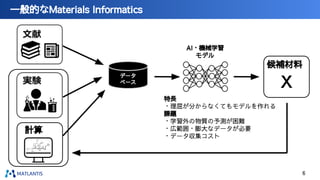
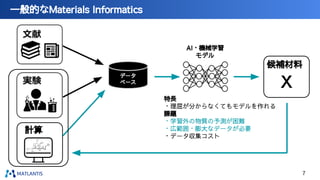
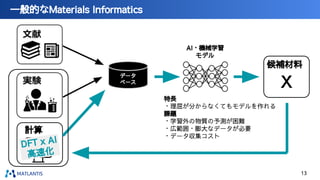
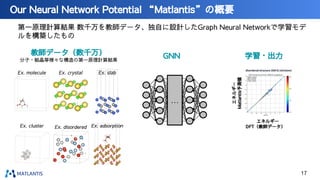
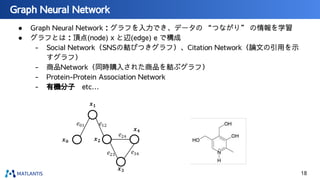
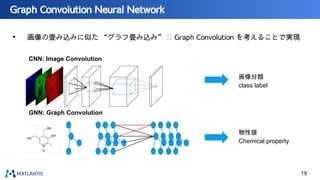
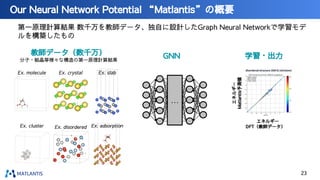
nano tech2022での講演資料です。 https://www.nanotechexpo.jp/main/ 汎用原子レベルシミュレータ「Matlantis」に関して、技術的な背景知識から、実際の活用事例まで紹介しております。 Preferred Computational Chemistryウェブサイト https://matlantis.com/ja/




![DFT計算 x 機械学習の事例
9
[1] Gómez-Bombarelli, R., Aguilera-Iparraguirre, J., Hirzel, T. et al., Nature Mater 15, 1120–1127 (2016).
[2] Zhong, M., Tran, K., Min, Y. et al., Nature 581, 178–183 (2020).
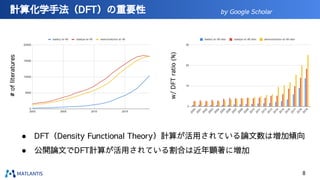
● CO2
還元触媒の探索 [2]
● 有機EL材料の探索 [1]
✓ 文献から候補抽出
→DFT理論予測
→実験候補の抽出
✓ コスト軽減のためDFT算出
の物性値推算モデルを構築
✓ t-SNEで吸着構造を分類することで
理想的な触媒組成・反応機構の考察
✓ 合計23万ものCu系触媒表面CO2
吸着
構造を計算・解析](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-9-320.jpg)

![高速かつ良精度とされる計算化学手法
DFTB法 ReaxFF
ハミルトニアンの積分項をパラメータ化することで
DFTよりも高速
分子動力学法ベースの手法のためDFTよりも高速
[3] S. Manzhos, G. Giorgi, and K. Yamashita, Molecules 20, 3371 (2015). [4] K. Nishikawa, H. Akiyama, K. Yagishita, and H. Washizu, Jurnal Tribologi 21 63 (2019).
×公開パラメータの対応原子が限られる
×パラメータの作成・フィッティングが必要
×公開パラメータの対応原子が限られる
×パラメータの作成・フィッティングが必要
強束縛近似を用いたKSハミルトニアンの簡略化
ex. アモルファスTiO2
表面の酢酸吸着[3]
電荷・結合パラメータを加えた古典分子動力学法
ex. Cu/Cu2
O表面のベンゾトリアゾール分子吸着[4]
11](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-11-320.jpg)

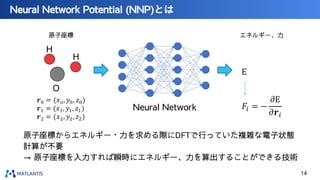
![DFT計算を高速化する技術:Neural Network Potential
[5] J. S. Smith, O. Isayev, and A. E. Roitberg, Chem. Sci. 8, 3192 (2017).
メリット:高速
•量子化学計算手法(DFT)と比べ
圧倒的に高速
デメリット:
•精度面 ― 精度の評価が難しい
•教師データ取得が必要
–学習するためのデータ収集として、結局DFT計算が必要
–取得したデータの周辺しか予測できない
15](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-15-320.jpg)
![GNNを用いたNNPの例
• CGCNN[7]:周期境界条件のある系に対するグラフ構築方法を提案
• MEGNet[8]:孤立系(分子)・周期境界条件(固体)双方へのGNN適用を報告
[7] T. Xie and J. C. Grossman, Phys. Rev. Lett. 120, 145301 (2018). [8] C. Chen, W. Ye, Y. Zuo, C. Zheng, and S. P. Ong, Chem. Mater. 31, 3564 (2019).
20](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-20-320.jpg)
![DFT計算の公開DBは特定の系に注目したものになってしまう
→汎用性を目指すためには独自dataset作成が必要
教師データ
表面系
https://opencatalystproject.org/
https://materialsproject.org/
http://aflowlib.org/
https://pubchem.ncbi.nlm.nih.gov/
http://pubchemqc.riken.jp/
結晶系
分子系
QM9 [10]
[10] R. Ramakrishnan, P. O. Dral, M. Rupp,
and O. A. von Lilienfeld, Scientific Data 1,
140022 (2014).
21](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-21-320.jpg)
![汎用なNeural Network Potential
教師データ
Neural Network
Architecture
[11] S. Takamoto et al., arXiv:2106.14583
様々な化学状態(結晶・分子・界面)を計算するために…
● 結晶構造、クラスター構造、表面構造、吸着構造、disordered構造等のDFT計算データを
独自に収集することが必要
● Neural Network の形状はGNNを採用
22](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-22-320.jpg)



