Downloaded 30 times


























![all There are no restrictions for indexing or serving. Note: this directive is the
default value and has no effect if explicitly listed.
noindex Do not show this page in search results and do not show a "Cached" link in
search results.
nofollow Do not follow the links on this page.
none Equivalent to noindex, nofollow.
noarchive Do not show a "Cached" link in search results.
nosnippet Do not show a text snippet or video preview in the search results for this
page. A static thumbnail (if available) will still be visible.
notranslate Do not offer translation of this page in search results.
noimageindex Do not index images on this page.
unavailable_after: [RFC-850 date/time] Do not show this page in search results after the specified date/time. The
date/time must be specified in the RFC 850 format.](https://image.slidesharecdn.com/technicalseocrashcourse-190618122530/75/A-Crash-Course-in-Technical-SEO-from-Patrick-Stox-Beer-SEO-Meetup-May-2019-36-2048.jpg)
















































The document provides an overview of technical SEO best practices. It discusses on-page SEO elements like titles, meta descriptions, headings, images and URLs. It also covers technical aspects like sitemaps, indexing APIs, robots.txt files, redirects and canonical tags. The document recommends prioritizing content, links and proper indexing as the most important ranking factors. It also lists various tools for SEO audits, monitoring and troubleshooting technical issues.
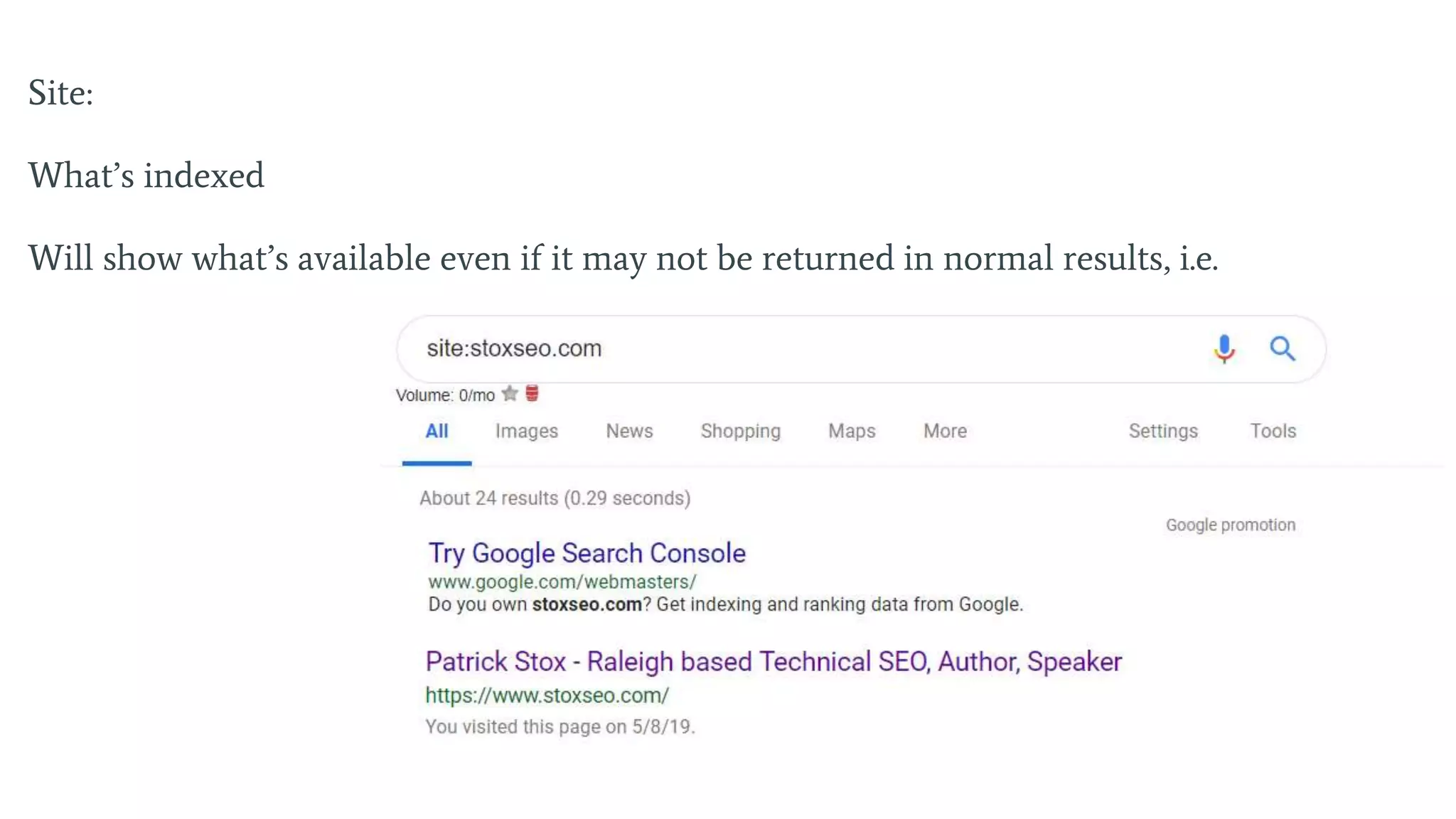
An overview of the presentation focusing on technical SEO by Patrick Stox from IBM.
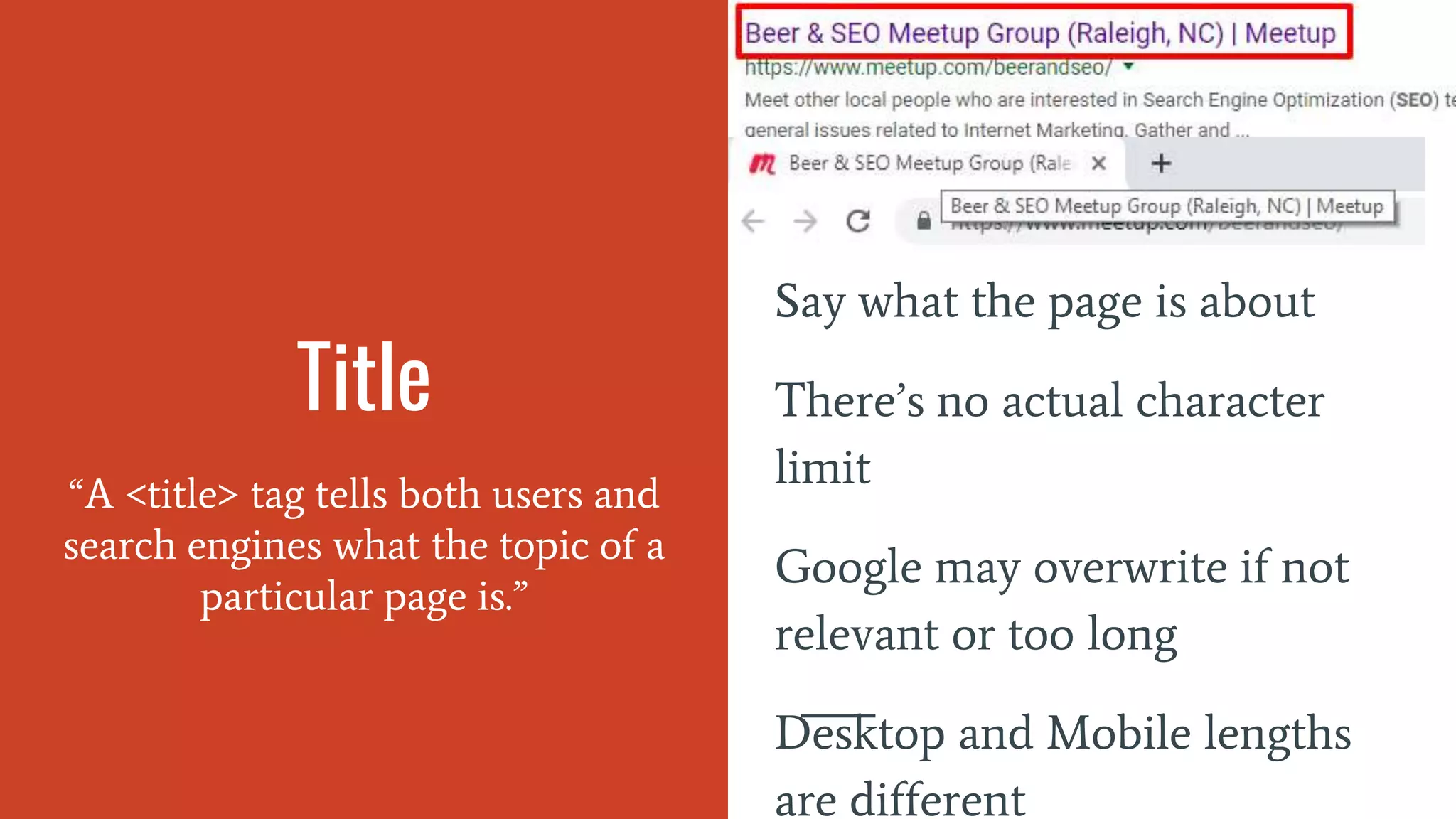
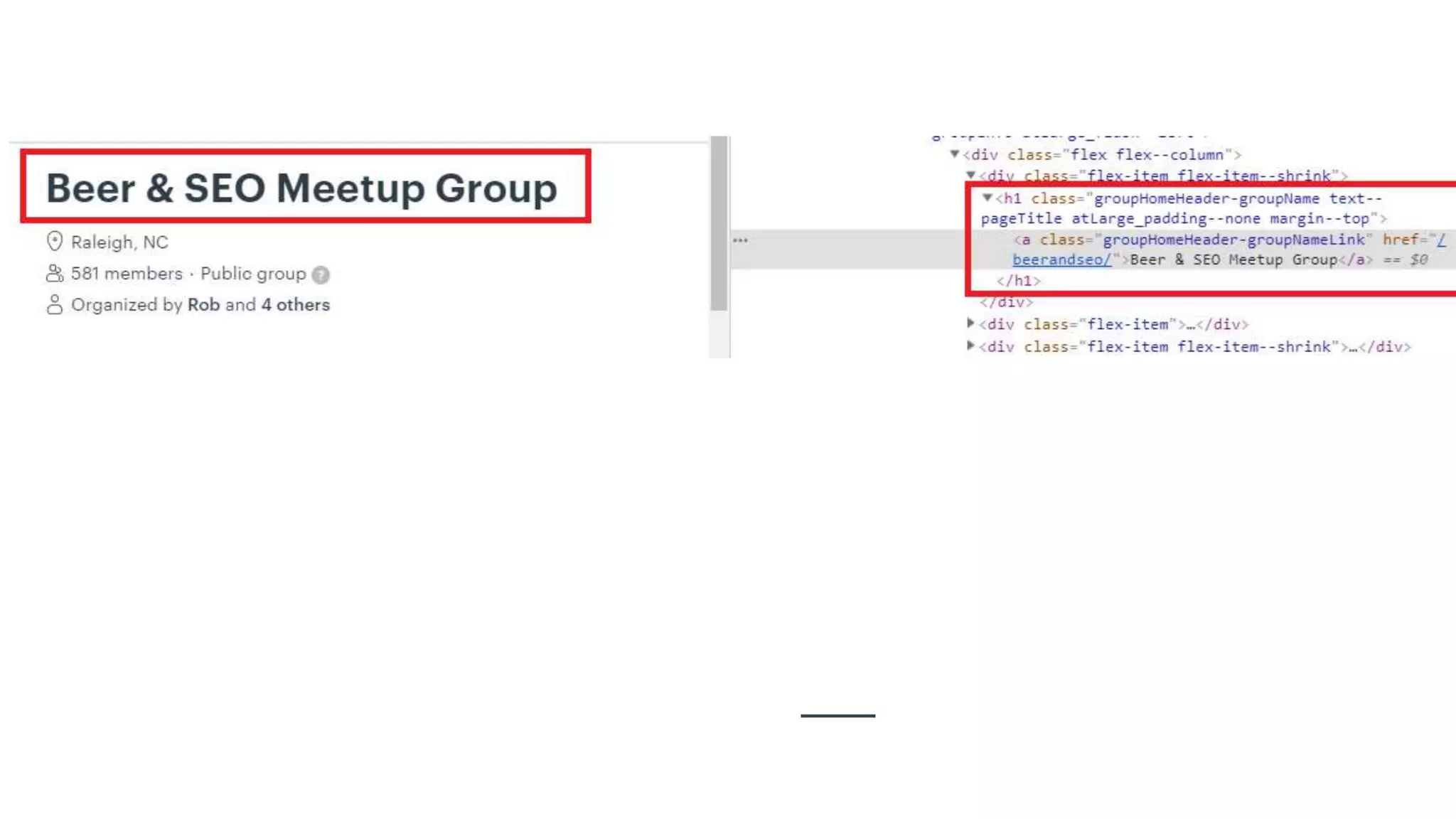
Discusses the importance of title tags, meta descriptions, headings, and images in on-page SEO.
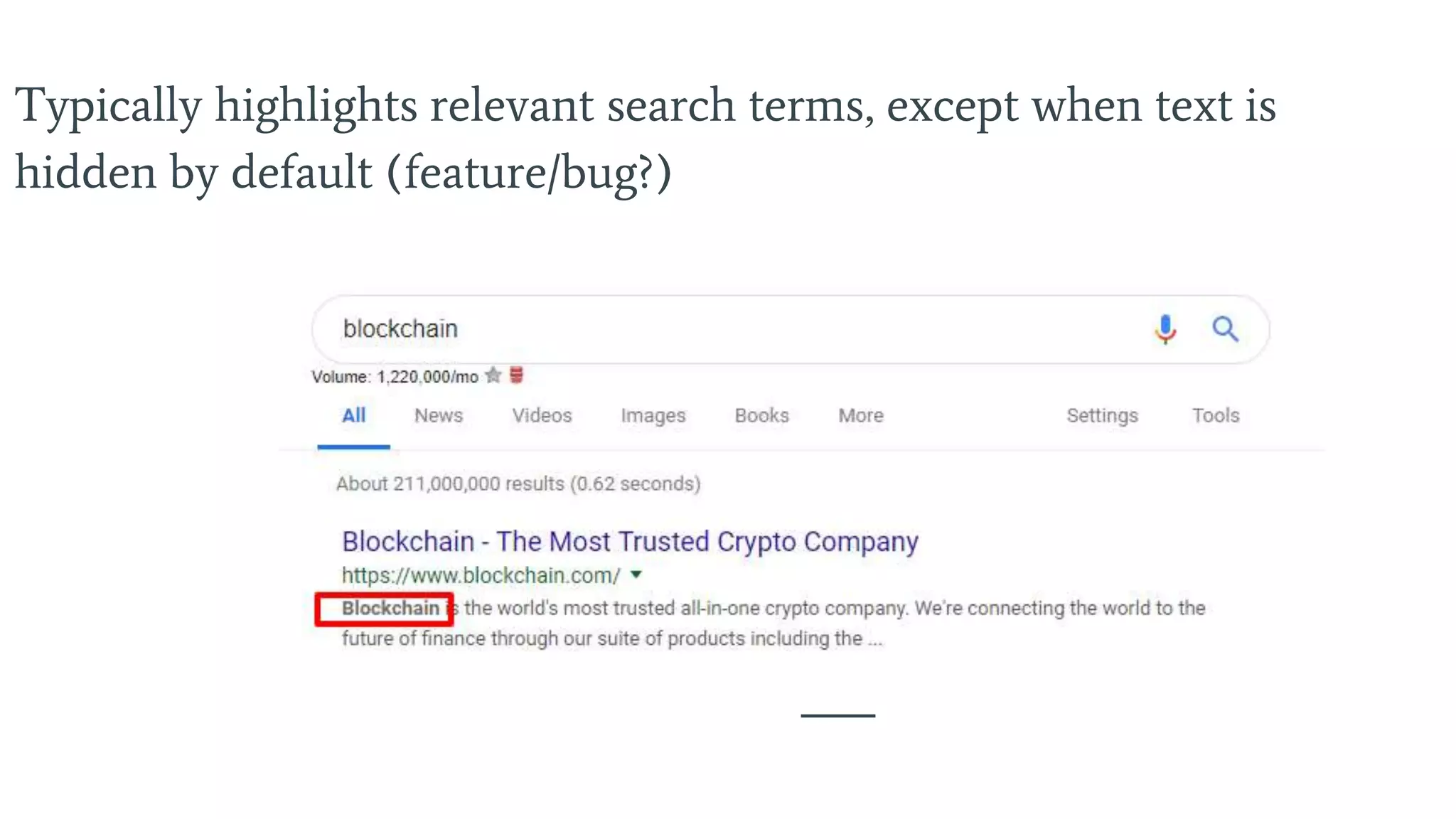
Meta descriptions summarize pages for search engines, keying on relevant search terms or rich results.
Importance of headings (H1-H6) for structuring content for better readability and skimming.
Emphasizes optimizing images through text content, alt attributes, and sensible naming practices.The significance of URLs in identification and discovery, along with structures for internal linking.
