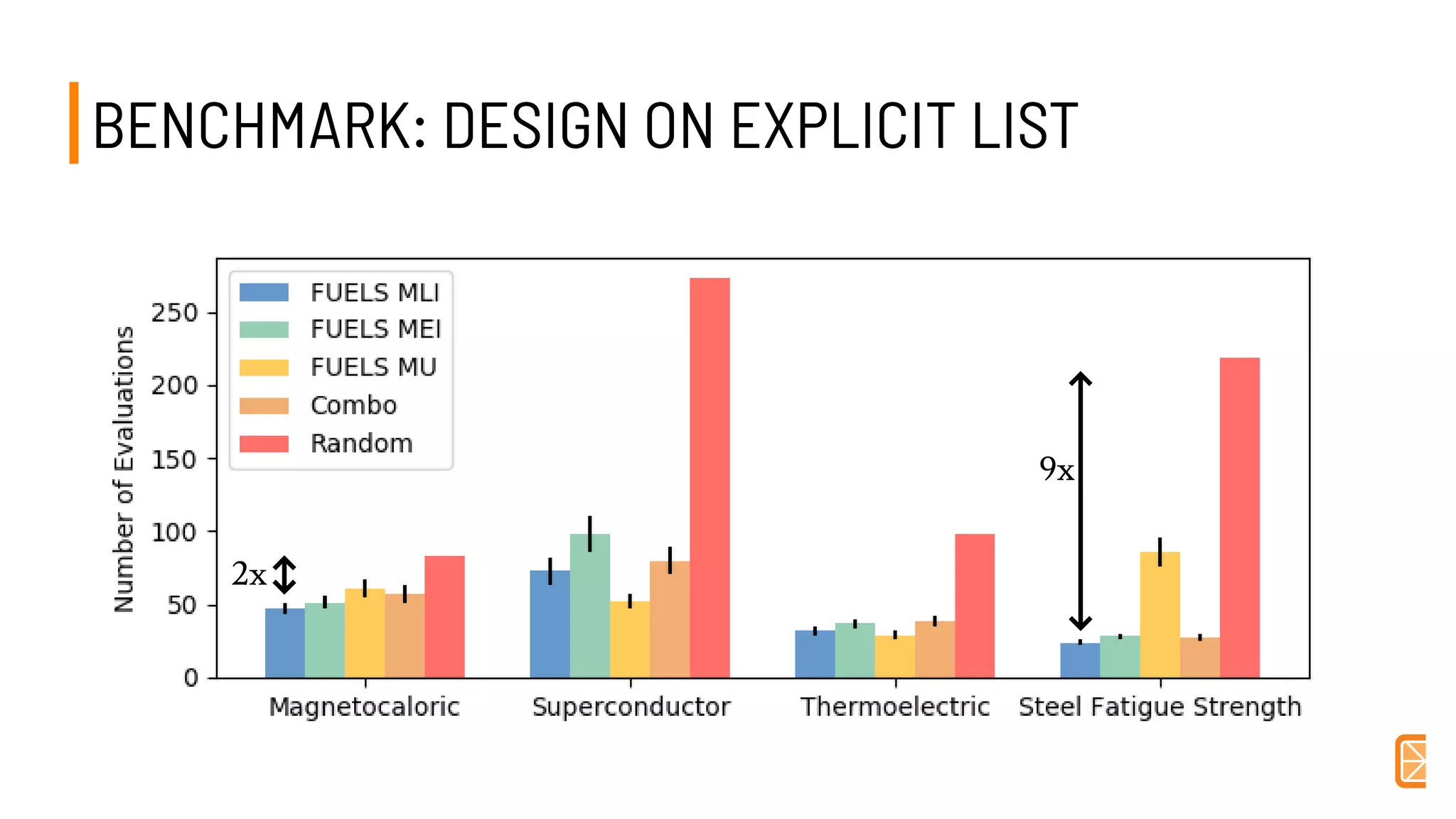
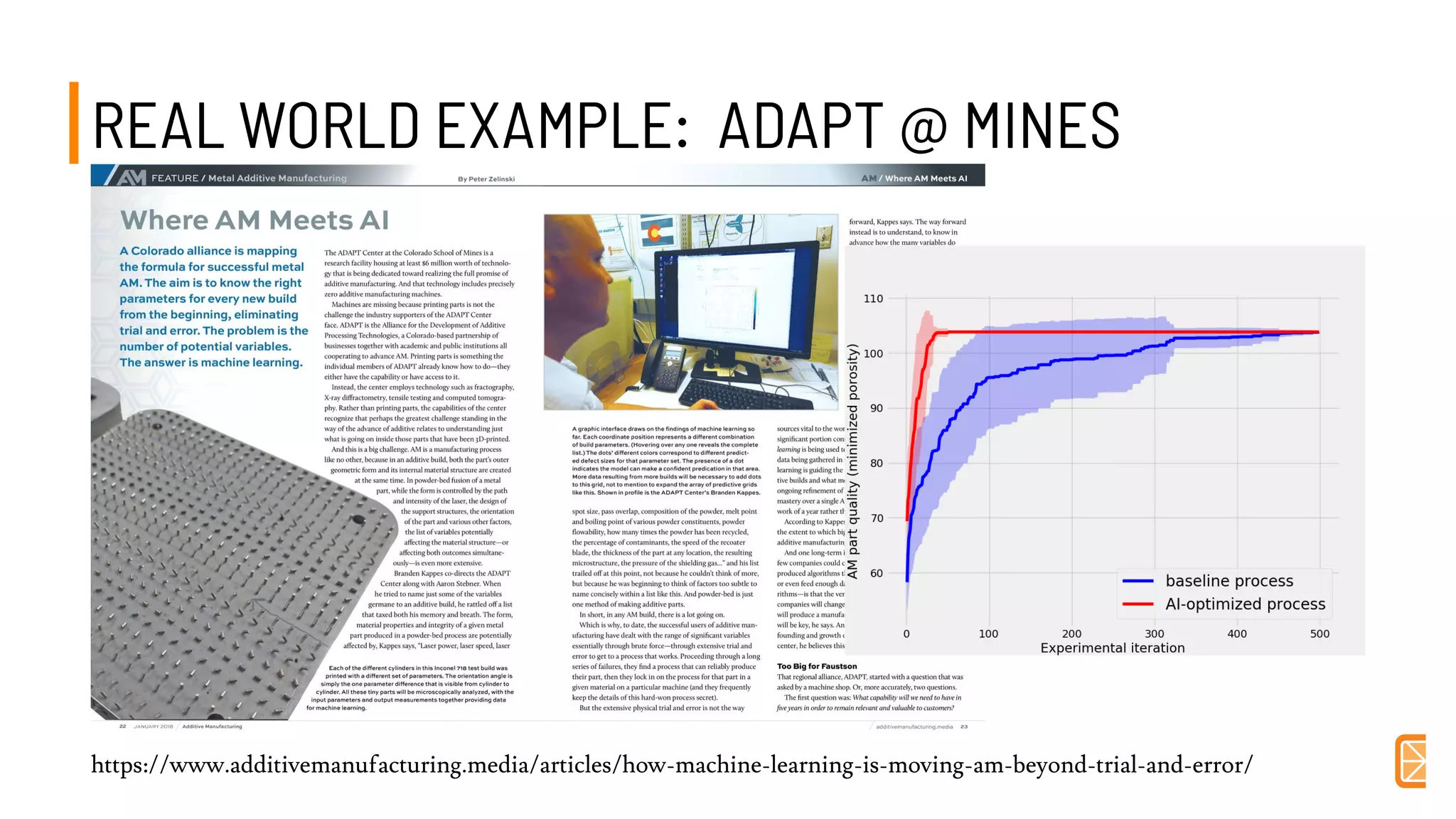
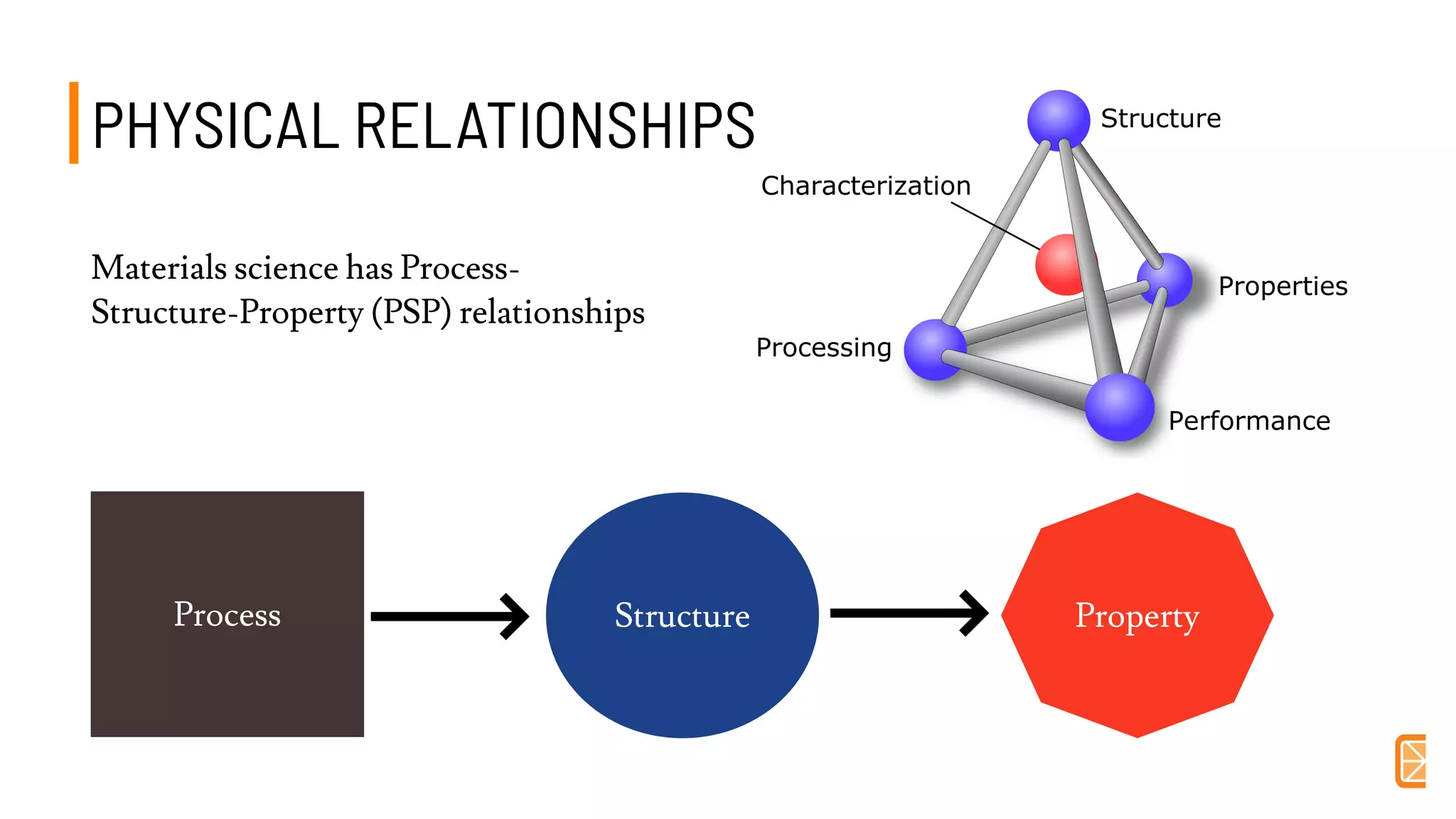
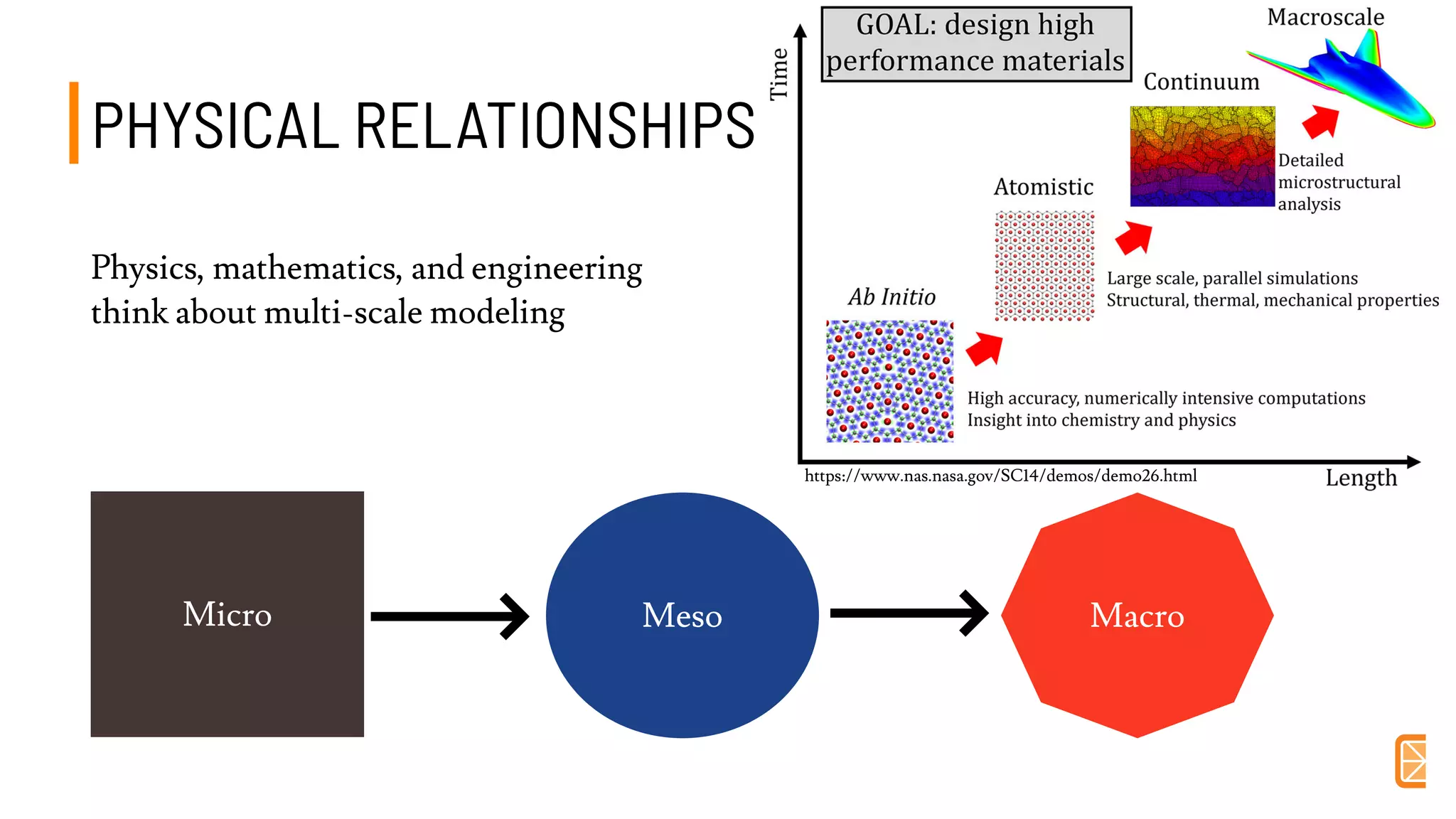
