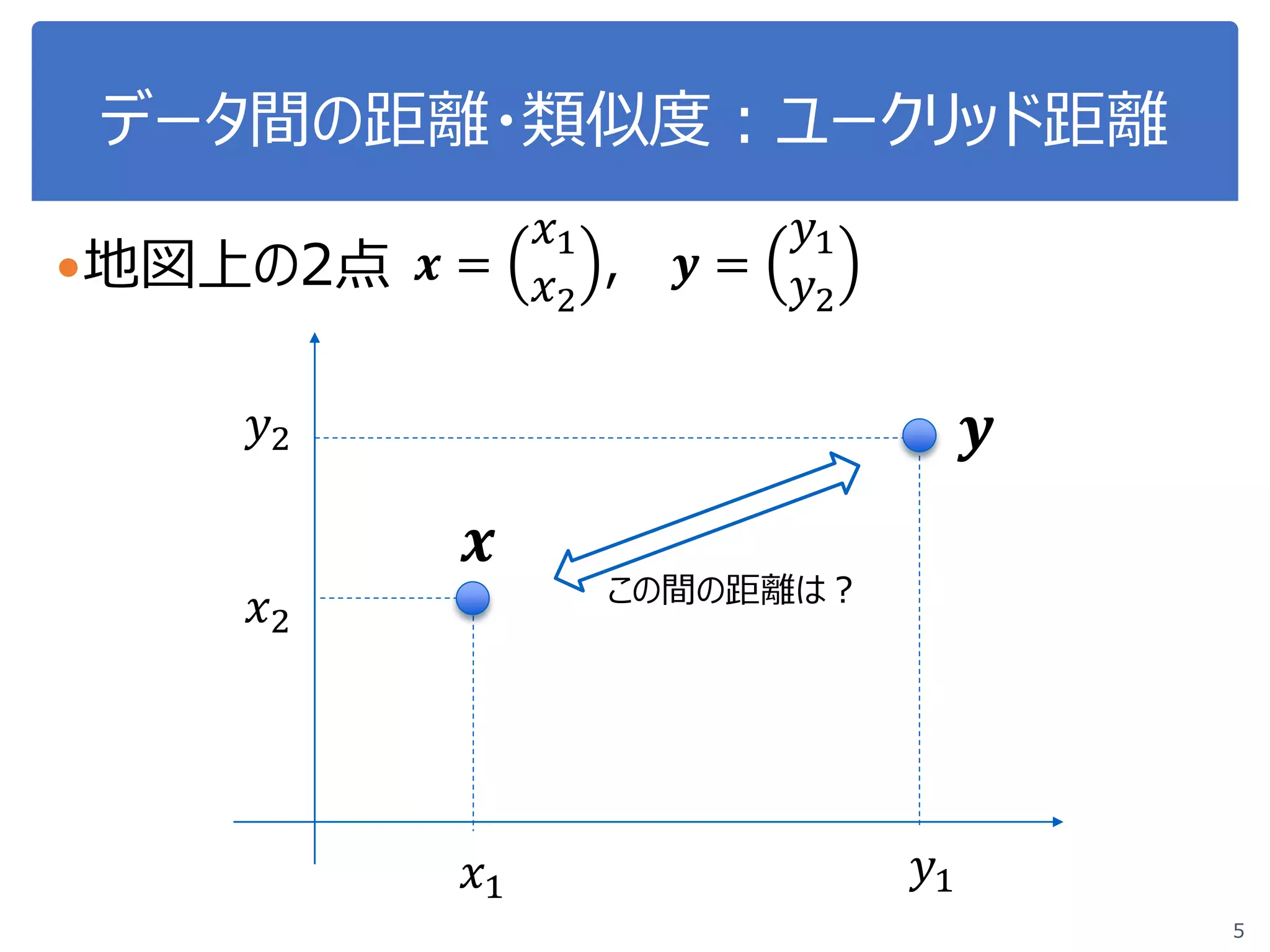
●2次元の場合 𝒙𝒙 =
𝑥𝑥1
𝑥𝑥2
, 𝒚𝒚 =
𝑦𝑦1
𝑦𝑦2
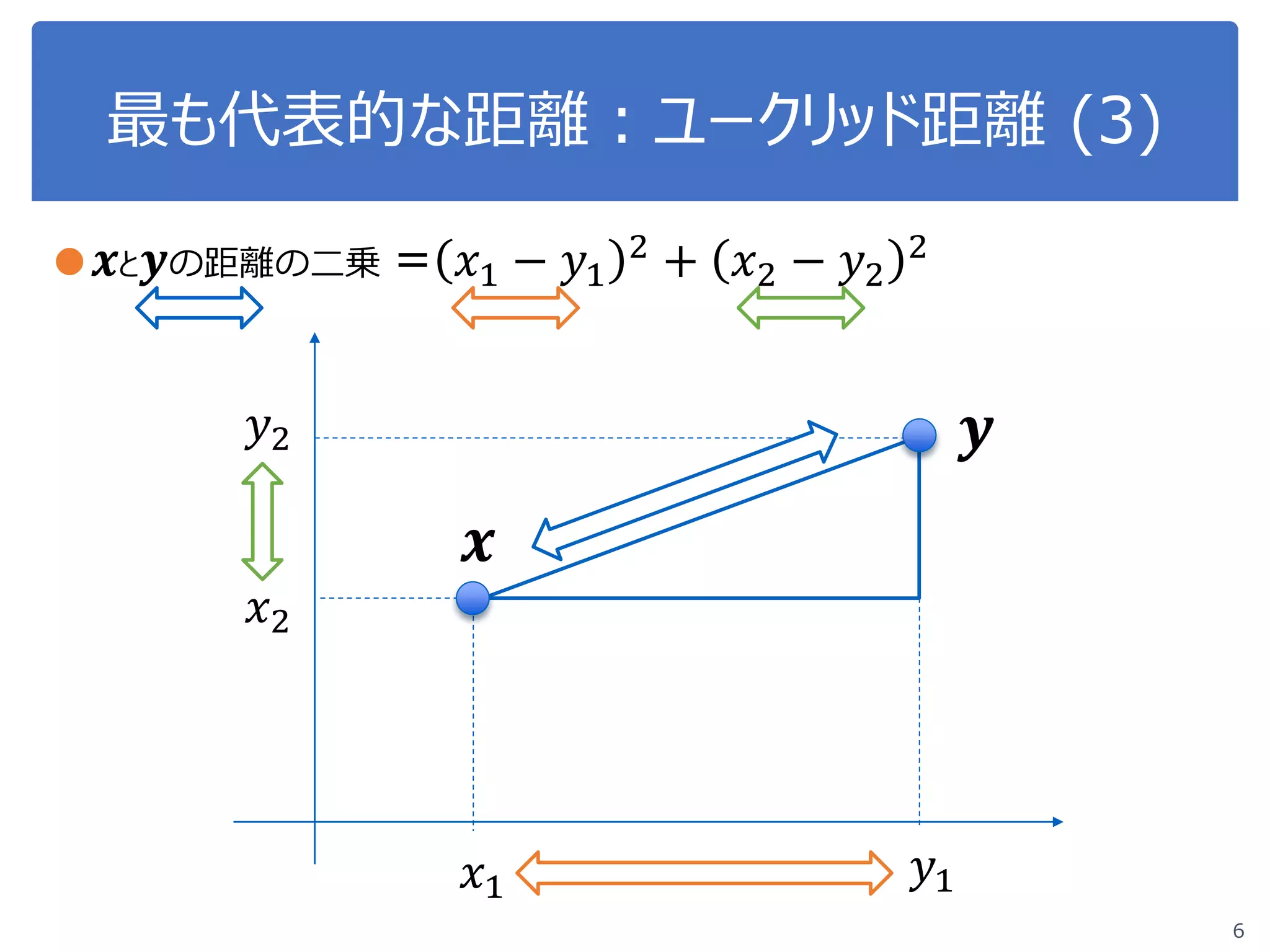
#xとyの距離の二乗:各要素の二乗和
d2 = (x[0]-y[0])**2 + (x[1]-y[1])**2
#平方根
d = math.sqrt(d2)
# 表示
print d
なるべく一般化してプログラムを記載!
これなら、 𝒙𝒙 と 𝒚𝒚 への入力後は同じ](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-12-2048.jpg)
![ユークリッド距離:プログラミング (11)
13
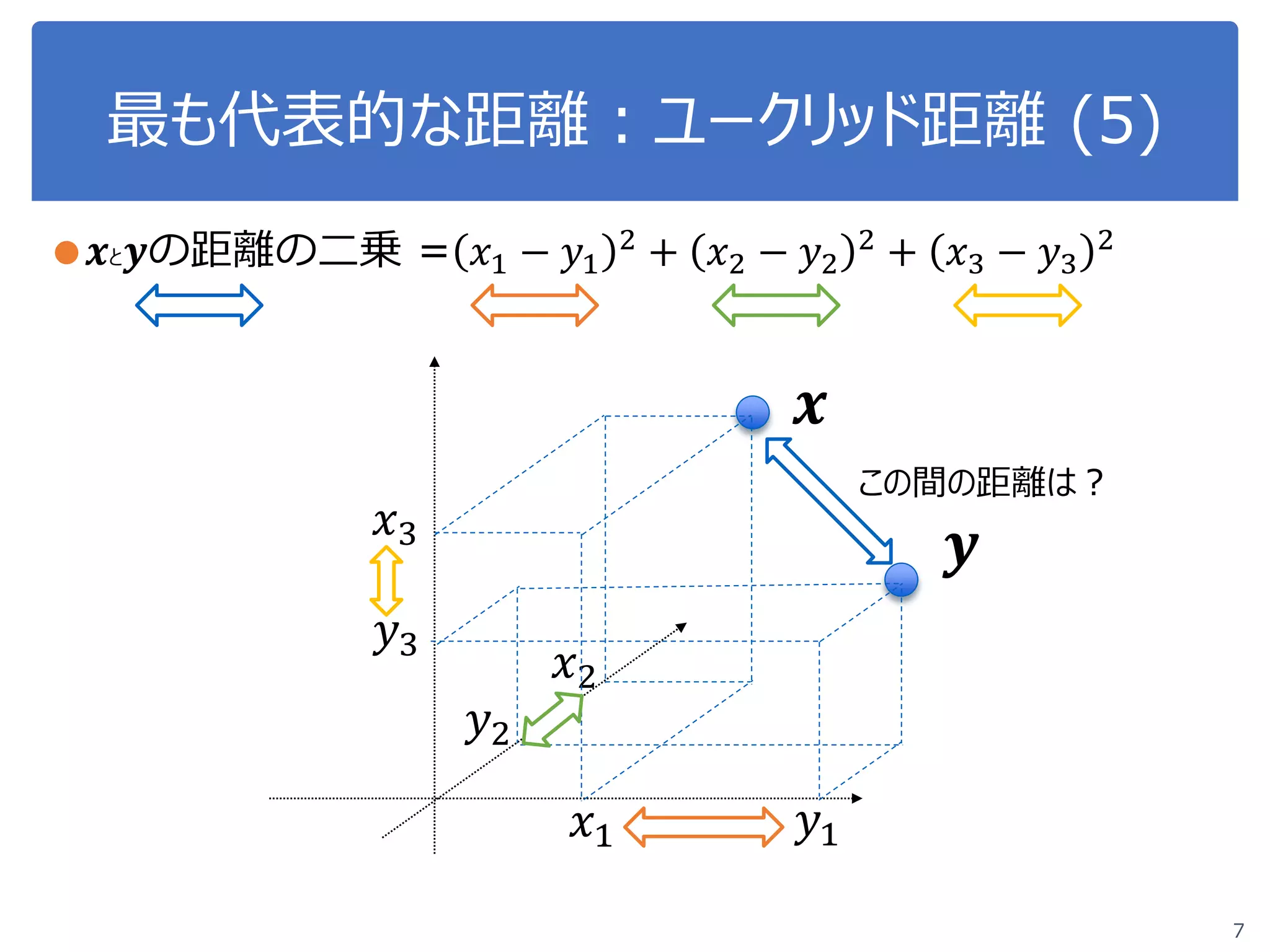
●3次元の場合 𝒙𝒙 =
𝑥𝑥1
𝑥𝑥2
𝑥𝑥3
, 𝒚𝒚 =
𝑦𝑦1
𝑦𝑦2
𝑦𝑦3
#xとyの距離の二乗:各要素の二乗和
d2 = (x[0]-y[0])**2 + (x[1]-y[1])**2
+ (x[2]-y[2])**2
#平方根
d = math.sqrt(d2)
# 表示
print d
次元が変わると、プログラムが変わってしまった
⇒1000次元だと、1000個分の要素を書かないといけない?](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-13-2048.jpg)