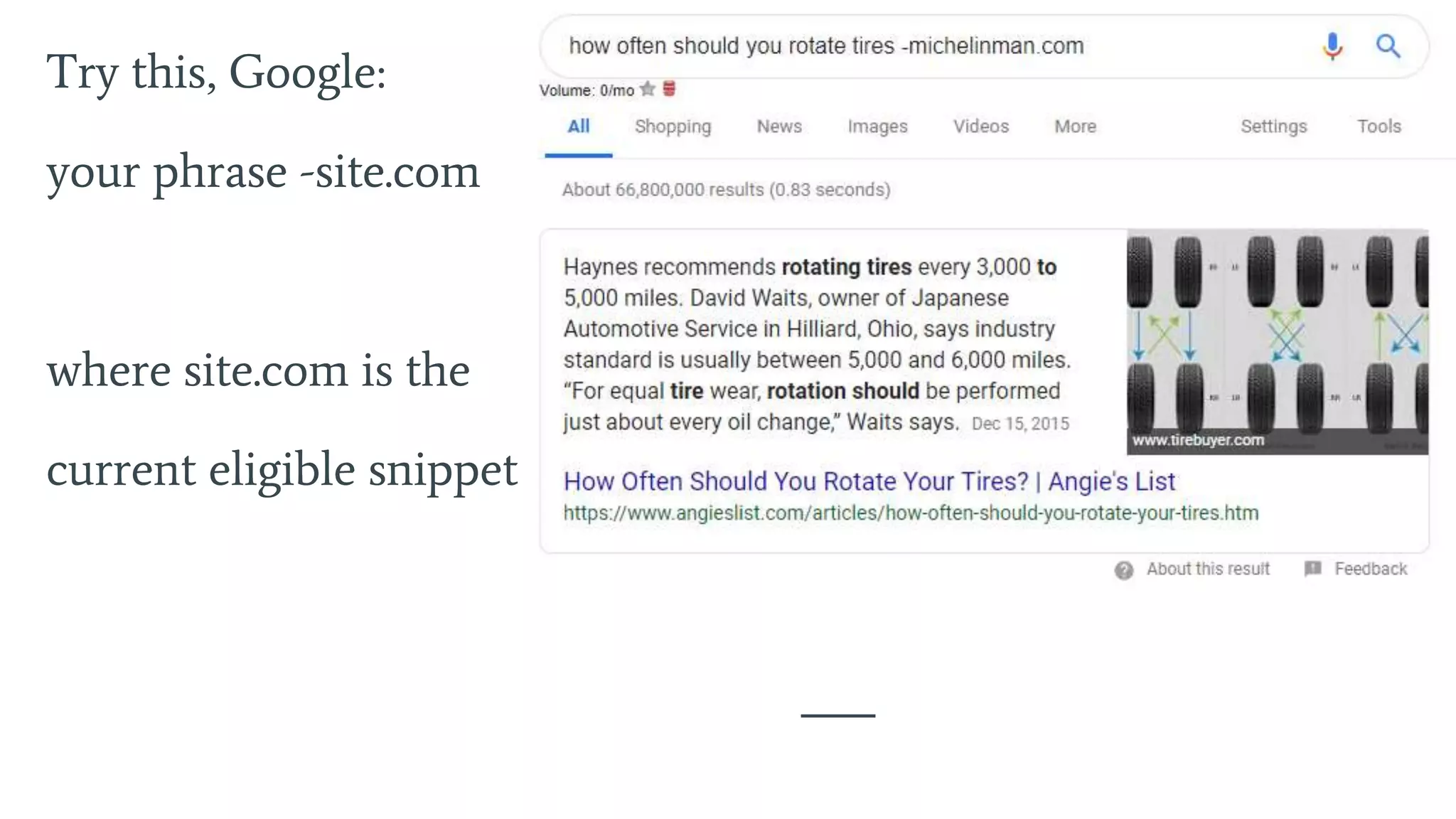
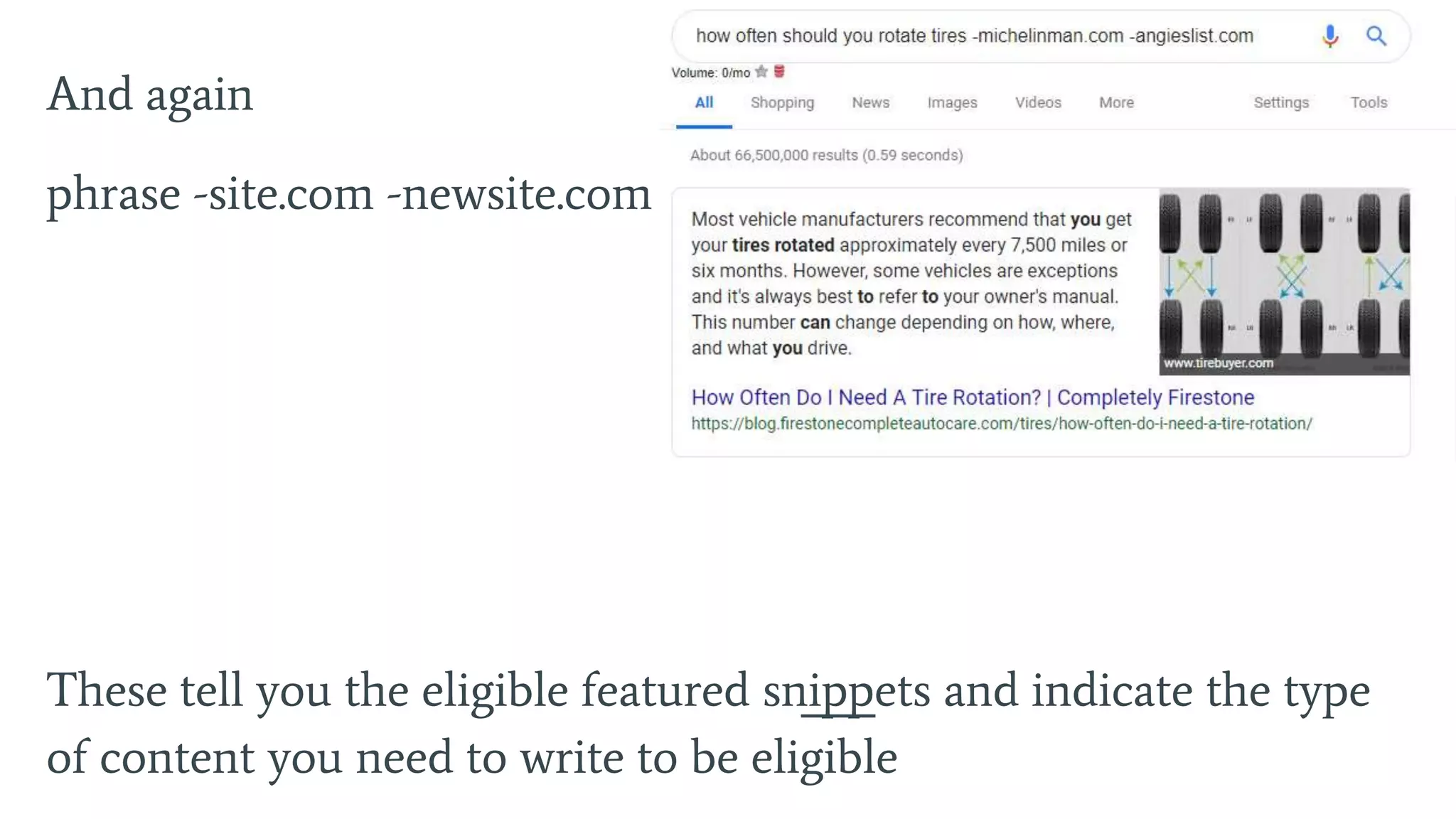
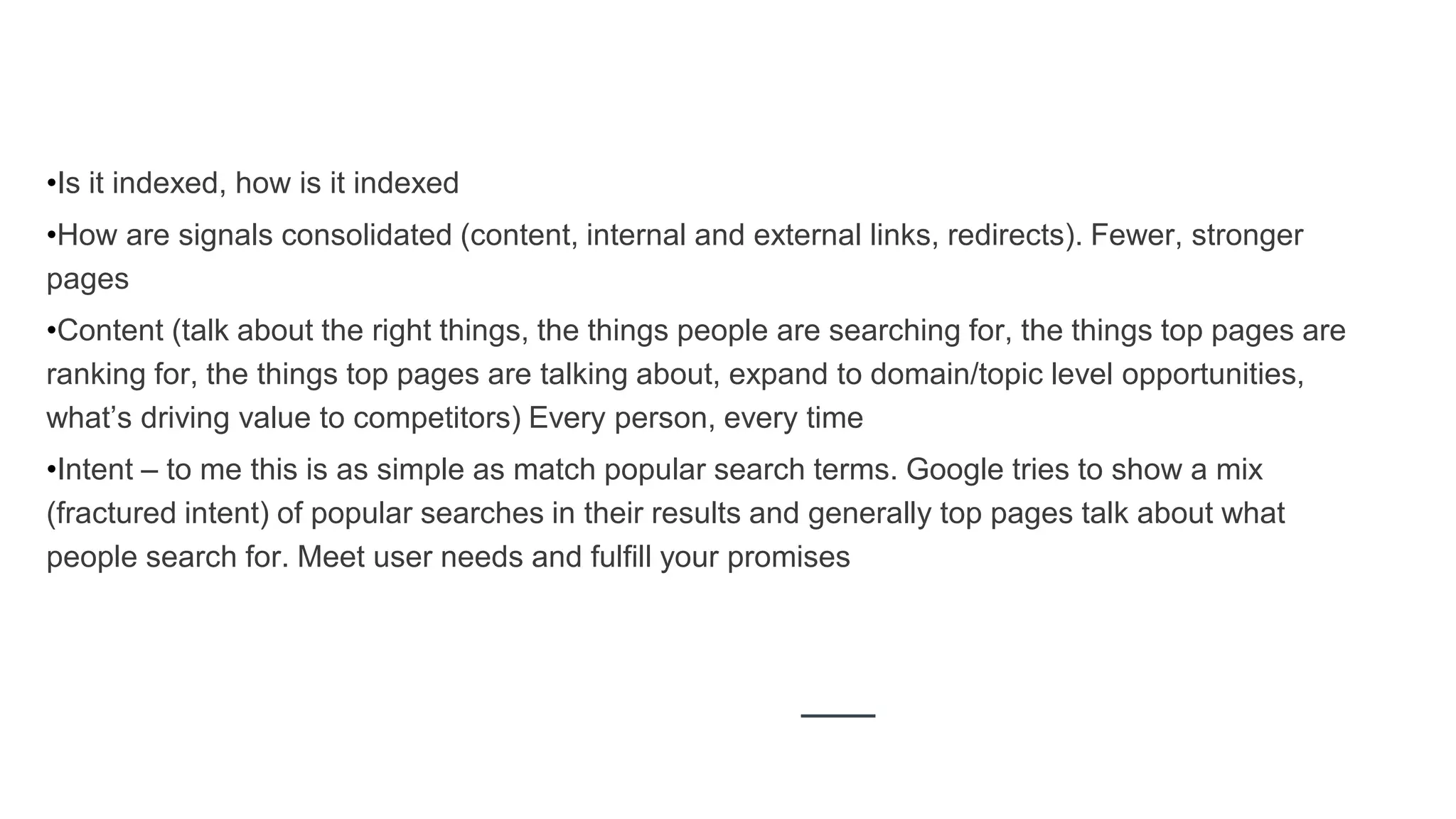
Highlights main ranking factors such as indexing, content relevancy, and tracking user intent.
Clarification on crawling vs indexing and their importance to search engine optimization.
Details how search engines like Googlebot crawl sites and the concept of crawl budget.
Explanation of the robots.txt file role in controlling crawler access to website content.
