Downloaded 61 times


















The document provides an overview of the NLP pipeline in machine translation (MT), detailing critical processes such as sentence breaking, tokenization, morphological analysis, and syntactic parsing. It emphasizes the importance of context and semantic analysis in achieving accurate translations, while also highlighting tasks not covered, including discourse phenomena and localization. Additionally, the author, Mārcis Pinnis, shares insights from his research at Tilde, focusing on enhancing language technologies to lower communication barriers.
Introduction to NLP in MT and an overview of relevant tasks and tools.
Mārcis Pinnis introduces his background and research focus on neural machine translation.
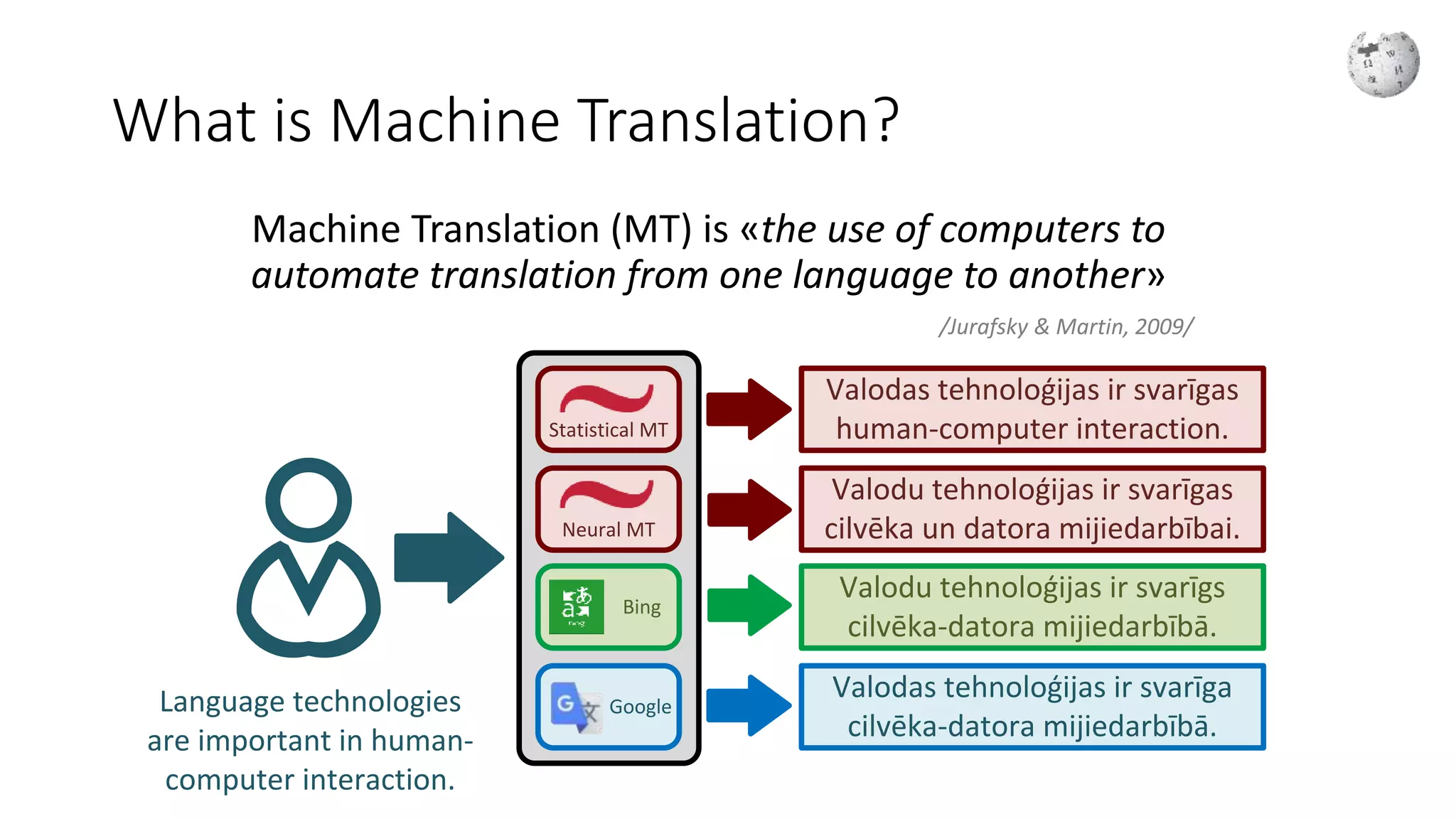
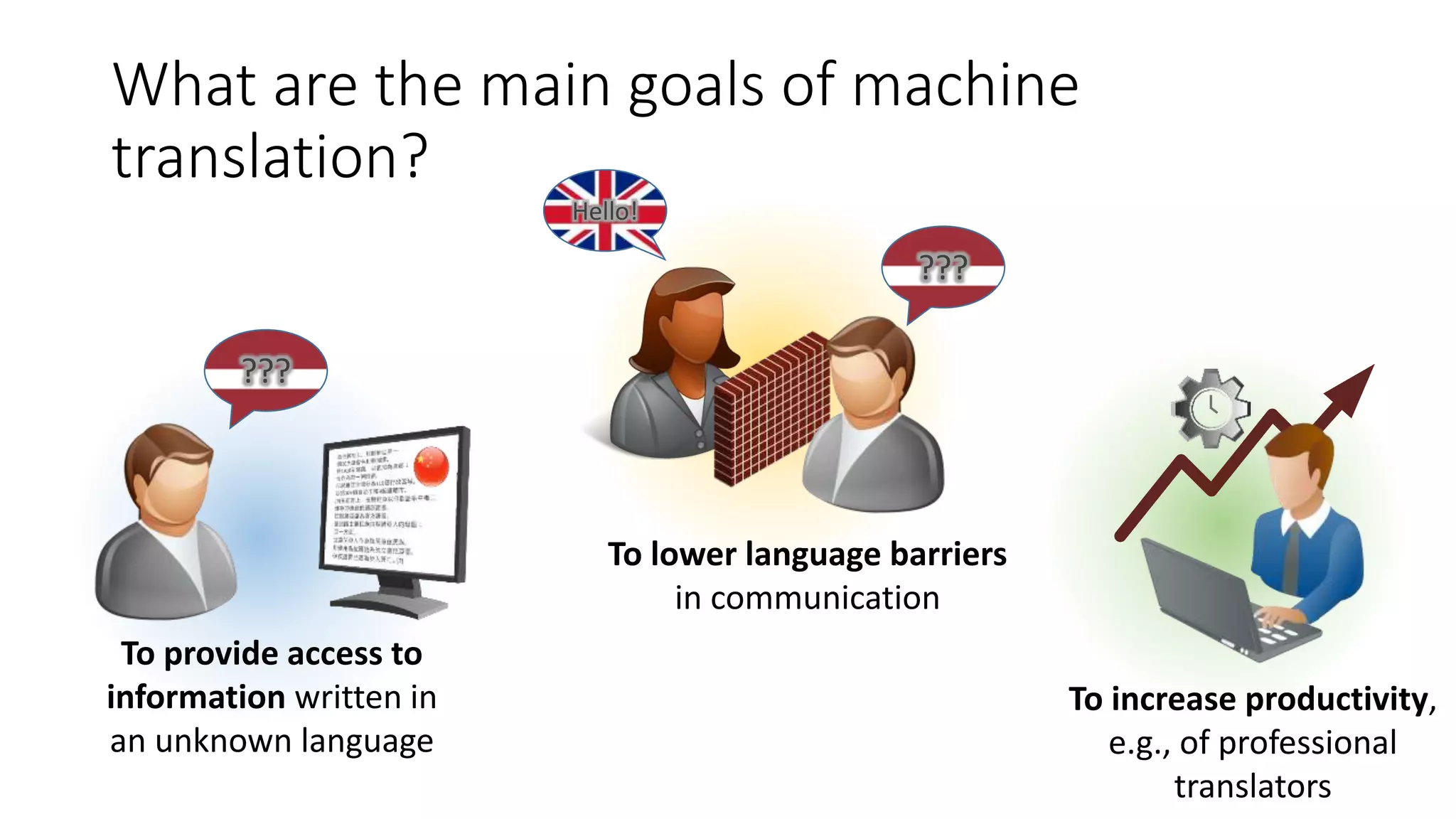
Defines machine translation, its goals, including lowering language barriers and aiding access to information.