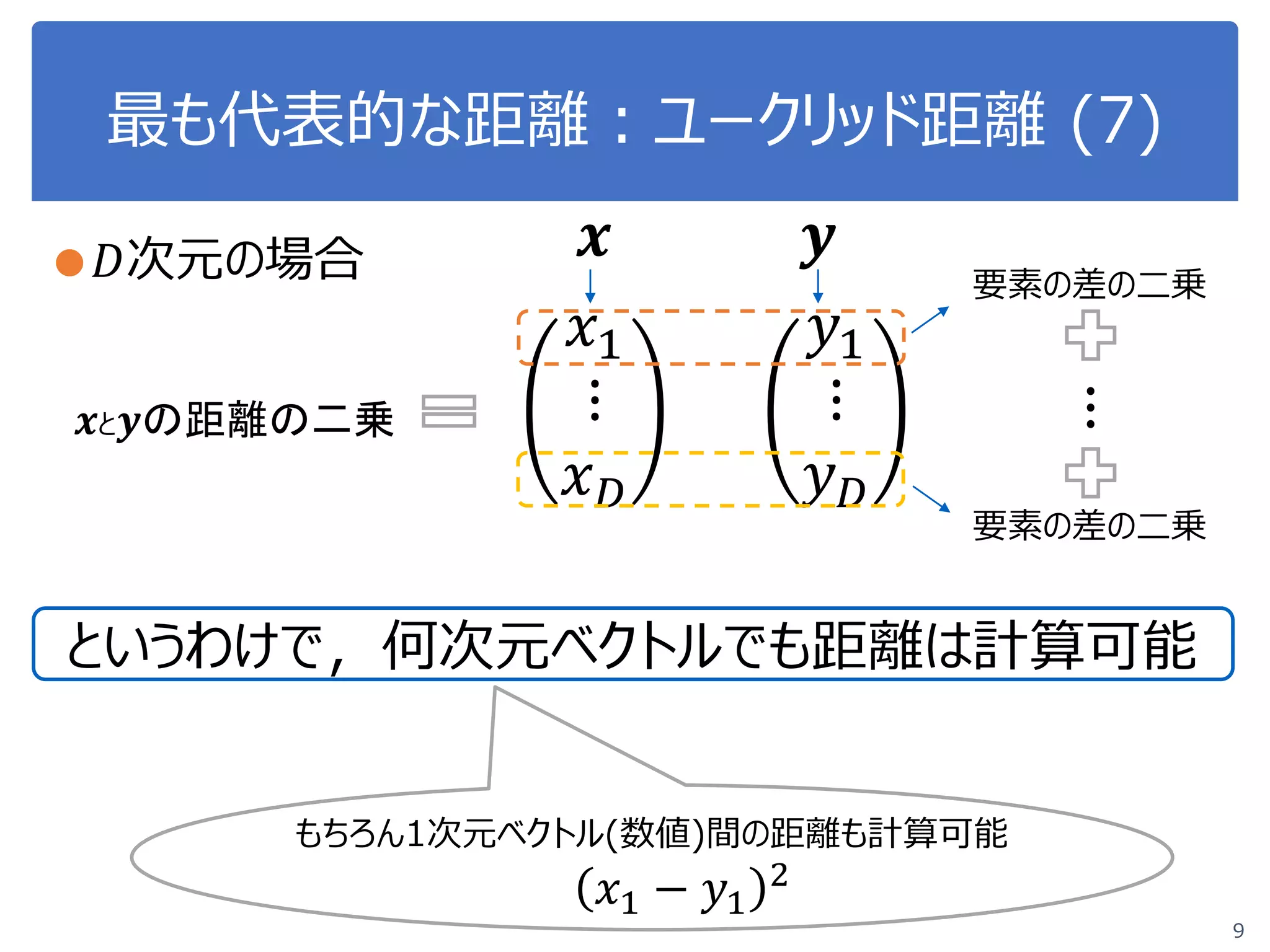
![ユークリッド距離:プログラミング (12)
14
●N次元の場合 𝒙𝒙 =
𝑥𝑥1
⋮
𝑥𝑥𝑁𝑁
, 𝒚𝒚 =
𝑦𝑦1
⋮
𝑦𝑦3
#xとyの距離の二乗:各要素の二乗和
for ii in range(len(x)):
d2 += (x[ii]-y[ii])**2
#平方根
d = math.sqrt(d2)
# 表示
print d
何次元になっても、同じプログラムで表記できる。
⇒関数にしておくと、繰り返し簡単に使える。](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-14-2048.jpg)
![ユークリッド距離:プログラミング (13)
15
import numpy
#xとyの定義
x = numpy.array([60,180])
Y = numpy.array([60,150])
#xとyの距離の計算
d = numpy.linalg.norm(x-y)
実は、pythonに関数が用意されている。
Webで調べて既にあるものを利用するのも
プログラミングの大事なスキル!](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-15-2048.jpg)

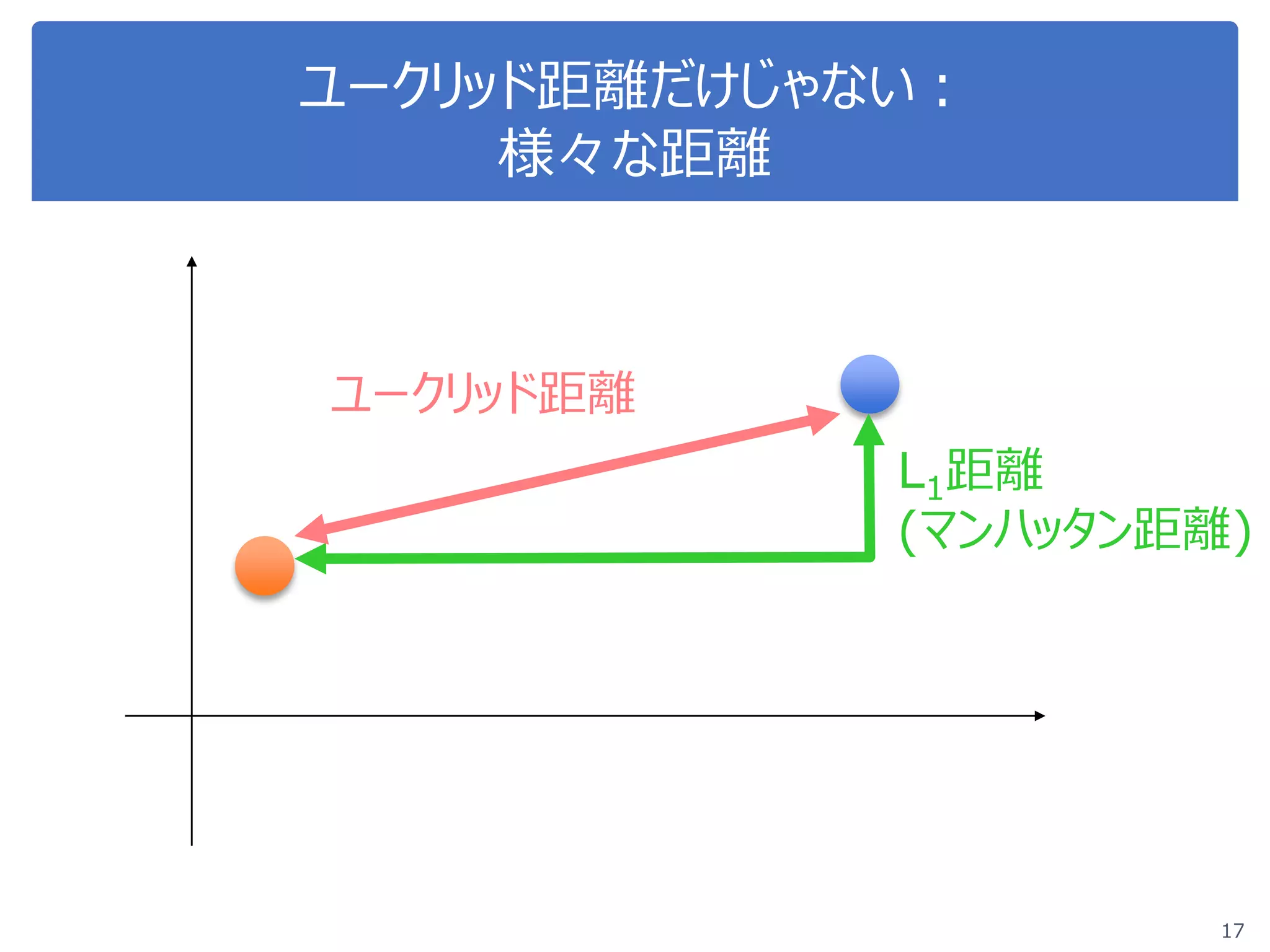

![マンハッタン距離:プログラミング (7)
19
●N次元の場合 𝒙𝒙 =