Sitemaps facilitate crawling and indexing by search engines, detailing structure and links.
Robots directives define crawling and indexing rules affecting how search engines see pages.
Discusses issues with conflicting instructions and common HTTP response status codes.
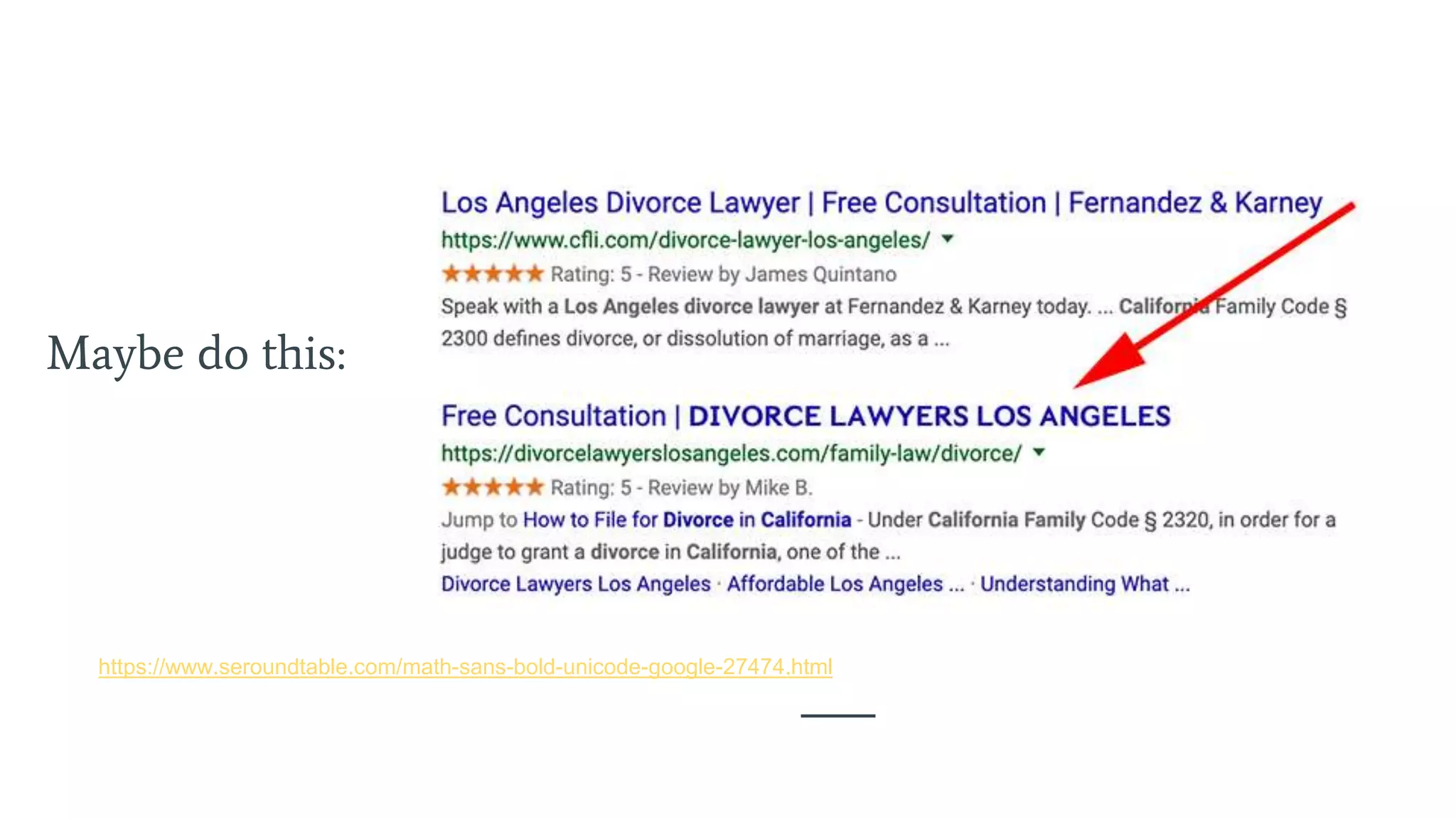
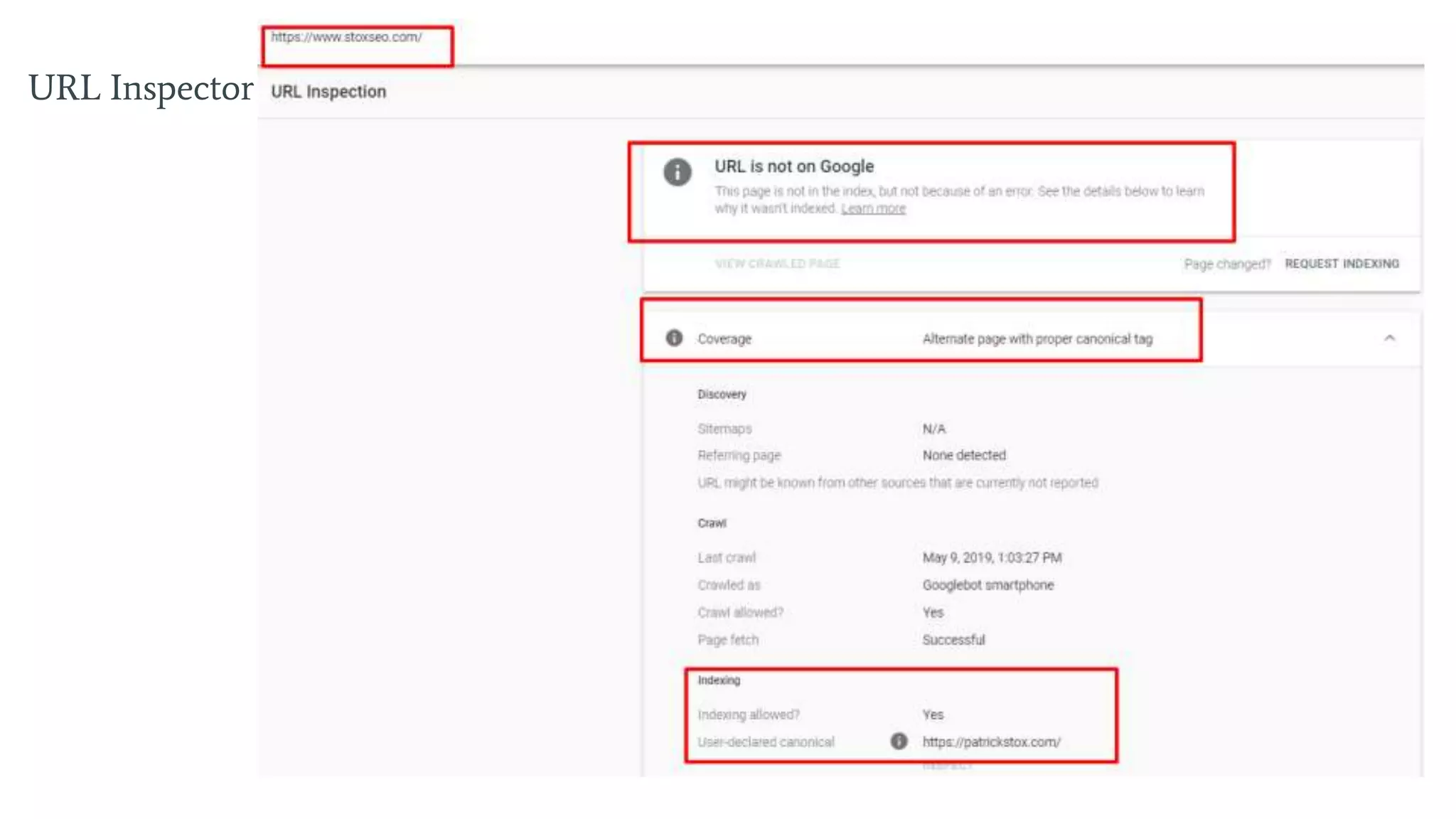
Utilizes canonical tags to resolve duplicate content issues and manage the preferred version of pages.