Overview of the NLP pipeline and introductory example for translating a text.
Description of sentence breaking and tokenization as initial steps in text processing for MT.
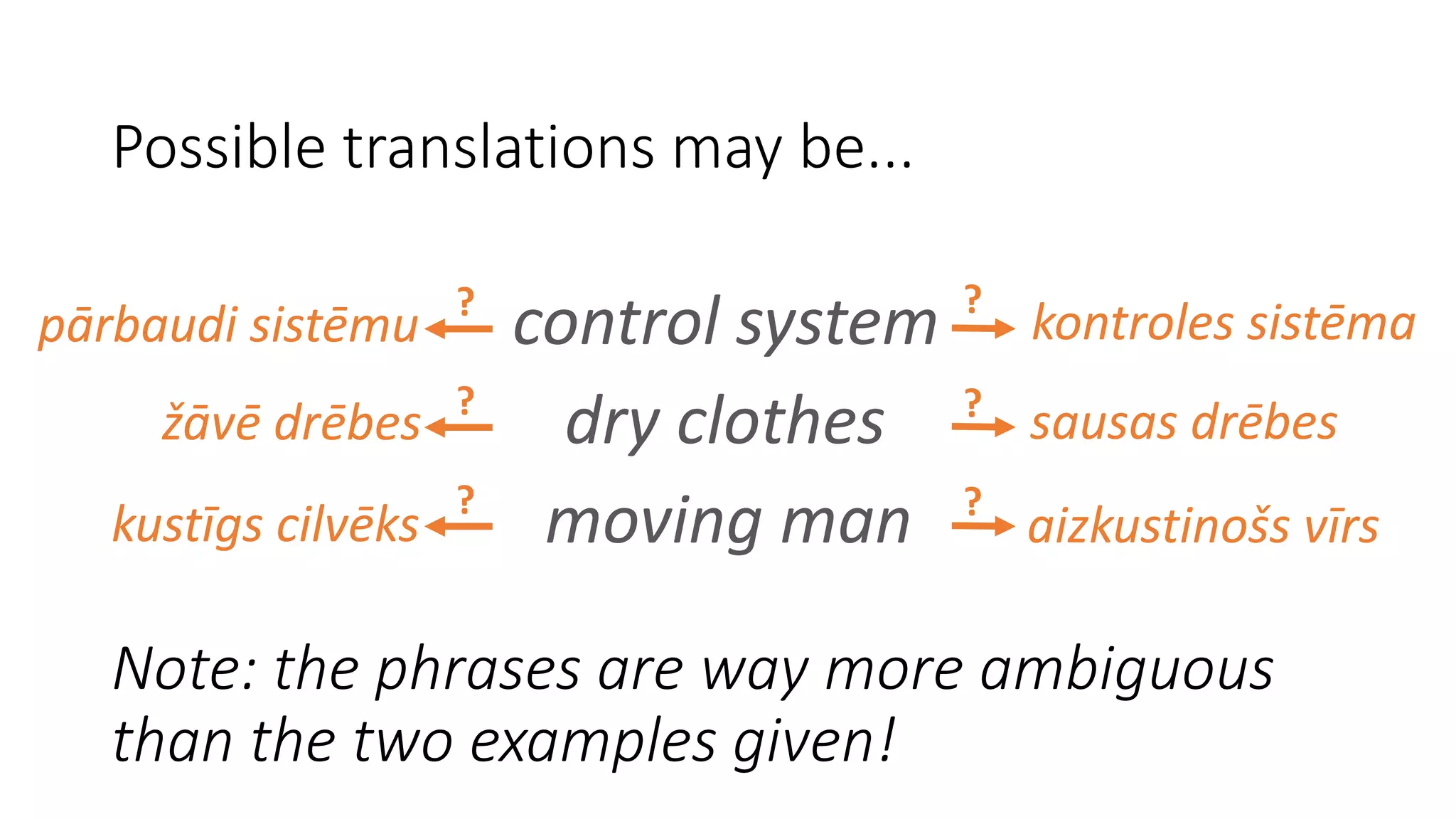
Discussion of ambiguous phrases and their potential translations, emphasizing context.
