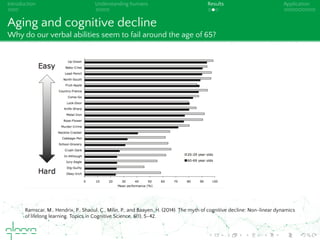
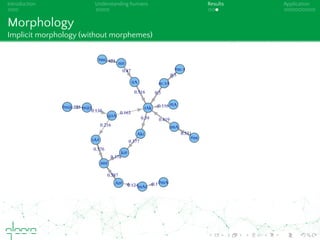
This document discusses cognitive plausibility in learning algorithms, with a focus on natural language processing. It outlines the author's background and motivation, which is to model human learning and communication more accurately. Some key points made include: understanding language acquisition as discriminative learning rather than compositional; explaining features of human language through models like Rescorla-Wagner learning; and how naive discrimination learning can be applied to NLP tasks through an incremental learning algorithm. The document also provides an overview of available NLP tools and limitations in fully achieving language understanding.





















![[Paper Reading] Supervised Learning of Universal Sentence Representations fro...](https://cdn.slidesharecdn.com/ss_thumbnails/paperreadingmt-supervisedlearningofuniversalsentencerepresentationsfromnaturallanguageinferencedata-171216153412-thumbnail.jpg?width=640&height=640&fit=bounds)





























































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)











![7.__Developing_a_Research_Proposal[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/7-260131073037-df92dd7d-thumbnail.jpg?width=640&height=640&fit=bounds)