Strategies for dealing with duplicate content, including Canonical tags and redirects.List of tools for SEO monitoring, site speed testing, and troubleshooting methods.
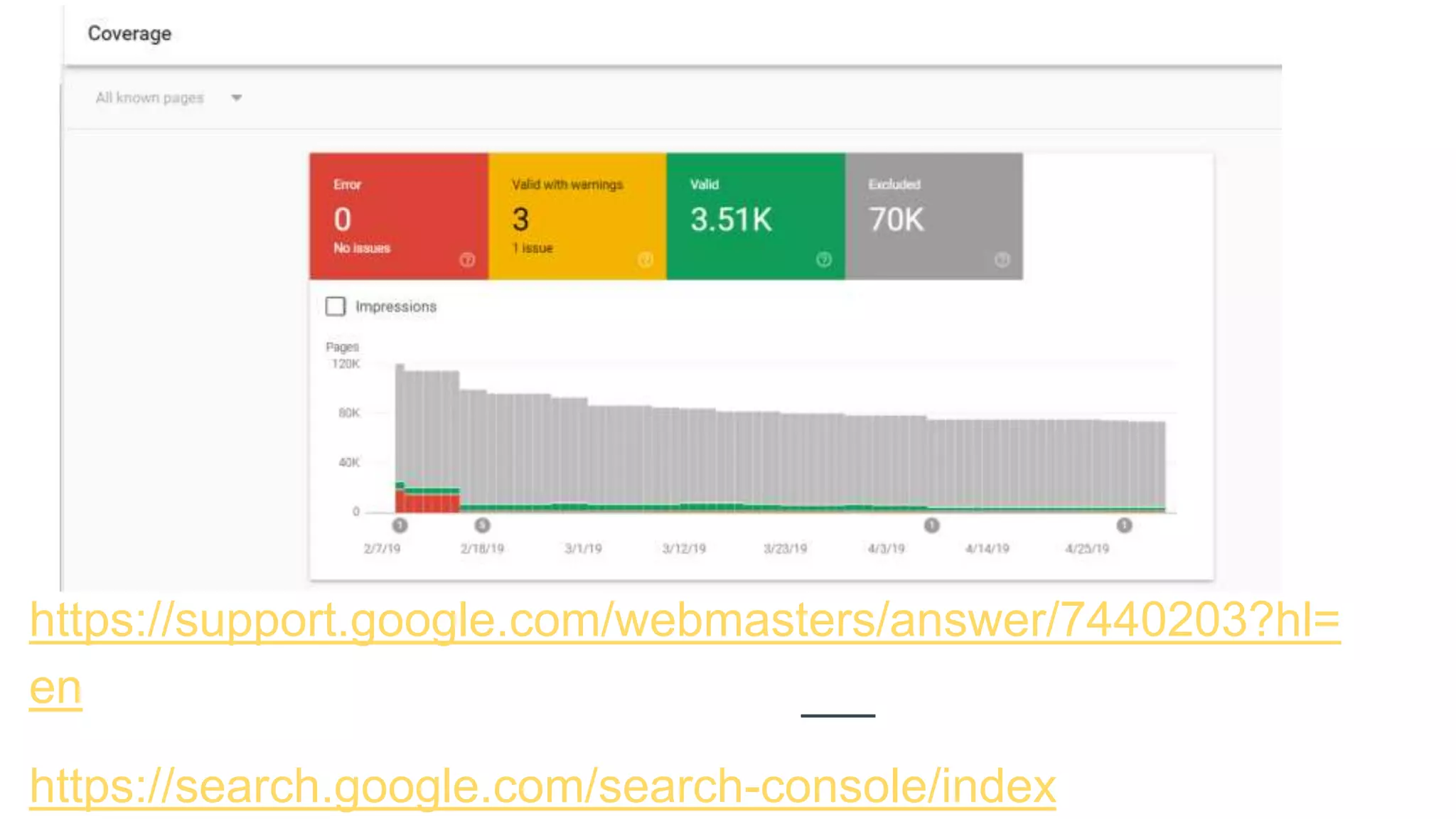