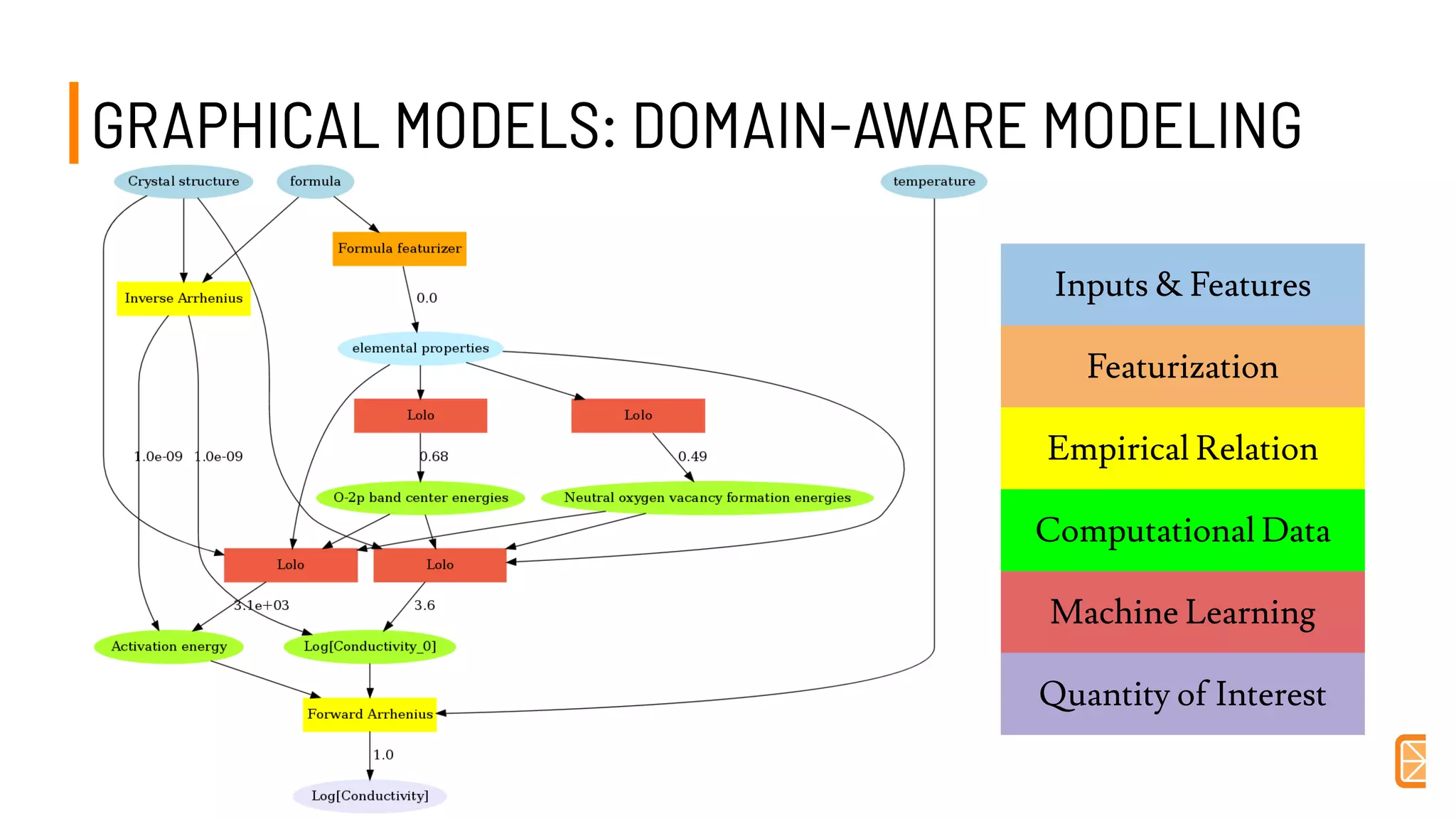
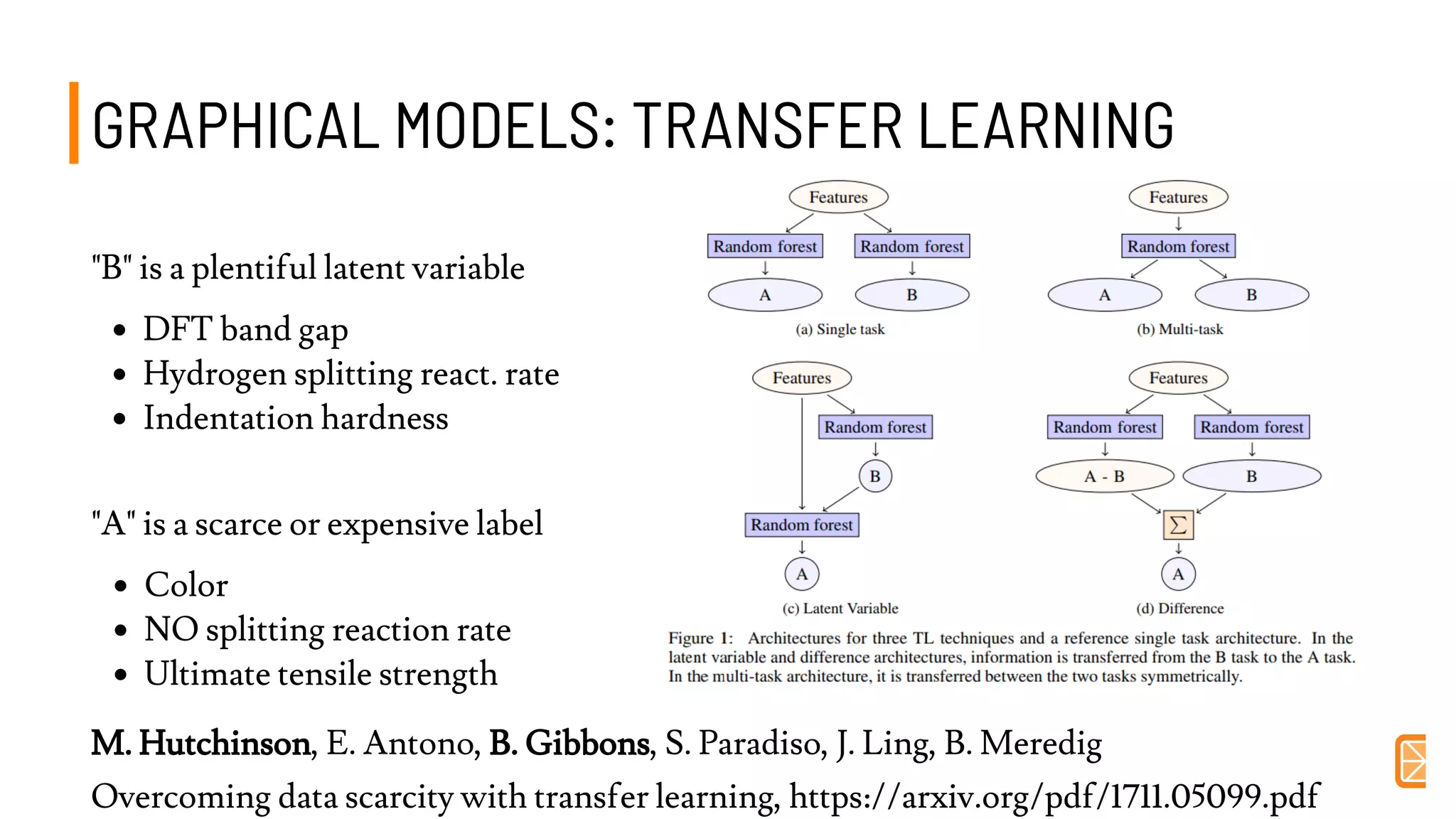
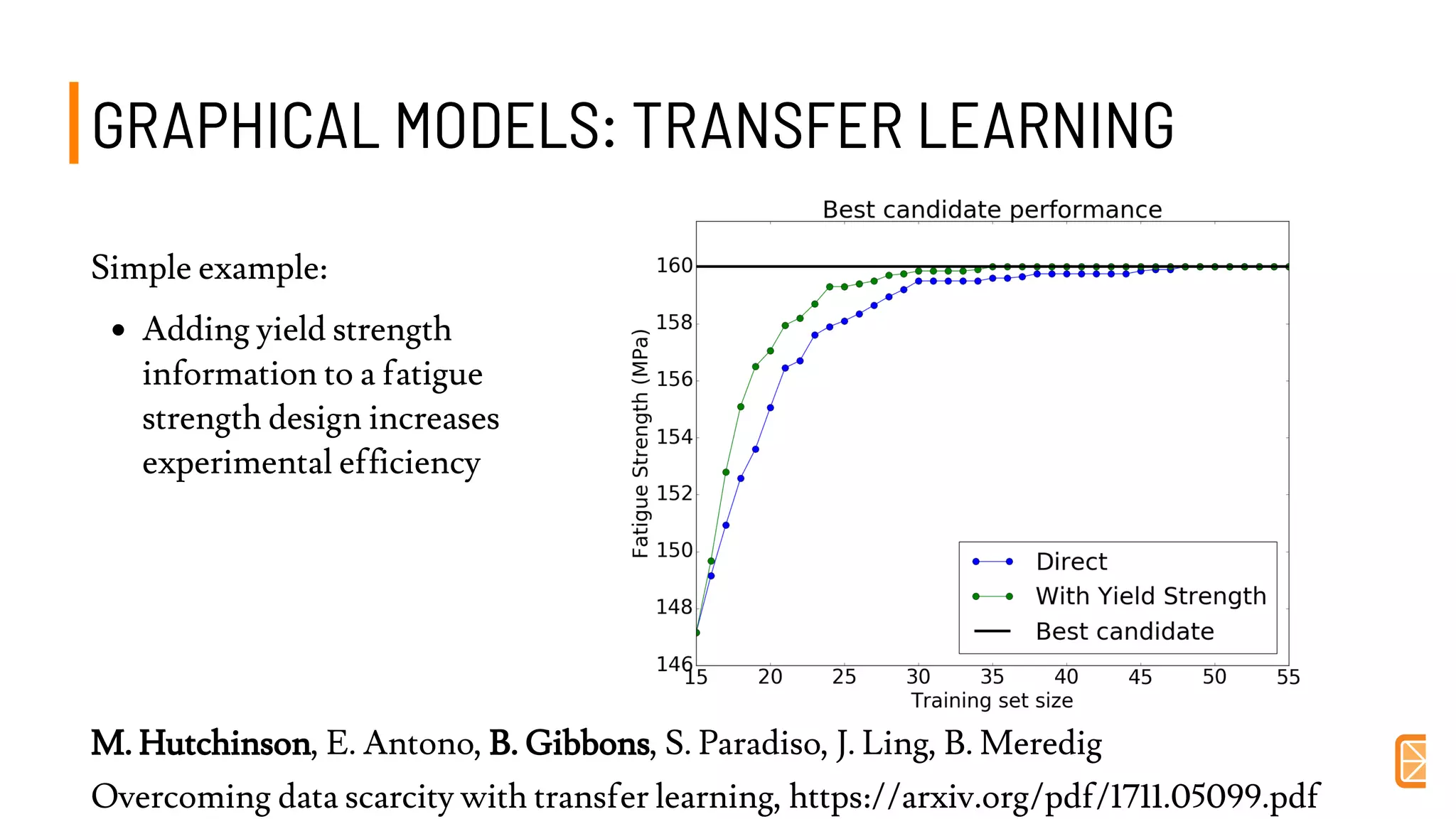
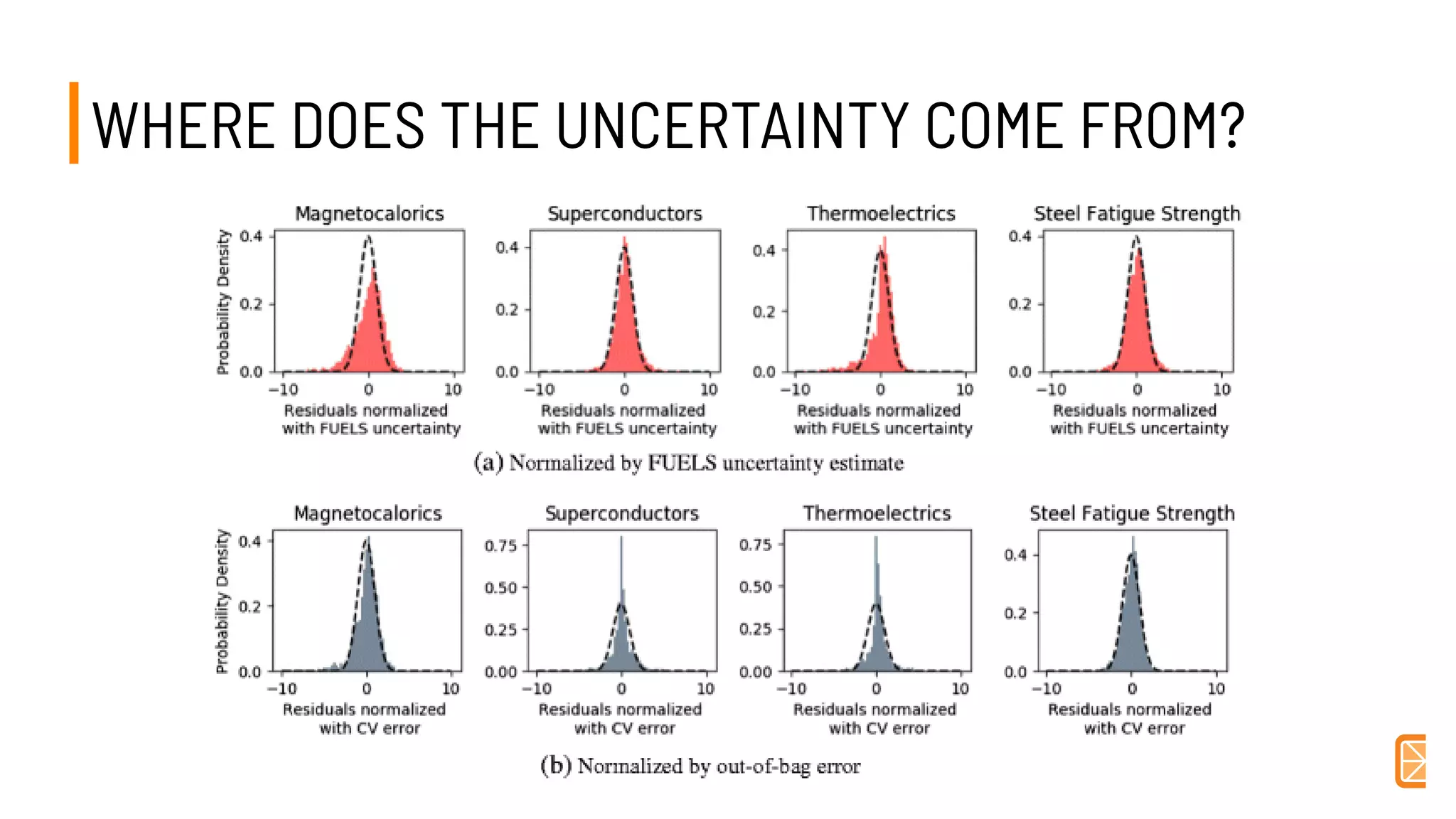
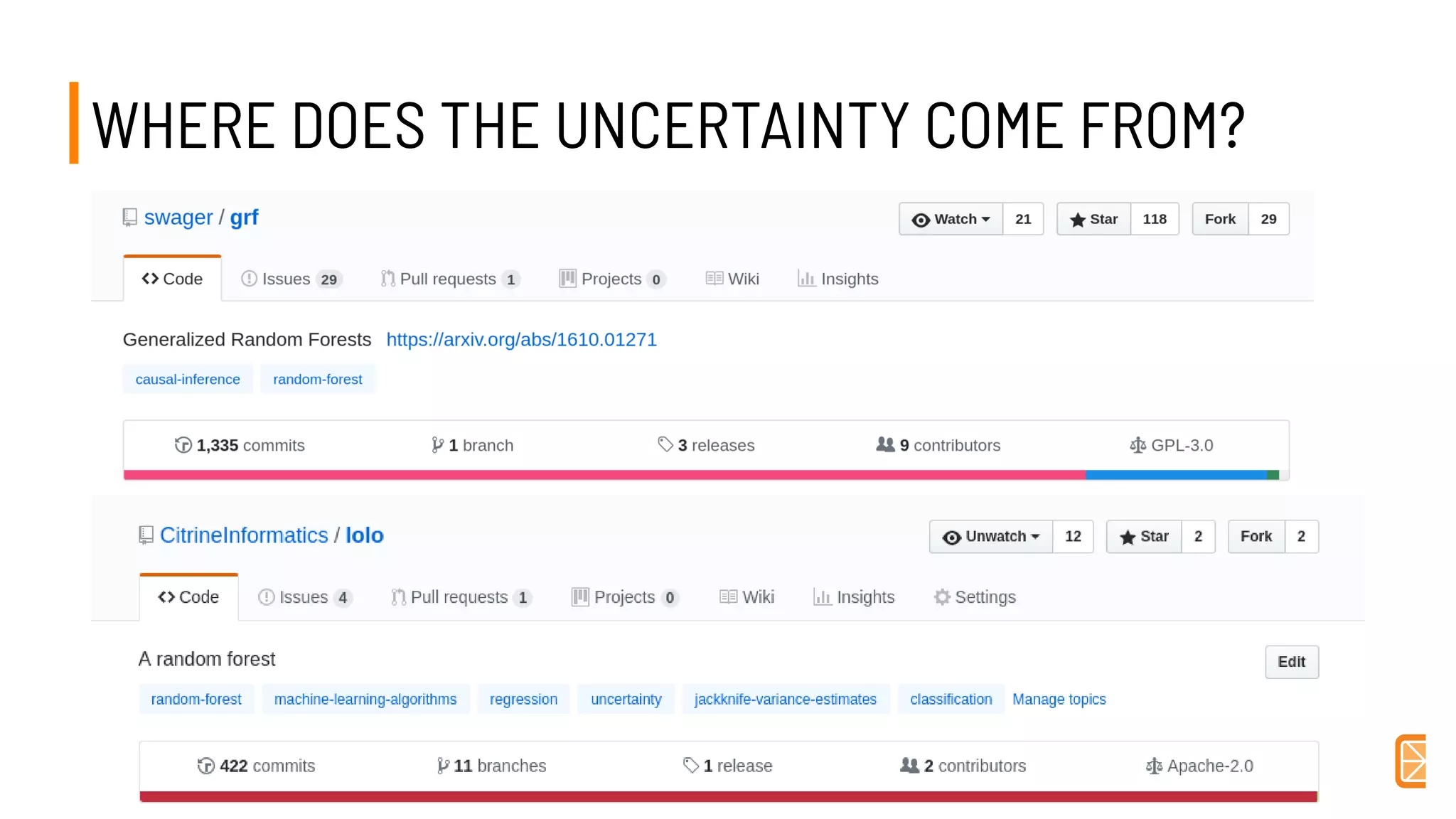