𝑥𝑥1
⋮
𝑥𝑥𝑁𝑁
, 𝒚𝒚 =
𝑦𝑦1
⋮
𝑦𝑦3
for ii in range(len(x)):
d2 += numpy.abs(x[ii]-y[ii])
# 表示
print d
𝒙𝒙と 𝒚𝒚の距離= 𝑥𝑥1 − 𝑦𝑦1 + ⋯ + 𝑥𝑥𝑁𝑁 − 𝑦𝑦𝑁𝑁
各要素の差の絶対値の和
絶対値](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-19-2048.jpg)
![マンハッタン距離:プログラミング (7)
20
import numpy
#xとyの定義
x = numpy.array([60,180])
Y = numpy.array([60,150])
#xとyの距離の計算
d = numpy.linalg.norm(x-y, 1)
こちらも、pythonに関数が用意されている。](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-20-2048.jpg)
![練習1: 距離
●ユークリッド距離(任意の次元)を計算する関数を自身で定義して、
下記のベクトル間のユークリッド距離を求めよ
●例1)A=[10,8], B=[5,3]
●例2)A=[10,8,3], B=[5,3,7]
●numpyのデフォルトの関数を実行して結果が同じか比較しよう
●マンハッタン距離(任意の次元)を計算する関数を自身で定義して、
上記のベクトル間のマンハッタン距離を求めよ
