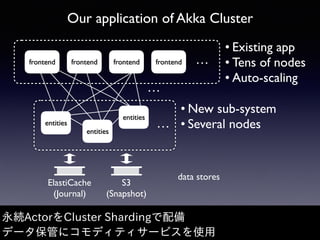
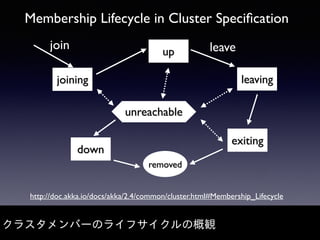
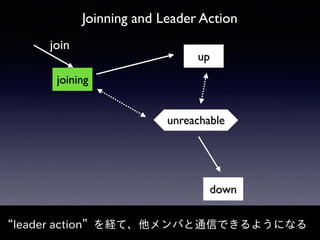
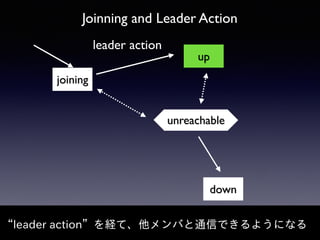
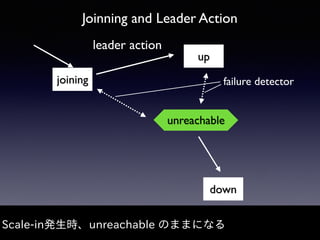
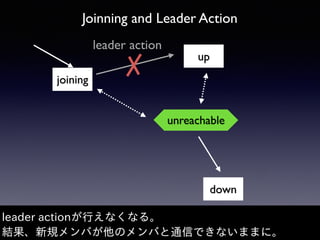
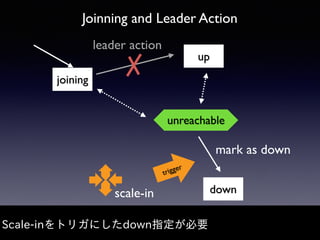
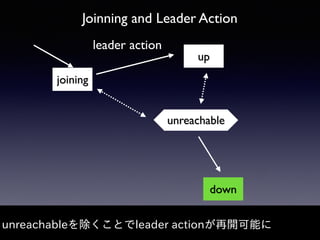
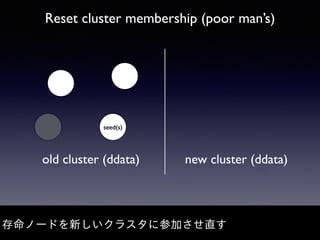
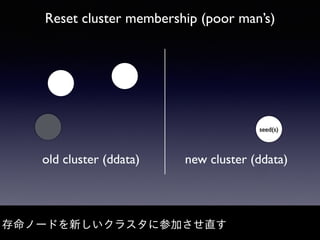
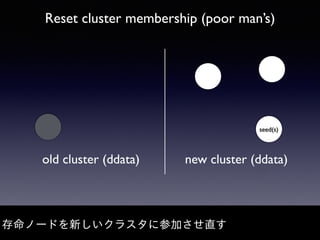
Akka Cluster allows distributing actors across multiple JVMs with no single point of failure. The document discusses challenges faced with unreachable members and journal lifecycles when operating an Akka Cluster application at scale for 10 months. For unreachables, triggering a scale-in to mark nodes as down and automating restarts addressed the issue. Journals stored in Redis required cleanup to avoid inconsistencies, as deleting messages did not remove the highest sequence number. Straying from event sourcing's complete event history model weakened ecosystem support.










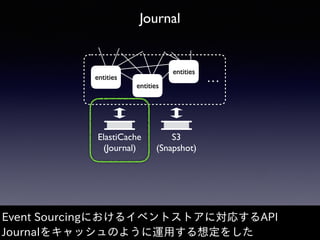

![Event Sourcing and Ecosystem
“it stores a complete history of the events
associated with the aggregates in your domain”
Reference 3: Introducing Event Sourcing, CQRS Journey[CQJ]
本来のイベントストアはイベントの完全な履歴を持つ想定
そこから逸れるとエコシステム(plug-in)のサポートも弱くなる](https://image.slidesharecdn.com/scala-matsuri-2017-ikuo-005-170226123908/85/Akka-Cluster-and-Auto-scaling-24-320.jpg)

![Reference
[CQJ] Exploring CQRS and Event Sourcing, Dominic Betts, Julian
Dominguez, Grigori Melnik, Fernando Simonazzi, Mani Subramanian,
2012, https://msdn.microsoft.com/en-us/library/jj554200.aspx
[PSE] Persistence - Schema Evolution, Akka Documentation, http://
doc.akka.io/docs/akka/2.4/scala/persistence-schema-evolution.html](https://image.slidesharecdn.com/scala-matsuri-2017-ikuo-005-170226123908/85/Akka-Cluster-and-Auto-scaling-26-320.jpg)





















































![5G Explained! A High Level Overview [Introduction]](https://cdn.slidesharecdn.com/ss_thumbnails/5gexplainedahighleveloverview-260119165306-cc137a3e-thumbnail.jpg?width=640&height=640&fit=bounds)