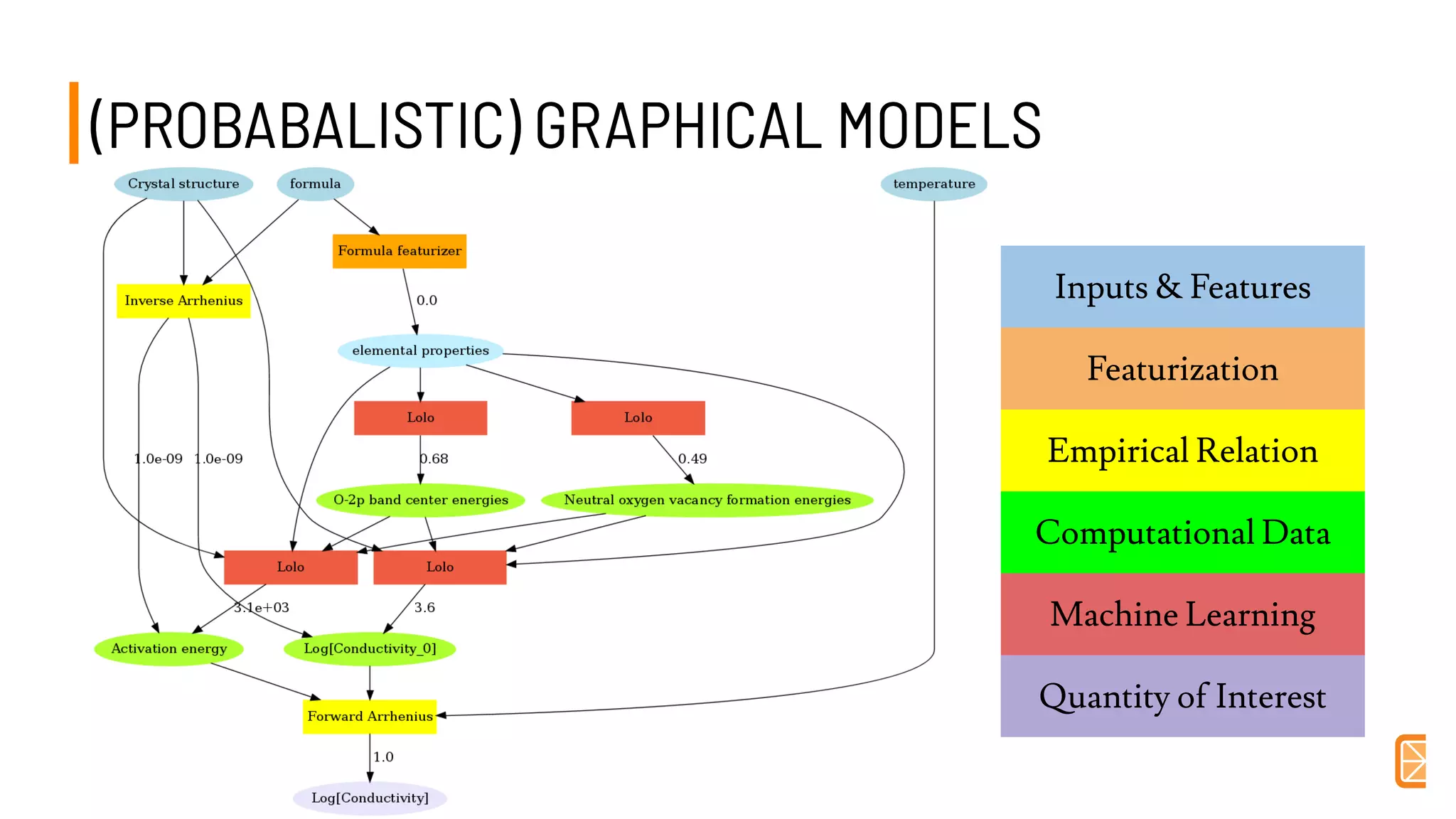
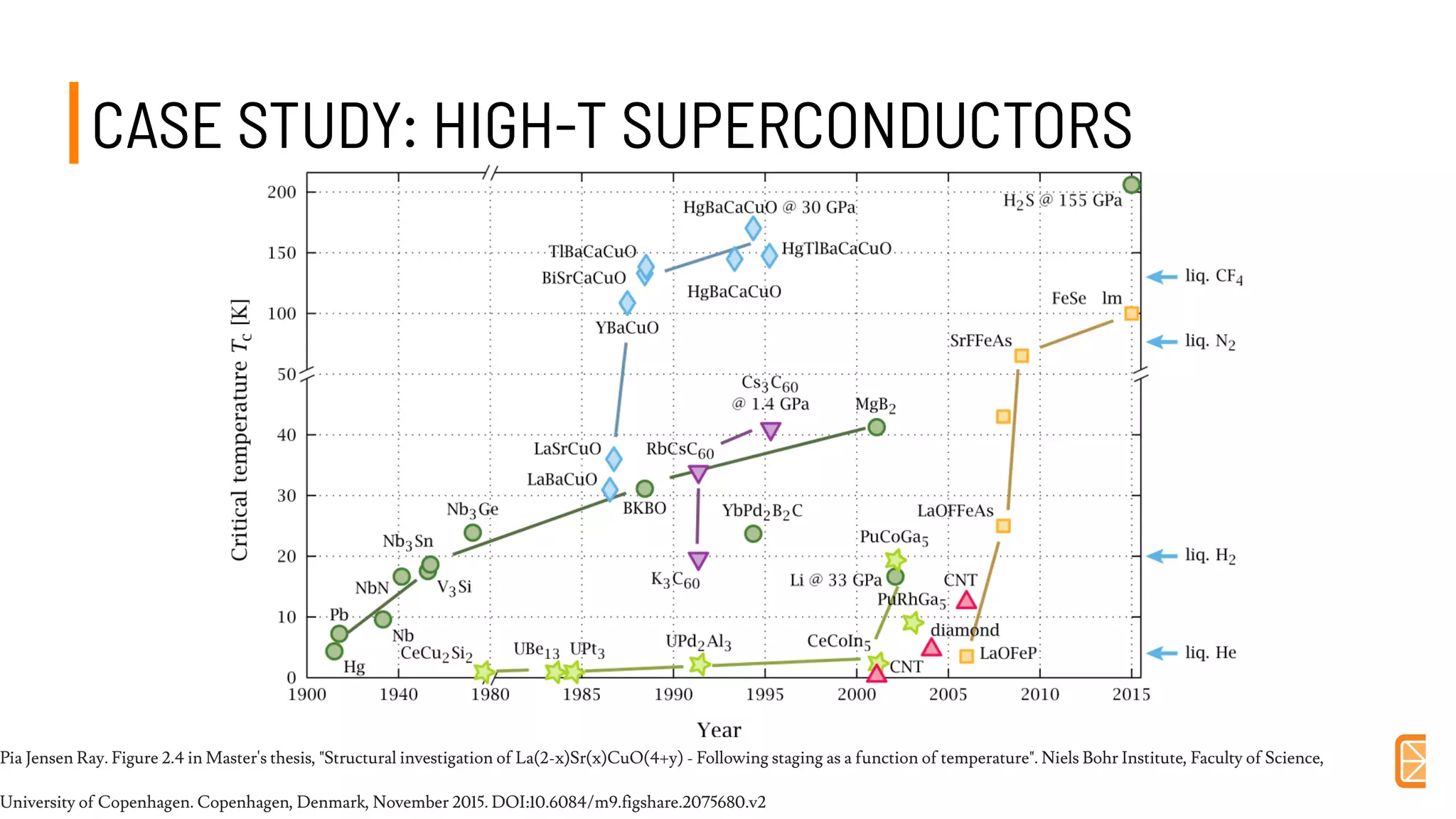
This document discusses challenges and opportunities in applying machine learning to materials science. It summarizes that simply applying off-the-shelf machine learning tools is insufficient for materials discovery due to unique challenges like scarce labeled data. Successful approaches require domain expertise to customize models using techniques like transfer learning that leverage relationships between different material properties. Sequential experiment design informed by machine learning can accelerate discovery by designing the next most informative experiments. While perfect prediction of new materials may not be possible, data-driven modeling can still deliver faster discovery.










![DESIGNING THE NEXT EXPERIMENTDESIGNING THE NEXT EXPERIMENT
Maximum Expected
Maximum Likelihood of
Improvement (MLI)
Maximum Uncertainty
x ∗ p(x; θ) dx∫−∞
∞
[ ]
p(x; θ) dx∫α
∞
[ ]
(x − ) dx∫−∞
∞
[ xˉ 2
]](https://image.slidesharecdn.com/max-180812201037/75/Materials-Data-in-Action-15-2048.jpg)