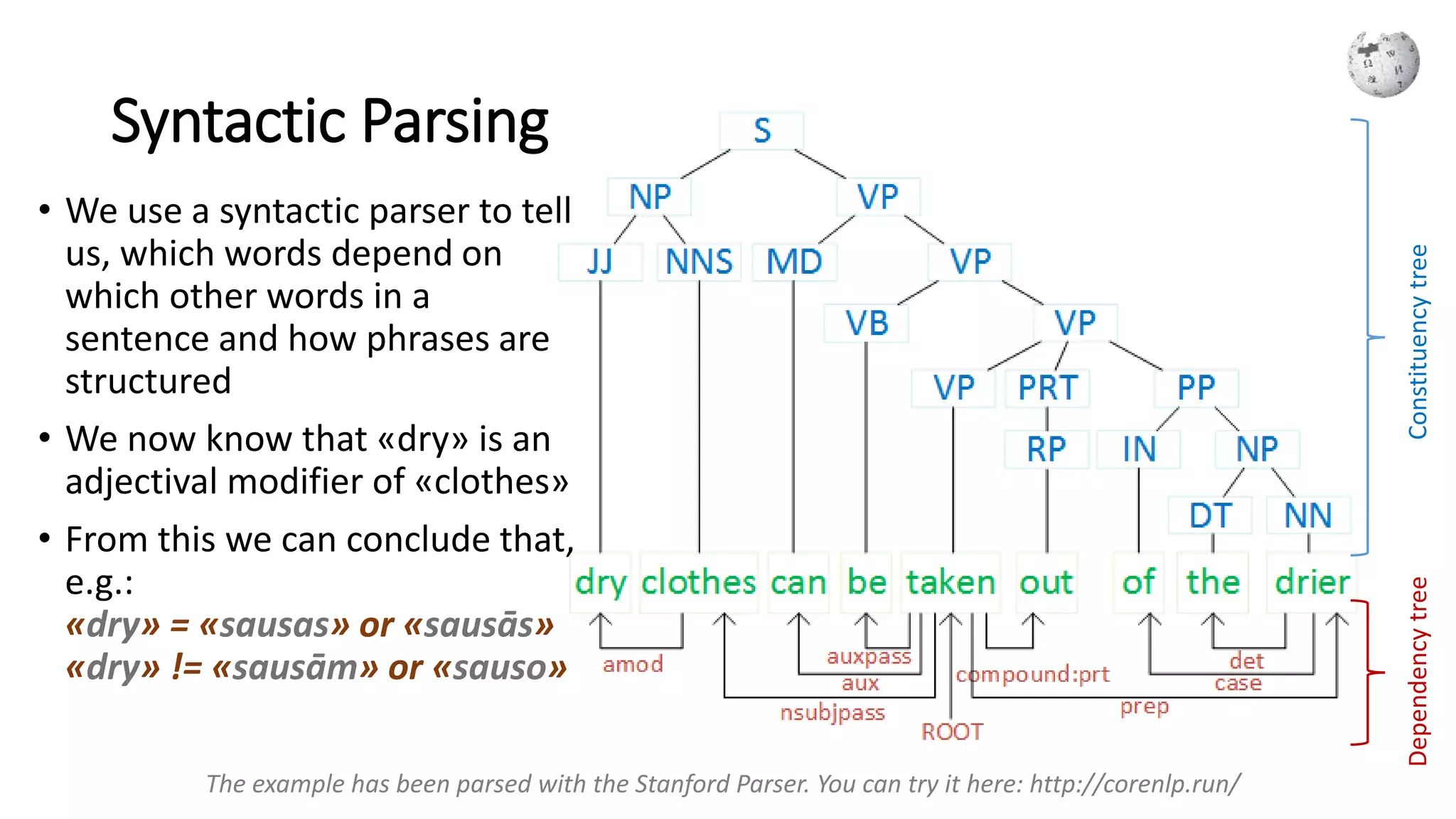
Analysis of word forms and tagging for disambiguation in translation context.