21](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-21-2048.jpg)

![分布の可視化
●csvファイル” height_weight.csv”を読み込み、「横
軸:身長、縦軸:体重」としてプロットして、分布の形状を
確かめよう。点Aを別の色で表示しよう。
plt.scatter(vlist[:,0], vlist[:,1],c='blue',marker='o',s=30)
plt.scatter(A[0], A[1],c=‘red’,marker=‘+’,s=100)
色 マーカー
の形
マーカー
のサイズ](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-23-2048.jpg)
![距離の可視化(1)
●A=(180,75)からの各点へのユークリッド距離をそれぞれ
算出し、最も距離が近い順に並び替えて、距離に応じて色
を変えて表示
# compute distances
A = np.array([180,75])
dlist = []
for row in vlist:
d = np.linalg.norm(A-row)
dlist.append(d)
# 距離が短い順に並び替え
sinds = np.argsort(dlist)[::-1]](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-24-2048.jpg)
![距離の可視化(2)
●距離に応じて色を変えて表示
# visualize
import matplotlib.cm as cm
count = 0
# 距離の近い順にプロット
for i in sinds:
row = vlist[i]
# 並び順に応じて色を決定
c = cm.hot(count/len(vlist))
# 決定した色を指定してプロット
plt.scatter(row[0],row[1],color=c)
count += 1
# 点Aの可視化
plt.scatter(A[0], A[1], c=‘green’,
marker=‘+’, s=60)](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-25-2048.jpg)





![正規化相関:プログラミング
32
cos 𝜃𝜃 =
𝒙𝒙 � 𝒚𝒚
𝒙𝒙 𝒚𝒚
正規化相関
import numpy as np
#xとyの定義
x = np.array([60,180])
y = np.array([60,150])
#コサイン類似度
D = np.dot(x,y); # 内積
xd = np.linalg.norm(x); #||x||
yd = np.linalg.norm(y); #||y||
C = D/(xd*yd); # コサイン類似度
print C # 表示](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-32-2048.jpg)