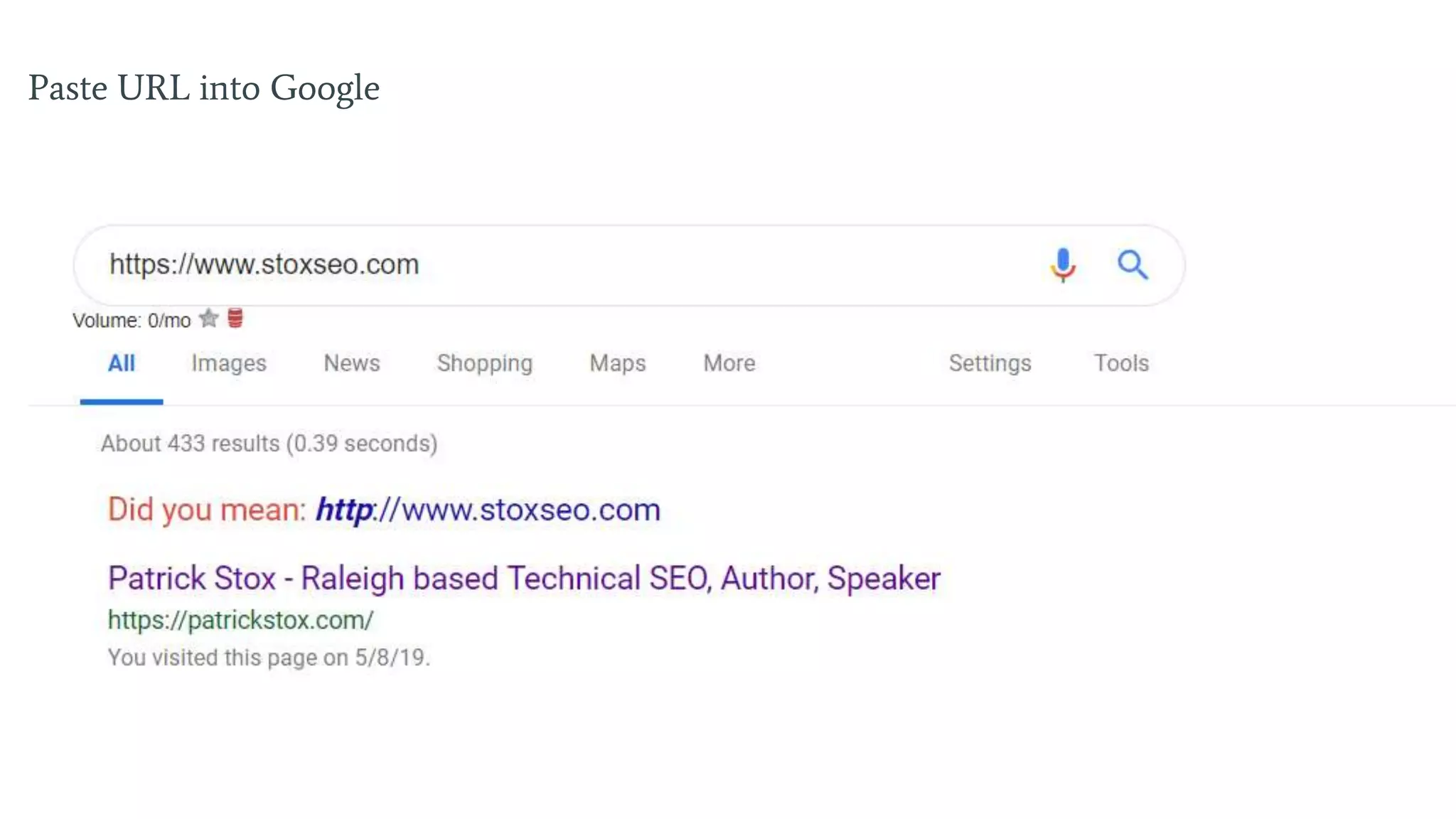
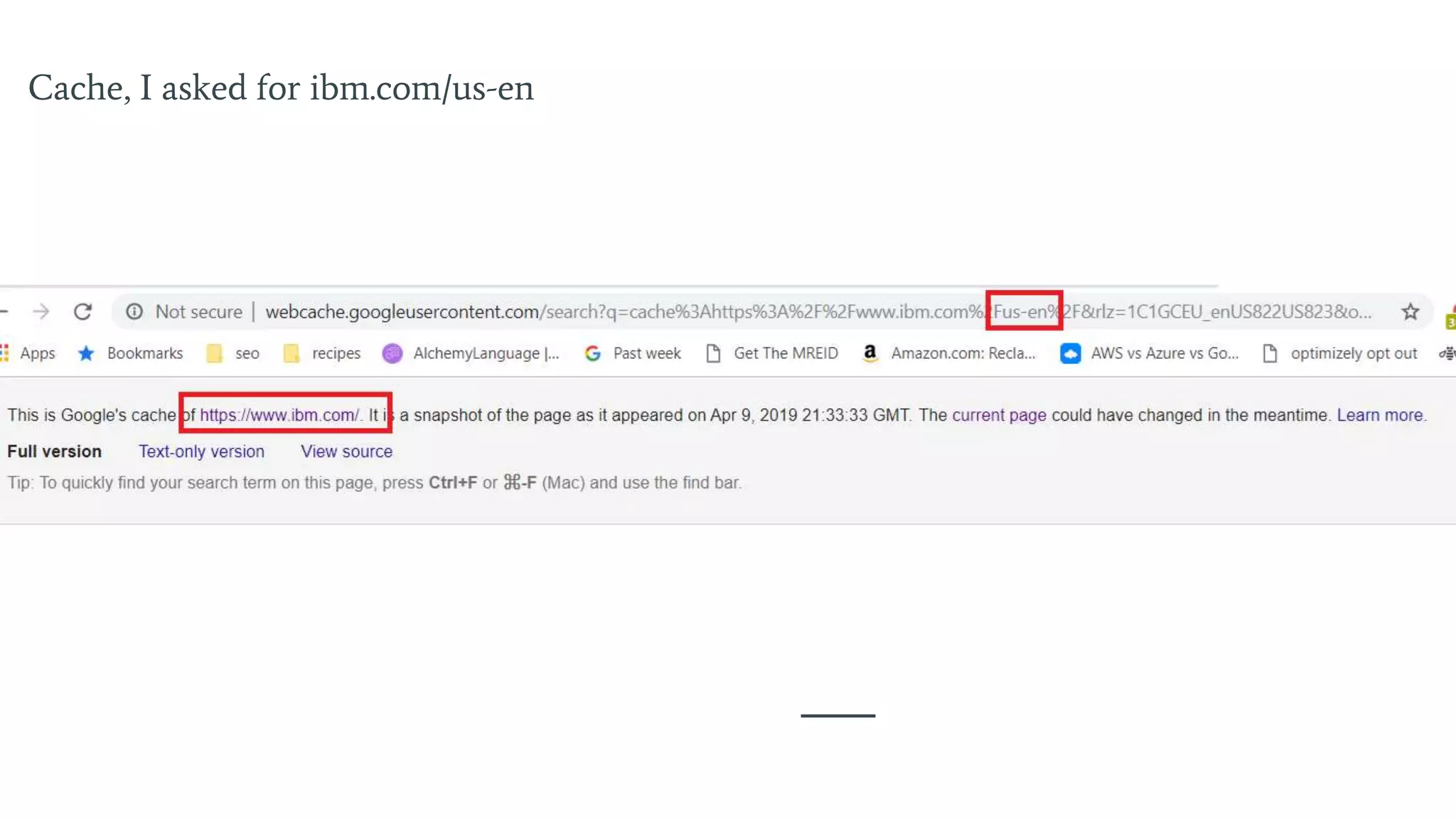
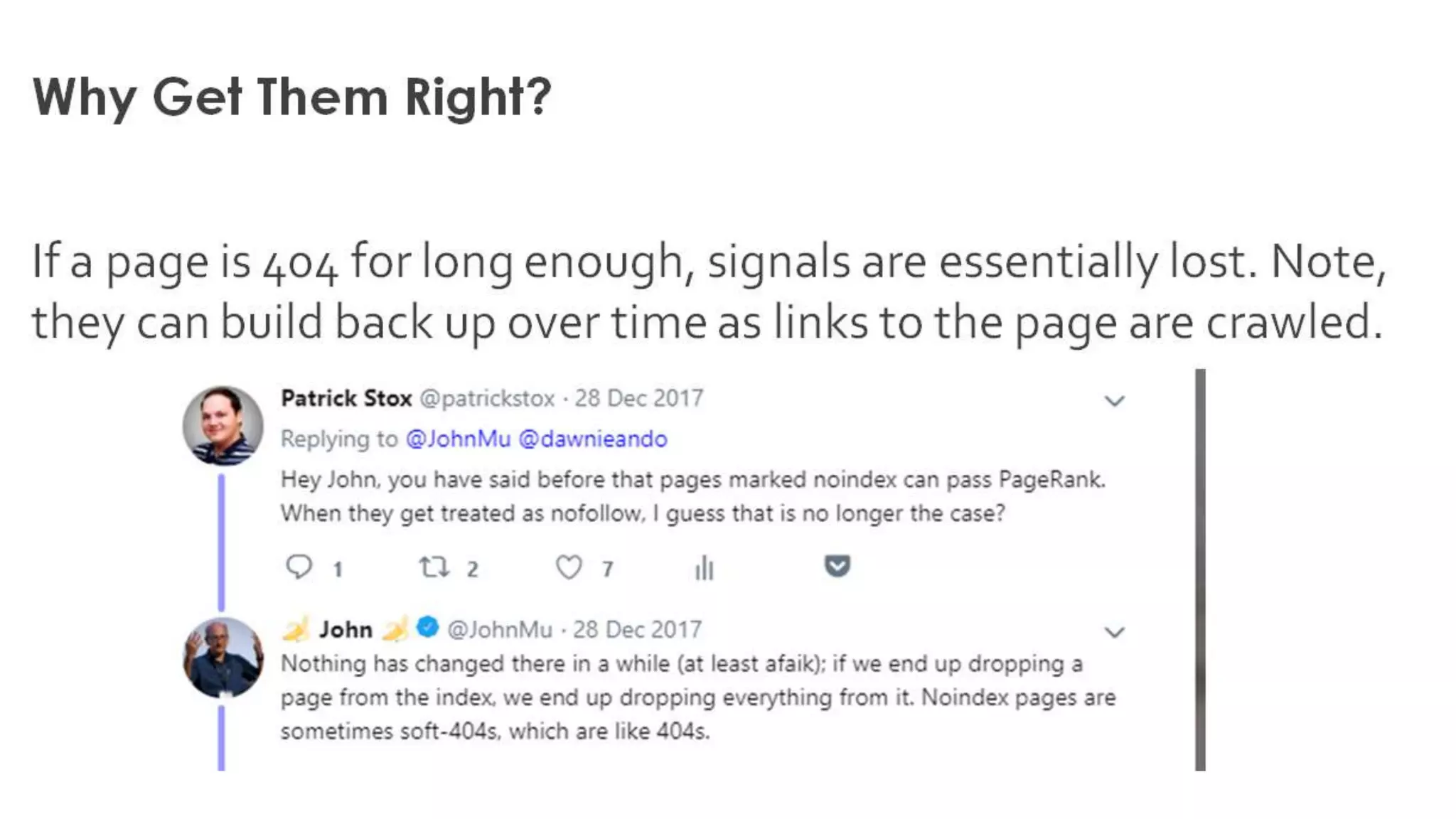
Insights on caching issues, the indexing process, and troubleshooting indexed pages.