![BaTiO3
は約130℃において正方晶(Tetragonal)から立方晶(Cubic)へ相転移し誘電特性が変化することが
知られている[13]
→現象を再現するためには電子状態を適切に取り扱えるモデルであることが重要
【実施】BaTiO3
正方晶構造を初期構造としてMatlantis(PFP)でMD計算。温度ごとの格子定数変化を取得。
BaTiO3
結晶の相転移解析事例
27
PFP計算条件
原子数 320 (4x4x4 supercell)
MD 0.1 ns (1 x 105
steps)
Ensemble NPT (Berendsen)
Temperature 300 ~ 600 K
[13] Smith et al., J. Am. Chem. Soc., 130, 6955-6963 (2008)
Tetragonal
Cubic
400 K付近の
BaTiO3
相転移
を再現](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-27-320.jpg)
![LiBに関する計算事例 : イオン拡散
https://www.kek.jp/ja/newsroom/2016/06/22/1833/
Li10
GeP2
S12
系固体電解質は高イオン伝導度を示す結晶
構造としてよく知られており、次世代電池材料として
注目を集める。
既報データも多く[14,15]、PFPで再現検討を実施。
計算条件
原子数 50
MD 1 ns (2x106
steps)
Ensemble NVT (Langevin)
実行時間 46 h
平均二乗距離@523K 拡散係数
活性化Energy(meV)
PFP DFT[14] Exp[15]
230 210 242
[14] Mo et al. Chem.Mater. (2012) 24, 15-17
[15] Y. Kato, et. al. Nat. Energy 1, 16030.
• DFTおよび実験結果をよく再現
• 高速な計算により低温領域まで計算可能
https://matlantis.com/ja/cases/calculation004/
DFT[14]
PFP
28](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-28-320.jpg)
![【PFP】 64.4 [kJ/mol]
【DFT[16]】 61.0 [kJ/mol]
多孔質材に関する計算事例 : MOF
29
[16] F. Bonino, et. al., Chem. Mater. 20, 4957 (2008).
https://matlantis.com/ja/cases/calculation002/
ゼオライトに代表されるようなナノサイズの微小細孔を持つ材料は
吸着材、分離膜、触媒材料として幅広い分野で利用されている。
【実施】 近年注目を集めるMetal-organic
frameworks(MOFs)への水分子吸着
エネルギーを計算
ΔE = 1/n (Eads
- EMOF
- nEH2O
)
MOF-74Niの構造
左:水分子吸着なし、右:水分子吸着あり
原子数:162 原子数:216](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-29-320.jpg)
![石油合成触媒探索 Fischer-Tropsch process
Co+V触媒上でのC-O解離反応
Co触媒の一部元素置換による活性化エネルギー変化
(Coのみの基準を1.0)
良
1.0
0.0
0.8
0.6
0.4
0.2
メタン化反応
活性化エネルギー比較
DFT[18] vs. PFP
30
● Fischer-Tropsch機構の律速過程CO解離反応を促進する高性能触媒
組成を探索
● およそ9,300回の反応経路解析( NEB)スクリーニングを実施
● Co/V系で活性化エネルギーの低減を確認
→実験事実[17]と合致
[17] K. Shimura, T. Miyazawa, T. Hanaoka, and S. Hirata, Applied Catalysis A: General 494, 1 (2015).
[18] B. Zijlstra, et al., Catalysis Today 342, 131 (2020).](https://image.slidesharecdn.com/dxmatlantisnanotech2022-220131065351/85/Dx-Matlantis-_nano-tech2022_2022-1-28-30-320.jpg)















![[DL輪読会]ICLR2020の分布外検知速報](https://cdn.slidesharecdn.com/ss_thumbnails/iclr2020ood-190927011524-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]Set Transformer: A Framework for Attention-based Permutation-Invariant...](https://cdn.slidesharecdn.com/ss_thumbnails/20200221settransformer-200221020423-thumbnail.jpg?width=640&height=640&fit=bounds)









![[DL輪読会]Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets](https://cdn.slidesharecdn.com/ss_thumbnails/20220325okimura-220405024717-thumbnail.jpg?width=640&height=640&fit=bounds)

![SSII2022 [TS1] Transformerの最前線〜 畳込みニューラルネットワークの先へ 〜](https://cdn.slidesharecdn.com/ss_thumbnails/ts120220608ssiitransformerr2-220607054025-3adacf07-thumbnail.jpg?width=640&height=640&fit=bounds)







![[DL輪読会]Inverse Design of Solid-State Materials via a Continuous Representation](https://cdn.slidesharecdn.com/ss_thumbnails/200214dl-200214034842-thumbnail.jpg?width=640&height=640&fit=bounds)


![[Japan Tech summit 2017] MAI 001](https://cdn.slidesharecdn.com/ss_thumbnails/techsummit2017pdfmai001-171115034129-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DL輪読会]マテリアルズインフォマティクスにおける深層学習の応用](https://cdn.slidesharecdn.com/ss_thumbnails/181207dlwakasugipanasonicver4-181207003725-thumbnail.jpg?width=640&height=640&fit=bounds)



![[AI08] 深層学習フレームワーク Chainer × Microsoft で広がる応用](https://cdn.slidesharecdn.com/ss_thumbnails/ai08-170705031536-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DL輪読会]Learning to Simulate Complex Physics with Graph Networks](https://cdn.slidesharecdn.com/ss_thumbnails/learningtosimulatecomplexphysicswithgraphnetworks-200508054213-thumbnail.jpg?width=640&height=640&fit=bounds)










