Downloaded 22 times




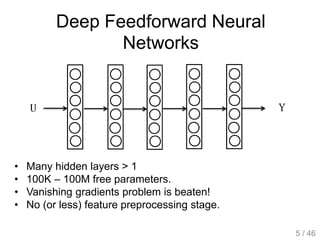


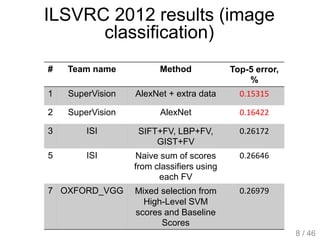

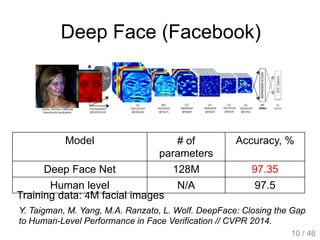



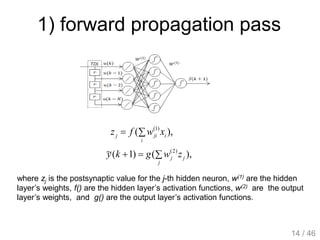














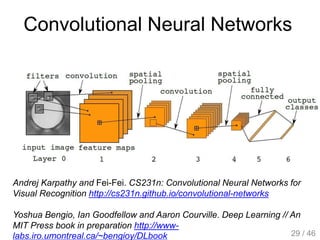




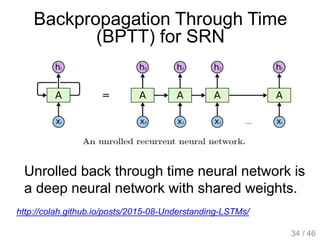
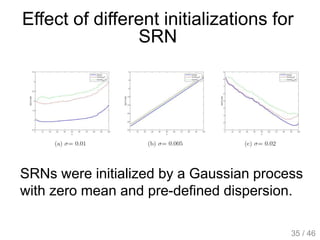
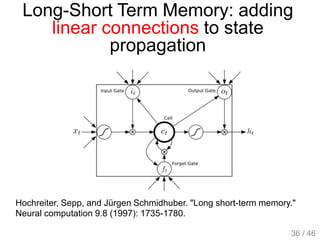












The document provides an overview of deep learning, covering various neural network architectures including deep feedforward neural networks, convolutional neural networks, and recurrent neural networks. It discusses important topics such as the challenges of vanishing gradients, training techniques like backpropagation, and the evolution of models through notable research and datasets like ImageNet. Key advancements in neural network design, performance metrics, and optimization strategies are highlighted throughout the text.




















































