Importance of context in disambiguation, leading to the need for syntactic parsing.
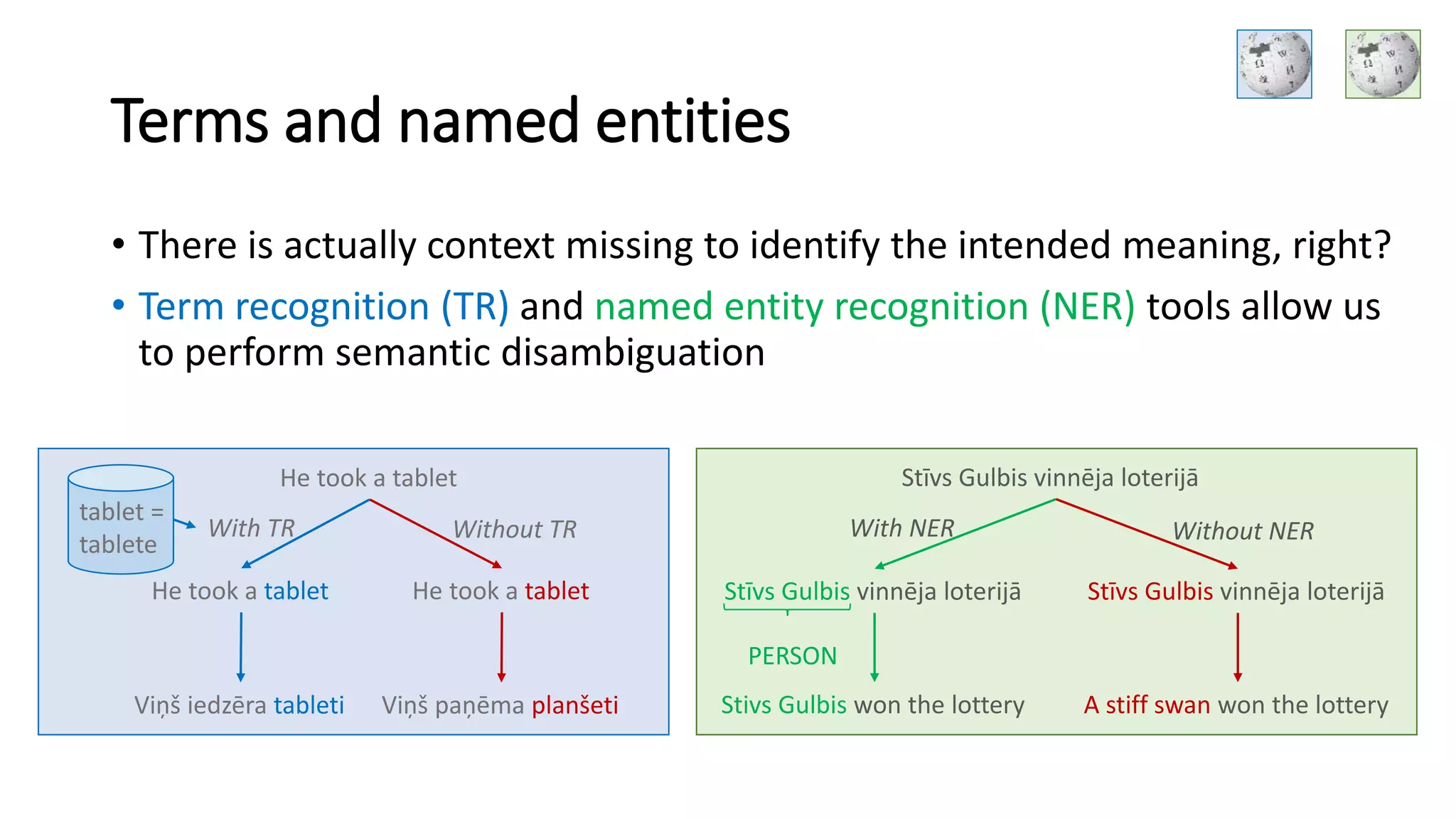
Role of term recognition and named entity recognition in semantic disambiguation.
Overview of semantic parsing and its role in understanding language in translation.
