

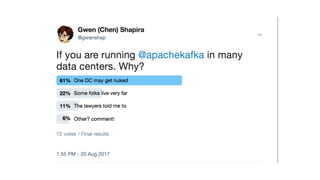


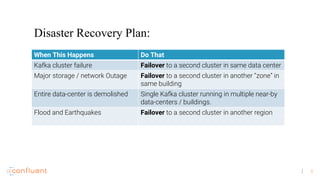






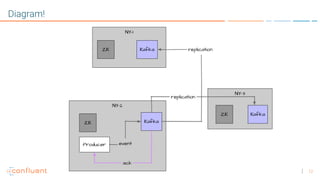





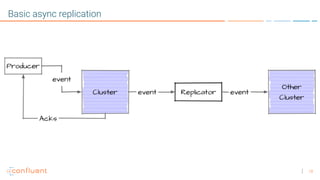
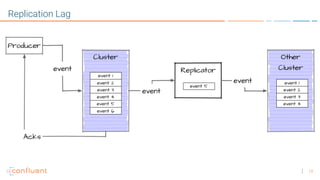


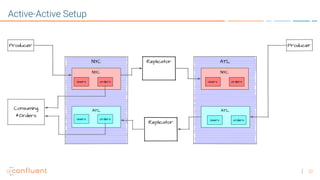

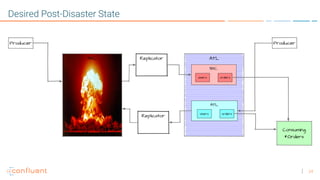

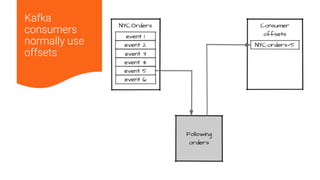
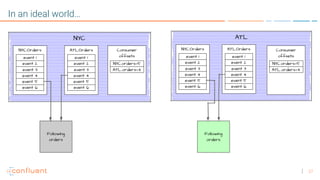








The document discusses disaster recovery plans for Apache Kafka in multi-data center environments, addressing potential failures such as cluster failures and major outages. It outlines solutions for failover strategies, including using stretch clusters and asynchronous replication, while considering trade-offs like latency, costs, and monitoring requirements. The need for careful planning, monitoring replication lag, and future-proofing by leveraging features like timestamps for effective failover is emphasized.






















































