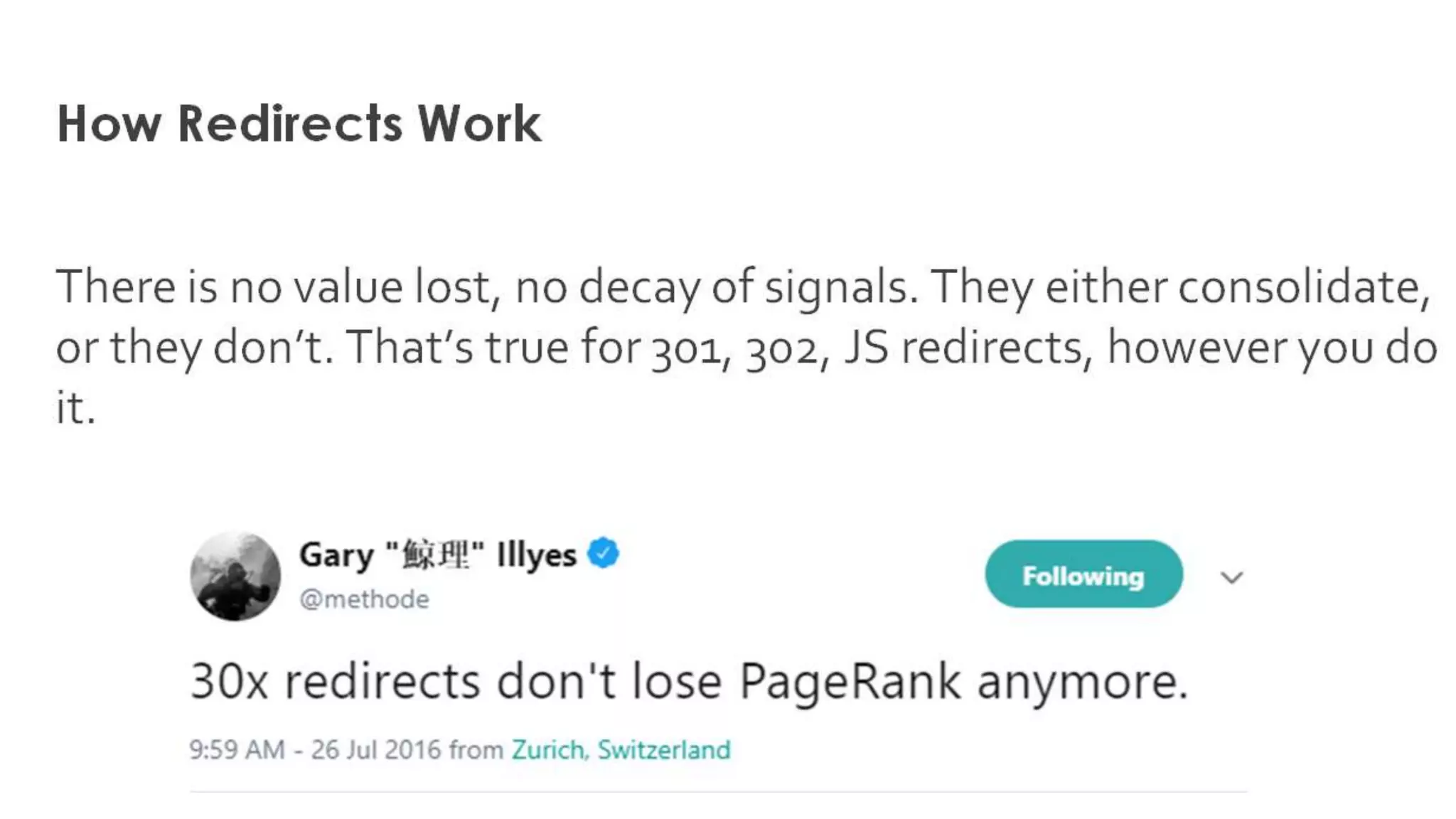
Redirects facilitate page navigation for users and search engines, ensuring proper URL routing.
Importance of site speed, platforms for monitoring, and the impact on user analytics.
Introduction to AMP and its contribution to optimized loading speed for mobile users.
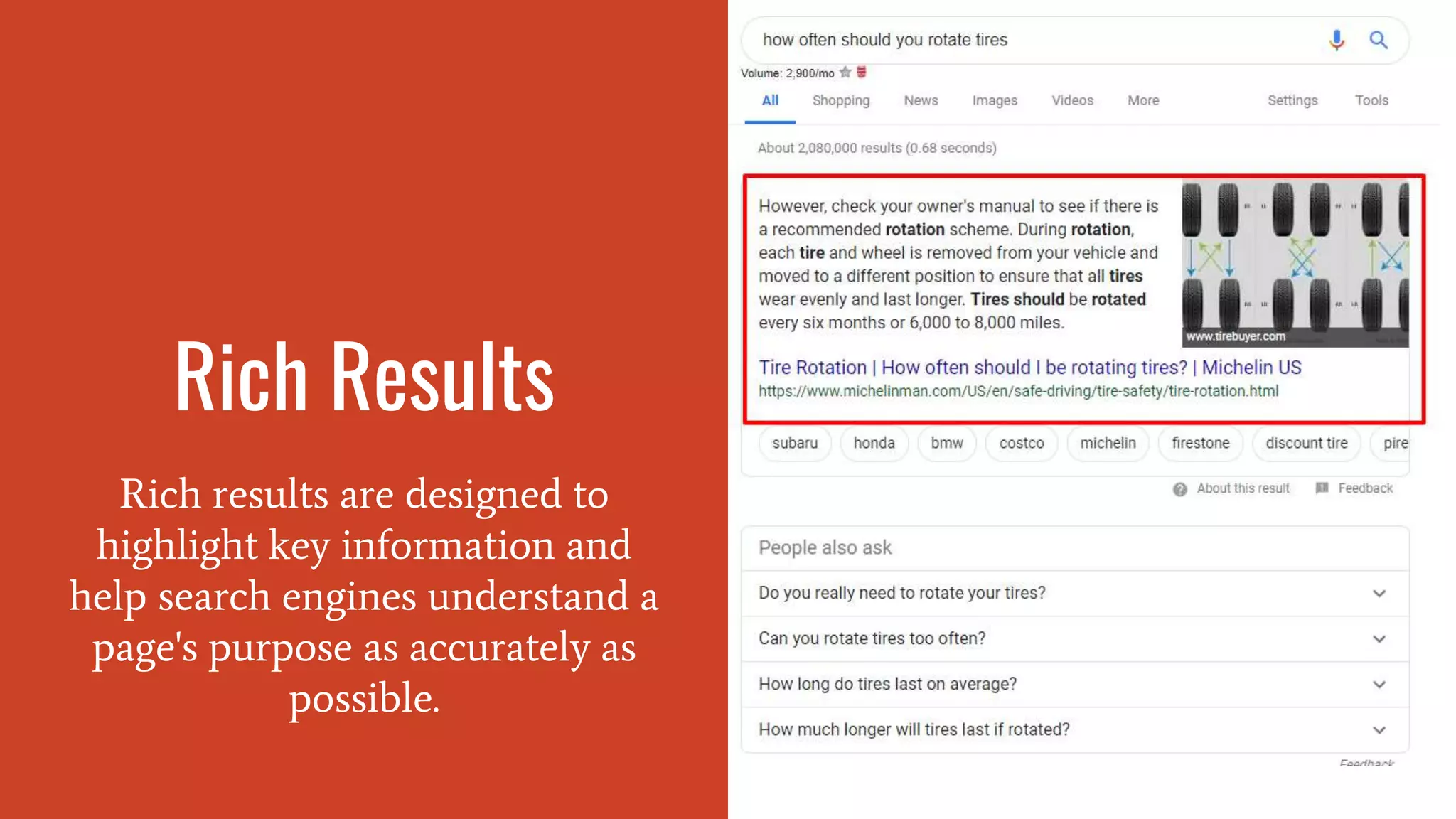
Discussion on schema markup benefits for SERP features, including rich snippets.