![練習4:類似度
●ベクトル間の正規化相間(類似度)を計算する関数を自身で定義
して、下記のベクトル間の類似度と距離を求めよ
●例1)A=[17,16], B=[5,3], C=[4,4]
•A-B、B-C、C-A間についてそれぞれ求めよう
●点A,B、Cへ原点から線を引いて可視化してみよう。
可視化した点の距離と角度を見て、類似度と距離の違いを考えてみ
よう
34](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-34-2048.jpg)





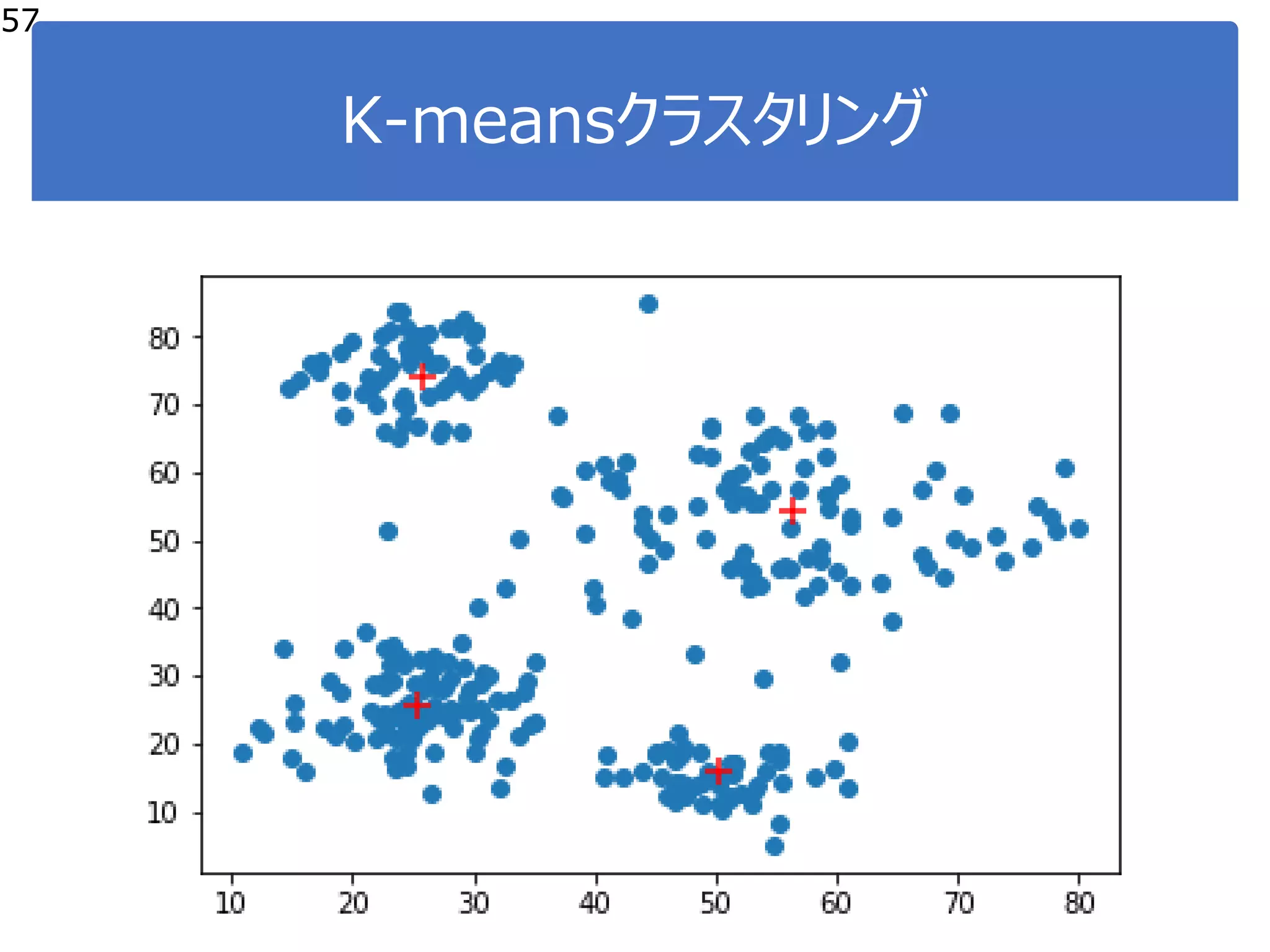
![K-means:プログラミング
45
●ステップ0:
●データ入力
●クラスタ数の決定
import csv
#データの入力
f = open(‘data.csv’,’rb’)
Reader = csv.reader(f)
vlist = []
for row in Reader:
vlist.append([float(row[0]),
float(row[1])])
vlist = np.array(vlist)
f.close()
#k(クラスタ数)の決定
K = 4;](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-45-2048.jpg)
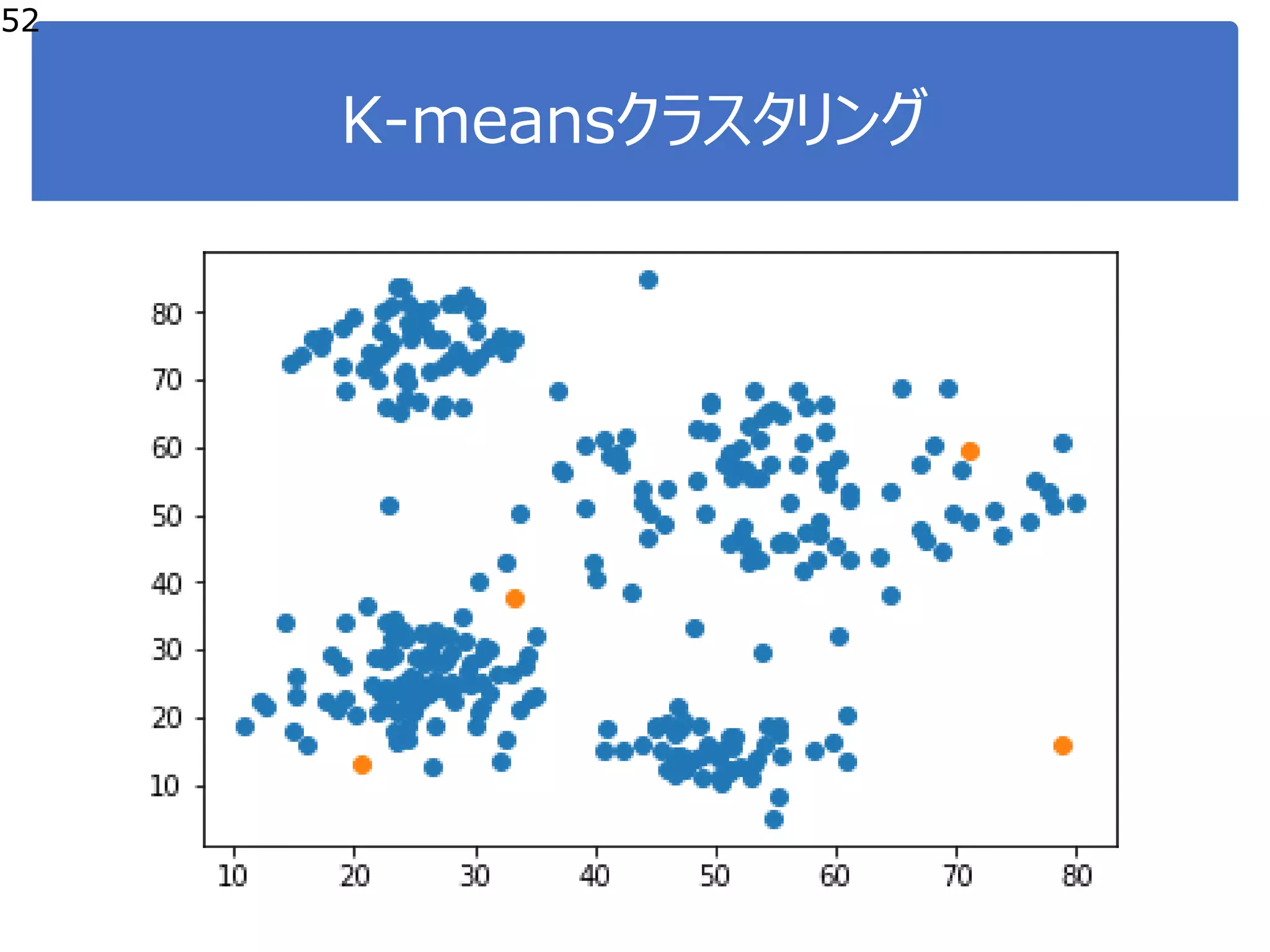
![K-means:プログラミング
