Download to read offline











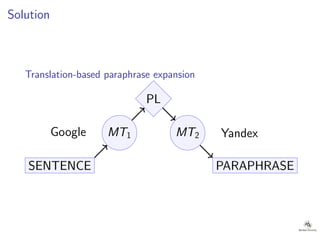







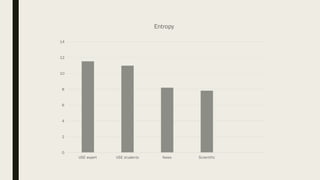
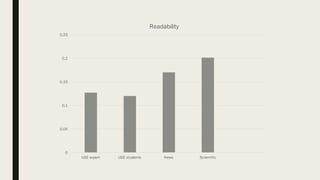
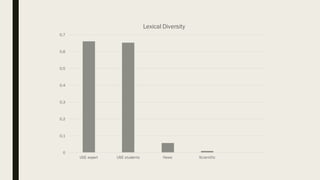
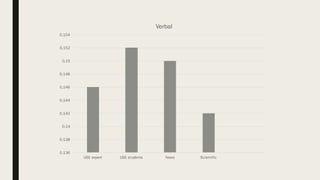
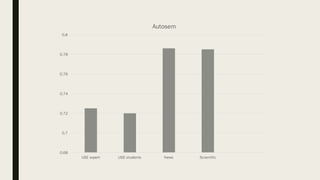
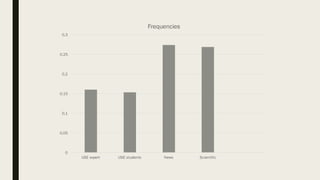



















1. The researcher analyzed quantitative characteristics such as entropy, readability, lexical diversity, frequencies of words, and parts of speech for different text genres including scientific texts, news articles, and student writings. 2. The analysis found that student writings had higher entropy and readability than news articles or scientific texts. News articles had higher lexical diversity and frequencies of common words. 3. To evaluate the accuracy of a developed Old Irish lemmatizer, the researcher applied it to a test corpus of 840 tokens, of which 186 were unknown words. The lemmatizer correctly predicted lemmas for 84 of the unknown words, achieving an accuracy of around 60% for unknown words.


















































