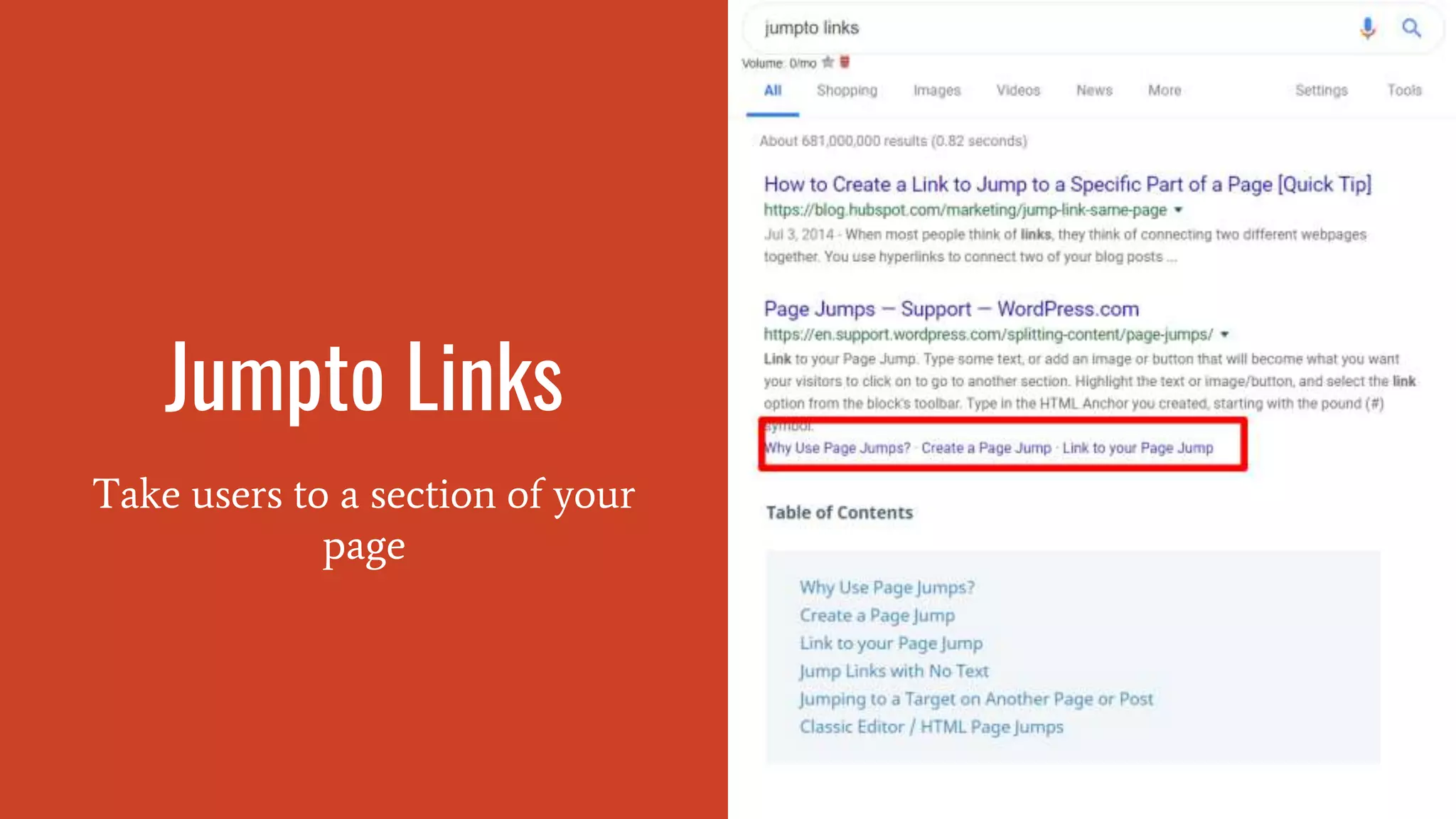
Embedding jump links for quick navigation to sections on a page for better user experience.
The transition to HTTPS and its significance for security and SEO benefits.
Managing mixed content issues during HTTPS migration through content security policies.
Challenges and strategies for optimizing JavaScript frameworks for search engines.
Overview of pagination's effectiveness and best practices for current SEO needs.
Focus on creating fewer and stronger pages for effective SEO management.
Using log files for insights into user interaction and site performance.
Discussion on middleware systems and their influence on SEO strategies.
Examining serverless SEO practices and their relevance in modern site optimization.
How hreflang tags address internationalization challenges in SEO.
Insight into keyword cannibalization and strategies to manage it in SEO.
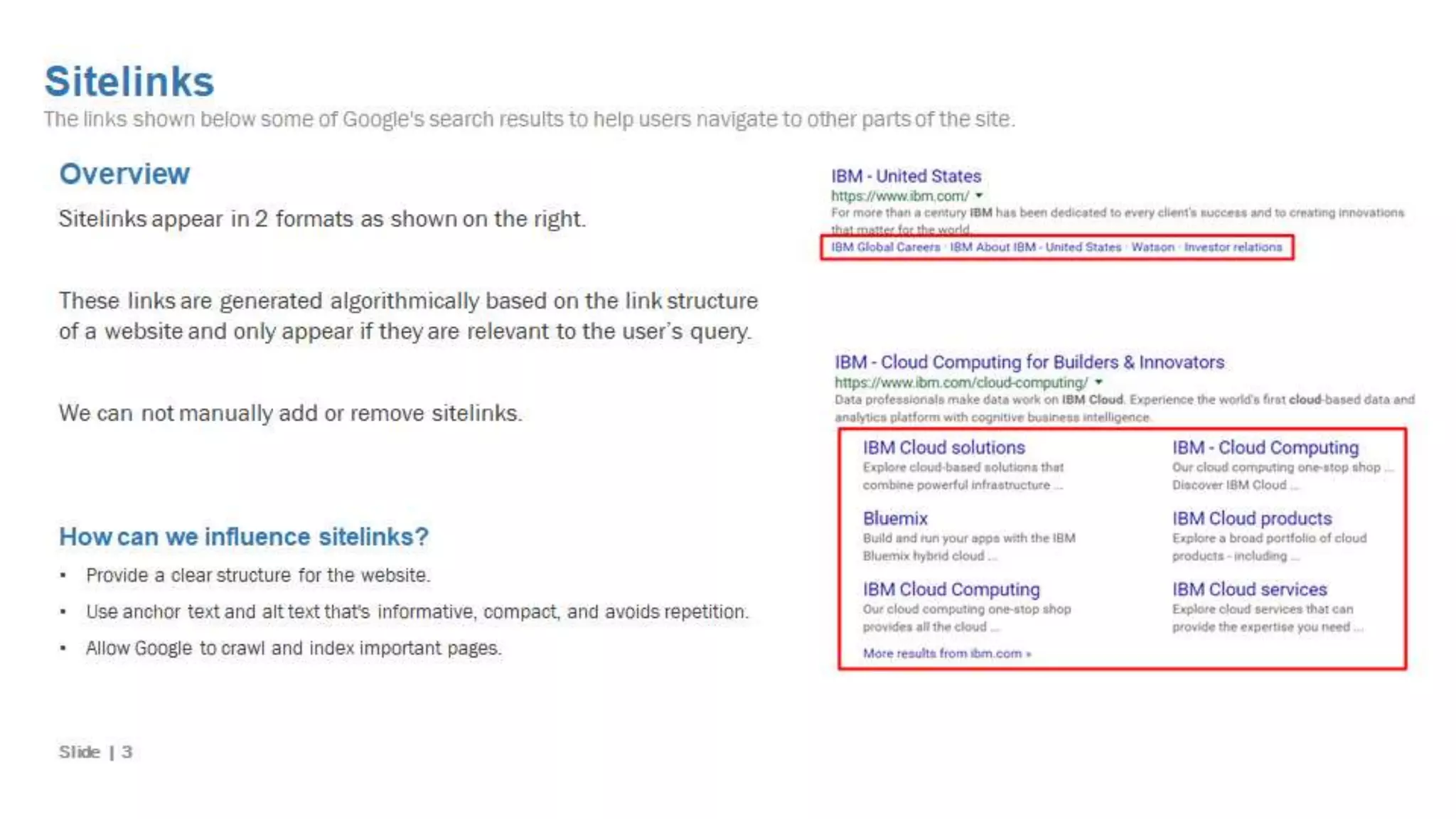
The significance of internal links in enhancing website SEO performance.








![Content Design & its Role in SEO and Accessibility [BrightonSEO Spring 2023]](https://cdn.slidesharecdn.com/ss_thumbnails/bseocontentdesignitsroleinseoandaccessibility-230419114610-31da7d19-thumbnail.jpg?width=640&height=640&fit=bounds)













































