46
●ステップ1:
●初期代表点の決定(ランダム)
#random値の範囲決定
a = np.min(vlist[:,0])
b = np.max(vlist[:,0])
c = np.min(vlist[:,1])
d = np.max(vlist[:,1])
#ランダムに決定
Clist = np.c_[(b-a)*np.random.rand(K) + a,
(d-c)*np.random.rand(K) + c]
plt.scatter(vlist[:,0], vlist[:,1])
plt.scatter(Clist[:,0], Clist[:,1])](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-46-2048.jpg)

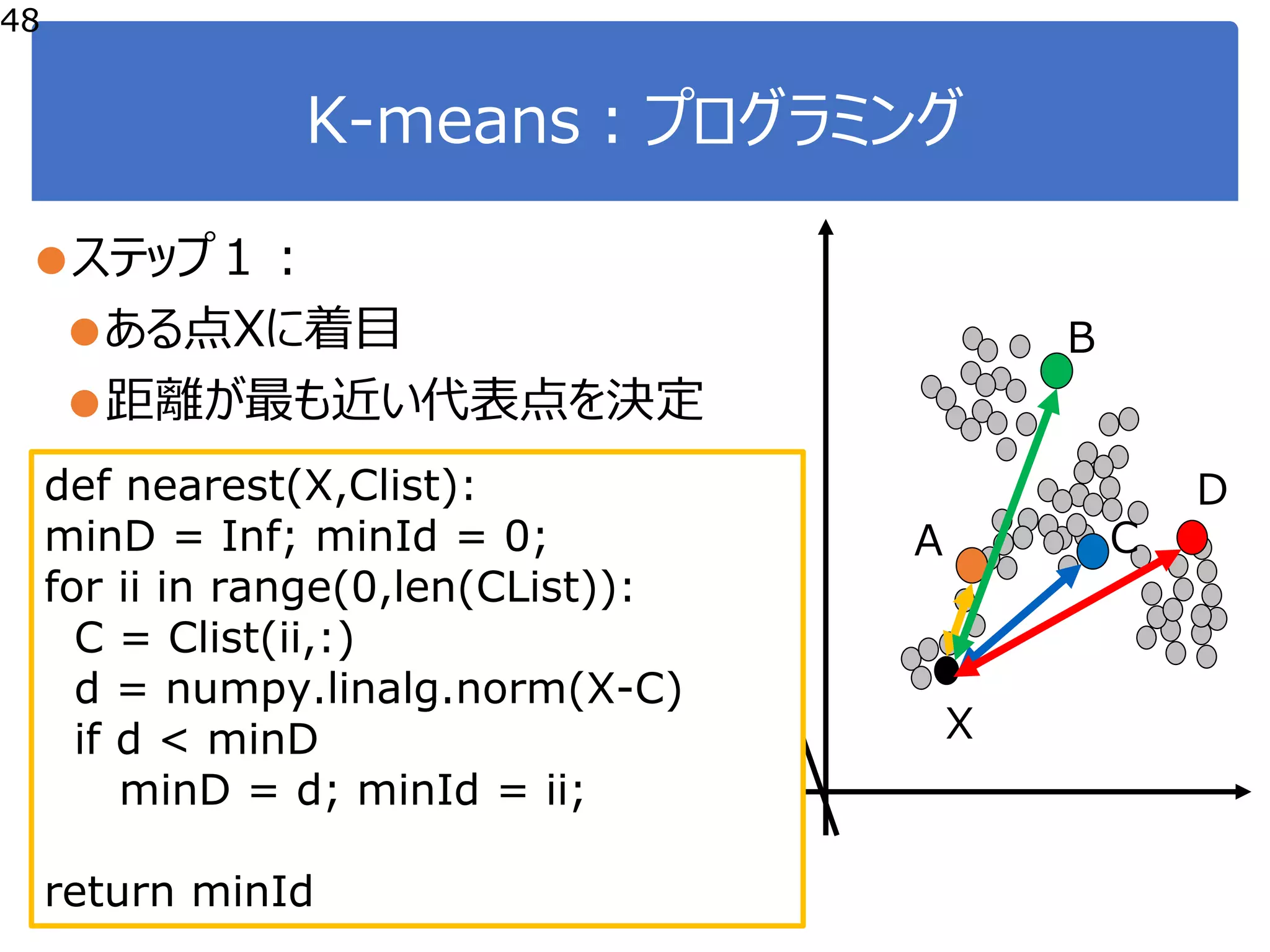
![K-means:プログラミング
49
●ステップ1:
●全ての点で代表点を決定
A
C
B
D
X
def selectCluster(vList,Clist):
cIList = [];
for row in vList:
cIList.append(nearest(row,Clist))
Return cIList](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-49-2048.jpg)
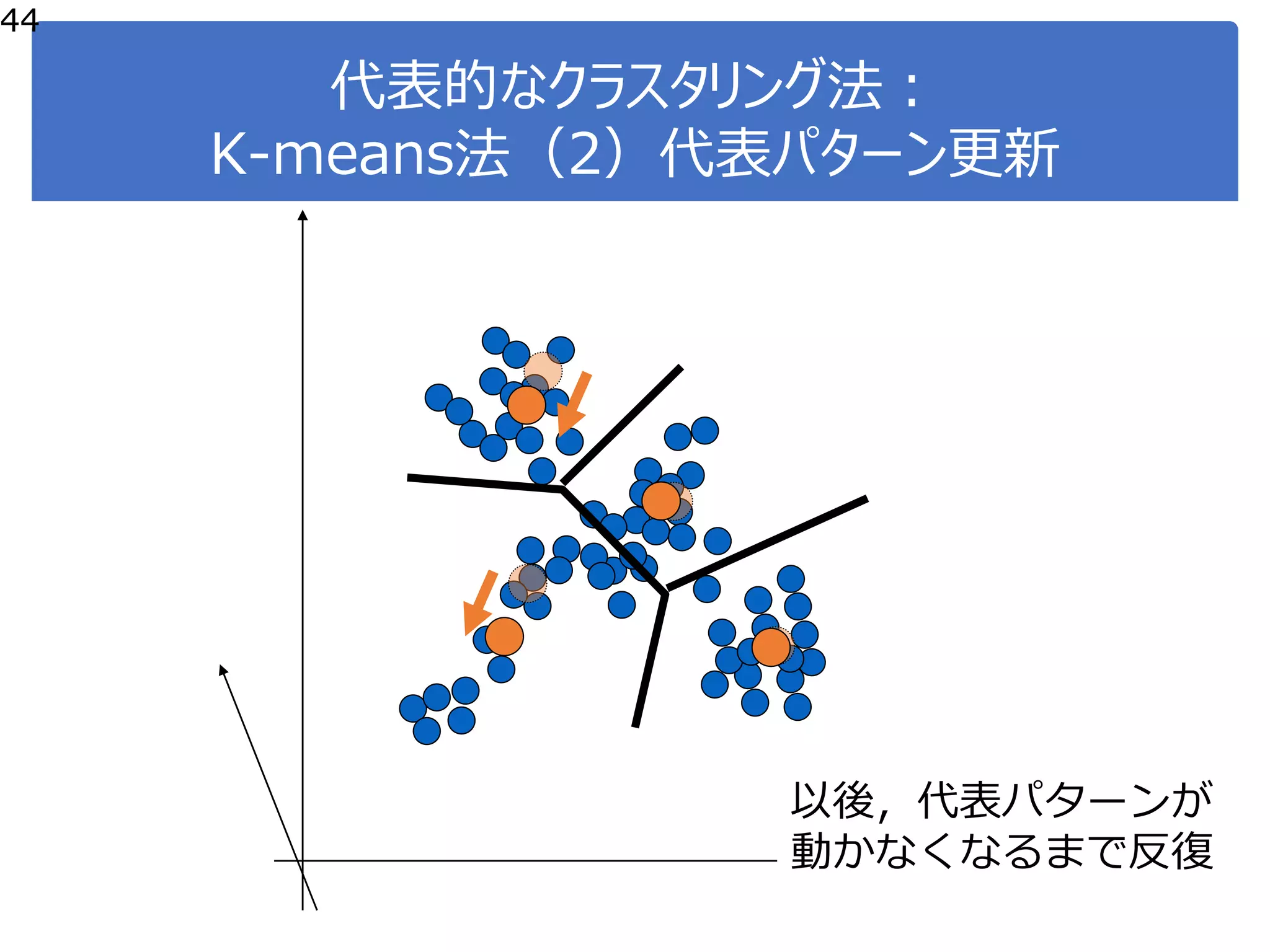