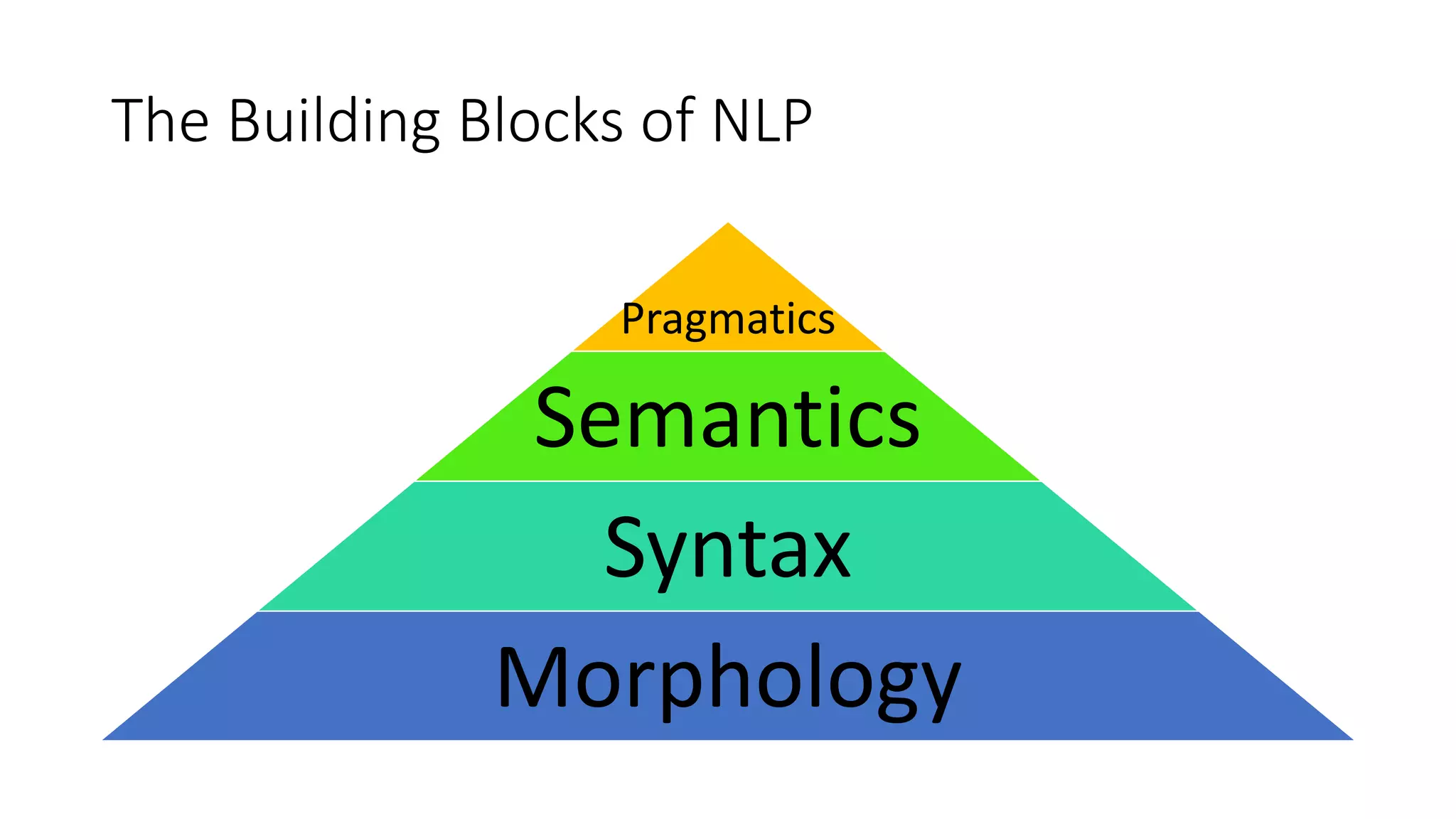
Introduction to key components of NLP: pragmatics, semantics, syntax, morphology.
Exploration of additional NLP tasks beyond basics, enhancing MT capabilities.
