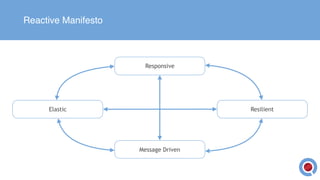
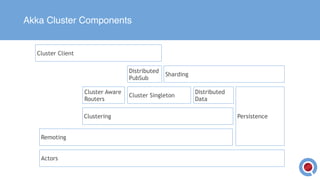
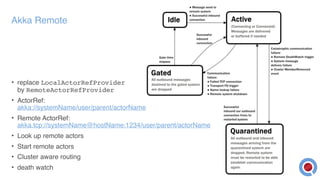
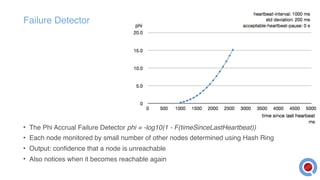
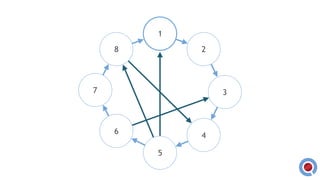
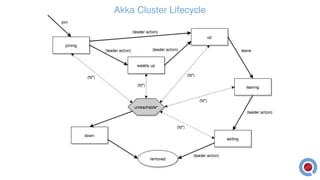
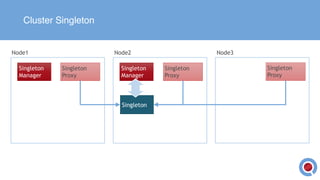
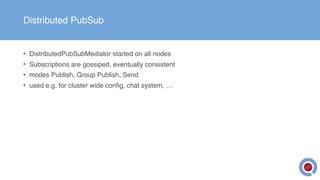
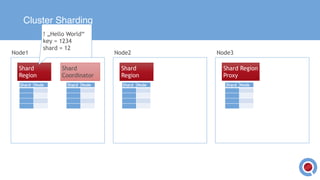
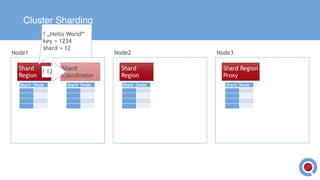
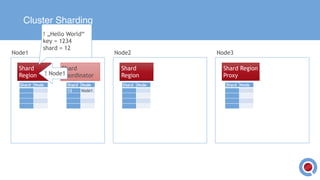
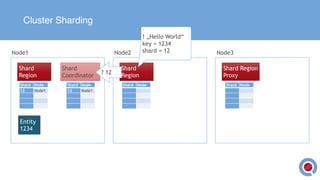
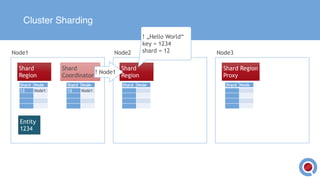
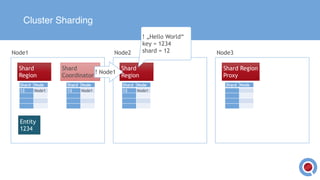
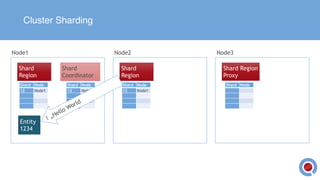
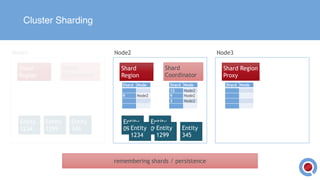
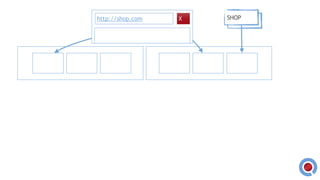
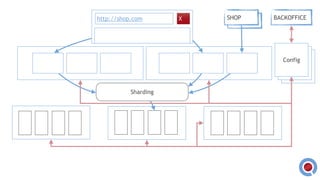
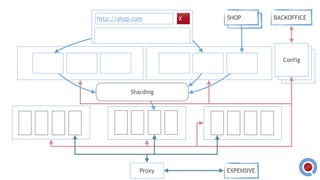
The document discusses the implementation and management of an Akka cluster in production for applications like online shopping and fraud detection across various industries. It outlines key components such as clustering, actor model, sharding, and data persistence, emphasizing the importance of resilience and responsiveness through effective failover strategies. It also shares insights and lessons learned regarding configuration, performance, and operational caveats in a distributed architecture.




![case class Gossip(
members: immutable.SortedSet[Member], // sorted set of members with their status, sorted by address
overview: GossipOverview = GossipOverview(),
version: VectorClock = VectorClock()) // vector clock version
case class GossipOverview(
seen: Set[UniqueAddress] = Set.empty,
reachability: Reachability = Reachability.empty)
case class VectorClock(
versions: TreeMap[VectorClock.Node, Long] = TreeMap.empty[VectorClock.Node, Long]) {
/**
* Compare two vector clocks. The outcome will be one of the following:
* <p/>
* {{{
* 1. Clock 1 is SAME (==) as Clock 2 iff for all i c1(i) == c2(i)
* 2. Clock 1 is BEFORE (<) Clock 2 iff for all i c1(i) <= c2(i)
* and there exist a j such that c1(j) < c2(j)
* 3. Clock 1 is AFTER (>) Clock 2 iff for all i c1(i) >= c2(i)
* and there exist a j such that c1(j) > c2(j).
* 4. Clock 1 is CONCURRENT (<>) to Clock 2 otherwise.
* }}}
*/
def compareTo(that: VectorClock): Ordering = {
compareOnlyTo(that, FullOrder)
}
}](https://image.slidesharecdn.com/meetupakkacluster-160826152623/85/Akka-Cluster-in-Production-11-320.jpg)

































































![JavaOne: A tour of (advanced) akka features in 60 minutes [con1706]](https://cdn.slidesharecdn.com/ss_thumbnails/atourofadvancedakkafeaturesin60minutescon1706-160921210355-thumbnail.jpg?width=640&height=640&fit=bounds)





























![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)