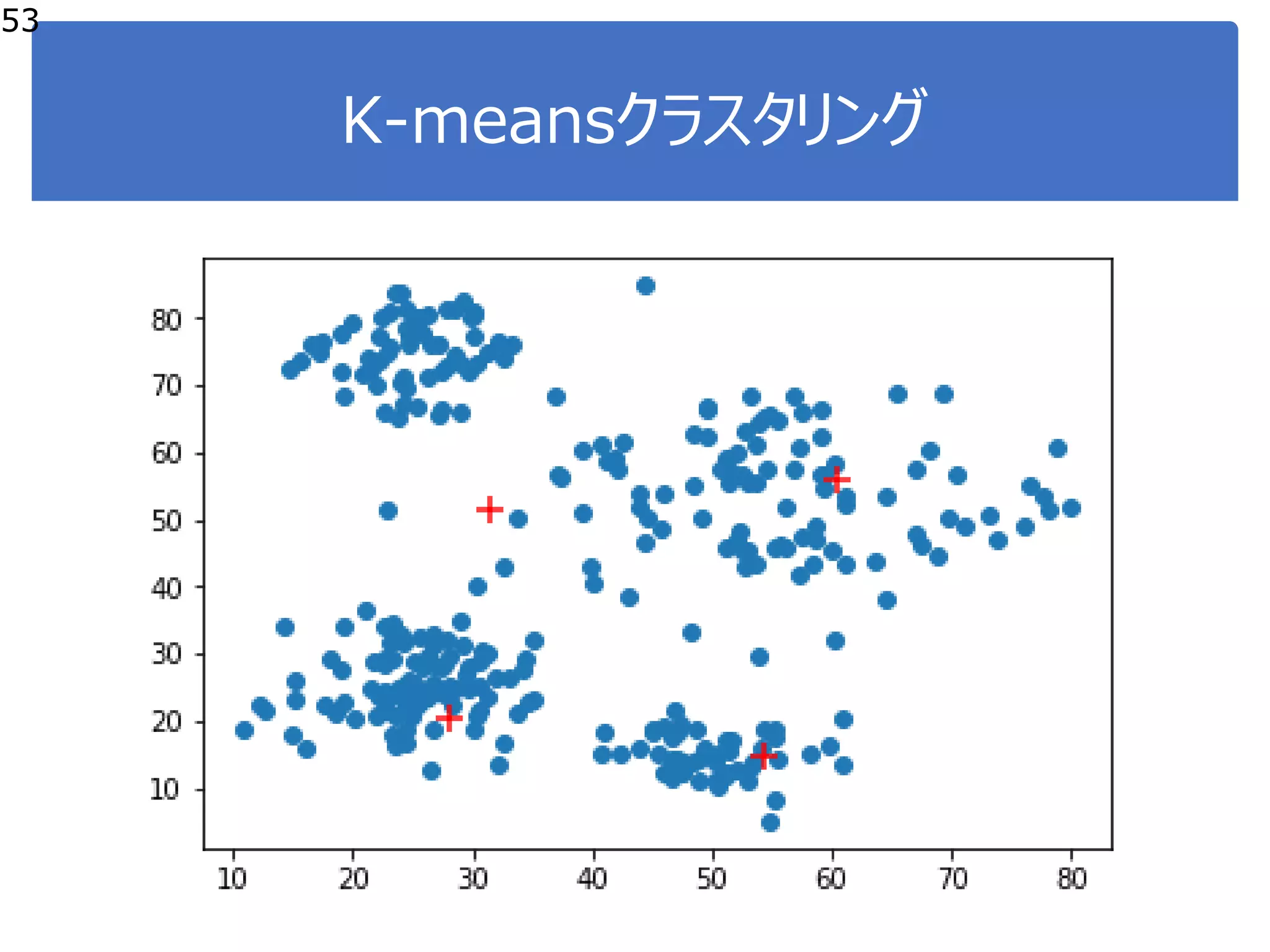
![K-means:プログラミング
50
●ステップ2:代表点を更新
●各クラスタの支持者群の平均値
を代表点とする。
A
C
B
D
X
def updateCenter(vlist,CIList):
CList = []
for k in range(K):
Z = []
for j in range(len(CIList)):
if CIList[j] == k:
Z.append(vlist[j])
mc = np.mean(Z,0)
CList.append(mc)
return CList](https://image.slidesharecdn.com/course20180529-180605044445/75/DS-Exercise-Course-4-50-2048.jpg)





































![[DL輪読会]Wasserstein GAN/Towards Principled Methods for Training Generative Adv...](https://cdn.slidesharecdn.com/ss_thumbnails/wgan-1-170224021826-thumbnail.jpg?width=640&height=640&fit=bounds)







