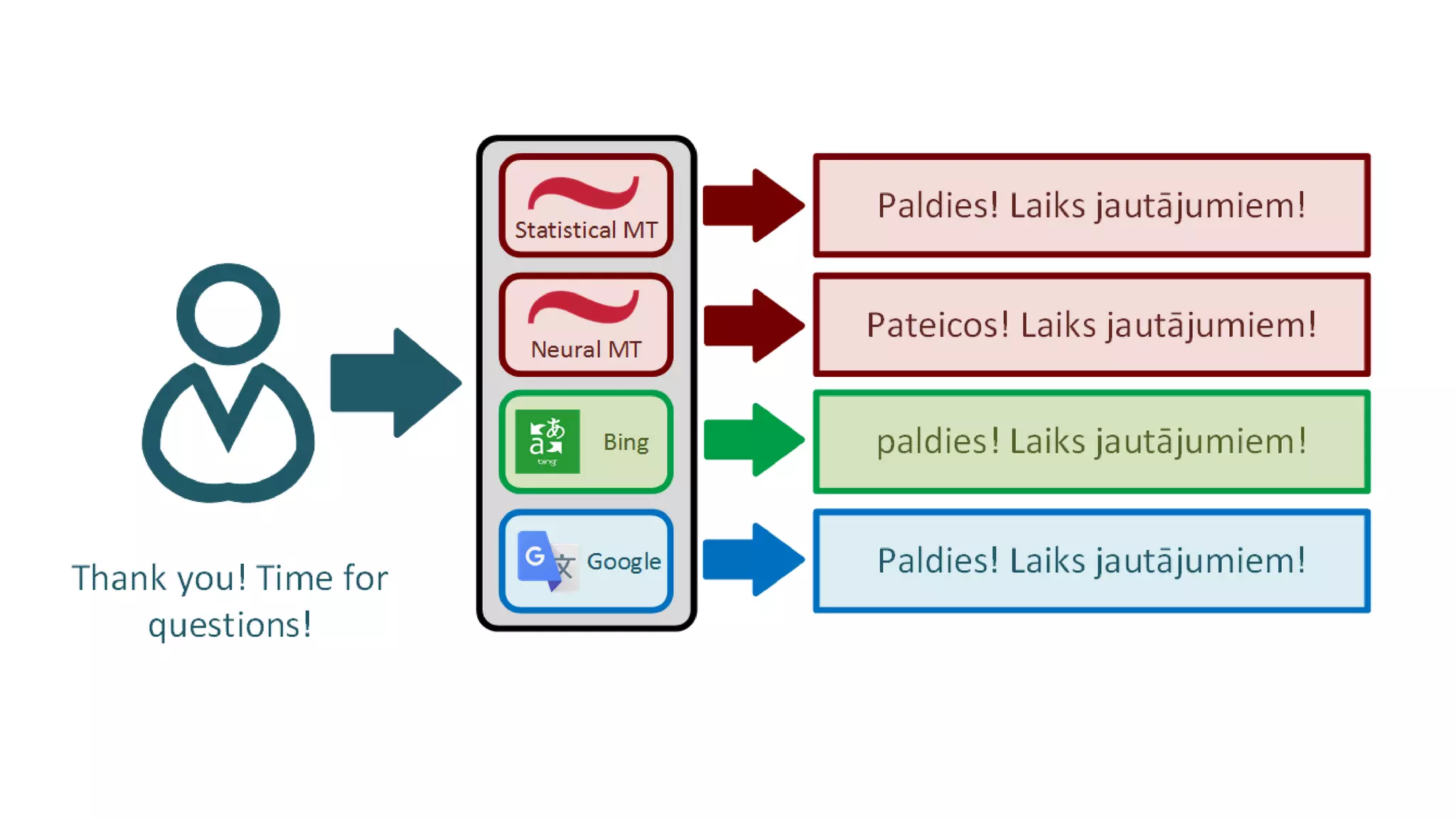
Invitation to try out an NLP demo or explore resources for practical experience in MT.























































































